多尺度卷积特征融合的SSD手势识别算法
2021-04-06谢淋东仲志丹乔栋豪高辛洪
谢淋东,仲志丹,乔栋豪,高辛洪
(河南科技大学 机电工程学院,河南 洛阳 471003)
0 引 言
近年来,视觉识别技术飞速发展并广泛地应用于手势识别中[1-2]。手势分为静态与动态两种,由于动态手势识别难度较高、实时性较差且可识别的手势数量较少,无法满足大量繁杂信息输入的需求,所以目前的主要研究方向是静态手势的识别。用于静态手势识别方法大体分为两种:一是基于传统图像特征和机器学习的方法[3],此类方法难以从复杂的背景中提取到有代表性的语义信息,识别精度普遍偏低。二是基于深度学习[4-5]的方法,如R-CNN(region with convolutional neural network)[6]模型、R-FCN(region-based fully convolutional networks)[7]模型、Faster R-CNN[8]模型、YOLO(you only look once)[9]模型、SSD[10]模型等,其中SSD模型因其具有较好的识别效果而备受青睐。然而SSD算法用于中小占比目标识别时,识别效果一般,因此,很多学者改进了SSD算法,例如Wen等[11]提出了一种改进的SSD算法,即加入了Atrous[12]滤波器、SeLU激活函数以及引入一种数据规则来提高识别精度与速度。Tang等[13]基于原始的SSD算法,提出了一种多视窗的处理特征图的方法,该方法利用多个窗口多个通路检测中小占比目标,但由于目标的拆分,该方法存在鲁棒性低等问题。Fu等引入了一种特征提取能力更强的改进型网络,提出了DSSD(deconvolutional single shot detector)模型,与原有的SSD模型相比,特征融合能力有所加强,识别精度有所提高,但计算复杂度更高,从而存在耗时长等问题。
该文基于SSD模型,引入特征融合思想,以提高模型的语义表征能力,同时,改进了损失函数,以提高目标的分类能力。
1 SSD手势识别算法
SSD算法用于目标识别时,以特征提取为基本思想,以金字塔特征结构进行信息的目标识别。在VGG16网络中,每一级的卷积特征图用作本层的特征信息,即每一级卷积层的特征图始终描述着该层独有的特征信息,由于相邻的两个卷积层是相互独立的,从而忽视了对其他层的特征信息进行补充。
针对SSD算法存在的问题,该文提出了一种多尺度卷积特征融合的SSD手势识别算法。该算法基于原有SSD模型中多尺度卷积检测方法,同时引入了不同卷积层的特征融合思想,将新融合成的特征层代替原有的卷积层用做目标识别。此外,为了提升模型对目标手势的分类能力,提出一种改进的损失函数。
1.1 空洞卷积操作
在手势识别过程中,手势的特征图通过卷积、池化等操作后,很可能出现深层语义特征层出现信息丢失的情况,最主要原因是仅有conv4_3层用于识别小占比目标,导致特征提取不充分,一旦某一级的卷积层信息出现丢失,则与此相关联的另一卷积层也将受到影响,因此为了减少此类影响,采用空洞卷积操作[14]。空洞卷积操作能扩大卷积核的感受野范围,且保证参数个数不变,进行空洞卷积操作的特征层将学习到更多的上下文语义信息。
卷积核的感受野可由如下计算式得到:
Fdi=[2(di/2)+2-1]×[2(di/2)+2-1]
(1)
