基于引文全文本的医学领域突破性文献识别研究*
2021-04-07杨雪梅林紫洛关陟昊唐小利
王 雪 杨雪梅 林紫洛 关陟昊 唐小利
(北京协和医学院/中国医学科学院 医学信息研究所 北京 100005)
Research on Identification of Medical Breakthrough Articles Based on Citing Sentences
Wang Xue Yang Xuemei Lin Ziluo Guan Zhihao Tang Xiaoli
(Peking Union Medical College/Chinese Academy of Medical Sciences, Beijing 100005)
Abstract:[Purpose/Significance]From the citing perspective of the academic community, based on the citing sentences, and word frequency statistics, deep learning, etc., the paper explores the text features that represent breakthrough evaluations in the citing sentences and builds an automatic recognition model to identify potential breakthrough articles. [Method/Process] The authors selected the key publications of the Nobel Prize winners in Physiology or Medicine and the representative articles of Science Breakthrough of the Year as the gold standard breakthrough articles collection and obtained their citation sentences. Word frequency statistics combined with manual screening were carried out to obtain common words that characterize breakthrough evaluation. The authors manually labeled the citing sentences and used BERT and BIOBERT models for training to form automatic recognition models, and finally selected the cancer field for empirical analysis. [Result/Conclusion] The results show that there is obvious textual characteristics when evaluating literatures with great breakthrough value. Compared with the BERT model, the recognition ability of BIOBERT model was improved, with F1 value of 0.84. The automatic recognition model based on citing sentences can accurately identify the literature with important academic value and realize early recognition and early evaluation to a certain extent.
