基于多变量LSTM 神经网络的澳大利亚大火预测研究
2021-04-09杜丽霞张子柯
李 莉,杜丽霞,张子柯
(1. 山西大学计算机与信息技术学院 太原 030006;2. 杭州师范大学阿里巴巴商学院 杭州 311121)
丛林大火是澳大利亚炎热干燥季节频繁发生的野外火灾,由于火灾时常交替发生,自然生态系统随之演变,丛林大火成为了澳大利亚生态的重要组成部分[1]。随着全球气温升高,澳大利亚大火愈发猛烈且不可控制。2019 年7 月以来,澳大利亚全境发生持续性的丛林大火[2],造成了巨大的损失。据澳大利亚联邦统计,大火总燃烧面积约1.7×107hm2,全国超过10 亿只动物因大火而丧生。澳大利亚大火造成的影响不止当地的损失,大火的连锁反应导致它成为一个全球性的问题,对人类生存有极大的消极影响,如引起CO2排放量上升、污染水源、破坏生态系统等[3]。
本文首先对森林火灾发生的必要因素[4]进行了分析,影响森林火灾发生的主要因素包括燃料、氧气和火源。山火蔓延的烈度和速度取决于环境温度、燃料湿度、风速和坡度。桉树、刺槐等易燃植物的分布是火灾发生的根本依据,干燥的燃料会燃烧得很快,而潮湿或湿的燃料不易发生火灾,所以降雨量是评估山火的重要考虑因素;环境温度越高,越有可能发生火灾,因此环境温度也是预测森林火灾重要指标。
针对澳大利亚大火的预测,已有一些学者进行了研究,如文献[5]利用前馈反馈、多层感知等神经网络的方法预测澳大利亚最有可能发生火灾的地点。但是这种神经网络模型容易出现梯度消失或者梯度爆炸问题;文献[6]通过元胞自动机来模拟森林的生长-火灾-恢复过程,构建自然因素与火灾蔓延关系的模型。可是预测该模型没有考虑澳大利亚真实历史数据,预测结果与实际情况存在偏差。
综合分析以上原因,本文以气候分布、植被分布、降水量和温度作为依据建立了LSTM(long short-term memory)多变量数据驱动预测模型,通过添加门控制来解决神经网络出现的梯度消失或者梯度爆炸问题,利用有时间依赖的数据进行预测,同时与BP(back-propagation)和ARIMA(autoregressive integrated moving average model)进行对比,多变量LSTM 预测效果良好,有较高的可信度。
1 研究方法
1.1 BP 神经网络模型
BP 神经网络是应用最广泛的神经网络。它的基本思想是梯度下降法,利用梯度搜索技术,使网络的实际输出值和期望输出值的误差均方差最小[7-8]。
