基于深度确定性策略梯度的粒子群算法
2021-04-09鲁华祥尹世远龚国良
鲁华祥,尹世远,龚国良*,刘 毅,陈 刚
(1. 中国科学院半导体研究所 北京 海淀区 100083;2. 中国科学院大学微电子学院 北京 海淀区 100089;3. 中国科学院脑科学与智能技术卓越创新中心 上海 松江区 200031;4. 半导体神经网络智能感知与计算技术北京市重点实验室 北京 海淀区 100083)
群智能优化算法属于随机优化算法的一种,包括经典粒子群算法(particle swarm optimization, PSO)[1]、鲸鱼群算法(whale optimization algorithm, WOA)[2]、灰狼算法(gray wolf optimization algorithm, GWO)[3]、蝙蝠算法(BAT)[4]等,这些算法都是模拟大自然中某种生物的生活习性而创造的算法。
PSO[1]是一种群智能优化算法,其原理是模仿鸟群捕食和聚集的行为,并采用计算机模拟的方式创造一种随机优化的算法。该算法自首次提出开始就受到广泛关注,其优势主要在于它简单的基本原理、较少的参数和快速的收敛速度。该算法已经广泛应用于工业生产[5]、矿山[6]、煤炭[7]、水电调度[8]等领域。
但PSO 算法也有一些不足。传统PSO 算法可以很好地工作在低维问题上,但是在高维问题上经常表现很差。另外,PSO 算法在求解复杂问题时,经常会被困在局部最优点中,过早地收敛[9]。研究者对PSO 算法存在的问题进行了很多改进。文献[10]首次提出了惯性权重,文献[11]首次提出了收缩系数。这些方法都通过控制算法的一些运行参数较好地平衡了算法的探索能力和挖掘已有信息的能力。自组织层次化粒子群算法[12]通过采用一个随时间变化的参数,提升了算法的收敛能力。文献[13]提出了一种自适应粒子群优化算法,通过进化状态估计将种群状态划分为探索、开发、收敛和跳出4 种状态,然后根据这4 种状态自适应地调整惯性权重和加速度系数。