Keywords:citing sentences;deep learning;breakthrough articles;automatic identification;text classification;textual characteristics
科学的重大进展在很大程度上取决于突破性的科学发现[1]。目前,世界各国政府和科研资助机构已对优先发展主题领域或前沿领域投入大量资源和资金支持,特别是突破性研究和变革性研究,以期促进科学发展。早在2007年,美国国家科学委员会就提议加强对变革性研究的支持[2]。近年来,美国国立卫生研究院专门为变革性研究设立资金资助(Transformative Research Award),旨在支持“具有创造或推翻基本范式潜力的异常创新和/或非常规研究项目”[3]。我国在十九大报告中提出加快建设创新型国家,指出要瞄准世界科技前沿,强化基础研究,实现前瞻性基础研究、引领性原创成果重大突破,其中一个重要方面就是加快推进基础研究领域突破性、颠覆性创新的遴选和培育[4]。尽管各国都已逐步建立资助政策和研究基础设施以激励和促进突破性研究的发展,但最初选择和资助的提案是否最终会成为一项突破性研究仍然是一个重要且不可避免的挑战。
本研究尝试从科学共同体的定性描述出发,结合深度学习等方法,实现从海量文献中自动识别潜在突破性文献。潜在突破性文献的识别,可以为科研人员的研究方向以及资助机构的重点资助方向提供参考,促进潜在突破点、突破性技术的大力发展,同时帮助科研人员准确锁定研究领域中的突破性进展;引用语句体现着学术共同体在引用原始文献时的评价态度,基于引用语句识别潜在突破性文献,丰富了传统学术评价的内容,为基于引用语句实现论文评价提供了新的运用实践。
1 相关研究
1.1突破性文献识别目前,国内外已有关于突破性文献识别的相关研究成果,研究方法各有不同,主要包括以下两个方面:一是基于学术共同体的定性识别,通过定性评价以确定该文献是否为突破性文献,另一种是基于科学计量学定量识别潜在突破性文献[5]。
同行评审仍是识别突破性文献的有效精准方式之一,例如诺贝尔奖、Science十大科学突破、MIT十大科技突破。此方法可以全面地考察每一篇论文,识别结果较为精准,但是具有费时费力、主观性强的缺点,并且同行评议一般只能在少数几个同行专家中展开,得出的结论容易具有片面性[6]。
另一种是基于科学计量学的定量识别。目前有研究人员探索突破性文献是否有特异性指标。例如Ponomarev等[1]使用单一指标——引文速度,来预测潜在突破性论文,而Wolcott等人[7]使用时间依赖性和非依赖性的多维组合指标以区分金标准突破性文献集以及对照组文献集。引用网络建立在文献引用关系的基础上,是知识传承和流动的体现,突破性研究的出现常常表现为引发传统研究范式下引文链的改变或“破裂”,故Huang等[8-9]提出用引文链的“破裂分数”来识别突破性研究。Schneider等[10]提出3种基于引用分析的方法从高被引论文中检测潜在的突破性研究。常规科学中的渐进性研究累积到一定临界点时,科学突破导致范式转变,进入一种新的研究范式下的常规科学,继而循环往复。对于突破性研究的识别是对这些临界点的预警信号的研究。因此荷兰莱顿大学学者提出了突破检测算法,基于科学结构本身的变化,早期检测对科学发展有重要影响的新发现[11]。随着引文全文本的可获得,目前研究人员在外部特征分析的基础上结合文本内容特征以识别科学发现。