其中,di(dilation)表示空洞卷积操作时的不同扩张值,即卷积核计算出的半径值,Fdi表示不同感受野。可以看出,随着dilation的增加,感受野明显扩大。
因此,通过空洞卷积操作,将浅层视觉特征层进行空洞卷积下采样操作,与高层的特征层作融合处理,并且保持通道数不变,以及进行尺度的归一化处理。
1.2 反卷积操作
在SSD模型中,中高层的特征图具有更丰富的语义信息,而在识别中小占比的目标时,浅层特征层所能学习到的语义信息有限,从而影响对此类目标的识别精度。因此,为了让模型能够学习到更多的上下文信息,采用反卷积操作。卷积操作实现的是对高维数据进行低维特征提取,而反卷积操作与卷积操作的作用相反,它能够将低维度特征映射成高维输入。
反卷积操作利用转置后的卷积核对特征图像进行处理,通过对输入的特征图像进行填充补零,使得输出的特征图像尺寸大于输入图像的尺寸,最终能够将特征图像扩大到原图像的大小。假设输入图像大小为i、输出图像大小为o、边缘扩充为q、卷积核大小为w、步长为p,通过卷积操作输出的特征图计算公式为:
o=[(i+2q-w)/p]+1
(2)
通过反卷积操作可将特征图还原到原图像大小,计算公式为:
I=p(o-1)+w-2q
(3)
因此,通过反卷积操作扩大了卷积运算之后输入的特征图的尺寸,同时也保留了更多的特征信息,提高了模型的特征表达能力。
该算法将利用在卷积层之后引入反卷积网络以实现上采样并学习的思想,实现将具有更丰富的语义的高层特征层融入到浅层特征层中,代替原有的浅层特征层用于手势识别,且保持通道数不变,并对其进行归一化处理。
1.3 改进的网络结构
针对原始的SSD算法中网络结构忽略了层与层之间的联系,提出一种新的基于特征融合的网络结构。首先,基于原有的VGG16架构,将conv4_3_c,conv7_c,conv8_2_c,conv9_2_c, conv10_2_c,conv11_2_c设置为预测的新特征层,之后,使用空洞卷积下采样操作将浅层特征层融入到深层特征层中,从而使得模型能够学习到更多的中小占比的目标信息。考虑到深层特征层所含语义信息较丰富的特点,通过引入反卷积网络实现上采样与学习的特征,将深层特征层融入到浅层特征层中。
基于上述思想,新融合的低特征层conv4_3_c由两部分组成,第一部分使用扩张值为1,步长为1,大小为3×3的卷积核,通过conv4_3层自身的卷积运算得到256个38×38的特征图,这些特征图的尺寸未发生变化。第二部分,使用大小为2×2,步长为2,扩张值为0的卷积核,通过conv7的反卷积上采样操作得到256个38×38的特征图,并且这些特征图的尺寸增加了一倍。
新融合的特征层conv7_c由三部分构成,第一部分使用大小为3×3,步长为2,扩张值为2的卷积核,由conv4_3通过空洞卷积下采样操作生成256个19×19的特征图,这些特征图的尺寸缩小了一半。
第二部分使用步长为1,扩张值为1,尺寸为3×3的卷积核,由conv7通过自身的卷积运算得到512个19×19的特征图,此部分的特征图的尺寸不变。第三部分使用步长为2,扩张值为1,尺寸为3×3的卷积核,由conv8_2通过反卷积上采样操作得到的256个19×19的特征图,特征图增大了一倍。