BP 神经网络是线性权重的激活函数模型,输入一个向量,对向量进行加权处理输入到隐含层神经元的激活函数中,再将函数的输出值进行加权处理最后得到输出层的值,典型的BP 神经网络模型图如图1 所示。

图1 BP 神经网络模型[9]
输入层的输入为i=(i1,i2,···,in),输入单元经过加权处理后成为隐含层的输入 lik;隐含层神经单元个数为 p ,经过处理后,隐含层的输出为 lop;隐含层的输出结果经过 whj加权处理后成为输出层的输入 oom;输出层神经元个数为q,输出层的输出为oo。当实际输出与期望输出之间的误差超出规定的精度时,进入误差的反向传播阶段。误差通过输出层按误差梯度下降的方式修正各层权值,向隐含层、输入层逐层反传。
1.2 ARIMA 模型
ARIMA 模型的全称叫做差分自相关移动平均模型,是统计模型中最常见的一种用来进行时间序列预测的模型[10-11]。ARIMA 模型实质上是自回归模型(autoregressive model, AR)、移动平均模型(moving average model, MA)和差分法3 种方法的整合。
1.3 多变量LSTM 模型
长短周期记忆神经网络通常被称为LSTM 网络,是一种时间递归的神经网络,适合预测和处理有时间依赖的问题[12]。它有能力捕获过去阶段的数据,并使用过去一段时间某一事件时间特征来预测未来一段时间内的活动特点,在许多实际应用中展现了优异的性能[13]。
LSTM 的网络架构是由一个个重复的神经元模块组成的链式结构[14]。每一个重复的神经元模块有4 个神经网络层,且通过一种特殊的方式交互。LSTM 的神经元模块结构如图2 所示。
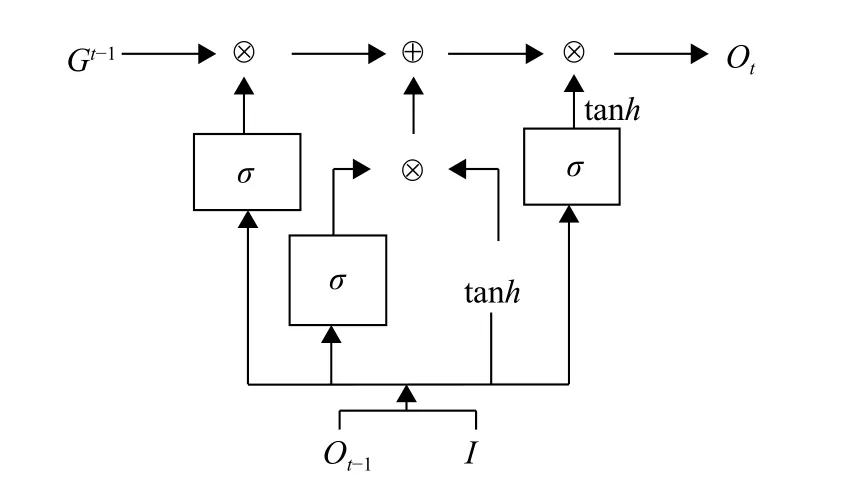
图2 LSTM 神经元模块
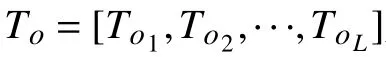
本文所采用的数据为浮点型数据,利用LSTM进行预测时,首先将数据进行归一化处理。考虑到上一个时间段降水量和温度,构造时间序列数据集,并将时间序列问题转化为监督学习问题,以监督学习输出值作为预测结果进行多变量时间序列预测,最终预测当前时刻的着火情况(1 表示着火,0 表示未着火)。预测输出结果为一系列0~1 之间的无量纲值,越接近0,说明着火的可能性越小,反之,越接近1 说明着火可能性越大。

图3 多变量LSTM 预测模型框架[14]
2 数 据
2.1 澳大利亚气候与植被概况