文献[14]通过将粒子位置的各维度进行逐通道学习避免了PSO 算法在优化过程中经常出现震荡的问题。文献[15]提出了无速度约束多群粒子群优化,通过加入约束处理技术,在优化可行域之前将总体搜索引向搜索空间的可行区域,使得PSO 算法可以解决约束优化问题。文献[16]提出了基于末端弹性机制和交叉转向机制的粒子群算法,通过引入非线性惯性权重和弹性机制,更好地平衡了算法的利用与开发。文献[17]提出了一种具有变异算子的粒子群优化算法,通过将种群分为不同的亚群,引入非均匀突变算子,增加高斯变异操作,提高了算法的探索能力。
这些改进方法具有一个共同的特点,即通过人工对算法的超参数进行设置,只有经过多次反复尝试才能得到一个相对较优的参数组。近年来,随着机器学习和强化学习的兴起,神经网络逐渐展现出强大的参数搜索能力。优化问题的目标是优化一个函数的值,而每步之间该值的差非常适合作为强化学习中的奖励基准来使用。这使得在群智能算法领域应用强化学习成为可能。
但是,在传统的连续控制领域,动作空间十分巨大并且动作值均为连续的实数值。这使得强化学习智能体直接从像素级别信息进行学习变得十分困难。近些年Google DeepMind 团队提出了一种新型的深度强化学习算法:深度确定性策略梯度算法(deep deterministic policy gradient, DDPG)[18],其在很多连续控制问题上表现突出,比如Atari 电子游戏[18-19],但尚未有人将该算法与群体智能算法相结合来进行研究。
本文提出了一种基于深度确定性策略梯度的粒子群优化算法,在原有的粒子群算法中引入神经网络来动态调节算法的收敛速度。通过提前训练,获得一个动作网络,然后应用动作网络求解优化问题。对改进的算法进行仿真验证,在多种测试函数上与其他优化函数进行对比,得出DDPGPSO 有了更高的寻优速度和精度。
1 提出算法的基本原理
本文首先介绍基本的粒子群算法,然后介绍DDPG 的基本思想,最后介绍融合了DDPG 的粒子群优化算法DDPGPSO。
1.1 粒子群优化算法