新融合的conv8_2_c特征层与conv7_c融合类似,由三个部分构成,其中:第一部分使用尺寸为3×3,步长为2,扩张值为2的卷积核,由conv7通过空洞卷积下采样方式生成,所得的特征图尺寸缩小了一半。第二部分使用步长为1,扩张值为1,尺寸为3×3的卷积核,通过自身卷积操作得到。第三部分使用大小为2×2,步长值为2,扩张值为0的卷积核,由conv9_2_c通过反卷积上采样操作提供的,特征图尺寸增加一倍。
由于从conv9_2特征层开始,每个特征层尺度过小,自身包含的语义信息较强,所以,在保证算法精度的情况下应更多地考虑算法的检测速度,因此对conv9_2层之后的特征层不做特征融合操作。新的网络结构如图1所示。
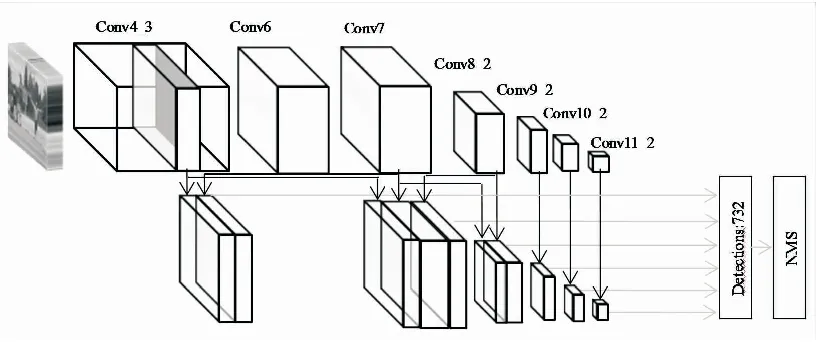
图1 新的网络结构
为了提高特征层的融合效果,对经过融合处理之后的特征层,加入BatchNorm层[15]用以计算不同特征图之间的偏差,再用Scale运算进行归一化处理。针对特征融合处理的特征层维度不相等的问题,使用1×1大小的卷积核进行降维处理,之后再经过一次BatchNorm运算,最终得到的结果作为该特征层的特征输出。
1.4 损失函数
SSD算法的损失函数是根据预测部分的输出结果来设计的,其损失函数由置信度损失Lconf和位置损失Lloc组成,公式如下:
L(y,f,c,r)=n(Lconf(y,f)+βLloc(y,c,r))
(4)

(5)
(6)
其中,n=1/N,N表示与真实框匹配后的剩余个数。Lconf(y,f)表示置信度损失,Lloc(y,c,r)表示位置损失,β是位置损失的整体占比,即权重,位置损失一般运用smoothL1Loss计算得出;当预测框与真实框相互匹配时,y的值设为1,反之为0;c和r分别表示预测框和真实框的位置信息;f表示预测框的目标分类。
SSD在检测过程中,检测框所能检测到的目标时为正样本,反之则为负样本,对于中小占比的目标手势而言,在一张图像中,目标手势的占比很小,正样本数量远小于负样本数量,直接导致了分类性能差等问题,从而影响检测的精度与速度。因此,针对由于正负样本不平衡导致模型分类性能差的问题,该文用改进的交叉熵损失函数IL(pt)代替了Lconf标准的交叉熵损失函数,公式如下:
CE(pt)=-ln(pt)
(7)
IL(pt)=-(1-βt)ηεln(pt)
(8)
其中,η=(pt-1)2,pt表示不同类别的分类置信度,且pt∈[0,1]。SI(pt)比CE(pt)多了βt和(1-pt)ε,βt为权重参数,在传统模型中βt=0,但很容易导致正负样本不均衡的问题。为了解决这个问题,对于正负样本的βt值设定进行区分,对于负样本,需要把βt设置为一个较小的值,用来平衡置信度损失和位置损失的比例。为了优化负样本的算法学习模型,将权重系数β设为0.1。ηε称为调制项,它反映了算法的分类能力,且pt∈[0,1],当pt的值接近于0时,算法将重点放在难以分类的目标数据上。否则,它将侧重于易于分类的目标数据。如图2所示,以pt为横轴,以loss为纵轴,绘制pt与loss的图像,从图中可以看出,随着pt的增加,分类手势的损失逐渐趋近于0,即损失在总损失中所占的比例越小,并且ε越大,分类损失减小的速度越快,分类能力越强。
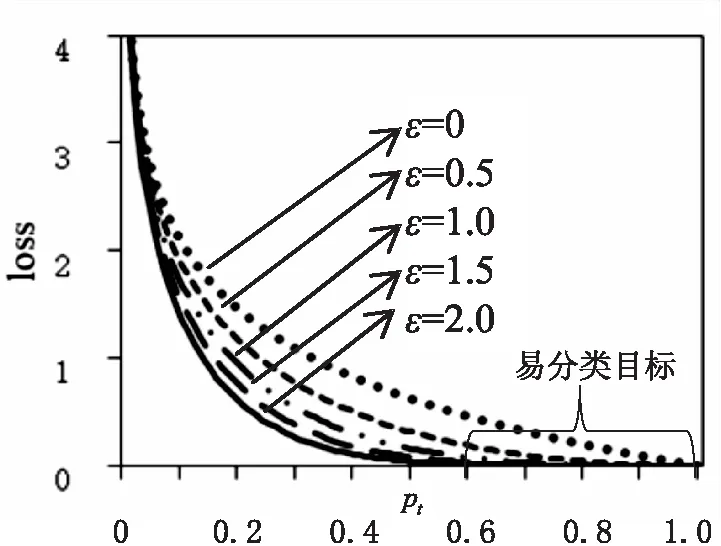
图2 损失函数变化
2 实验与结果分析
2.1 实验环境准备