例如郭倩影[12]等基于引用强度、引文网络、引用时长和引用内容四个维度识别构成学术传承中的关键文献,其中在内容分析中选择以“first*”“breakthrough”“landmark”“originally”“classical”等词作为标志性评价词汇作为判断标识;Small等[13]提取带有提示词“*discover *”的“发现引用语句”及其参考文献,并筛选出具有一定数量“发现引用语句”的文章,将含有20个以上“发现引用语句”的文献进行人工筛选识别出表征科学发现的文章。上述文献有效证明了可以利用引用语句来识别被引文献的内在价值,同时也证明文本特征在从大量出版物中快速识别关键文献的重要作用。
论文的被引需要时间的积累,因此无论是基于引文指标的识别,还是基于引文网络的识别抑或引用内容分析识别都存在滞后性。但相较于需要较多时间来形成特定的引文模式,文本特征出现得更快也更加明显,因此基于引用内容的识别可以相对较早地识别潜在突破性研究。
1.2基于引用语句的文本分类引文全文本,即引用语句,是指文献全文中包含一个或多个参考文献标识符且引用参考文献部分内容或对参考文献进行评论性描述的语句。基于引用语句可以实现论文影响力评价、揭示研究贡献点等。传统引文指标在评价论文时忽略作者在引用参考文献时的情感因素(如负面引用),导致传统指标无法真正反应论文的影响力[14]。因此有学者通过对引用语句的引用极性进行分类,从中识别表达正向情感的引用语句,以此弥补单纯依赖传统引用指标来评价文献学术影响力的不足[15-16];或对引用功能进行分类,揭示不同的引用动机从而反映引用价值[17];或从中识别有意义且重要的引用语句,揭示原始文献的贡献点所在[18-19]。
与标题、摘要和关键词等文献信息不同,引用语句记录了知识流动的细节,而被引用的信息和创新点也是被同行学者普遍认为重要的,因此有价值的引用语句可以真正体现论文对科学发展的重要意义。引用内容的特殊意义为突破性文献的识别提供新的思考和方向。
1.3引用语句获取关于引用语句的获取,有部分研究者通过人工阅读原始研究的施引文献并手工提取对应的引用语句[20],或者利用自然语言处理技术从全文中抽取引用内容进行分析[21-23]。上述研究得到的引用语料都是根据特定研究需要而“定制”,只适用于特定场景的分析。除此之外,计算语言协会 (Association for Computational Linguistics,ACL)提供的网络语料库选集ACL Anthology Network (AAN)[24]包括引用语句,可供计算语言学和自然语言处理领域的研究人员不同研究需求。同时,国外已有研究人员对如何提取引用语句进行探索并开发相应的数据库供科研人员使用,例如Colil[25]、Semantic Scholar[26]、SciRide Finder[27]。相较于传统搜索引擎如PubMed、Web of Science、Google Scholar等,其显著区别是通过数据库检索可以获取后续发表研究对原始研究的评论性描述。Colil是基于PMC OA文献集构建的生物医学领域的引用语句文本库,可通过文章的PMID号获取对应文献的引用语句。本研究拟选择Colil实现引用语句的批量获取。
2 数据来源与方法
本研究提出一种基于引用语句结合深度学习算法识别医学领域潜在突破性文献的方法,并构建自动识别模型和对模型领域进行实证研究。方法路径如图1所示。

图1 医学领域潜在突破性文献自动识别模型构建及实证研究方法路径
2.1金标准突破性文献集的确定识别潜在突破性文献的首要任务是确定一组核心出版物作为金标准集,并基于施引作者在引用这些文献做出的描述性评论语句来探索突破性评价情感及语言学特征。然而由于目前生物医学领域论文数据爆发式的增长,个人难以从大量的文献中确定标准集且个人的筛选存在偏倚。因此,本研究借鉴已有的学术共同体对论文的评审结果,纳入诺贝尔生理学或医学奖获得者的关键文献(1981-2019年)以及Science 10大科学突破主题的代表文献(医学领域,1996-2019年)作为突破性文献的金标准文献集。共计644篇文献。通过Colil数据库获取644篇的引用语句,约16万条。