粒子群优化算法是一种群体智能的算法。这种算法源于对鸟群捕食和聚集行为的研究,通过设计一种无质量的粒子来模拟鸟群中的鸟,粒子仅具有两个属性:速度和位置,速度代表移动的快慢,位置代表移动的方向。每个粒子在搜索空间中单独的搜寻最优解,将其记为当前个体极值,并将个体极值与整个粒子群里的其他粒子共享,找到最优的个体极值作为整个粒子群的当前全局最优解,粒子群中的所有粒子根据自己找到的当前个体极值和整个粒子群共享的当前全局最优解来调整自己的速度和位置。其具体流程如下:
假设种群中含有m 个粒子,解空间的维度是n,每个粒子代表解空间中的一个点。粒子i 包含一个n 维的位置向量(x1,x2,···,xn)和速度向量(v1,v2,···,vn)。每个粒子通过学习它的最优历史位置和全局最优位置来更新速度和位置,更新公式如下:
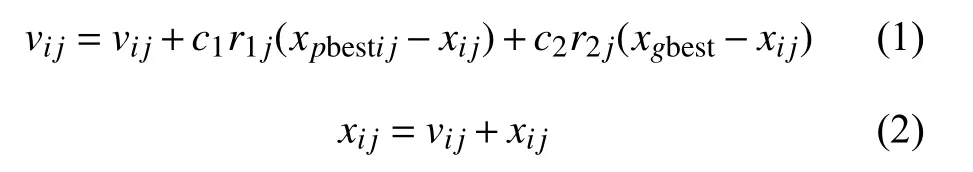
式中,i=1,2,···,m,j=1,2,···,n,m 和n 分别是种群数量和解空间的维度;vij和xij分别代表粒子i 的第j 维的速度和位置;xpbestij代表粒子i 的历史最佳位置;xgbest代表种群内的历史最佳位置;c1和c2是控制加速的参数;r1j和r2j是两个均匀分布于[0,1]区间的随机数。最大速度参数vmaxj被用来将每个粒子的速度控制到一个合适的区间中。如果|vij|>vmaxj,则令vij=vijvmaxj/|vij|。为了平衡种群的探索和挖掘能力,文献[9]提出了速度惯性权重来控制速度,式(1)被修改成:
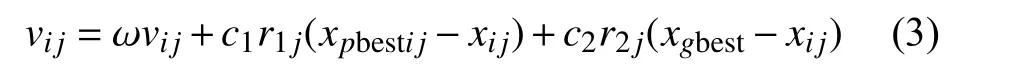
式中, ω一般设置为从0.4~0.9 随时间线性递减。在搜索过程中,惯性参数 ω的这种变化确保算法在早期拥有强大的全局探索能力,在后期拥有强大的局部搜索能力。
1.2 深度确定性策略梯度原理
