基于ERNIE 2.0模型的用户评论多标签文本分类研究
2021-04-05孟晓龙

摘 要:文章针对多标签文本分类这一热点问题,采用“预先训练模型+微调策略”模式,即研究持续学习语义理解框架ERNIE 2.0和基于知识蒸馏的壓缩模型ERNIE Tiny预先训练模型,以及倾斜的三角学习率STLR微调策略在用户评论多标签文本数据集中的实践。相对经典语义表征模型BERT,采用ERNIE 2.0模型的效果可提高1%以上,采用ERNIE Tiny模型的速率可提升3倍左右;相对默认微调策略,采用倾斜的三角学习率STLR微调策略的效果同样可再提高1%左右。
关键词:多标签文本分类;预先训练模型;微调策略;知识蒸馏
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2021)17-0087-05
Abstract: Aiming at the hotspot issue of multi label text classification, this paper adopts the mode of “pre training model + fine tuning strategy”, that is, to study the continuous learning semantic understanding framework ERNIE 2.0, the compression model ERNIE Tiny pre training model based on knowledge distillation, and the practice of inclined triangular learning rate STLR fine tuning strategy in user comments multi label text data sets. Compared with the classical semantic representation model BERT, the effect of ERNIE 2.0 model can be improved by more than 1%, and the rate of ERNIE Tiny model can be increased by about 3 times; compared with the default fine tuning strategy, the effect of inclined triangular learning rate STLR fine tuning strategy can also be improved by about 1%.
Keywords: multi label text classification; pre training model; fine tuning strategy; knowledge distillation
0 引 言
多标签文本分类是自然语言处理中一个重要而富有挑战性的任务,与通常一个文本仅归属于一个标签的单标签文本分类不同[1-3],多标签文本分类任务则是将文本同时归属于一个或多个标签,并且多个标签之间可能存在更加复杂的关系。
随着深度神经网络的发展,研究者提出各种基于深度神经网络的多标签文本分类模型,特别是将多标签分类任务当作序列生成问题,考虑标签间相关性的序列到序列Seq2Seq模型与考虑输入文本关键信息的注意力Attention机制结合的各类算法大放异彩,进一步提升多标签文本分类模型的性能。与此同时,将上游预先训练语言模型应用于自然语言处理下游特定任务这个划时代的思想,让预先训练模型PTMs(Pre-trained models)渐渐步入人们的视野。随着ELMo、GPT、BERT等预先训练模型在自然语言处理任务方面取得SOTA结果,一系列以BERT为基础的改进模型相继被提出,大大推动自然语言处理领域的进步。
