基于Matlab的WOS地址字段提取与分析方法
2021-04-05颜斌
摘 要:为研究高校各二级单位对ESI某学科的贡献度,需对近十年来SCI和SSCIS收录论文(Article和Review)的地址字段信息进行自动化分析处理,以统计各学院机构的发文及被引频次情况。文章提出了一种基于Matlab的WOS地址字段提取与分析方法,可以高效快速地地检索WOS地址字段,筛选属于本校的地址字段,从中提取论文所属的二级单位英文名称并匹配所属首单位,进而分析计算各二级单位在不同学科下的论文贡献度。
关键词:ESI;Matlab;WOS地址字段
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2021)17-0065-04
Abstract: In order to study the contribution of each secondary unit in colleges to a discipline of ESI, it is necessary to automatically analyze and process the address field information of papers included in SCI and SSCIS (Article and Review) in recent ten years, so as to make statistics on the document issuance and citation frequency of colleges and institutions. This paper proposes a WOS address field extraction and analysis method based on Matlab, which can efficiently and quickly retrieve the WOS address field, screen the address field belonging to the college, extract the English name of the secondary unit to which the paper belongs and match the first unit, and then analyze and calculate the paper contribution of each secondary unit in different disciplines.
Keywords: ESI; Matlab; WOS address field
0 引 言
WOS(Web of Science)是美國科学情报研究(ISI)于1997年推出的基于网络的引文索引数据库,它将SCI、SSCI、AHCL这3个引文数据库集成在1个平台上,具备多数据库同时检索的功能[1]。ESI(Essential Science Indicator)又称为基本科学指标数据库,是科睿唯安公司推出的对科研机构研究成果及学科发展态势定量分析和评价的工具,也是“双一流”建设中对一流学科评价的极为重要的参考依据[2]。
ESI和WOS数据库是衡量科学研究绩效,跟踪科学发展趋势,评价高校、学术机构、国家/地区国际学术水平及影响力的重要评价工具[3],目前国内各高校都将学科是否进入ESI全球前1%以及ESI高被引论文的数量作为衡量高校学科发展的重要指标。高校图书馆是学校的学术性服务机构,为ESI学科建设服务已成为当前各高校图书馆发展的重要任务和研究课题[4]。
为了统计分析高校各二级单位在不同学科下的ESI发文总数及总被引频次数据,本文利用WOS数据库中的ESI期刊,选用近十年来Article和Review的论文,选取论文的地址字段作为分析的对象。从WOS数据库下载的论文信息的地址字段中包含作者姓名、学校英文缩写名称、学院机构英文名称等信息,为了准确快速地获取论文所属首机构的信息,需要对WOS地址字段进行数据清洗,检索匹配提取,进而分析计算各学院机构在不同学科下论文贡献度。何春建提出了一种从WOS地址字段提取二级机构数据的半自动数据清洗方法[5],刘贤玉介绍了利用WOS快速统计学校(学院)论文的技巧[6],谢群提出了一种在WOS中准确进行中文机构检索的方法[7]。为了保证数据的准确性,通常都是人工进行数据统计分析,但是工作量十分繁琐,工作效率极低;而上述提及的半自动清洗方法虽然提高了工作效率,但准确性较差。为了减少在数据处理过程中出现的人工误差并且提高工作效率,本文设计实现了一种基于MATLAB的WOS地址字段数据提取与分析方法(MW),可以快速高效的对大量论文的WOS地址字段数进行读取、检索匹配、分割提取、去重合并及计算分析,大大方便了日常工作。