在标准的强化学习环境中,每一个智能体与环境进行交互,最终目标是最大化环境收益。这种互动过程被格式化地描述为马尔科夫决策过程(MDP),可以通过四元组(S, A, R, P)来描述这个过程。S 是状态空间,A 是动作空间,R:S×A→R 是奖励函数,P:S×A×S→[0,1]是转移概率。在这个环境下,一个智能体会去学习一个策略π:S→A来最大化在环境中的收益:
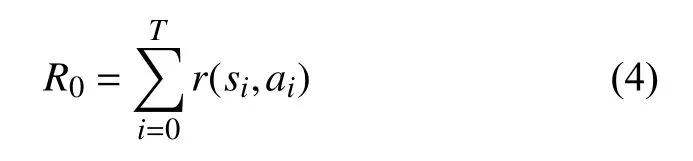
式中,T 是交互结束时前进的步数;r(si,ai)是在环境si中执行ai所获得的收益。通常情况下环境中的长期收益会通过参数γ来缩减:

一般用动作价值函数代表在s 环境中执行a 动作的长期收益:
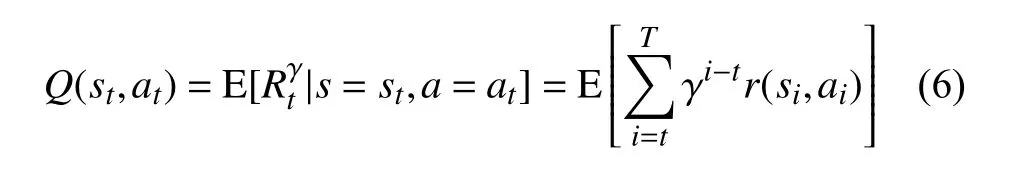
通常使用贝尔曼方程来寻找这种最优的动作价值函数:
然而,这种方式只适合于那些动作和状态空间都是离散情况的场合。为了应用强化学习到动作空间和状态空间为连续情况的问题,DDPG 设计了两个深度神经网络,分别是动作价值网络Q(st,at|θQ)和动作网络μ(st|θμ),其中 θQ和 θμ为网络参数。动作网络μ(st|θμ)就是一个对应状态空间和动作空间的映射,可以直接根据状态产生需要的动作。动作价值网络Q(st,at|θQ)用于接近动作价值函数,并且可以为动作网络的训练提供梯度。
对这种动作价值网络的训练是要最小化损失函数:
式中, Q′是目标价值网络,从 Q网络同步权重。而动作网络参数的更新需要策略梯度算法,其梯度更新方向为:
1.3 基于深度确定性策略梯度的粒子群优化算法原理
1.3.1 迭代参数改进原理
标准的粒子群优化算法在运行过程中,参数都是确定的,如式(3)所示。也有一些文献采用提前设置参数变化形式的方式来自动修改参数[20],但其实质仍是在开始运行时就已经确定,无法根据后续情况进行变化,不能达到最佳的算法效果。为了增加算法的自动调整能力,提高算法的寻优和收敛能力,本文引入了动态自适应参数调整算法,根据当前运行的情况来生成下次迭代所需的参数。改进后的速度更新公式为:

式中,t 为当前的迭代次数;G 为生成函数,本文使用神经网络作为生成函数,这样就可以在迭代过程中动态生成运行参数。