本文基于某用户评论多标签文本分类数据集,分别从如何构建基于预先训练模型的多标签中文文本分类模型,如何在效果损失较少的情况下显著地提升模型速率,如何有效地设计微调策略这三个方面进行研究。主要的贡献有:
(1)改造某细粒度用户评论情感分析数据集成为用户评论多标签文本分类数据集,并采用二元交叉熵损失作为多标签分类的损失函数。
(2)相对于典型的预先训练模型BERT,本文采用的持续学习语义理解框架ERNIE 2.0的效果可提高1%以上,而基于知识蒸馏的压缩模型ERNIE Tiny的速率可提升3倍左右。
(3)相对于模型默认微调策略,本文采用的倾斜的三角学习率STLR微调策略效果可再提高1%左右。
1 相关工作
1.1 多标签分类
多标签文本分类的关键是如何合适地表达标签间复杂的相关性。随着神经网络的发展,研究者提出各种基于深度神经网络的多标签文本分类模型。
Zhang等人提出[4]多标记学习的反向传播算法BP-MLL(Back Propagation for Multi-Label Learning),通过定义成对排序损失函数来捕获多标签学习的特征,首次在多标签文本分类问题上展现多层前馈神经网络明显优势。Nam等人基于Zhang的工作,以交叉熵损失函数作为目标函数[5],并采用整流线性单元ReLUs激活函数、Dropout正则化机制和AdaGrad优化器学习率调整等技巧来提升训练效果。此后,Kurata等人提出[6]利用标签之间的共现关系来初始化输出层权重,采用词嵌入和卷积神经网络CNN(Convolutional Neural Network)结构来捕获标签相关性,而Chen等人提出[7]采用卷积神经网络CNN和递归神经网络RNN(Recursive Neural Network)来从文本中提取全局和局部语义信息。
为了更好地解决多标签文本分类问题,Nam等人利用循环神经网络RNN(Recurrent Neural Network)巧妙地使用序列到序列Seq2Seq模型[8],对给定的源文本进行编码,并对表示进行解码,将多标签文本分类问题近似于序列预测问题。Yang等人采用[9]短期记忆网络LSTM(Long Short-Term Memory)处理标签序列的依赖关系来考虑标签之间的相关性,并利用注意力Attention机制考虑文本不同部分的贡献,提出一种新的全局嵌入解码器结构。Lin等人通过[10]多层扩展卷积产生更高层次的语义单位表示并结合注意力机制来进行多标签分类,与传统的Seq2Seq模型相比,该模型能够更好地预测低频标签,并且受标签序列先验分布的影响较小。Yang等人结合[11]卷积神经网络CNN和并行自注意力机制设计分层解码器来生成标签序列,以从源文本中提取细粒度的局部邻域信息和全局交互信息。
1.2 预先训练模型
预先训练一直是学习深度神经网络参数的有效策略,早在2006年,Hinton等人就指出通过“预先训练”可以得到比较接近最优模型参数的初始化权值,并经“全局微调”达到模型优化重建的目的[12]。