澳大利亚位于南太平洋,南回归线横贯澳大利亚大陆中部,大部分地区在副热带高气压带和东南信风的控制下,炎热干燥。
澳大利亚的北部夏天,来自赤道的西北风带来丰沛的降水,较为湿润,冬季受东南信风控制,为干季;中部受副高控制,形成干燥少雨的热带沙漠气候;南部、西南部位受到副高和西风带的交替控制,为地中海气候;最南端常年受西风控制,形成温带海洋性气候;西部沿海受东南信风和副高控制,加上沿岸的寒流影响,形成热带草原气候;东南沿海受暖流影响,比较湿润,形成亚热带湿润气候;东北部常年吹东南信风,降水丰沛,形成热带雨林气候[15]。
澳大利亚的植被分布呈明显半环状,即北、东、南三面以森林为主,向内逐步以草原植被为主,核心为荒漠植被。
2.2 研究数据
本文基于澳大利亚地图,根据气候和植被的分布特点划分59 个节点。选取每个节点2018 年1 月1 日-2020 年4 月1 日的日最低降水量、最高温度和是否着火3 项数据作为研究数据。本文以节点36 为研究对象,对预测模型进行详细说明,节点36 的日最高温度、最低降水量数据如图4 所示。
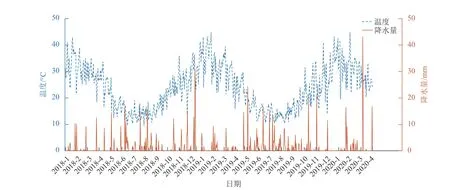
图4 节点36 的日最高温度、最低降水量数据
3 澳大利亚大火预测
3.1 数据准备
为了构建基于多变量LSTM 神经网络的澳大利亚大火预测模型,选取2018 年1 月1 日-2020年1 月10 日的数据作为训练集,2020 年1 月11 日-2020 年3 月31 日的数据作为测试集。以日最高温度、最低降水量、是否着火作为模型变量输入,以测试集的均方根误差(RMSE)作为模型训练预测精度评价指标。
为了提高模型预测精度,加快模型训练收敛速度,本文采用以下方法对原始变量时序集进行标准化处理[16],表示为:
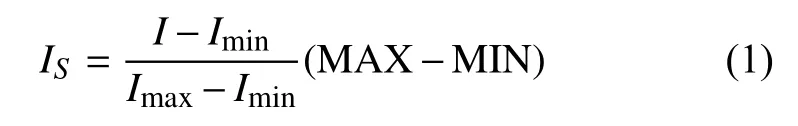
式中,MIN=0;MAX=1; IS表示标准化后的值;I表示标准化前的值; Imin表示原始数据集中的最小值;Imax表示原始数据集中的最大值。
3.2 模型训练
根据LSTM 模型结构[16],多变量LSTM 神经网络预测模型训练步骤如下:
1) 在输入层中,定义2018 年1 月1 日-2020 年3 月31 日的数据集为:
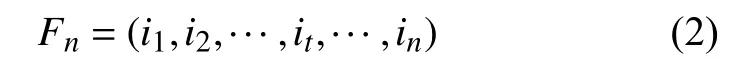
式中,it={at,bt,ct}, at、 bt、 ct分别表示t 时刻对应的最高温度、最低降水量和是否着火。
