基于Xgboost算法的大学生积极心理品质预测及影响因素分析
2021-04-09刘俊彤
杨 利,昌 杰,张 浩,刘俊彤
(皖南医学院 医学信息学院,安徽 芜湖 241002)
当前,社会竞争日益激烈和社会环境日益复杂,大学生承受着学习、人际、情感和择业等诸多压力。培养大学生的积极心理品质,提高大学生心理素质,使他们能以积极的心态面对多方面压力,从而更好的适应社会的发展。随着机器学习技术的快速发展和广泛使用,可将其应用于大学生的积极心理品质数据的分析,挖掘影响大学生积极心理品质的影响因素,预测大学生积极心理品质状况,从而找到可提高大学生积极心理品质的有效方法。
积极心理品质最早由Seligman于2002年在《真实的幸福》提出,他用“积极品质”(positive character)描述个体的积极心理品质[1]。官群、孟万金认为积极心理品质是人本身固有的、潜在的、建设性的,是一种正向的或主动的心理品质,并针对中国学生人群开展了大规模问卷调查,挖掘出20项积极品质,分为6大类:认知、人际、情感、公正、节制、超越[2]。国内不少学者对这6个维度20项积极心理品质进行了进一步研究,各种研究表明,年龄[3]、家庭教养方式[4]、体育参与度[5]、社交[6]、是否独生子女[7]等因素对个体积极心理品质有重要影响。因此本文选取性别、年级、科别、生源地、独生子女、父母的教养方式等因素,预测大学生的积极心理品质状况,并对这些影响因素进行分析。
机器学习是研究计算机模拟或实现人类的学习行为,重组已有的知识结构并使之不断改善[8],广泛应用于心理领域[9-13],但大部分机器学习算法存在计算量大、过拟合及预测的准确率不高等缺点。Xgboost是一种性能优异的机器学习算法,2016年由陈天奇提出,是一种改进的GBTD(Gradient Boosting Decision Tree)算法[14]。近年来,大量研究学者对Xgboost算法展开了深入研究,该算法已作为分类、回归和特征排序的有效方法并迅速发展,广泛应用于电子商务推荐[15]、商业预测[16]、住房预测[17]、信用评估[18]等领域。
因此,本文通过量表收集积极心理品质相关数据,建立基于XgBoost算法的大学生积极心理品质预测模型,预测出大学生积极心理品质,同时分析其影响因素。
1 Xgboost算法
Xgboost是一种提升方法(boosting)。提升方法通过构造多个“弱学习器”,这些“弱学习器”之间有着很强的依赖关系,通过线性组合,最终形成一个“强学习器”,可大幅提升分类算法的准确度,“弱学习器”一般通过改变训练数据的的概率分布或权值分布所得。代表性的提升方法有AdaBoost和GBDT(Gradient Boosting Decision Tree)。AdaBoost主要用于二分类问题,选用指数损失函数作为损失函数,通过提高前次学习器分错样本的权值用于训练下一个学习器[19]。而GBDT以决策树为基分类器,可选用多种损失函数,计算前次学习器的残差,在残差减少(负梯度)的方向上拟合下一个决策树(学习器)。GBDT只需拟合当前分类器的残差,相对于AdaBoost算法要简单的多[20]。然而对于一些复杂的损失函数,GBDT难以计算其负梯度。Xgboost对损失函数进行了二阶泰勒展开,通过计算参数的一阶和二阶导数替代负梯度,同时Xgboost还引入了树的复杂度作为正则化项,树的复杂度由树的叶子节点数目和权值构成,有效降低了计算的复杂度,显著提升了模型的泛化能力。
下面对Xgboost算法的决策树模型、目标函数及具体步骤进行说明。
1.1 决策树模型
设训练数据集T={(x1,y1),(x2,y2),…,(xn,yn)},xi为第i个样本点,yi为第i个样本点对应的标签。决策树模型定义如下:
(1)
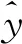
1.2 目标函数
对于第k次训练,设目标函数为:

(2)
目标函数由损失函数和正则化项构成,正则化项Ω(fk)定义如下:
(3)
使用二阶泰勒展开式(3)并优化可得:
(4)
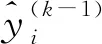
1.3 Xgboost算法具体步骤
1.3.1 初始化f0(xi)=0。
1.3.2 使用贪心算法构建第k(k∈1,2,…,K)次决策树模型。
对树中的每个叶子节点,使用贪心算法遍历所有特征值及其切分点,选取切分后目标函数变化最大的作为当前决策树fk(xi)。目标函数变化的计算公式如下:
(5)
GL、GR分别为切分后左、右子树对参数的一阶导数,HL、HR为切分后左、右子树对参数的二阶导数。