Peters等人2018年采用深度双向Bi-LSTM来实现上下文相关,提出一种动态的、语境化的语言模型ELMo(Embedding from Language Models),将目标任务处理转移到预先训练产生词向量的过程中[13]。Radford等人2018年提出基于多层单向Transformer结构的生成式预先训练方法GPT(Generative Pre-Training),先用无标签的文本去训练生成语言模型,再根据具体的目标任务对模型进行微调[14]。Devlin等人2018年提出基于多层双向Transformer结构的语义表征模型BERT(Bidirectional Encoder Representations from Transformers),同时利用下一句子预测任务和掩码语言模型来获得高级别的语义表征[15]。Zhang等人2019年提出增强的语言表征模型ERNIE(Enhanced Language Representation with Informative Entities),该模型[16]结合大规模语料库和知识图谱,可同时充分利用词汇、句法和知识信息。Sun等人进而提出持续学习语义理解框架ERNIE 2.0(AContinual Pre-Training Framework for Language Understanding),该框架[17]以递增方式构建预先训练任务,并通过连续多任务学习来让模型学习这些已构建的任务。
1.3 微调策略
随着预先训练模型深度的增加,其所捕获的语言表征使目标任务更加容易,微调策略已逐渐成为预先训练模型适应目标任务的主要方法。然而,微调的过程往往是脆弱的,即使有相同的超参数值,不同的随机种子就可导致实质上不同的结果。Sun等人的研究表明[18],对相关领域语料进行进一步的预先训练,可以进一步提高BERT的能力,并在文本分类数据集上取得SOTA的性能。Li等人提出的TransBERT(Transferable BERT)[19],不仅可以从大规模的未标注数据中迁移学习通用的语言知识,还可以从各种语义相关的监督任务中迁移学习到特定类型的知识。Stickland等人在预先训练模型BERT添加额外的特定任务适应模块PALs(Projected Attention Layers)[20],实现比标准微调模型少7倍参数,却在通用语言理解评估基准GLUE(General Language Understanding Evaluation)表现相当的性能。Goyal等人2017年提出预热方法[21],即在训练初期使用较小的学习率开始,并在训练后期逐步增大到较大的学习率;Howard等人2018年提出倾斜的三角学习率STLR(Slanted Triangular Learning Rates)方法[22],先线性地增加学习率,然后根据训练周期线性地衰减学习率。
2 关键技术
2.1 持续学习语义理解框架
持續学习语义理解框架ERNIE 2.0通过不断地引入各种各样的预先训练任务,以帮助模型有效地学习词汇,句法和语义表示[17]。其训练过程包含:
(1)基于大数据和先验知识的无监督预先训练任务构建。
(2)持续的多任务学习更新。
2.1.1 预先训练任务构建
先前的预先训练模型通常基于单词和句子的共现来训练模型。实际上,除单词和句子的共现外,还有其他词汇,句法和语义信息值得在训练时进行检查。比如,个人名称、位置名称和组织名称之类的命名实体可能包含概念性信息;句子顺序和句子接近度之类的信息可能包含结构感知表示;文档级别的语义相似性或句子之间的语篇关系可能包含语义感知表示。因此,ERNIE 2.0构造单词感知任务、结构感知任务和语义感知任务等不同种类任务。其中,单词感知任务能够使模型捕获词汇信息,结构感知任务能够使模型捕获语料库的句法信息,而语义感知任务能够使模型学习语义信息。
2.1.2 持续的多任务学习
受人类能够不断积累通过学习或经验获得的信息,从而有效地开发新技能这一学习特点的启发,ERNIE 2.0引入持续学习的理念,即通过增量的方式进行多任务学习,不是只使用新增的任务来训练,而是通过多任务学习同时学习之前的和新增的任务。
