基于模糊近似支持向量回归的股价预测研究
2021-04-06王冰玉刘勇军
王冰玉,刘勇军
(华南理工大学,广东 广州 510640)
0 引 言
股价预测主要基于相关预测模型预测股价的未来变化趋势以捕捉相应的市场行情,从而促进股票选择。近年来,股价预测是热点问题。许多学者和业界人士都从理论和实践层面对其股价预测模型进行相关研究,其研究方法包括GARCH[1-3]、模糊时间序列[4-5]、ARIMA[6-8]等。由于计算机技术的发展和广泛应用,各种机器学习和量化投资模型也被逐渐地应用到股票预测领域,例如支持向量机、人工神经网络、遗传算法和差分进化算法等股价预测模型。
Yu和Yan基于PSR方法和DL的长短期记忆网络(LSTMs),设计了一种基于DNN的股价预测模型,并对不同时期的多个股票指数进行预测[9]。Onoh等利用协调搜索(HS)和遗传算法,建立混合人工神经网络模型,并根据数据集的统计和财务表现进行实证分析[10]。Moghaddam等研究人工神经网络对纳斯达克股票日汇率的预测能力,从而对用反向传播算法训练的几种前馈神经网络进行了评估[11]。Hjek等将情绪与财务指标相结合,使用一个多层感知器神经网络来预测异常股票回报率[12]。綦方中等提出一种基于PCA-IFOA-BP神经网络的股票价格预测模型,并借助上证指数进行预测[13]。孟叶等选取K-近邻、梯度提升和自适应提升这3个分类器,通过改进的投票算法聚合成一个新的分类器模型,对指数行情数据进行学习分类[14]。
虽然基于神经网络的混合模型是预测股票市场指数的有效预测方法,但是却存在着诸如黑箱技术、过拟合、收敛速度慢、陷入局部极小等局限性。为了克服这些局限性,Cortes和Vapnik提出的支持向量机(SVM)方法已经成为股票市场指数预测领域的一种流行研究方法,它采用结构风险最小化的原则,以最小化泛化误差的上界。通过应用支持向量机,不太可能出现过拟合,而且最优解也可能是全局的[15]。Nayak等构建一种支持向量机与K近邻法相结合的混合框架,用于印度股市指数的短期、中期和长期预测[16]。Chen等引入特征加权向量,进一步提出特征加权支持向量机和特征加权K最近邻的基本混合框架,以有效地预测股票市场指数[17]。Xiao等提出一种将SVM和SSA相结合的组合模型,并建立基准模型进行对比分析[18]。Lee创建一种基于支持向量机(SVM)和混合特征选择方法的股市趋势预测模型[19]。Fung等提出一种新的近端支持向量机(PSVM)模型,并使用公开的数据集上的计算结果表明,PSVM不仅具有与SVM相当的测试集正确性,而且具有相当快的计算时间[20]。姚潇和余乐安在PSVM的基础上,引入模糊隶属度的思想,提出模糊近似支持向量机(FPSVM),并利用两个公开的信用数据集进行实证研究验证该模型的有效性[21]。张贵生等针对股价的非线性特点,提出基于近邻互信息特征选择SVM-GARCH的股价预测模型[22]。张冰等提出具有局部信息挖掘功能的DNN加权算法对eplion-TSVR模型进行改进,并借助上证A股的高频数据进行实证预测[23]。
综上所述,首先虽然SVR能够在股价预测中发挥更好的表现力,但是都未考虑股票数据中所含的噪声信息对股价预测的影响,其次现有研究未曾考虑投资者对两种预测误差((1)预测值>实际值;(2)预测值<实际值)的不同偏好。有的投资者更注重收益,而有的投资者更关注损失,因此,不能简单直接地使用SVR模型进行股价预测,而是应该根据实际情况,针对投资者的不同目标赋予不同的偏好值,构建有效的股价预测模型进行股票价格的准确预测。
综合考虑以上研究现状和存在的不足之处,该文构建信噪比特征向量,并借用现有文献表明的相关股价预测指标,选取历史数据、趋向、反趋向、能量、量价、波动和信噪比等其他七个方面的指标作为输入变量,考虑到投资者对预测误差的不同偏好,引入模糊隶属度和双边权重测量方法,构建基于信噪比的模糊近似支持向量回归模型进行股价预测。
1 模糊近似支持向量机
模糊近似支持向量机(FPSVM)是由姚潇和余乐安在2012年提出的[21]。该模型是为了减小训练样本的奇异点和噪声对模型的干扰,在PSVM的基础上,引入了模糊隶属度。设含有N个训练样本的训练集样本对{(x1,y1),(x2,y2),…,(xN,yN)},其中xi∈Rd为第i个训练样本的输入向量,d为样本空间维度,yi∈{+1,-1}为对应输出值,则FPSVM模型的具体形式如下:
(1)
其中,C>0为错误项的惩罚参数,εi为松弛变量,Φ(x)为非线性映射函数,wT为特征空间维数,b为待定的标量参数,mi为隶属度,表示第i个样本点对超平面的贡献率。mi越小,则误差项所占的比例越小,在整个模型的影响就越小。当所有的mi=1时,FPSVM就退化为PSVM。
2 股价预测输入指标的获取
由于买卖反弹,价格变化的离散性、交易规模的差异和订单流的战略组成部分等因素导致所观察到的价格过程是一个包含噪声的过程[24]。现实生活中,一般所观察的对数价格过程包含对数有效价格和噪声两部分,相应的股价对数形式为:
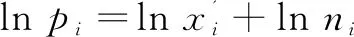
(2)