提出的手势识别算法以Python语言作为实验框架,实验所使用的计算机配置为:Windows 10 64 位操作系统,处理器(CPU)型号为Intel i7,内存为16 GB,显卡(GPU)为NVIDIA GTX1080Ti。实验中所使用的各个软件版本为:Visual Studio 2016、Anaconda3、CUDA 9.0、Python 3.6.4、Tensorflow1.9.0。
最后,在集成环境上安装如pandas、nose等Python的第三方库及Keras、Tensorflow Research Models 等深度学习的API,以降低实验的实施难度。
2.2 数据集描述
实验所使用的数据集为MSRC-12 Kinect Gesture Dataset及2013 Chalearn Gesture Challenge Dataset,这两个数据集均是从实际场景收集得到的,手势属于中小占比目标。其中,MSRC-12 Kinect Gesture Dataset数据集包含12个不同手势,4 900张图片,从每种手势中随机选取400张图片,共4 800张图片。为了使实验更有说服力,选取数据库更为庞大,且场景更为复杂的2013 Chalearn Gesture Challenge Dataset数据集,共包含20种不同手势,图片总量达11 000张,每种手势随机选取400张,共8 000张图片,最终将两个数据集的12 800张照片共32种不同手势,以5∶3∶2的比例划分为训练集、测试集和验证集。
2.3 模型训练过程中的参数选择与优化
训练数据经过左右翻转和随机采样实现数据增强,随机采样最小的Jaccard overlap值为0.5,训练集与测试集的尺寸均等比例缩小为300*300大小,使用限制学习率的动态自适应梯度法[16]来训练。网络训练过程中,为了使BatchNorm在训练过程中有稳定的计算结果,参考文献[17]及现有的实验平台,实验开始时,将batch_size设置为16,动量因子设置为0.9,初始学习速率设置为10-3,权重设置为0.000 5,模型训练的时候使用回调函数观测val_loss,耐心值patience设置为15,当val_loss经过15个epoch不下降时,学习速率降低10倍。模型训练过程中的 training loss如图3所示,经过144个epoch训练后learning_rate从10-3降低为10-4,200个epoch后模型收敛。

图3 训练损失值
2.4 测试结果
为了验证提出的改进算法在对中小占比手势识别上的可行性和优越性,选取了目标完整度(COM)、全局精度(Global Acc)、IOU[18]以及FPS作为本次实验的评价指标。
其中,目标完整度表示预测框中标记目标图像占整个图像的比例;全局精度表示对目标手势正确分类的结果;IOU表示错误识别的目标手势的情况,是一种测量在某一数据集中检测的相应物体准确度的标准;FPS表示处理目标图像的速度,每秒内可以处理的图片数量。
为了探究训练集对评价指标的影响,从训练集中随机挑选20%、40%、60%、80%、100%构成5个新的训练集,基于这5个训练集训练模型,在检测集上进行检测,观察不同训练集上的检测效果,检测精度如表1所示。

表1 检测精度
