基于ICA的眉毛识别方法研究
2021-04-07李颜瑞
李颜瑞
(山西机电职业技术学院信息工程系 山西 长治 046011)
1 引言
随着信息技术的发展和互联网的广泛应用,利用人的生物特征作为识别依据,在信息安全领域已经成为一个非常重要的研究课题。目前已经研究的生物识别有指纹[1]、虹膜[2]、掌纹[3]、人脸[4]和眉毛[5]等识别技术。主成分分析方法即PCA已经用在了眉毛识别研究当中,与独立分量分析方法即ICA相比较发现,二者有很多相似的地方。但是独立分量分析方法更具优越性。因为独立分量分析方法不仅考虑了图像或者音频信息的二阶统计信息,而且也考虑了图像或者音频信息的高阶统计信息,生成的特征信息具有独立性。所以,ICA方法同时考虑了二阶和高阶信息,并且特征相互独立,这样提取特征比用PCA提取特征更有利于进行识别。所以,本文使用独立分量分析方法即ICA方法进行眉毛识别的研究。
2 ICA理论
ICA也称为独立分量分析方法[6],是一种基于统计信息的特征提取方法,发源于盲源分离技术,属于线性变换的一种,它是将音频或者图像等信息,通过自己设置的特定函数,生成相应独立分量并且由这些独立分量组成线性组合,这样更有利于提取特征并且能够保持更好的特征向量。

3 基于ICA的眉毛识别方法
3.1 眉毛信息预处理[7]
预处理是生物特征验证和生物特征识别过程中的一个非常重要的步骤,对下面特征提取的好坏有直接的影响。因此,为了提高眉毛的识别率,减小眉毛图像的尺寸等外在因素的影响,应该在特征提取之前进行眉毛图像的预处理。本文决定采用李玉鑑教授提供的原始眉毛库,作为本文的原始眉毛库(图1),并且采用左眉毛作为研究对象,同时圈取出眉毛部分并进行保存(图2)。利用公式
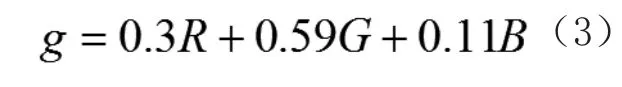
进行灰度化处理(图3),用零阶插值算法对图像进行归一化处理,大小为40*200(图4)。
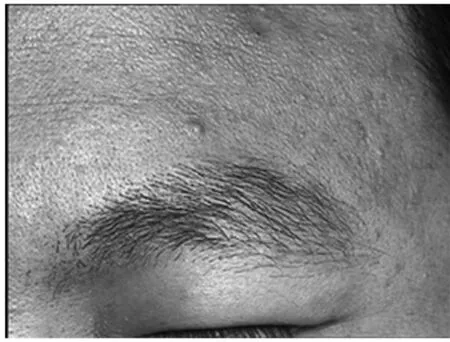
图1
图2
图3
图4
3.2 眉毛特征提取
用于特征提取的图像必须是经过预处理后的图像,否则将会很大程度上影响特征提取的结果,所以必须在预处理的基础上再进行特征提取。


3.3 眉毛识别
近邻法[8]则是一种根据样本提供的信息,绕开概率的估计而直接决策的技术,所以它也属于非参数判别方法的一种。在特征提取的基础上,研究采用K-近邻方法进行识别。
(1)将训练集眉毛图像的特征向量,都存储起来共同构成训练集眉毛图像的特征库。
(2)计算训练集眉毛图像特征库中特征间的最大欧式距离的一半,即眉毛间的最大许可距离记:dmax。
(3)计算测试眉毛特征与训练集中的眉毛特征之间的距离,记为为眉毛库中特征个数。
4 实验结果分析
实验是建立在50人的眉毛库上,每人提供6张眉毛组成眉毛库,则眉毛库共有300张眉毛图片。实验中,每人选取三张作为训练眉毛,剩下三张作为测试眉毛,则训练眉毛有150张,测试眉毛有150张。共进行了三次实验,实验结果如下。
4.1 不同的眉毛库对识别率的影响
见表1所示。

表1 不同的训练库
4.2 比较近邻法则与k近邻法则对识别率的影响
见表2所示。

表2 近邻与k近邻
5 结语
本次研究采用基于ICA的眉毛识别方法在50人的眉毛库上取得了较好的识别效果,再一次证明了使用眉毛这一生物特征用于识别是完全可行的。但是本次研究仍有一些不足之处和需要加强改进的地方。例如预处理阶段仍然采用人工的方式进行提取眉毛区域,没能实现自动化,在眉毛识别的研究推广应用上,就存在一定的障碍和阻力;眉毛库的数量还是比较有限,而目前仅仅是在实验室中完成的,如果是在现实应用中,估计还有其他问题出现;所以今后的研究重点应该是眉毛区域的自动提取方法和建立大规模且合格的眉毛数据库。