1.3.2 参数生成改进原理
随着PSO 各种改进方式越来越复杂,越来越多的参数需要进行设定,但人工设定各种参数不仅麻烦,而且也不一定能获得最佳性能。加入了参数生成函数后,所需调整的参数量更加巨大,迫切地需要一种自动化的方式来自动配置算法。但是,由于这种优化效果本质上也是一个优化的问题,是不可求导的,也没有合适的损失函数可供使用,传统的深度学习算法无法应用到这种优化问题之中。因此,本文利用DDPG 算法,创建一个智能体,通过跟算法的交互自动习得参数。
该算法所使用的状态空间为六维,前5 个维度代表群智能过去的平均适应性函数的变化量,最后一个维度代表当前的迭代次数,其计算公式为:
式中,fitmeant代表粒子群在第t 轮循环时所有粒子解的平均值;Tmax代表迭代的最大次数;Sit表示第t 轮循环、第i 维的状态向量。
算法的动作空间为三维,动作值介于-1~1 之间,通过线性变换将动作映射到合理的区间。三维动作分别对应式(3)中的 w,c1,c2,其中c1,c2变换到0.5~2.5 区间,w 变换到0.1~0.9 区间。线性变换公式为:
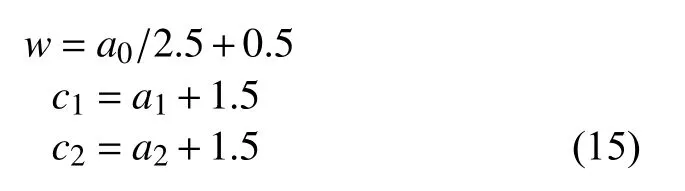
式中,a0,a1,a2分别为动作的3 个维度。算法的奖励值设置如下:当PSO 在当前环境最佳值发生变化,则奖励为1,否则奖励为-1:

这样设置是为了让网络寻找参数,使原有算法更快地对问题进行优化,提高算法的寻优速度。
1.4 算法步骤
1.4.1 训练步骤
1)初始化训练所需参数:训练最大次数TrainMax,当前训练次数episode =1;
2)随机初始化动作网络μ(s|θμ)和动作价值网络Q(s,a|θQ)的参数 θQ和 θμ,具体结构如表1~表2所示;
3)初始化目标网络 Q′和 μ′,其权重值从Q 和μ复制过来;
4)初始化回放缓存R;
5)初始化环境(粒子种群)Xi(i=1,2,···,Q),计算每个个体Xi的适应度值F,得到初始最优位置X*,当前迭代次数t=0,最大迭代次数Tmax;