1 MW方法介绍
1.1 函数表达
在本文中,主要利用了MATLAB的xlsread、writetable函数对文档进行读写操作,strcmp、strfind函数对数据进行检索匹配,regexp(A, a,' split')正则表达式对数据进行分割提取,unique、strcat函数对数据进行去重合并,.etc最后对得到的数据进行分析计算。
1.2 程序设计思路
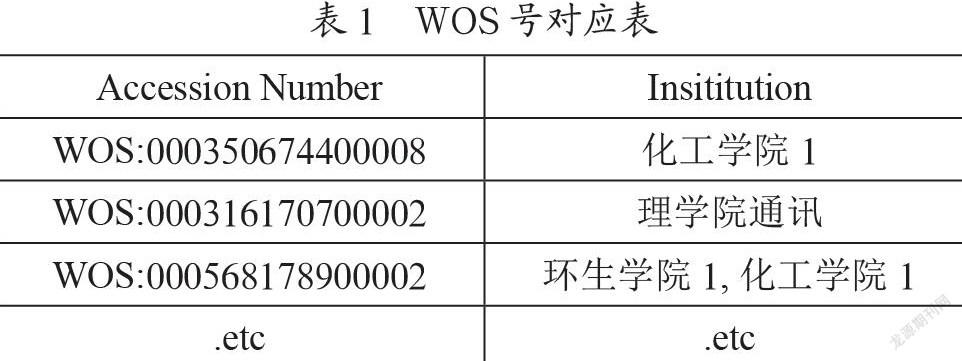
首先读取包含本校近十年来SCI和SSCI(Article和Review)论文的Excel文档,该文档中的论文信息不包含地址字段信息,因此需要根据论文的WOS号从WOS数据库下载的论文信息中检索匹配提取对应的地址字段信息,再截取地址字段信息中所需的学校缩写名称及学院机构英文名称形成新的地址字段信息,按截取顺序为其标序。在查询过程中发现有地址缺省的情况,对该种情况的论文进行人工查询,并将该篇论文的WOS号与其属于本校的首机构及序号信息一一对应,记录存储成如表1所示形式的“WOS号对应表.xlsx”Excel文档,以便以后查询。
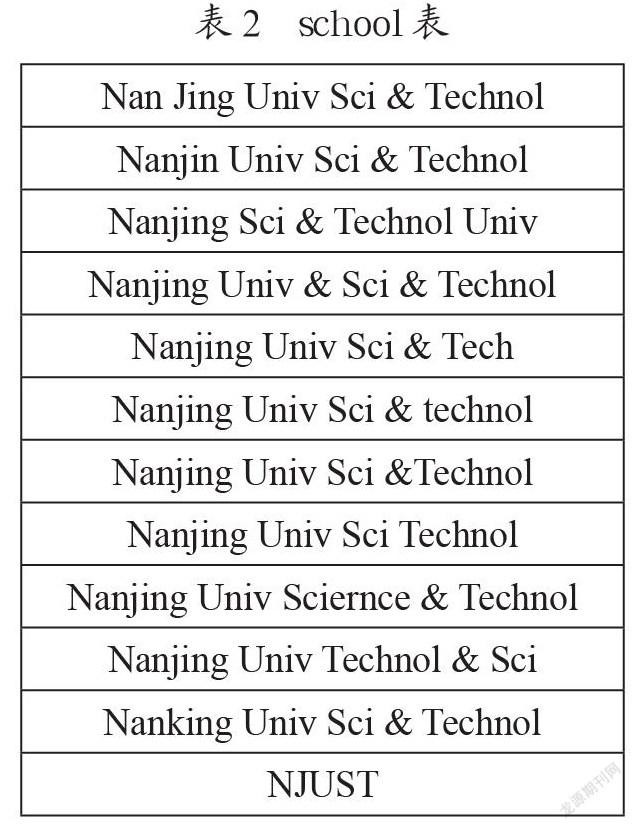
由于汉语拼音的因素带来英译重名及别称、俗称等情况[4],有的存在英文字符拼写错误的情况,学校缩写英文名称存在多种形式,本文统计的形式就有12种,将其汇总在如表2所示的“school.xlsx”Excel文档中,使用~ isempty(strfind(raw1, school))函数筛选属于本校的地址字段信息及序号。
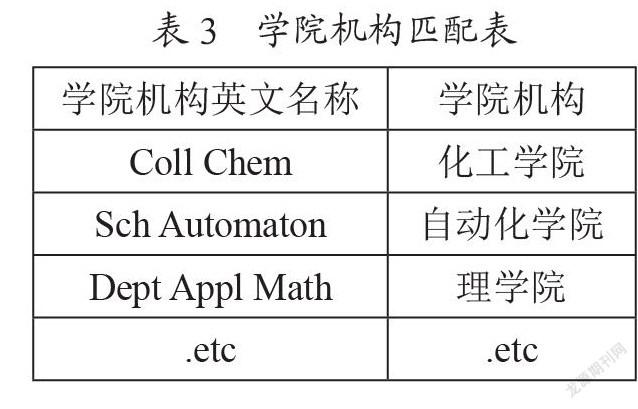
由于各学院机构和其包含的众多下属院系及机构存在众多英文名称,且存在英文字符拼写错误的情况,为了匹配筛选后属于本校的地址字段信息中包含的学院机构英文名称对应的中文学院机构名称,图书馆信息战略研究部的工作人员通过平时的积累记录形成了如表3所示形式的“学院机构匹配表.xlsx”excel文档(目前统计记录了31个学院机构)。
然后对筛选后得到的属于本校的地址字段信息进行处理,该地址字段信息包含需要查询的学院机构英文名称,通过isempty()函数从学院机构匹配表中检索匹配得到该篇论文所属的学院机构中文名称及其序号。针对一篇论文存在多个所属学院机构的问题,根据机构序号提取该篇论文的首学院机构信息,最后根据“Timesited”字段计算得到各学院机构的论文贡献度,将处理后的EXCEL文档输出并绘制相关饼状图。
程序设计流程图如图1所示。
2 MW方法设计
2.1 文档读写模块
使用xlsread函数对待处理的EXCEL文档进行读操作:
[~,~,raw1]=xlsread(filename1);
使用cell2table函数将数据转化为表格形式,再使用Writetable函数将处理后的数据输出为EXCEL文档:
T=cell2table(raw1);
Writetable(T,filename1,'WriteVariableNames',false)
2.2 数据检索匹配分割提取模块
為了获取本校近十年来SCI和SSCI(Article和Review)论文所属的学院机构信息,需获取地址字段信息,地址字段信息中包含该篇论文的学院机构英文名称。但是本校近十年来SCI和SSCI论文文档中的论文信息不包含地址字段信息,因此需要首先通过strcmp函数从WOS数据库下载的论文库中检索匹配论文的WOS号,根据WOS号一一对应提取出对应的地址字段,再通过strfind函数及regexp(A,a,'split')正则表达式分割提取得到的地址字段,截取所需的学校缩写名称及学院机构英文名称形成新的地址字段信息,并按截取顺序为其标序,那么A论文的地址字段截取成以下三段:1.[Nanjing Univ Sci & Technol, Sch Chem Engn];2.[Beijing Jiaotong Univ, Minist Educ, Key Lab Luminescence & Opt Informat];3.[Nanjing Univ Sci & Technol, MIIT Key Lab Adv Solid Laser]。该模块的核心代码由以下程序实现:
#检索匹配提取地址字段信息
If ( strcmp (raw1 {row_j , col1}, raw2{row_i , col2}))
test (row_j , 1) = row_j;
test (row_j , 2) = row_i;
raw1 {row_j, col1} = raw2{row_i , col2};
#分割地址
Address = regexp ( raw1{ row_j , col1 }, '; [', 'split' );#分割从WOS库中检索得到的地址字段