(3)

噪声的存在会影响股价预测。若该文能在SVM方程的构建中进一步消除噪声,则可提高股价预测精度。信噪比(SNR)是描述信号中有效成分与噪声成分的比例关系参数,可以有效地对噪声进行处理[25]。该文考虑引入SNR降低噪声干扰。根据现有文献,可得到信噪比(SNR)的计算公式[26]:

(4)

此外,股票市场中,开盘价、最低价、最高价和总交易量历史数据通常被用做输入指标。最近相关学者研究表明一些技术指标有助于更好地预测股价[17]。故该文同时借助相关的技术指标作为输入变量,具体将这些指标分为:
(1)趋向指标:移动平均线(MA)、指数移动平均线(EMA)、异同移动平均线(MACD)和动量指标(MTM);
(2)反趋向指标:相对强度指数(RSI);
(3)能量指标:AR、BR和成交量变异率(VR);
(4)量价指标:多空比率净额(DK);
(5)波动指标:平均真实范围(ATR)。
3 基于FPSVR的股价预测模型构建
3.1 FPSVR模型构建
直接采用SVR模型进行股票预测会存在以下不足:首先原有的SVR模型都未考虑投资者对股价预测误差的不同偏好情况,默认投资者对预测误差的偏好是一致的,使得预测结果不能准确反映投资者的投资策略,其次SVR模型无法处理噪声和奇异点对模型的干扰状况,影响模型的预测准确度。


故而,该文得到基于模糊近似支持向量回归的股价预测模型,其具体形式如下:

(5)
其中,i为所选取股票的第i个样本,N为训练样本总数,xi为第i个输入向量,xi=(xi1,xi2,…,xi15)分别代表开盘价、最高价、最低价、总交易量、移动平均线、指数移动平均线、异同移动平均线、动量指标、相对强弱指数、人气指标、意愿指标、成交量比率、多空比率额、真实波动幅度均值和信噪比,yi为实际股票收盘价。
通过构造拉格朗日函数对式(5)进行求解,得到:
(6)
分别对w,b,mi,ni求偏导,得:
(7)
对式(7)求解得到:
(8)
故上述规划问题变为:
(9)

f(x)=w*Φ(x)+b=
(10)
3.2 隶属度的获取

(11)
4 实证分析
4.1 数据的选取
选择沪深300成份股的股票日数据进行股票收盘价的实证分析,相应时间序列的日期为2008年1月1日至2019年12月31日,数据来源于东方财富数据库。沪深300成份股共包括300只股票,故该文总共选取300只股票作为总样本,并从中随机选取30只股票进行股票收盘价预测。所有的实证均在同一系统环境下运行,系统运行环境为PC(CPU 2.60 GHz,4.00 GB RAM),操作系统为Windows 10,仿真软件为Matlab R2016b。此外,采用libsvm处理SVR。并将样本数据集分为训练样本数据集和测试样本数据集,选择样本数据的前80%作为训练样本,后20%作为测试样本。
沪深300成份股是沪深证券交易所于2005年4月8日联合发布的反映A股市场整体走势的指数,由上海和深圳证券市场中选取300只A股作为样本,其中沪市有179只,深市121只,综合反映深交所上市A股的股价走势。它具有业绩优于整体、对家方案较优、股改行情明显等优势,经常被研究者用于股价预测。
为了更好地反映所提出的基于信噪比的FPSVR股价预测模型的有效性,将所选取的股票时间序列按照股市的波动情况(牛市、震荡市和熊市)分为三个阶段,进行阶段式预测。为了更清晰地展示股市状况,以招商银行为例,对阶段式预测进行说明,如图1所示。

图1 招商银行2008-2019年日收盘价的变化趋势
从图1可看出,招商银行的收盘价变化趋势可分为三个阶段,其中H代表熊市阶段,为阶段1;N代表牛市阶段,为阶段2;其余时间的指数变化趋势大致代表震荡市阶段,为阶段3。
本研究为确保所有的输入特征位于相同参数范围内,以防止大范围的输入特征压倒其他输入特征,采用式(12)对数据进行标准化处理:

