基于图数据库的传染病高风险人群防控系统研究
2021-04-06李剑温海燕张恒
李剑 温海燕 张恒
随着交通多元便捷,大规模人口的流动更加广泛和快捷,激活了传染病传播网络中的长程链接,导致传染病的扩散更加迅速,严重影响了传染病的防控。本文的研究采集某种传染病确诊病人及疑似病人的传染病史、病历数据和亲缘、人口家庭关系数据,综合运用图模型及相关数据库平台、图查询语言等技术,建立满足传染病防控工作的人员及其亲缘关系图模型,实现现有人口家庭系统数据模型到图数据模型的转换及高风险人群的快速定位,对政府和主管部門决策辅助支持具有重要的意义。
大规模的人口的流动激活了网络中的长程链接,使得传染病的防控任务更加艰巨。传染病的爆发和发展变化、医疗卫生资源的调配和部署还缺乏大数据支撑,这也给传染病防控工作带来了诸多挑战。传染源和传播途径是传染病流行的重要环节,“控制传染源,切断传播途径”成为传染病防控重要措施,需要快速的筛查传染病患者的密切接触人员这类高风险人群,避免传染源增多,此类筛查需要重点对关联关系数据进行分析。目前的诸多卫生信息系统大都采用传统关系模型,加之流行病学调查数据量大,且常使用手工填报非结构化的数据,这都不利于快速开展关联关系查找分析。图数据库作为一类数据存储管理平台,更适合存储分析事物间的关联关系,已在社交网络、通信网络等领域广泛应用。如果能基于图数据库,依托传染病患者、疑似病人的传染病史、病历数据和亲缘、姻缘关系等数据,构建基于图模型的亲缘姻缘关系,结合主索引关联个体病人的电子健康档案和历史就诊记录,对病人的传染病暴露风险进行分级评估,将给予政府和主管部门决策辅助支持具有重要的意义。
一、图数据库概述
(一)主流图数据库介绍
在计算机科学中,图数据库(Graph Database,GDB[)是一个使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。该系统的关键概念是图,它直接将存储中的数据项,与数据节点和节点间表示关系的边的集合相关联。
目前,据维基百科统计,主流的图数据库有十多种,例如Neo4j是一个基于Java实现,兼容ACID特性的开源图数据库;FlockDB是Twitter为进行关系数据分析而构建的图数据库;InfiniteGraph是一个分布式的图形数据库,已被美国国防部和美国中央情报局所采用;HugeGraph是百度开源的分布式图数据库,可支持千亿级规模关系数据;ArangoDB是一个原生多模型数据库,兼有key/value键/值对、Graph图和document文档数据模型,该数据库采用了试用于所有数据模型的统一内核和统一数据库查询语言,无需在不同数据模型间相互“切换”,也不需要执行数据传输过程。
(二)关系型数据库与图数据库关联关系查询效率比较
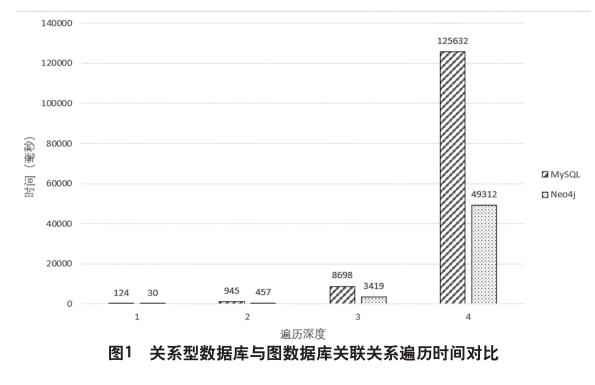
关系型数据库的数学理论关系代数将实体本身的属性元组视为关系,实体间的关联关系通过指定键值的连接运算实现,这就意味着在查找实体间关联关系时,将进行大量的连接操作,其中需要进行集合间的笛卡尔积运算和选择、投影运算,消耗大量的计算、存储资源,随着数据量的增加,运算效率急剧下降。图数据库运用数学理论图论将数据组织为属性图,将实体及其属性视为节点,实体间的关联关系视为边,相关类型属性视为标签,实体间关联关系的查找通过图的遍历即可实现,指定实体的关联关系与节点数量无关。文献以MySQL关系型数据库和Neo4j图数据库为实验环境,100万节点,300万边数据量的不同深度遍历进行了比较,结果通过对比关联关系查询时间发现,在深度为1~2时(即一对一映射),无论关系型数据库还是图数据库,在查询时间方面都表现得足够好。