6) For episode=1, TrainMax do
7)初始化一个随机过程来对动作进行探索;
8)接收环境的初始化观测s1;
9) for t=1, Tmaxdo
10)根据当前的策略和探索噪声选择动作:

11)在环境中执行动作at并观察奖励回报rt和新的状态st+1;
12)将(st, at, rt, st+1)保存到缓存R 中;

15)通过采样的动作策略梯度来更新动作网络:
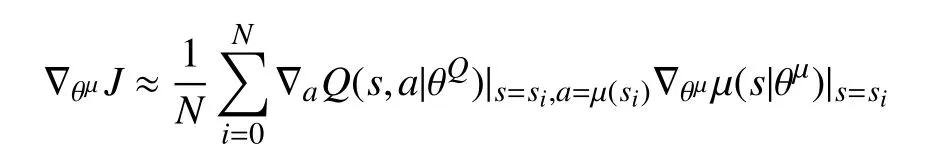
16)更新目标网络函数的权值:

17) end for
18) end for
19)保存训练好的动作网络权重,用于之后的优化问题。

表1 动作网络结构

表2 动作价值网络结构
1.4.2 优化步骤
1)初始化粒子种群xi(i=1,2,···,Q),计算每个个体xi的适应度值,得到初始的全局最优位置x*,最优解F*,当前迭代次数t=0,最大迭代次数Tmax;
2) while t < Tmax
3)计算当前状态,更新全局最优值;
4)根据动作网络μ(s|θμ)和当前状态,获取当前动作,由式(15)转化为群探索参数;
5) for i = 1∶Q
6)应用式(3)更新Xi的速度vi;
7)应用式(2)更新Xi的位置xi;
8) end for
9) end while
2 实验仿真测试
本文将DDPGPSO 算法同飞蛾扑火算法(moth flame optimization, MFO)、布谷鸟算法(CUCKOO)、蝙蝠算法(BAT)、乌贼算法(cuttlefish algorithm, CFA)、多元宇宙算法(multi verse optimizer, MVO)、鲸鱼算法(WOA)、细菌觅食算法(bacterial foraging optimization, BFA)8 种常用的优化算法,以及一种粒子群算法的变种混沌粒子群算法(a chaotic pso algorithm based on sequential algorithm, CPSOS)[20]进行实验对比,参数设置如表3 所示。