2) 对标准化处理和格式转换后的数据进行训练集和测试集划分,可表示为:
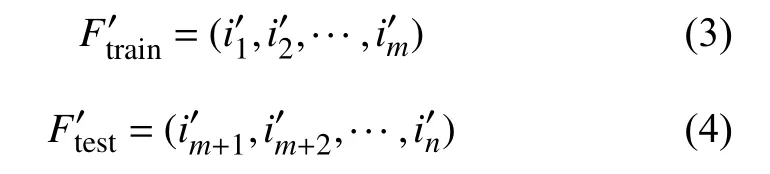
《南村辍耕录》上说,中书丞相史天泽本来须髯已白,然而,一朝忽尽黑。元世祖忽必烈见之,惊问曰:“史拔都,汝之髯何乃更黑耶?”史天泽说,我用药染了。问:染了干什么呢?答:“臣揽镜见髭髯白,窃伤年且暮,尽忠于陛下之日短矣,因染之使玄,而报效之心不异畴昔耳。”丞相巧舌如簧,忽必烈听了非常高兴。
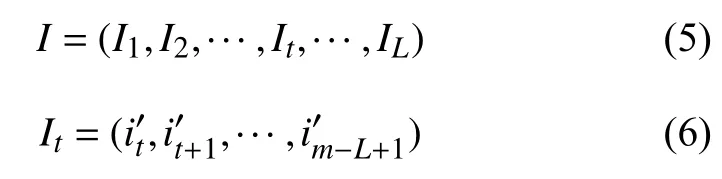
式中,I 为输入到隐含层L 个细胞单元的数据集。
4) 隐含层理论输出为:

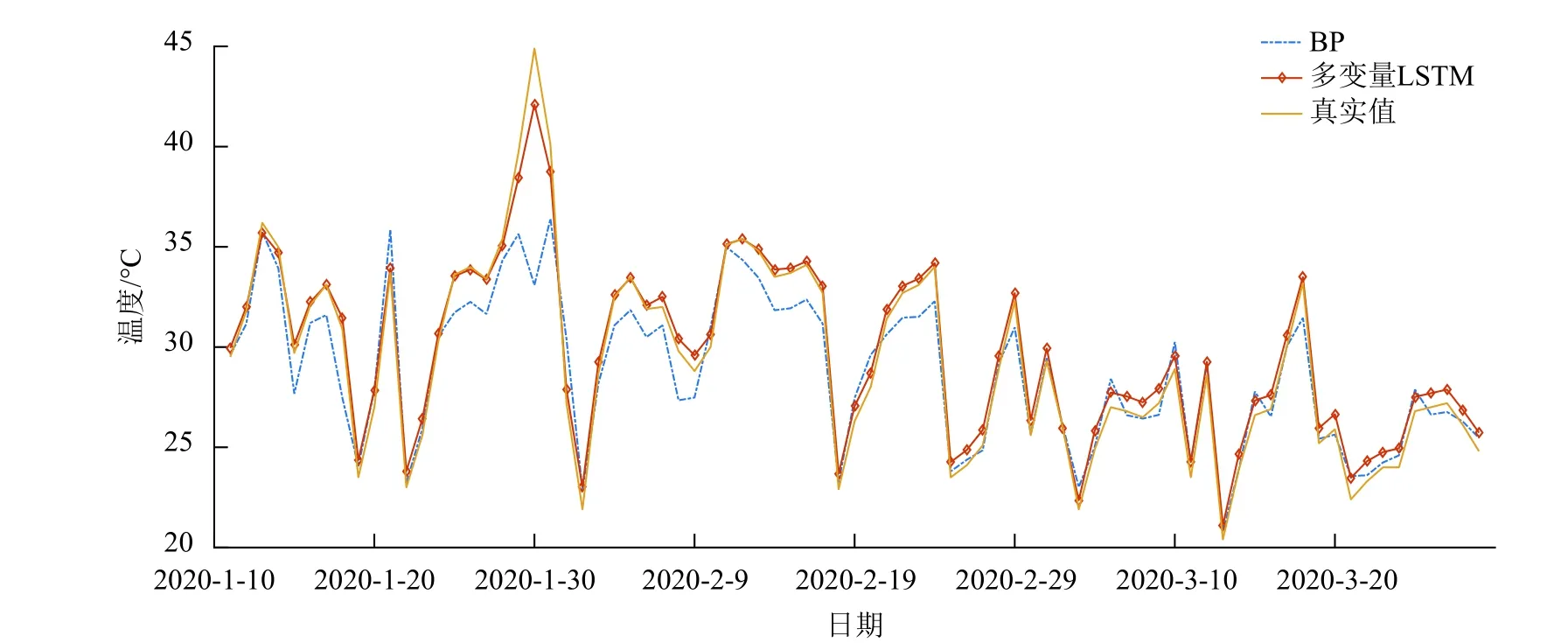
图5 BP 与多变量LSTM 对日最高温度的预测
实际输出为:

式中,LSTM 为图2 所示计算过程。
5) 训练过程中均方误差(RMSE)作为损失计算公式:
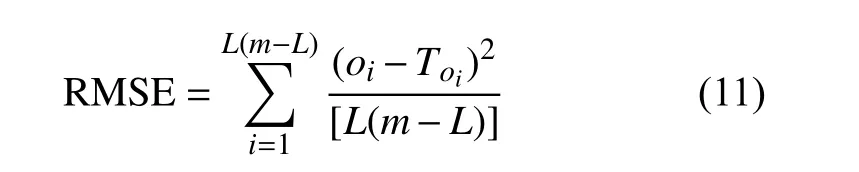
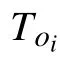
6) 以RMSE 最小为优化目标,应用Adam 优化算法更新权重,直到RMSE 最小。
3.3 实验结果
为了验证多变量LSTM 神经网络预测澳大利亚大火的优点,使用多变量LSTM 神经网络与ARIMA神经网络和BP 神经网络预测结果互相对比的方法进行分析。
BP 神经网络预测通常以相互影响的因素作为输入来预测剩余的单个因素,以日最高温度、最低降水量和是否着火作为互相影响的元素,利用BP神经网络分别对节点36 从2020 年1 月11 日-2020年3 月14 日的日最高温度进行预测;ARIMA 预测对数据的平稳性有一定要求,通过对训练集数据进行平稳性检验和白噪声检验后,发现数据的平稳性较好,不需要进行差分处理,随即利用ARIMA 对日最高温度进行了预测;多变量LSTM 神经网络以日最高温度、最低降水量和是否着火三维数据作为输入,通过综合分析3 种元素之间的相互影响,对日最高温度进行了预测。图5 为利用BP 与多变量LSTM 对日最高温度的预测,图6 为ARIMA 与多变量LSTM 对日最高温度的预测。

图6 ARIMA 与多变量LSTM 对日最高温度的预测