为有效地管理和训练这些任务,ERNIE 2.0构建Task Embedding模型提供任务嵌入以表示不同任务的特征。每个任务ID都分配给一个唯一的任务嵌入,并以相应的令牌Token、位置Position、句子Sentence和任务Task嵌入作为模型的输入。对于给定的序列,特殊分类嵌入[CLS]标记序列的首位,分隔符[SEP]标记多个输入任务的间隔;同时,ERNIE 2.0使用多层Transformer作为基本编码器,通过Self-Attention机制来捕获序列中每个令牌的上下文信息,并自动将每个任务分配给不同的训练阶段。这样,模型就可以即保证方法的效率,又不会忘记先前训练有素的知识。
2.1.3 压缩模型
ERNIE Tiny通过如图1所示的方法进行模型结构压缩和模型蒸馏。ERNIE Tiny模型采用3层Transformer结构实现线性提速,并采用加宽Hidden层来实现效果提升。ERNIE Tiny模型采用中文Subword粒度输入来缩短输入文本的序列长度,进一步降低计算复杂度。ERNIE Tiny利用模型蒸馏的方式,扮演学生角色在Transformer层和Prediction层学习教师模型ERNIE 2.0模型对应层的分布和输出。
2.2 多标签分类损失函数
本文使用二元交叉熵损失(Binary Cross Entropy Loss)作为多标签分类的损失函数[5],其定义为:
其中,N为样本的数量,K为标签的数量,yij∈{0,1}和∈[0,1]分别表示第i个样本的第j个标签的真实标签值和概率预测值。
2.3 倾斜的三角学习率
本文使用倾斜的三角学习率STLR(Slanted Triangular Learning Rates)方法[22],即先线性地增加学习率,再根据训练周期线性地衰减学习率。具体表达为:
其中,T是总的训练迭代次数,cut_frac是学习率上升在整个训练迭代次数的比例,cut是学习率转折时的迭代次数,p是学习率递增或将递减的放缩比例,ratio是最小学习率与最大学习率ηmax的比值,ηt是第t次迭代的学习速率。
经验发现,当cut_frac等于0.1,且ratio等于32时,具有短期增长和长衰减期特性,结果较好。
3 实验与分析
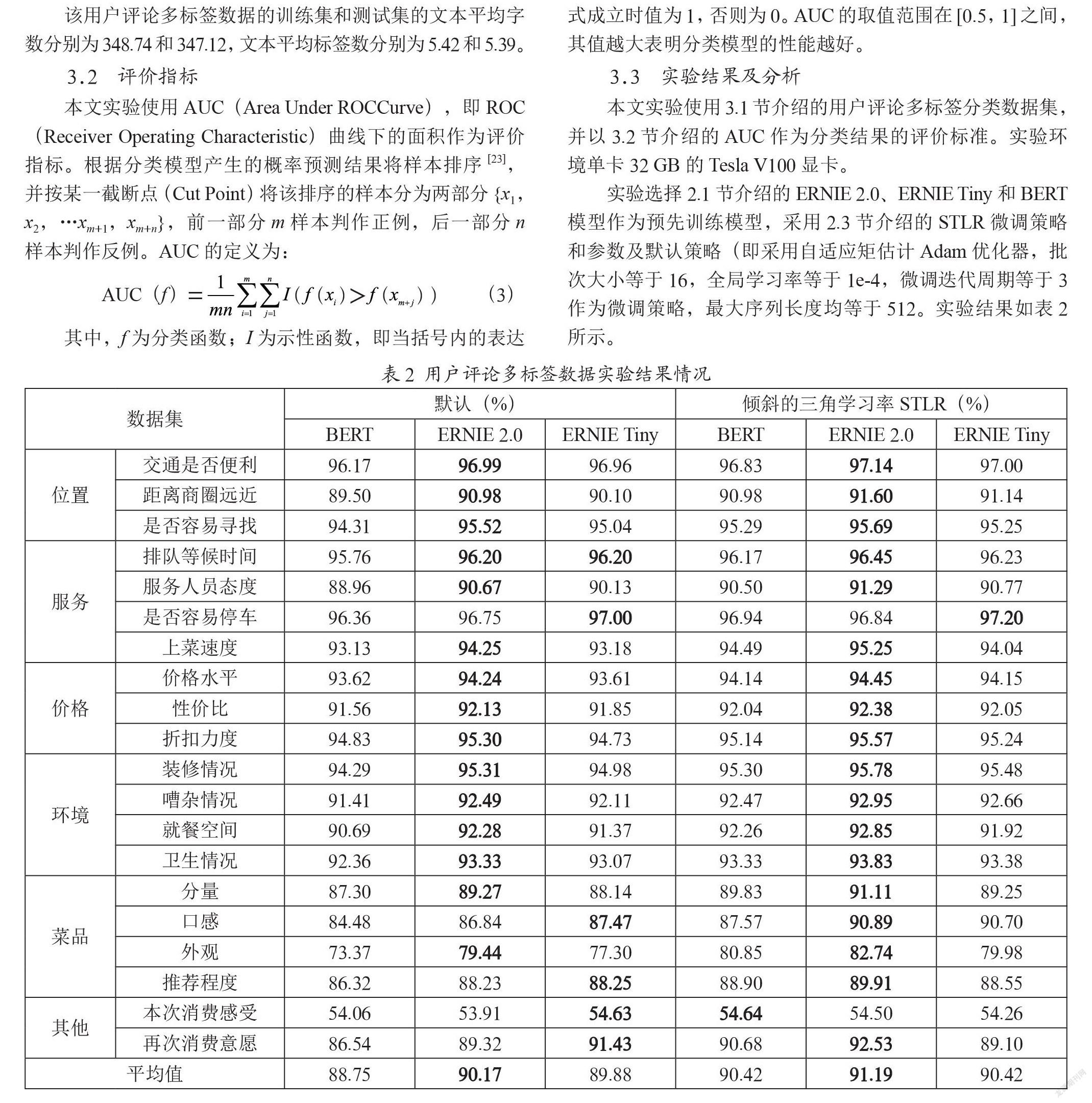
3.1 实验数据
本文改造AI Challenger 2018细粒度用户评论情感分析数据集,将其正向、中性、负向、未提及四种情感倾向状态合并成用户评论的“提及(1)”和“未提及(0)”两种类别,形成包含6大类共20个标签的用户评论多标签中文数据集,训练集105 000个样本,测试集15 000个样本,以测试集为例介绍数据集的基本情况如表1所示。
该用户评论多标签数据的训练集和测试集的文本平均字数分别为348.74和347.12,文本平均标签数分别为5.42和5.39。
3.2 评价指标
本文实验使用AUC(Area Under ROCCurve),即ROC(Receiver Operating Characteristic)曲线下的面积作为评价指标。根据分类模型产生的概率预测结果将样本排序[23],并按某一截断点(Cut Point)将该排序的样本分为两部分{x1,x2,…xm+1,xm+n},前一部分m样本判作正例,后一部分n样本判作反例。AUC的定义为:
其中,f为分类函数;I为示性函数,即当括号内的表达式成立时值为1,否则为0。AUC的取值范围在[0.5,1]之间,其值越大表明分类模型的性能越好。
3.3 实验结果及分析
本文实验使用3.1节介绍的用户评论多标签分类数据集,并以3.2节介绍的AUC作为分类结果的评价标准。实验环境单卡32 GB的Tesla V100显卡。