由于本文主要验证DDPGPSO 的参数生成能力,为了保持一致,CPSOS 的一些复杂操作不予考虑。选用了8 个常用的基准测试函数[21](F1~F8)如表4 所示,最优值均为0。对于所有的算法和测试函数,算法的参数设置如下:最大迭代次数设为100,种群数量设为40,重复计算10 次,采用平均值(mean)、标准差(std)和迭代中的最优值(best)来评价算法的性能,F1~F8 的迭代图分别如图1~图8 所示。在这些测试中,所有的优化算法的初始值均随机生成,在解空间中符合均匀分布。由于画图中采用对数坐标作为纵坐标,为了防止在算法搜索到最优值0 时产生无意义数据,所有绘图的y 数据均增加了一个极小值。图2 和图4 中的DDPGPSO 由于已经搜索到最小值0,对数图中会产生无穷小,因此删去部分末尾数据。
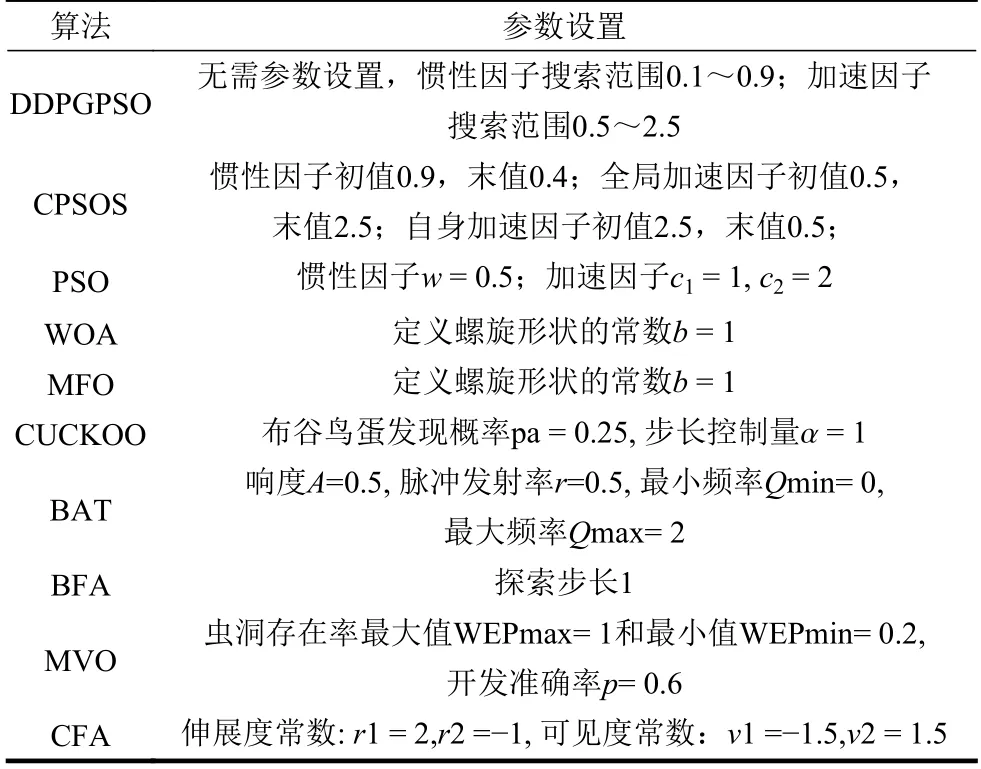
表3 算法参数设置

表4 基准测试函数

图1 F1 迭代图
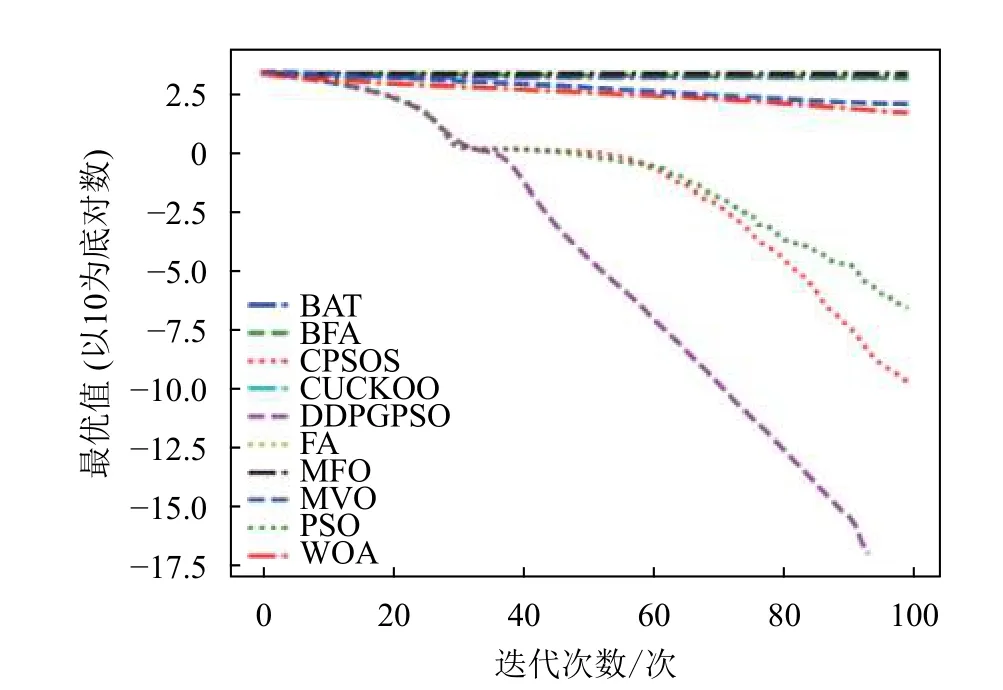
图2 F2 迭代图
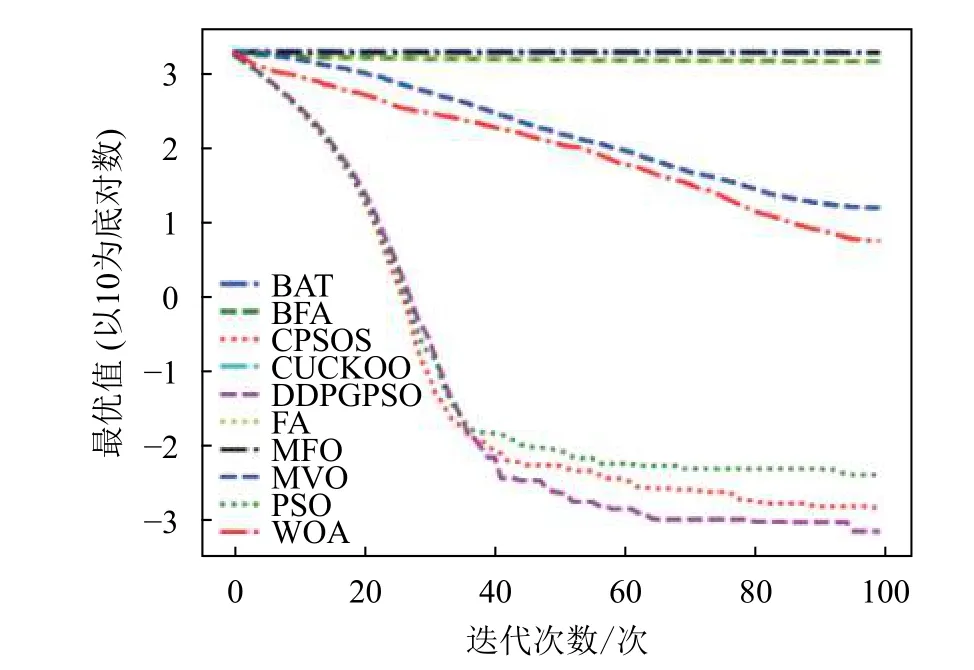
图3 F3 迭代图
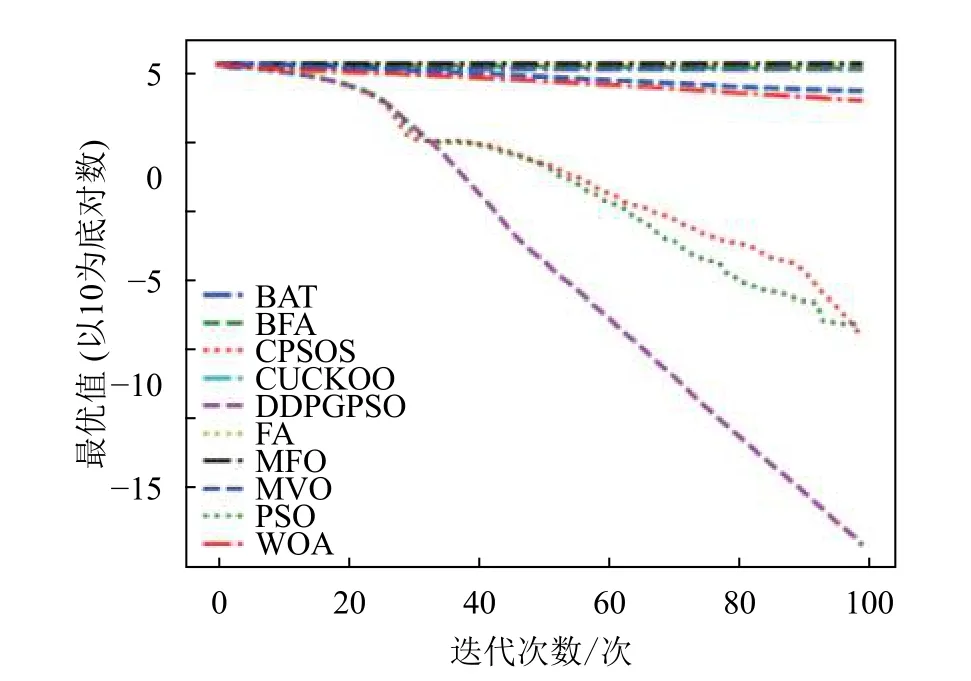
图7 F7 迭代图

图4 F4 迭代图
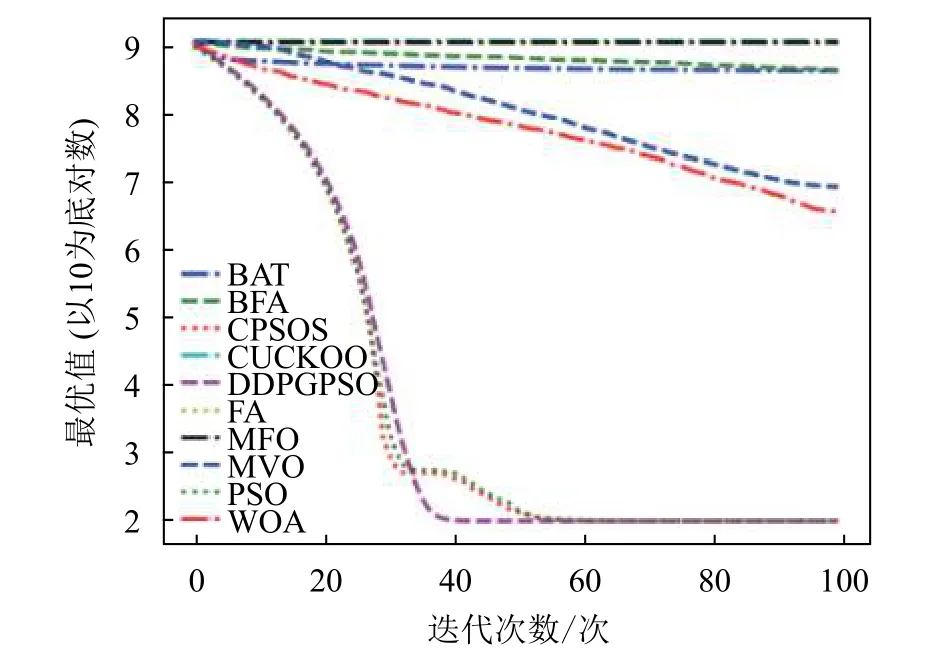
图5 F5 迭代图
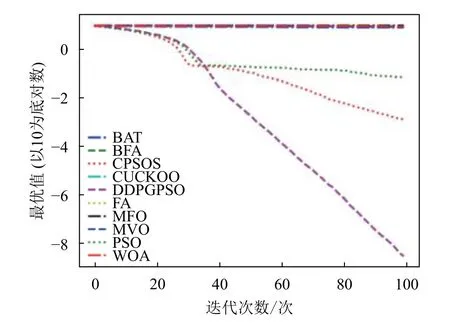
图6 F6 迭代图
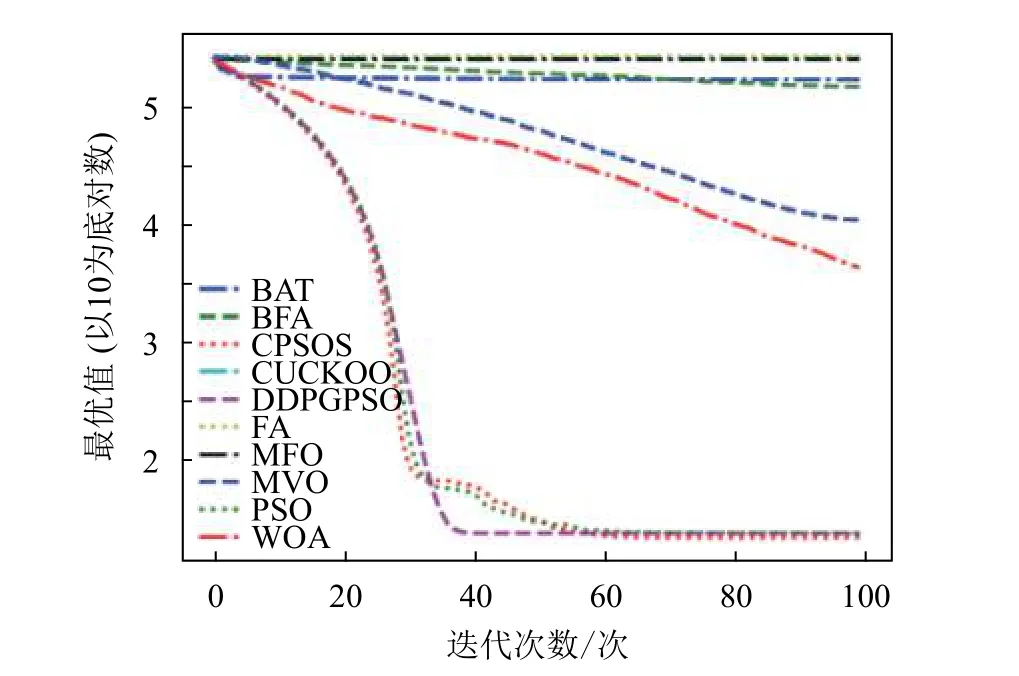
图8 F8 迭代图