以PMID为12 466 850的一条引用语句为例,如例1,其施引文献是PMID为19 468 303的文献。其中>> <<表示目标文献,即PMID为12 466 850的文献,该篇文献在施引文献(PMID:19 468 303)中为第11篇参考文献。
例1:In late 2002, we published a draft mouse genome assembly, referred to as the MGSCv3, of a single, inbred strain (C57BL/6J, or “B6”) [>>11<<]. This publication marked a watershed in mammalian genetics and genomics, as it allowed the first genomic comparisons between mouse and human.
2.2突破性评价文本特征的提取为探索学术共同体在引用突破性文献时是否存在语言学特征,本研究利用Standford CoreNLP工具对上述644篇突破性文献的引用语句进行分词及词频统计,明确是否存在表征突破性评价的特征词。为降低特殊字符对分词造成的影响,进行分词之前对每条引用语句进行预处理,删除每条语句中的特殊符号(如= - * : " ' — ! ~ & √等)及数字(0,1,2,3,4,5,6,7,8,9)。从具有一定词频的候选特征词中筛选出常被施引作者用来评价突破性文献的精准特征词。由于英文单词存在一词多义的特点,因此提取出包含上述任一候选特征词的引用语句进行人工标注,表征突破性意义的标为1,无突破性意义的引用语句标为0。标注规则如表1。将标注结果按以下公式作比,比值越高,表明该词表征突破性评价意义的概率越大。将比值≥50%的词作为突破性评价精准特征词。
比值=
2.3医学领域突破性文献识别模型的训练从金标准突破性文献的全部引用语句中随机抽取20%的数据进行人工标注并构建自动识别模型。在人工标注过程中,按照表1中的规则进行标注,将表征突破性意义的标为1,无突破性意义的引用语句标为0。利用通用领域模型BERT[28]以及生物医学领域特异性模型BIOBERT[29]自动学习其语义特征与人工标注标签之间的关系。
2.4癌症领域潜在突破性文献识别与评价癌症是当前危害全球人类健康的重大疾病之一。近年来,癌症领域的基础研究与临床转化均取得显著进展,例如癌症靶向药物、疫苗研发、AI应用等。本研究以近5年发表的癌症领域相关文献为例开展实证分析。分别通过PubMed数据库(检索策略:"Neoplasms"[Mesh],Filters applied: Journal Article, from 2015/1/1 - 2019/12/31)、Colil数据库获取得到约58万篇文献题录、200万条引用语句。选择最优模型进行实证分析并选取两个指标——F1000数据库以及美国临床肿瘤学会发布的年度进展报告(Clinical Cancer Advances: ASCO’s Annual Report on Progress Against Cancer)对识别结果进行评价。F1000数据库是全球顶尖基础研究学者与临床专家甄选生物学与医学领域中最重要的论文及动向的数据库,并对其进行分类及评估。美国临床肿瘤学会每年发布的癌症临床进展报告强调了过去一年癌症领域中最具影响力的研究进展,并确定了癌症领域的未来优先发展事项。如果模型识别出的文献被F1000数据库或癌症临床进展报告收录则证明该模型可以识别出具有重要价值的文献。基于上述指标对识别结果进行评价。

