基于K-Means聚类的在线学习用户个性化分类
2021-04-08郭飞雁
郭飞雁
湖南电气职业技术学院 湖南省 湘潭市 410000
1 前 言
《教育信息化2.0 行动计划》是加快实现教育现代化的有效途径,是“教育现代化2035”的重点内容和重要标志。教育信息化2.0 行动计划中明确指出,人工智能、大数据、区块链等技术迅猛发展,将深刻改变人才需求和教育形态。如何利用人工智能提供个性化学习环境及服务已成为当前教育研究者关注的焦点[1]。个性化学习研究主要集中在根据学生不同的学习风格、认知风格等为其提供不同形态的学习资源及个性化的教学方法。但在实施个性化教学前对学生进行个性化分类是我们首先需要解决的一个问题。近年来,随着各种在线学习平台的层出不穷,越来越多的研究者将研究重点定位到利用在线学习平台上的大量学习行为数据进行分析,实现基于大数据的在线学习用户个性化分类,从而实现个性化学习资源推送,达到个性化教学的目的[2]。
因此,我们基于在线学习用户相关学习数据,采用KMeans 聚类方法建立在线学生用户模型,进行学生用户进行个性化分类,对不同的学生用户类别进行特征分析,比较不同类学生用户特征,对不同类学生用户提供个性化服务,制作相应学习策略,实现精准推荐学习,因材施教,从而提高在线学习用户参与度,达到在线学习效率最大化目标[3]。
2 在线学习用户IFLPT分类模型