表5 为8 种算法在8 个测试函数的实验结果对比,可以看出,DDPGPSO 在F2、F4 函数上直接搜索到了最优值,而在其他函数上虽然没有搜索到最优值,但是与其他算法相比,在寻优精度上也有很大提高,另外,在F5 和F8 中,虽然算法不是第一名,但是所搜索出的最优值与第一名相比较,差距也在10%以内,说明DDPGPSO 在各种情况下的性能都处于较好水平。另外可以看到,CPSOS在多种情况下也优于标准粒子群网络,说明采用人工方式对参数进行一些设定也可以优化算法性能。而DDPGPSO 在大多数情况下优于CPSOS 也证明了机器学习在参数生成方面相较于人工方式的优势。
从图1~图8 可以看出,DDPGPSO 算法相较其他算法在收敛速度上提升明显,另外在多个测试函数中也取得了更好的测试结果。这种结果与强化学习中设定的更快收敛的奖励是一致的。这说明通过强化学习对PSO 进行训练可以显著改善算法的各项性能,同时在多个函数测试项目上也取得了更好的收敛精度。
表6 为DDPGPSO 在不同迭代次数情况下的结果。可以看出,在迭代次数增加到500、1 000 后,DDPGPSO 仍是几种对比算法中最有竞争力的算法,在平均排名和排名第一的百分比两项参数上都有很大优势,也说明了该算法的优越性和强化学习应用于群智能算法的潜力。

表5 实验结果对比
综上所述,基于深度确定性策略梯度算法的粒子群优化算法(DDPGPSO)相较于其他同类别算法具有更高的寻优精度,更快的收敛速度,能够有效解决高维度的复杂数值优化问题。基于强化学习的群优化算法相较于手工设定参数的群优化算法拥有更好的寻优能力与探索能力。
3 结 束 语
粒子群优化算法是模拟鸟群和鱼群的觅食和聚集行为而提出的一种群智能优化算法。本文提出了一种基于深度确定性策略梯度的粒子群算法(DDPGPSO),利用强化学习的手段来自动控制参数的变化,提高了原有PSO 算法的收敛精度和收敛速度。通过测试算法在基准测试函数上的效果,验证了该算法的有效性和可行性,为以后强化学习与群智能算法的结合提供了一种方案。结果表明,同其他 9 种优化算法相比,DDPGPSO 算法求解质量取得了很好的效果。今后的研究工作一方面会通过更多的实验来验证并改进算法的性能,另一方面将探索DDPG 与其他算法结合是否能产生更好的效果。