实验选择2.1节介绍的ERNIE 2.0、ERNIE Tiny和BERT模型作为预先训练模型,采用2.3节介绍的STLR微调策略和参数及默认策略(即采用自适应矩估计Adam优化器,批次大小等于16,全局学习率等于1e-4,微调迭代周期等于3作为微调策略,最大序列长度均等于512。实验结果如表2所示。
实验结果表明,相对典型的预先训练模型BERT,本文采用的持续学习语义理解框架ERNIE 2.0的效果可提高1%以上,而基于知识蒸馏的压缩模型ERNIE Tiny的效果与之相近,但速率可提升3倍左右,这是由于ERNIE 2.0不断地引入各种各样的预先训练任务,可以有效地学习词汇、句法和語义表示;采用倾斜的三角学习率STLR的“预热”策略,同样可再提高模型的效果1%左右,这是由于该策略有助于减缓模型在初始阶段的提前过拟合现象和保持模型深层的稳定性。
同时,分析实验结果也发现,上述三种预先训练模型在此用户评论多标签中文数据集的绝大多数类别的AUC值可达90%以上的优秀表现,而在如“菜品—口感”和“其他—本次消费感受”等严重不平衡类别的表现不佳。
4 结 论
在本文的研究中,作者证实“预先训练模型+微调策略”模式在多标签文本分类问题研究的优异性能,展现ERNIE 2.0和ERNIE Tiny预先训练模型和STLR微调策略在用户评论多标签文本数据集上的突出表现。同时,作者也发现多标签分类损失函数的定义、预先训练模型的蒸馏压缩、微调策略的设计和超参数的设定,以及类别不平衡导致效果不佳的问题,都将是作者后续此类研究的突破点。
参考文献:
[1] 肖琳,陈博理,黄鑫,等.基于标签语义注意力的多标签文本分类 [J].软件学报,2020,31(4):1079-1089.
[2] 谢志炜,冯鸿怀,许锐埼,等.电力基建施工问题文本分类研究 [J].现代信息科技,2019,3(17):17-19.
[3] 孙明敏.基于GRU-Attention的中文文本分类 [J].现代信息科技,2019,3(3):10-12.
[4] ZHANG M L, ZHOU Z H. Multi-label Neural Networks with Applications to Functional Genomics and Text Categorization [J].IEEE Transactions on Knowledge and Data Engineering,2006,18(10):1338-1351.
[5] NAM J,KIM J,MENC?A E L,et al. Large-Scale Multi-label Text Classification — Revisiting Neural Networks [C]//ECML PKDD 2014:Machine Learning and Knowledge Discovery in Databases:Nancy:Springer,2014(8725):437-452.
[6] KURATA G,XIANG B,ZHOU B. Improved Neural Network-based Multi-label Classification with Better Initialization Leveraging Label Co-occurrence [C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.San Diego:Association for Computational Linguistics,2016:521-526.