明确在线学习用户分类目标为在线学习爱好特征分类,识别用户分类应用最广泛的模型是三个指标(学习时间间隔(Interval),学习互动频率(Frequency),学习时长(Length),以上指标简称IFL 模型,作用是识别不同类型的在线学习用户。考虑到在线学习资源类型多样化,用户对学习资源类型的个性化偏好在一定程度上影响学习时长,所以增加指标个性 化 偏好P (Preferences)。同时,在线学习用户访问学习资源类别也代表了用户的个人喜好,因此再增加指标访问学习资源类型T(Types)。通过学习时间间隔(Interval),学习互动频率(Frequency),学习时长(Length),个性化偏好P(Preferences)及访问学习资源类型T(Types)以上五个指标,作为在线学习用户分类指标体系,记为IFLPT 模型。
传统的IFL 模型,依据三个属性的平均值进行划分,但由于细分用户群太多,在线个性化教学的成本太高[4]。因此,我们采用聚类法对在线学习用户进行分类,以IFLPT 模型为基础,总体流程如图1 所示。
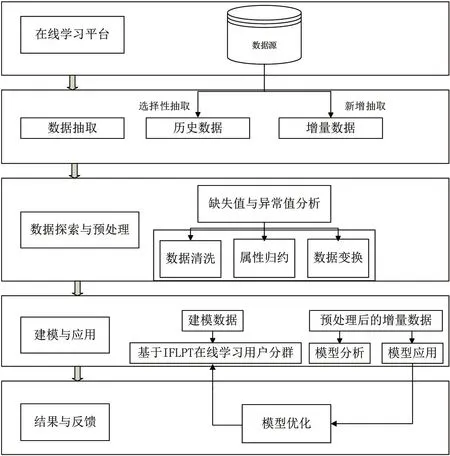
图1 在线学习用户数据挖掘建模总体流程
在线学习用户数据挖掘建模总体流程中,我们首先从在线学习平台选择性抽取已产生数据,并对新增数据进行抽取,形成历史数据和增量数据。对历史数据和增量数据进行数据探索性分析和预处理,主要对有缺失值与异常值的数据进行分析处理,主要操作为属性规约、数据清洗和数据变换。在已处理完毕的规则化数据基础上,建模数据,基于IFLPT 模型进行学生用户分群,对各个用户群进行特征分析,从而实施个性化推荐。
3 基于IFLPT模型的在线学习用户分类