(12)
其中,xij为第i个样本的第j个输入特征值,xminj为样本数据第j个输入特征的最小值,xmaxj为样本数据第j个输入特征的最大值。
4.2 相关性分析
Spearman相关系数不但可以衡量存在非线性关系的相关变量之间的相关程度,而且未对数据有严格的假设要求,故本节采用Spearman相关系数进行输入特征变量与股票收盘价之间的相关性分析。为了更清晰地说明特征变量与股票收盘价之间的相关性,进一步地以招商银行为例展示输入特征与股票收盘价的相关性分析结果,如表1所示。
由表1可看出:
(1)在置信度为0.01时,开盘价、最高价、最低价、MA和EMA都与股票收盘价之间的Spearman相关系数>0.95,说明这些指标都与股票收盘价存在很强的正相关性,这些输入指标数值增加时,股票收盘价也增加。

表1 各指标相关性分析
(2)在置信度为0.01时,SNR与股票收盘价的Spearman相关系数>0.6,说明SVR与股票收盘价之间存在中等程度的正相关性,当SNR增大时,股票收盘价随之增大。
(3)不管是在置信度为0.01时,还是在置信度为0.05时,MACD、BR、VR和OBV都与股票收盘价存在非相关关系,但是这些指标与其他指标之间存在相关关系,说明这些指标可以影响其他指标,从而间接影响股票收盘价的变化。
从上述发现中可得到以下结论:①SNR与预测变量股票收盘价之间存在直接的正相关性,进而说明所构建的SNR特征变量是有效的;②这些输入特征之间存在紧密的相关性,且都与预测变量股票收盘价之间存在直接或间接的相关关系。
4.3 评估准则
众所周知,误差是指测量值与真实值或实际值之间的差值,主要用来衡量测量结果的准确度,其中平均绝对百分比误差因能避免误差相互抵消的问题,可以准确反映实际预测误差的大小,均方根误差不仅能对一组测量中的特大或特小误差反映非常敏感,而且能够很好地反映出测量的精密度,故经常被用于预测模型的准确度测量。该文将平均绝对百分比误差(MAPE)和均方根误差(RMSE)作为股价预测模型的评估准则,其表达式如下所示:
(13)

(14)

考虑到上述实验条件,对于所有RMSE和MAPE,它们的值越小,所构建的股票收盘价预测模型的预测性能越好。
4.4 结果分析
为了验证所提出的基于信噪比的FPSVR股价预测模型的有效性,在收盘价预测的过程中,选用三种基准模型预测方法,分别为模型1:未加入信噪比的支持向量回归(未加入SNR的SVR);模型2:加入信噪比的支持向量回归(加入SNR的SVR);模型3:未加入信噪比的FPSVR,并将这三种预测方法与文中所提的模型4—基于信噪比的FPSVR模型进行对比分析。
由于金融时间序列的动态特性是非线性的,文中将FPSVR模型应用于收盘价预测时,使用高斯核函数作为核函数,因为高斯核函数在一般的平滑假设下往往会有很好的性能[27]。此外,本节采用基于十折交叉验证的网格搜索方法,对传统的支持向量回归参数进行了选择,并对FWSVR模型也使用同样的参数,所使用的参数如表2所示。

表2 基于信噪比的FPSVR模型所使用的最优参数
此外,采用遗传算法(GA)对FPSVR股价预测模型进行求解,GA中所使用的相关参数为G=2 000,popsize=50,其中G为进化代数,popsize为种群规模,相应的适应度函数变化情况如图2所示。

图2 GA的适应度函数的变化情况
从图2中可看出,在进化代数为2 000时,随着GA算法的进化代数增加,适应度函数趋于稳定,从而说明这种情况下,GA算法可以很好地对FPSVR进行求解。
下面根据上述所建立的四种不同模型对沪深300成份股中随机选择的30只股票时间序列进行收盘价预测,并给出了四种模型在不同阶段的预测误差,如表3所示。
从上述实验结果中可以看出:
(1)与模型1和模型2相比,模型3和模型4的预测误差更低,说明加入模糊隶属度和双边权重的FPSVR模型可以更好地实现股价预测。
(2)模型2和模型4的预测误差分别低于模型1和模型3的预测误差,从而表明加入信噪比特征变量后的股价预测模型准确度更高。
(3)分阶段来看,不管是SVR股价预测模型还是FPSVR的股价预测模型,在阶段1和阶段2的预测误差均较高于阶段3的预测误差,说明在震荡时期,这两种模型更适用于股价预测。
(4)分阶段来看,在阶段1和阶段2时期,FPSVR的股价预测模型的预测误差要远低于SVR股价预测模型的预测误差,从而表明,该文所构建的FPSVR模型可以弥补SVR模型在阶段1和阶段2时期的股价预测误差较大的不足,可以更好地实现股价预测。

表3 模型对比分析结果
5 结束语
为了更好地实现股价的精准预测,提出了基于信噪比的模糊近似支持向量回归(FPSVR)的股价预测模型,并通过实证研究、相关性分析和对比分析三个方面实现和验证所提模型的准确性。研究结果表明,与现有模型相比,该模型不仅在震荡期,而且在牛市和熊市期均可实现股价的精准预测。该模型通过对沪深成份股2008年至2019年的股票日数据进行研究和分析,实现对股票的准确预测,为投资者提供一种更有效的预测方法,从而有助于投资者的投资决策。