表1 引用语句标注规则
3 结 果
3.1突破性评价文本特征通过对金标准突破性文献集的约16万条引用语句进行分词及词频分析,从中提取出88 166个词。其中冠词“the”的词频最高,词频为353 596。词频大于等于1 000的共有940个词,仅占总词数的1.07%;词频在1-5之间的词数最多,高达71.80%(见图2)。
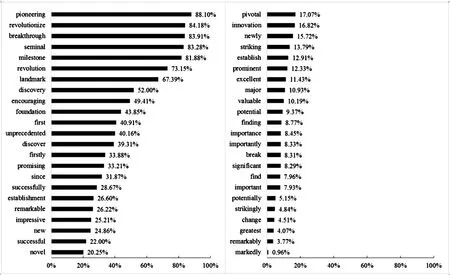
图2 不同词频范围的词个数占比统计
通过对特征词的筛选可以发现学术共同体在评价高价值文献时常用的词汇。为保证特征词筛选的概率意义,本研究从词频大于等于100 的词(共4 642个词,占比5.27%)中最终确定46个候选突破性评价特征词。含候选特征词的引用语句共有54 890条,占全部引用语句的33.57%,涉及522篇金标准文献。对包含候选特征词的引用语句按照标注规则进行人工标注,其作比结果如图3所示。含有“pioneering”的引用语句中有88.10%被标注为“1”,反映含有该词的引用语句具有88.10%的可能性被认为具有突破性评价意义。当某一候选特征词的比值大于等于50%,则表明含有该词的引用语句至少具有50%的可能性被评为突破性评价引用句,如“pioneering”“revolutionize”等。比值为50%以上的特征词元及还原前的词如表2所示,这些词可以被认为是常用来评价潜在突破性文献的精准特征词。

图3 候选特征词被判别为具有突破性评价意义的概率

表2 突破性评价文本特征词元及原词
3.2突破性文献自动识别模型从16万条引用语句中随机抽取20%的数据构建自动识别模型,其中标签为“1”的引用语句共有1 994条,标签为“0”的共有30 708条,比值为1∶15。模型训练结果如表3所示。由于训练集中正负样本数量差距悬殊,BERT以及BIOBERT模型对负样本识别能力优于对正样本的识别,但BIOBERT模型对正样本的识别能力相较于BERT有明显提高(F1=0.70)。总体而言,生物医学语言表示模型BIOBERT鲁棒性较好,对正负样本的识别能力均有所提高,总体F1值为0.84。

表3 BERT、BIOBERT模型训练结果对比
3.3癌症领域识别结果分析与评价利用基于BIOBERT的引用语句模型进行预测,共15596条引用语句被预测标注为“1”,即被认为具有突破性评价意义,对应10986篇原始文献。预测标注为“1”的引用语句数量最多的文献(67条)是2015年发表的题为“The future of immune checkpoint therapy”的综述,该篇综述总结了目前癌症免疫治疗的重大进展。然而综述、评论、指南、系统综述、meta分析的特点是对先前研究进行评论和系统评估,并不代表原创性的创新研究或重大突破。因此,后续将不对上述文献类型进行分析。同时由于深度学习模型识别结果存在误差性以及施引作者在引用参考文献时存在主观偏倚性,设置突破性评价引用语句的数量可在一定程度上弥补此缺陷。将具有2条及以上突破性评价引用语句的文献作为潜在突破性文献并对此进行分析。
2015年发表的潜在突破性文献最多,共有477篇,2019年发表的最少仅8篇(见图4)。对各年发表的具有突破性评价语句最多的TOP5文献基于指标进行评价,其结果如表4所示。每年发表的具有突破性评价语句最多的TOP5文献均被F1000数据库收录或被提名收录,多数被推荐为“New Finding”,表明是创新性的研究;其中有13篇被ASCO癌症临床进展报告收录。从评价结果可以看出,模型识别出的2015年、2016发表的文献几乎均同时被F1000数据库及ASCO癌症临床进展报告收录,而2017-2019年发表的文献只有少数同时满足两个指标,这表明发表较早的文献其识别结果更加精准。但该模型在一定程度上仍可以实现早期识别(例如PMID30665869、PMID30645973)。