3.1 数据预处理
通过在线学习平台“超星泛雅”导出《网页设计与制作》在线学习精品课程相关数据,选择宽度为1 个月的时间段作为观测窗口,抽取观测窗口内所有在线学习用户的详细数据,形成历史数据,对于后续新增的在线学习用户信息,采用目前的时间作为重点,形成新增数据。在两个数据基础上对数据进行缺失值和异常值分析,查找每列属性值中空值的个数、最大值及最小值,并对数据集进行数据清洗,丢弃空值、学习时长过短或学习频率低的相关记录。同时,由于原始数据中属性太多,根据在线学习用户IFLPT 分类模型,选择与模型相关的五个属性,删除其他无用属性[5]。
通过学习时间间隔(Interval),学习互动频率(Frequency),学习时长(Length),个性化偏好P(Preferences)及访问学习资源类型T(Types)以上五个指标,作为在线学习用户分类指标体系,记为IFLPT 模型。数据清洗完毕后采用数据变换的方式为方便属性构造和数据标准化,将原始数据转换成相应的格式,构造IFLPT 的五个指标如表1 所示。
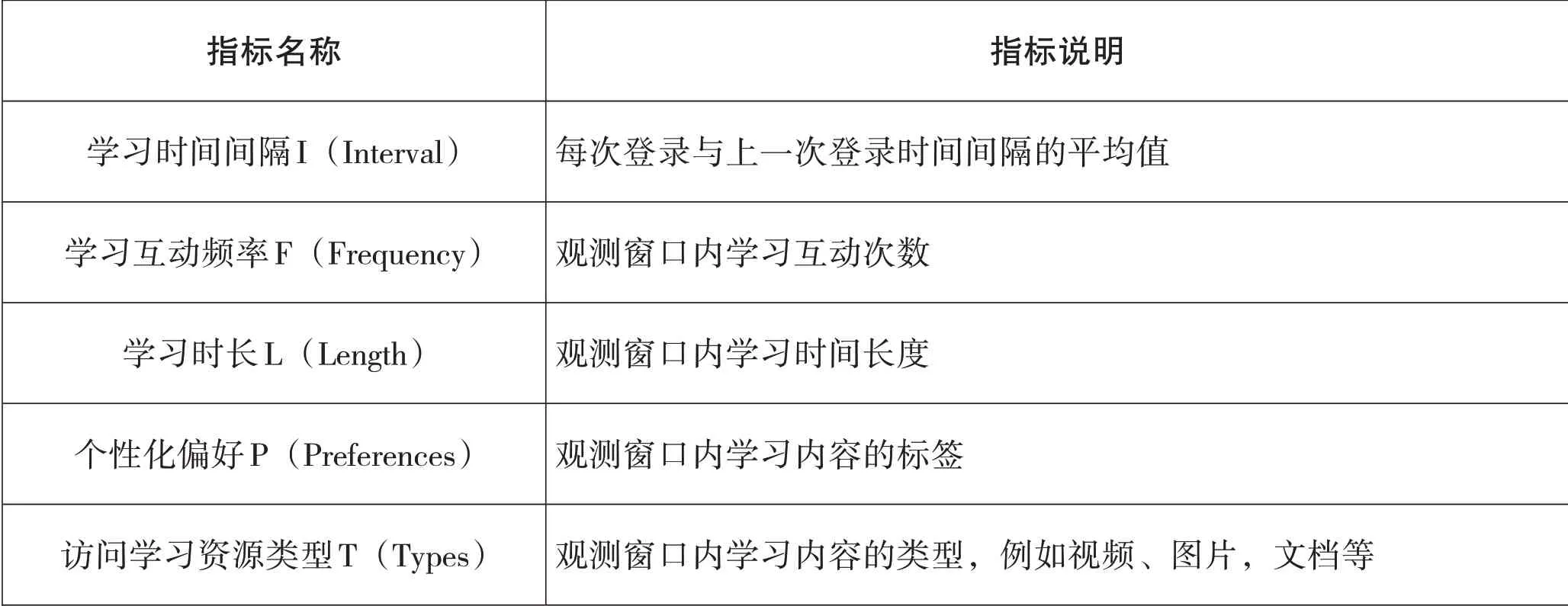
表1 IFLPT 模型指标说明
3.2 IFLPT 模型构建
采用K-Means 聚类算法对在线学习用户数据进行分群,聚成五类,代码如图2 所示。

图2 K-Means 聚类代码
分类结果如图3 所示。用户群1:red,用户群2:green,用户群3:yellow,用户群4:blue,用户群5:purple,横坐标上总共有五个节点,按顺序对应IFLPT。对应节点上的用户群的属性值,代表该客户群的该属性的程度。