为了更直观地看出3 种方法的优劣,本文利用评价指标均方根误差(RMSE)来刻画。BP 神经网络的RMSE 最大,为4.150;ARIMA 的RMSE 比BP神经网络略小,为4.012。多变量LSTM 神经网络的RMSE 最小,为3.862。这是因为BP 神经网络在训练过程中未考虑时序变化规律,只考虑了因素之间的相互影响,总体预测效果明显比其他两种方法差;ARIMA 模型没有考虑多个因素之间的相互影响,只是以日最高温度单个因素作为变量进行训练,然后根据日最高温度的时序性做出相应预测,因此预测效果一般,介于两者之间;多变量LSTM在预测过程中综合考虑了日最高温度、最低降水量和是否着火3 个因素的相互影响,同时结合了时间序列依赖关系[17],因此预测效果最好。
综上所述,BP、ARIMA 和多变量LSTM3 种预测模型中,基于多变量的LSTM 预测模型预测效果最佳,有较高的可信度。基于以上结论,利用多变量LSTM、BP 和ARIMA 对节点36 从2020 年1 月11 日-2020 年3 月14 日的着火可能性进行了预测,结果如图7 所示。
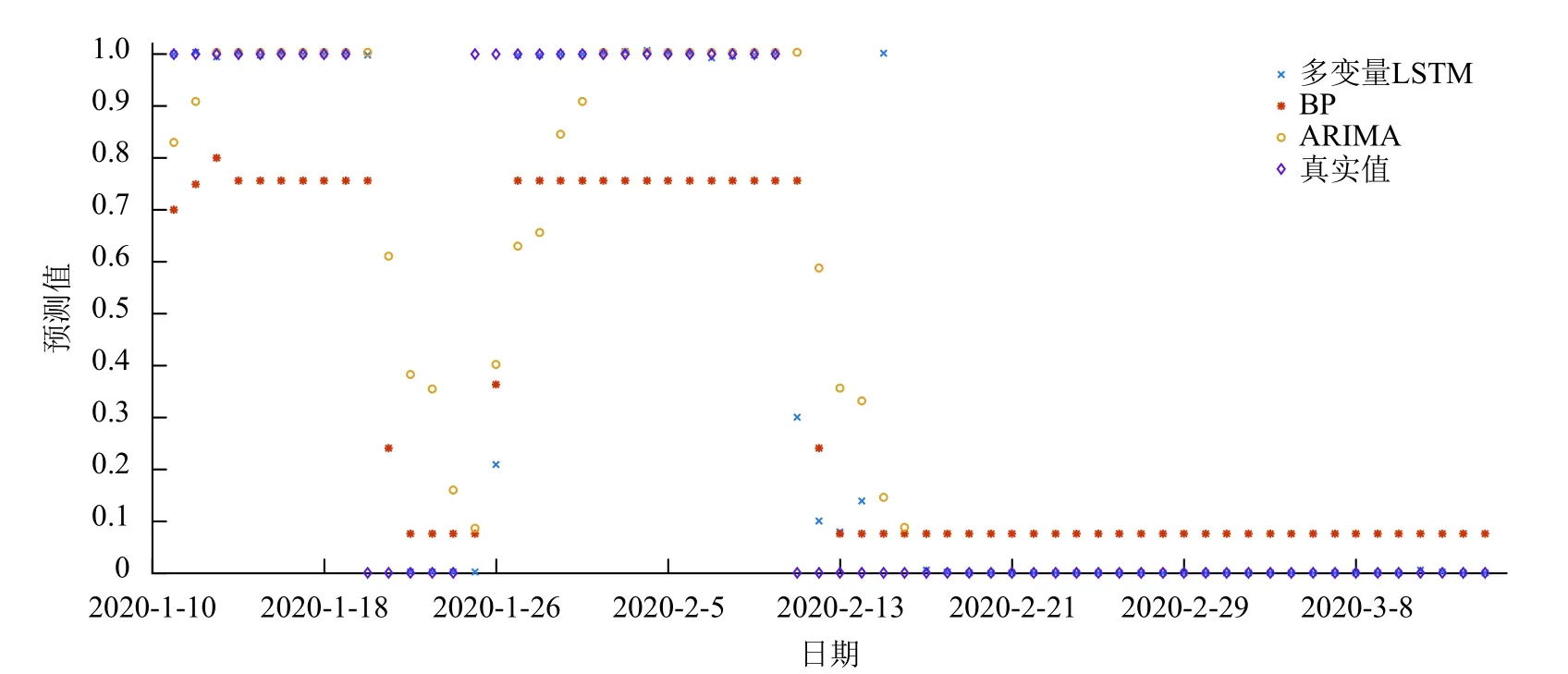
图7 着火可能性预测
利用RMSE 对3 种预测方法进行评价。其中,多变量LSTM 的RMSE 为0.238;ARIMA 的RMSE为0.297;BP 的RMSE 最大,为0.359。由此可见多变量LSTM 对澳大利亚大火的预测效果最好。
由于BP 神经网络方法存在梯度消失问题,不能很好地利用时间序列信息,所以预测结果与实际情况偏差较大;ARIMA 是时间序列预测常用的方法,可以很好地处理有时间依赖的数据。不足的是ARIMA 不能考虑其他因素对本变量的影响,所以ARIMA 的预测结果不佳。LSTM 多变量数据驱动的预测模型,通过添加门控制来解决神经网络出现的梯度消失或者梯度爆炸问题,并且可以结合考虑多个因素,预测结果与真实情况对比有较高的可靠性。
4 结 束 语
本文采用BP、ARIMA、多变量LSTM 神经网络模型对澳大利亚大火进行预测。经对比发现多变量LSTM 预测效果最好,用多变量LSTM 的方法将预测结果与实际值进行比较,预测结果有很高的可信度。LSTM 是长短周期记忆神经网络,由于其模型中3 种“门”的存在,使得其对于有时序性的数据有长时记忆的能力,对有周期性的数据预测精度较高。用来预测澳大利亚大火的数据是日最高温度、最低降水量以及着火点,这3 类数据均具有周期性,这也是多变量LSTM 预测效果比BP、ARIMA好的原因。实验表明该算法对大火预测的精度较高,可以用于对我国境内发生的大火进行预测,减少大火带来的危害。