随着深度的增加,关系型数据库查询时间呈指数级增长,然而图数据库却仍然能在较短的时间内完成查询任务。显然,关系型数据库在所擅长的方面有很好的技术能力,但在管理关联数据时却无能为力,特别是任何超出寻找直接关系或是寻找2级间接关系这样的浅遍历查询,都将因为涉及的索引数量而使查找变得缓慢。在社交数据中递归搜索关联关系这类应用中,图数据库Neo4j所需要计算的数据量远小于关系型数据库,性能要比关系数据库(MySQL)更好,因为它可以遍历给定的社交图。图遍历需要更多的子查询,查询应该更复杂。另外,由于关系模型的原因,关系数据库必须在查询中执行几个子查询,这相当于在图形数据库中执行指数查询比在符号查询中执行更多的查询,因此执行时间比查询数据库更长。图形数据库无论在性能、建模和维护方面都能迅速响应。因此,可以将图数据库视为比关系数据库更好的数据库,如图1所示。
二、患者亲缘关系图模型研究
患者的直系亲属和家庭成员作为其密切接触人员,该人群大概率是传染病的高风险人群,所以快速查找患者的亲缘关系人员是本课题的重要内容之一。所在地区经过多年积累,已建成人口信息数据库,用于支撑日常人口事务管理的业务工作,但其数据存储和管理主要依赖传统的关系模型。关系模型有着严密的关系代数数学理论支撑,相应的数据库历经多年研究,能够稳定高效的支撑业务管理工作,但随着人口数据的不断增加,传统的关系模型在关联事物查找、事物间关系的发现和分析方面效率不足的问题日益凸显,特别是数据量达到一定规模后,查询效率急剧下降。为快速筛选确诊患者密切接触人群,以图论为基础理论,综合运用图模型及相关数据库平台、图查询语言等技术,建立满足防疫工作的人员及其亲缘关系图模型,实现现有人口家庭系统数据模型到图数据模型的转换,实现高风险人群的快速定位。
(一)患者亲缘关系图模型转换步骤
基于图论的图数据模型可以定义为G=(V,E){V=vertex,E=edge},V表示顶点(Vertex)的集合,E表示边(Edge)的集合,以及两者相关的一些属性信息。相应的图数据库,在高效分析大数据关联关系方面优势明显,在关联事物查找方面甚至可以达到O(1)效率。因此,为快速发现患者的亲缘关系人群,需要对现有基于关系模型的亲缘关系数据进行数据模型转换,使之转换为图数据模型。经过研究分析,结合现有亲缘关系数据库的实际,通过建立视图辅助,将人口信息数据库中的人映射到图数据库中的顶点,将人的亲缘关系映射到图数据库中的边,有关数据列映射为顶点或边的属性,实际转换方法如下:
1.以传染病患者的唯一标识Id作为初始集合filter_id_set,作为在亲缘关系中筛选的初始条件;初始化人员关系集合personEdge_set={};
2.执行筛选,得到筛选出的关系人的唯一标识集合tmp_id_set和相应的人员关系以及相应属性集合tmp_presonEdge_set;
3.将tmp_id_set加入到filter_id_set中,作为第二次筛选的条件;同时将tmp_presonEdge_set加入到边集合personEdge_set中;
4.重复步骤(2),直至(人员关系是双向关联关系数据);
5.以filter_id_set作为在家庭关系中筛选的初始条件;
6.执行筛选,得到筛选出的家庭唯一标识集合filter_familyId_set和相应的人员家庭关系以及相应属性集合personFamilyEdge_set;