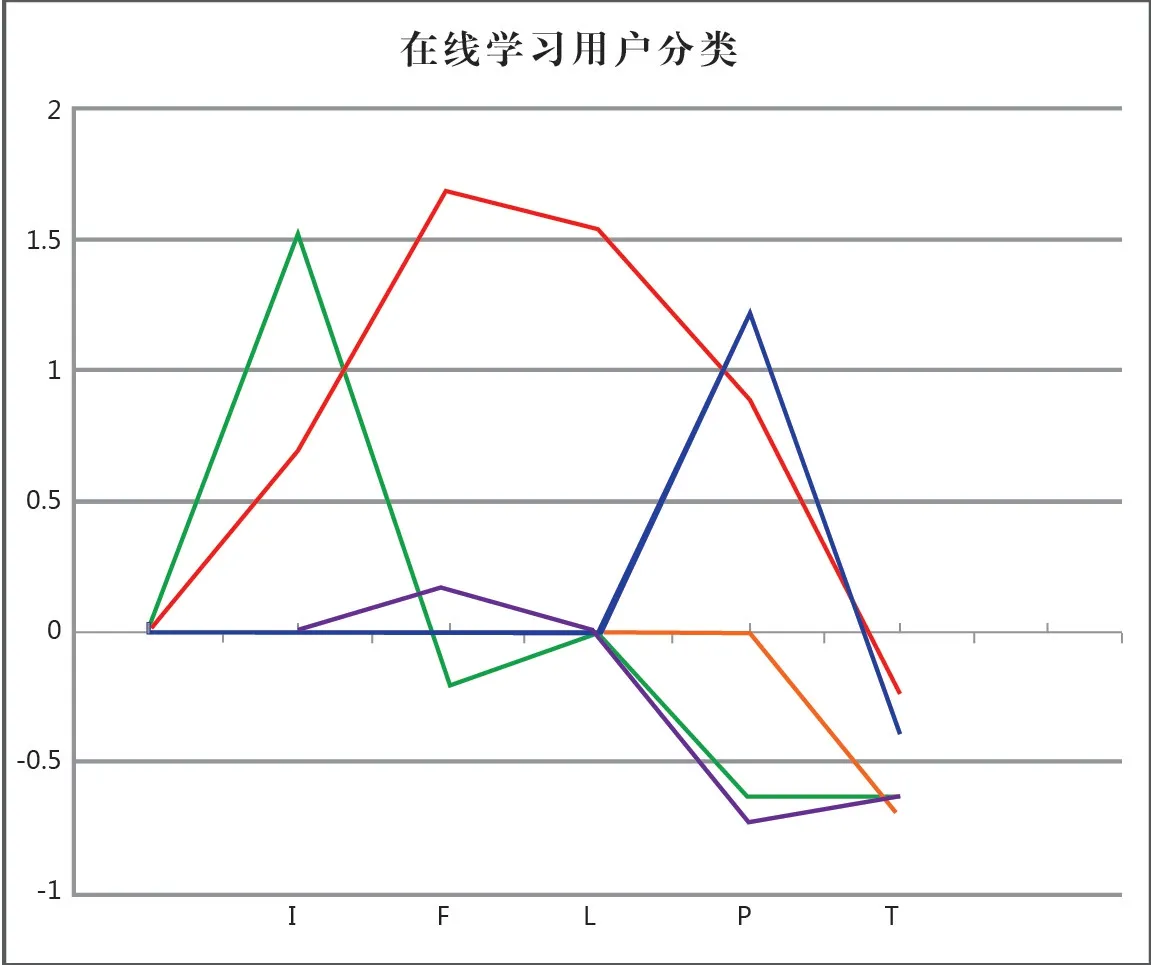
图3 在线学习用户分析
3.3 分类结果分析
我们重点关注I、F、L 三个属性,从图3 中可以看到:红色线代表的用户群1 的I 较低,F、L 都很高,表示该类用户群是学习主动的用户;绿色线代表的用 户 群2 的I 较 高,F、L 都 很低,表示该类用户群是懒散型的用户;黄色线代表的用户群3的I、F、L 值都居中,表示该类用户群会经常登录在线学习平台,但学习时长居中,属于普通型;蓝色线代表的用户群4 的I、F、L 值 都 不 高,但P 值 较高,说明该类用户只对某类学习资源感兴趣,属于专业型;紫色线代表的用户群5 的I 值低表示会经常登录学习平台,但F、L 各类值都较低,属于学习不主动型。
对于不同类型的学习用户群我们采取不同的策略对用户进行在线学习干预实施,从而达到最佳的在线学习效果[6][7]。如表2 所示。
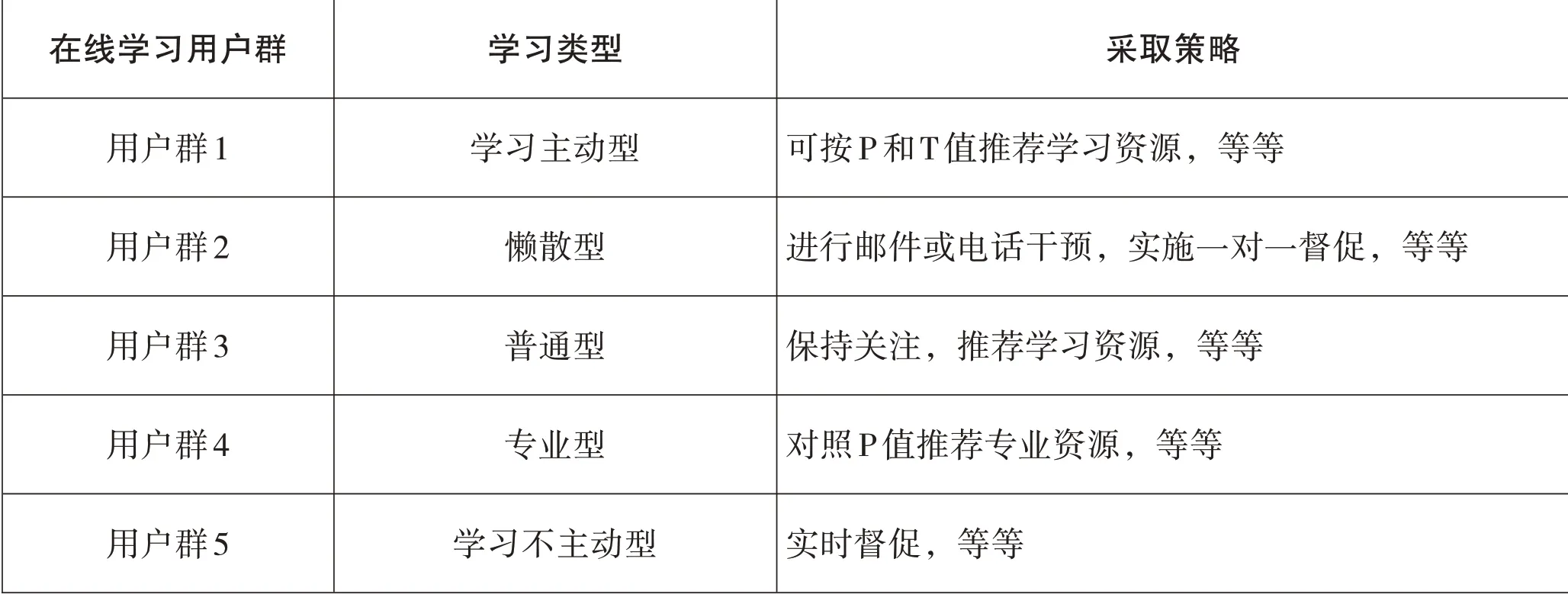
表2 在线学习干预策略
4 小 结
本文结合在线学习平台“超星泛雅”中《网页设计与制作》在线课程案例,重点介绍了数据挖掘算法中K-Means 聚类算法的应用。针对传统IFL模型的不足,结合在线学习案例进行改造,设定了五个指标的IFLPT 模型。最后通过聚类的结果,对在线学习用户进行分类,从而制定相应的在线学习干预策略,提高在线学习效率。