1.3.4 设定Gain阈值或树的深度,终止节点分裂,得到最终模型式(1)。
2 实验与结果
2.1 实验数据
采取整群抽样的方法,从安徽芜湖6所高校选取在校大学生为施测对象,通过纸质问卷和网络问卷的方式发放量表,施测对象共计2764人,有效回收量表数据2053人,有效率74.3%。
施测量表由以下两部分组成:
2.1.1 大学生积极心理品质影响因素调查表
包括性别(男、女),年级(大一、大二、大三、大四、大五),科别(文科,理科),生源地(农村,城市),独生子女(是、否),父母的教养方式(民主型、专制型、溺爱型、忽视型),父母的受教育程度(小学及以下、中学及高中、大学及以上),学习成绩(班级排名前30%、班级排名70%至30%、班级排名后30%),恋爱(是、否),每周锻炼时间(0~2小时、2~5小时、5小时以上),家庭经济状况(较差、一般、较好),社团活动(从不参加、很少参加、一般、经常参加)共计12个因素。设项目选项数为n,则计分为1至n,例如每周锻炼时间0~2小时、2~5小时、5小时以上分别计分为1、2、3。每条记录最多允许存在2个缺失值,否则作为无效数据,对于缺失值用众数填充。此次统计数据的被试的人口统计学变量(已填充缺失值)如表1所示。
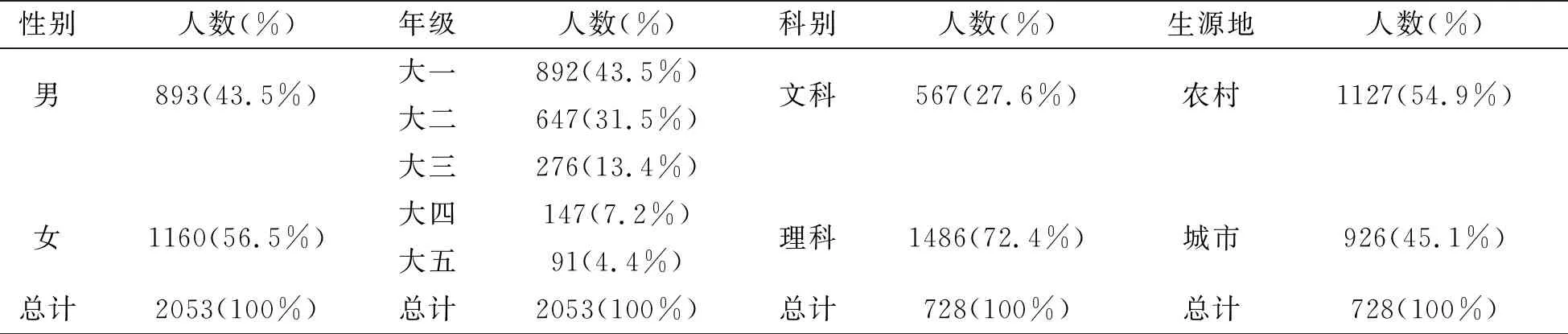
表1 被试对象的人口统计学变量
2.1.2 中国大学生积极心理品质量表

表2 大学生积极心理品质总体情况
2.2 数据模型训练
2.2.1 评价指标
实验采用R2(Coefficient of Determination,决定系数)作为评价指标,R2的计算公式如式(6)所示。
(6)

2.2.2 模型参数
本实验环境为python3.7,使用xgboost.sklearn包中的XGBRegressor模块训练数据。实验中,随机从这2053份大学生心理健康数据中选取70%(1437份)作为训练样本,30%(616份)数据作为测试样本。以R2为指标,使用GridSearchCV函数搜索learning_rate(学习率)、n_estimators(迭代次数)和max_depth(树的最大深度)等参数,找出最佳模型。GridSearchCV函数主要功能为自动调参,给出参数范围,能找出最优结果及其对应的参数,适用于小数据集。通过多次不断变化样本数据及设定参数范围,最终确定参数为learning_rate=0.12,n_estimators=322,max_depth=5。
2.2.3 实验结果
使用Xgboost和目前常用的心理数据分析方法决策树、SVM(support vector machines,支持向量机)、随机森林对大学生积极心理品质数据进行预测,先用GridSearchCV函数对决策树等3种方法进行参数优化,每种方法进行10次实验,每次实验随机选取总样本的70%进行训练,30%用于测试。记录R2指标的最大值和平均值,实验结果如表3所示。

表3 四种模型的的最大值和平均值
3 大学生积极心理品质影响因素分析
使用内置函数get_booster().get_fscore()分析Xgboost模型的特征权重,找出影响大学生积极心理品质的重要因素,为制定大学生积极心理品质培养策略提供决策支持。根据特征权重对模型贡献所占的百分比进行排名,结果如图1所示。
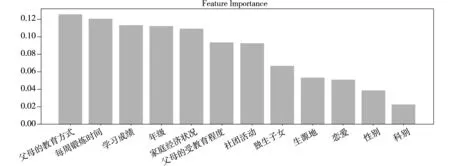
图1 特征重要性排名
从图1可以看出,与家庭环境相关的特征有:父母的教育方式、家庭经济状况、父母的受教育程度、独生子女,其特征权重分别排在第1、5、6、8位,说明家庭环境对于大学生积极心理品质的影响较大,相关教育工作者可通过建立有效的家庭联系常态化机制,及时掌握学生的家庭环境变化。模型贡献度较高的特征还有:每周锻炼时间、学习成绩以及社团活动,利用线性回归分析单独分析每个特征与积极心理品质关系发现,这三个特征与积极心理品质均呈现出一定的线性正相关性,因此鼓励学生积极参加体育运动、培育良好的学习氛围及各类社团活动,均有利于培养大学生积极心理品质。年级对模型的贡献度排在第4位,说明随着大学生的成长,其积极心理品质也不断发生变化,反映出大学生积极积极心理品质可塑性较高,因此需定期开展积极心理品质教育,确保变化朝着有助于提高积极心理品质的方向发展。
4 结论
本文使用Xgboost算法构建模型对大学生积极心理品质进行了预测,并使用GridSearchCV函数对模型参数进行优化,指标的最大值达到0.93,高于决策树、SVM和随机森林等算法。同时,对模型中的特征依据贡献度进行了排序,对影响大学生积极心理品质的重要因素进行了分析。本文不足之处在于使用了GridSearchCV函数对Xgboost算法模型进行调参,但这种调参方式一般适用于小样本,后续将研究大样本下Xgboost算法在大学生积极心理品质分析中的应用。