[7] CHEN G B,YE D H,XING Z C,et al.Ensemble application of convolutional and recurrent neural networks for multi-label text categorization [C]//2017 International Joint Conference on Neural Networks(IJCNN).Anchorage:IEEE,2017:2377-2383.
[8] NAM J,MENC?A E L,KIM H J,et al. Maximizing subset accuracy with recurrent neural networks in multi-label classification [C]//NIPS'17: Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach:Curran Associates Inc.2017:5419-5429.
[9] YANG P C,SUN X,LI W,et al.SGM:Sequence Generation Model for Multi-label Classification [J/OL]. arXiv:1806.04822 [cs.CL].(2018-06-13).https://arxiv.org/abs/1806.04822.
[10] LIN J Y,SU Q,YANG P C,et al.Semantic-Unit-Based Dilated Convolution for Multi-Label Text Classification [J/OL]. arXiv:1808.08561 [cs.CL].(2018-8-26).https://arxiv.org/abs/1808.08561.
[11] YANG Z,LIU G J. Hierarchical Sequence-to-Sequence Model for Multi-Label Text Classification [J].IEEE Access,2019(7):153012-153020.
[12] HINTON G E,SALAKHUTDINOV RR. Reducing the Dimensionality of Data With Neural Networks [J].Science,2006,313(5786):504-507.
[13] PETERS M E,NEUMANN M,IYYER M,et al. Deep contextualized word representations [J/OL].arXiv:1802.05365 [cs.CL].(2018-02-15).https://arxiv.org/abs/1802.05365.
[14] RADFORD A,NARASIMHAN K,SALIMANS T,et al.Improving Language Understanding by Generative Pre-Training [EB/OL].[2021-05-20].https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf.
[15] DEVLIN J,CHANG M W,LEE K,et al.BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].(2018-10-11).https://arxiv.org/abs/1810.04805.
[16] ZHANG Z Y,HAN X,LIU Z Y,et al. ERNIE: Enhanced language representation with informative entities [J/OL].arXiv:1905.07129 [cs.CL].(2019-05-17).https://arxiv.org/abs/1905.07129v1.
[17] SUN Y,WANG S H,LI Y K,et al.ERNIE 2.0:A Continual Pre-training Framework for Language Understanding [J/OL].rXiv:1907.12412 [cs.CL].(2019-07-29).https://arxiv.org/abs/1907.12412v2.
[18] SUN S Q,CHENG Y,GAN Z,et al.Patient Knowledge Distillation for BERT Model Compression [J/OL].arXiv:1908.09355 [cs.CL].(2019-08-25).https://arxiv.org/abs/1908.09355v1.
[19] LI Z Y,DING X,LIU T. Story ending prediction by transferable bert [J/OL].arXiv:1905.07504 [cs.CL].(2019-05-17).https://arxiv.org/abs/1905.07504v2.
[20] LIU X D,HE P C,CHEN W Z,et al.Multi-Task Deep Neural Networks for Natural Language Understanding [J/OL].arXiv:1901.11504 [cs.CL].(2019-01-31).https://arxiv.org/abs/1901.11504v1.
[21] GOYAL P,DOLL?R P,GIRSHICK R,et al.Accurate, Large Minibatch SGD:Training ImageNet in 1 Hour [J/OL].arXiv:1706.02677 [cs.CV].(2017-06-08).https://arxiv.org/abs/1706.02677.
[22] HOWARD J,RUDER S.Universal Language Model Fine-tuning for Text Classification [J/OL].arXiv:1801.06146 [cs.CL].(2018-01-18).https://arxiv.org/abs/1801.06146v5.
[23] 周志華.机器学习 [M].北京:清华大学出版社,2016:33-35.
作者简介:孟晓龙(1988—),男,汉族,上海人,讲师,硕士学历,主要研究方向:数据挖掘与机器学习。