如表1所示,随着训练集比例的增加,即训练集数据增多,目标的检测效果也越好,最好的检测效果是训练集比例达100%时。此外,当在比例为60%训练集训练时,检测效果已达到较高的检测水平,再往后提高训练集比例,识别效果提升幅度很小,因此,可以看出该算法具有较强的特征提取能力,在一定比例的训练集上,就能达到较好的检测效果,从而验证其具有较高的鲁棒性等特点。
为了更好地验证识别效果,选出常用于目标检测识别的Faster R-CNN算法、YOLO算法与SSD算法与文中算法(Our1)作对比,此外,分别对仅改进了网络结构的算法(Our2)与仅改进了损失函数的算法(Our3)验证改进效果。该实验在100%比例的训练集上训练模型,最终在测试集上观察测试效果,测试结果如表2所示,图4为文中算法对部分数据集测试的效果图。

表2 不同算法的测试结果

图4 检测效果
如表2所示,在目标完整度(COM)、全局精度(Global Acc)、IOU这三个指标中,Faster R-CNN识别效果最佳,文中所提出的方法识别精度与其相当,而SSD算法与YOLO算法在用于中小占比的手势检测中,识别精度较为一般,即通过多尺度卷积特征融合的方式改进SSD模型的网络结构,一定程度上能够提高识别精度。对于与检测速度有关的FPS指标,SSD算法的FPS值最高,为40,文中算法为31,即在进行特征融合时,一定程度上会增加网络的复杂度,从而影响模型的检测速度,此外,检测精度最高的Faster R-CNN却为9,检测目标图像的速度最慢,YOLO算法检测速度较为一般。
综合这四项指标及实际场景中对手势识别有着较高的识别精度与识别速度的需要,文中算法最优,即使Faster R-CNN算法的识别精度高,但却是以牺牲大量的检测速度实现的。为了提高对中小占比手势目标的识别精度,对SSD网络结构的卷积层进行空洞卷积操作与反卷积操作,将部分特征层进行融合,构建新的融合网络结构以代替原有的VGG-16网络结构用于手势识别,同时,在检测中小目标时,正负样本不均衡导致的分类性能差,从而影响检测精度与速度,对此改进了损失函数,将改进的交叉熵损失函数IL(pt)代替Lconf标准的交叉熵损失函数,以此提高了网络对目标手势的分类能力。对于conv_9_c层之后的语义信息较丰富的卷积层不做特征融合处理,以减轻网络的冗杂度达到轻量化的目的,但也因此牺牲部分的检测精度。
为了使模型更具有说服力,分别测试了仅改进网络结构的算法(Our2)与仅改进损失函数的算法(Our3),对于Our2算法,主要通过特征融合的思想提高目标的识别精度,与SSD算法相比,较大程度提高了识别精度,但也牺牲了部分识别速度,而对于Our3算法,通过改进损失函数,提高模型的分类性能,与SSD算法相比,一定程度提高识别精度的同时,提高了模型的识别速度。因此,基于SSD网络架构,通过改进网络结构与改进的损失函数,均能在对中小占比的目标识别过程中,保证一定水平的检测速度,同时提高目标识别精度。
3 结束语
提出了一种多尺度卷积特征融合的SSD手势识别方法。在原始的SSD多尺度特征卷积的基础上,引入了特征融合的思想,即对浅层视觉特征层与高层语义特征层作融合处理,以此使模型能够学习到更多的特征信息,提高模型对中小占比手势的识别精度,此外,提出一种改进的损失函数,使模型更侧重于分类损失,以便该算法更好地完成分类任务。在实际应用场合中,对于手势识别系统有着识别精度高和鲁棒性好的需求,提出的方法能够在保证较高水平的检测速度的同时,具有更高的检测精度与鲁棒性。