7.以filter_familyId_set作为在家庭关系中的筛选条件,对家庭关系再次进行筛选,得到筛选出的家庭关联人的唯一标识集合tmp_id_set和相应的家庭人员关系以及相应属性集合tmp_personFamilyEdge_set。(筛选出家庭(户籍)中非直系亲缘关系,如侄儿(女)、过继等。)
8.将tmp_id_set加入到filter_id_set中,得到所有患者的所有亲缘关系人;将tmp_personFamilyEdge_set加入到personFamilyEdge_set得到所有患者相关的家庭人员关系。
通过上述步骤,得到所有患者的亲缘关系人员(顶点)集合filter_id_set,所有亲缘关系(边)集合 personEdge_set,家庭(顶点)集合filter_familyId_ set,家庭人员关系(边)集合personFamilyEdge_set。
(二)基于图数据库的患者亲缘关系图模型展示
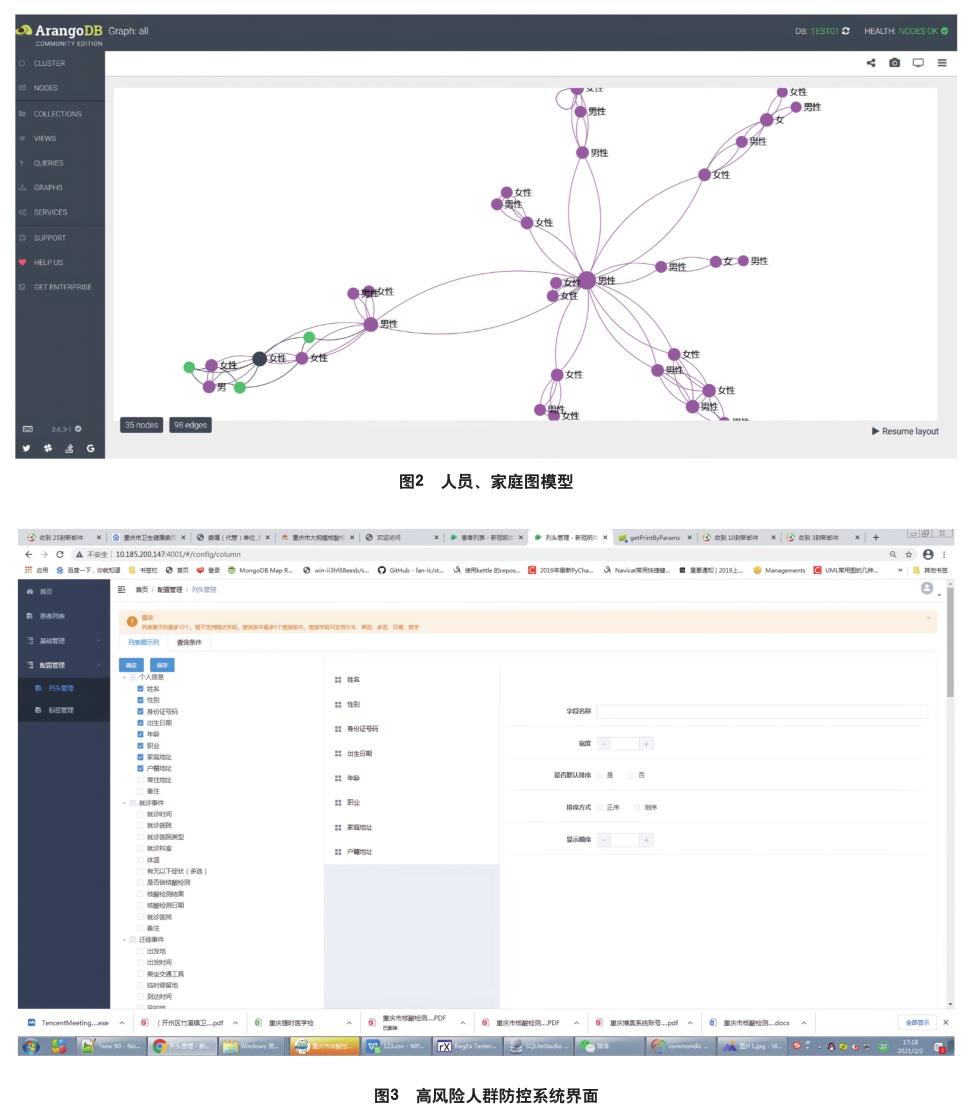
本研究选用了ArangoDB作为数据管理平台,在该图数据库中,将边和顶点视为文档(Document),使用集合(Collection)存储和管理边和顶点,两者通过组合定义图Graph,可以根据所属领域来构建图模型,并在逻辑上将边和顶点分组在集合中,并赋予查询它们的能力[7]。图Graph主要有命名图和匿名图两种类型,命名图通过至少一个边集合来定义在命名图中使用哪些集合,完全由ArangoDB管理,使用了ArangoDB所有图形功能。匿名图没有边集合来定义描述哪个顶点集合通过哪个边集合连接,图模型必须在客户端代码中维护,如使用AQL遍历图,相对更加自由。以人集合作为顶点,亲缘关系集合作为边,将进行模型转换后得到的数据导入到ArangoDB中存储管理,形成可供分析的基礎数据,如图 2所示。
三、可复用高风险人群防控系统设计
传染病患者的活动是流行病学史的重要内容之一,对快速查找随机接触人群实施隔离,切断传播途径有重大作用,也是本研究的重要数据支撑。研究立足流行病学调查的共有特点,综合运用现代软件工程架构和设计实现技术,建立可复用的通用流行病学调查数据采集系统,从而实现高风险人群的快速查找和疫情防控。
系统主要有数据模型配置、数据填报、综合分析、系统配置四大功能,数据模型配置主要提供被采数据的元数据配置和填写样式配置功能,提供了基本的元数据增删查改;数据填报功能主要提供基于已配置元数据开展数据采集,此次主要提供了传染病患者相关事件公共数据采集;综合分析功能主要提供基于图数据库的患者亲缘关系图模型和患者随机活动接触人员图模型分析结果的展示;系统配置主要提供了系统用户、角色以及权限的配置。系统实际运行时,依据流行病学史数据模型,结合传染病的公共特点,对系统的相关属性参数进行了配置,运行效果如图 3所示。
四、结语
面对传染病高风险人群的快速定位与防控工作的诸多挑战,本文在数据建模、模型转换、计算方法和系统建设等方面进行了探索。以重庆市在用人口信息模型和数据为基础,结合基于图论的图数据模型特点,提出了数据转换方法,使患者和家庭的关联对象查找可以达到O(1)效率,从而快速定位患者在亲缘关系方面的高风险人群。在此基础上,为应对不同类型流行病防控,综合运用Java、Vue、MySQL、MongoDB、Redis、ArangoDB等软件和技术,结合基于图数据库的转化模型,研发通用防控系统,抽象系统主要功能,建立系统动态属性参数模型,通过对参数模型的配置即可完成防控系统开发。该系统可复用性强,开发上线快,在需求明确的情况下,约2小时即可完成参数配置和系统上线运行。
作者单位:李剑、温海燕 重庆市卫生健康统计信息中心
张恒 西南大学人工智能学院 重庆市卫生健康统计信息中心
肖兵 重庆市卫生健康统计信息中心