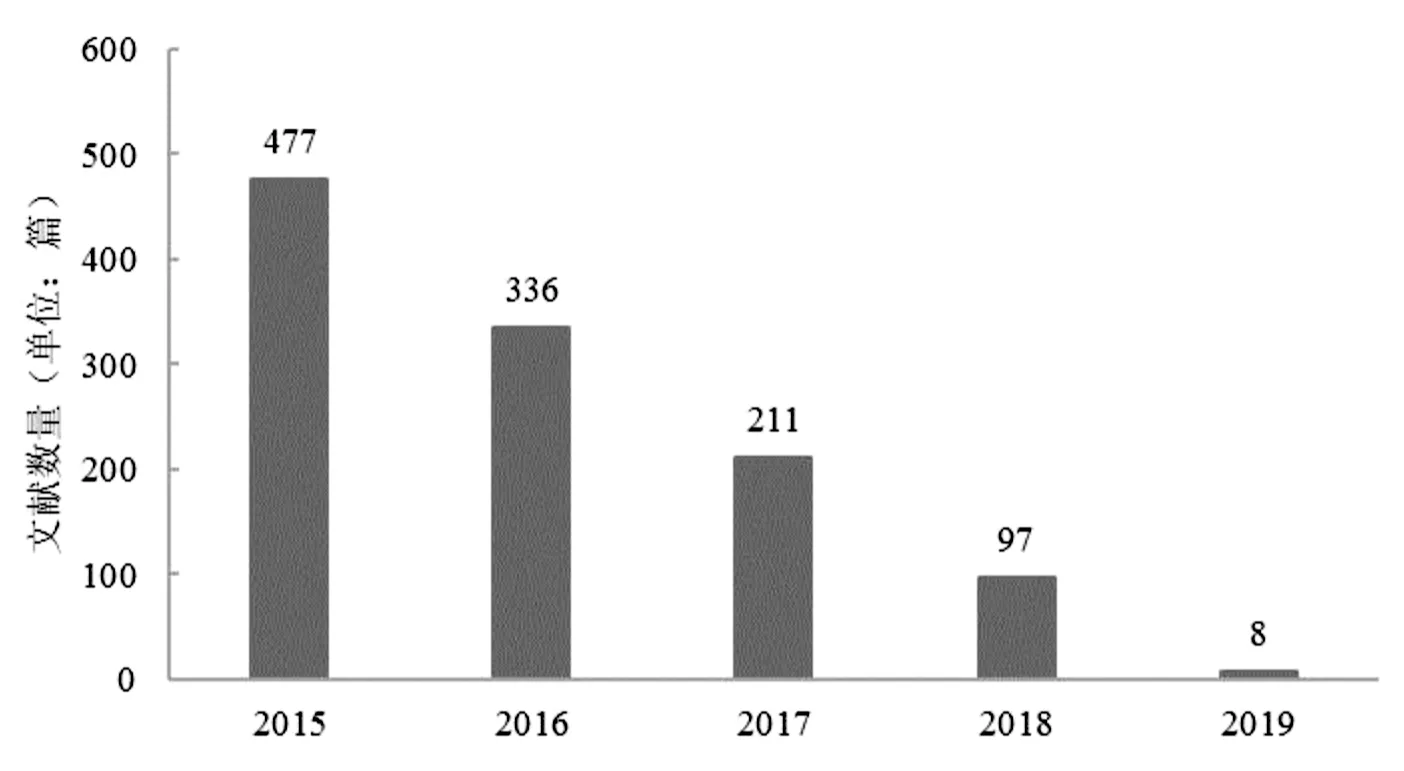
图4 癌症领域潜在突破性文献年度分布

表4 2015-2019年每年发表的具有突破性评价语句最多的TOP5文献基于指标的评价结果

续表4 2015-2019年每年发表的具有突破性评价语句最多的TOP5文献基于指标的评价结果
4 总结与展望
本文以医学领域为例,选取诺贝尔生理学或医学奖获得者的关键文献以及Science十大科学突破主题的代表文献(医学领域)作为金标准突破性文献集,探析学术共同体在引用具有重大突破价值的文献时是否存在显著的文本特征,同时基于引用语句的评价情感结合深度学习的文本分类功能,实现对潜在突破性文献的自动识别。
在研究中发现,学术共同体在评价具有重大突破价值的文献时具有明显的文本特征,“pioneering”“revolutionize”“breakthrough”“seminal”“milestone”等是施引作者常用来评价高价值文献的精准特征词,共有322篇金标准文献的引用语句含有上述特征词。同时在模型训练的标注语料中,27.5%被标注为“1”的引用语句含有精准特征词,86%的引用语句含有候选特征词,反映具有突破性评价意义的语句中具有明显的文本特征,因此在后续研究中可以在模型训练过程中提升特征词的权重,优化模型的识别能力。本研究识别出的精准特征词可用于构建检索式发现潜在突破性文献,并为检索词的选取提供了依据,特别是在引用语句检索中具有较大应用价值。本研究基于引用语句的评价情感结合深度学习模型以实现潜在突破性文献的自动识别,为识别突破性文献、文献评价提供了新的例证、方法和思路。对BERT、BIOBERT模型的训练结果进行对比分析发现,BIOBERT对潜在突破性文献的识别能力(F1=0.84)优于BERT的识别能力(F1=0.82),证明基于PubMed摘要和PMC全文文章训练得到的BIOBERT模型在处理生物医学文本分类任务中优于通用领域BERT模型,为后续开展生物医学文本分类任务提供了参考和例证。
在模型实证分析中,选择癌症领域作为实证领域,利用BIOBERTT模型识别该领域的潜在突破性文献并基于是否被F1000数据库收录、被ASCO癌症临床进展报告收录作为指标对识别结果进行评价。其结果表明,基于引用语句的自动识别模型能够识别具有重大突破性价值的文献,但识别效果在很大程度上仍依赖于文献发表时间或者是引用语句的数量,引用语句越多,其积累的突破性评价语句越多,用以区分非突破性文献的特征就越明显,则被判别为潜在突破性文献的概率越大。同时实证研究也验证基于引用语句的自动识别模型具有早期识别的能力。例如表4中于2019年发表的文献,尽管其只有少量的引用语句,但是该模型仍能从具有有限引文次数的文献中识别出具有重要价值的文献,证明基于引用语句的识别方法可以实现重要文献的早期识别和文献早期评价。
本研究是识别潜在突破性文献的有效尝试但仍有局限性。首先本研究提取的突破性评价特征词仅为单个词,忽略表征突破性评价的短语如“first discovery”“breakthrough research”。相较于单个特征词的多意性,短语词组更加精准。后续可开展突破性评价特征词组的识别。此外,针对模型的实证分析,本研究仅选择癌症领域开展研究。虽然证明该识别模型在癌症领域中的适用性,但模型在其他领域的迁移能力有待验证。最后,引用语句的来源存在局限性。Colil数据库是日本国家生命科学数据库中心基于PMC OA文献集开发的,而PMC-OAS文献集[30]仅约占PubMed数据库[31]中所有出版物的9.2%。因此通过Colil数据库获取得到引用语句数量十分有限。引用语句数据不全会对实证研究结果造成影响。