count = size (Address , 2);#分割的段数即总的通讯地址数
disp ( ['通讯地址数量:' , num2str ( count ) ]);
#对每个段进行分割
提取并形成新的地址字段添加到raw1中
if ~isempty(strfind(Address{1,y},'] '))
address=regexp(Address{1,y}, '] ', 'split');
raw1{row_j,col+y+1}= address{1,2};
else
raw1{row_j,col+y+1}=Address{1,y};
end
#通讯地址的序号
raw1{1,col+y+1}=y;
end
2.3 查询去重合并模块
首先通过isempty()及strfind()函数对截取的每一段地址字段信息进行筛选,得到属于本校的地址字段信息及序号。A论文属于本校的地址字段信息及序号为:1.[Nanjing Univ Sci & Technol, Sch Chem Engn];3.[Nanjing Univ Sci & Technol, MIIT Key Lab Adv Solid Laser]。然后读取学院机构匹配表的excel文档,使用isempty()及strfind()函数对地址字段中的学院机构英文名称逐一查询,检索到匹配项则返回该论文所属的学院机构中文名称及其序号,由于有的地址字段包含多个学院机构英文名称,返回的学院机构数据存在重复的情况,因此再使用unique()、strcat()函数对程序返回的学院机构数据进行去重合并操作,得到每篇论文所属的学院机构中文名称及序号,A论文的所属学院机构为[化工学院1,电子工程与光电技术学院3]。最后,使用writetable函数,将待查论文的所属学院机构信息数据输出成excel文档形式,该模块的核心代码由以下程序实现:
#筛选获取属于本校的地址字段信息
If ~isempty(strfind(raw1{row_j,col+y+1},school{1,s}))
#查询所属学院机构
If ~isempty(strfind(raw1{row_j,col+y+1},raw4{1,i}))
if isempty(raw1{row_j,raw1_col+y})
raw1{row_j,raw1_col+y}=
string([raw4{2,i},num2str(y)]);
else
raw1{row_j,raw1_col+y}=[raw1{row_j,raw1_col+y},string([raw4{2,i},num2str(y)])];
end
#去重及合并
raw1{I ,raw1_col+j}=unique
(raw1{i ,raw1_col+j});
count =size(raw1{i ,raw1_col+j},2);
if count >1
for c=2: count
raw1{i,raw1_col+j}(1)=strcat(raw1{i,
raw1_col+j}(1),',',raw1{i,raw1_col+j}(c));
end
raw1{i,raw1_col+j}=raw1{i,raw1_col+j}(1);
end
if ~isempty(raw1{i ,raw1_col+j})
raw1{i ,col1}=strcat(raw1{i,col1},',',
raw1{i,raw1_col+j});
end
2.4 提取首学院机构模块
由于一篇论文可能存在多个通讯地址的情况,为了便于统计,本文选用论文所属的首机构信息作为统计各二级机构在不同学科下论文贡献度的标准。在3.2节中已经获取了本校近十年来SCI和SSCI(Article和Review)论文所属的机构信息及序号信息。
在本节中,首先通过isempty()函数获得每篇论文通讯地址中所有机构字段的序号,再通过regexp(A,a,'split')正则表达式分割提取得到首机构序号,最后得到每篇论文所属的首机构信息,A论文的所属首机构为化工学院。该模块的核心代码由以下程序实现:
#获取所有学院机构字段的序号
if ~isempty(txt1{i,j})
raw1{i ,col1}=strcat(raw1{i,col1},',',
num2str(raw1{1,j}));
end
#分割提取首序号
if ~isempty(strfind(raw1{I ,col1},','))
address = regexp(raw1{i, col1}, ',', 'split');
raw1{i,col1}=address{1,1};
end
2.5 学科划分模块
为了模拟本校各二级单位在不同学科下的ESI发文总数及总被引频次数据,需要将近十年来WOS数据库中的ESI期刊论文(仅选取Article 和 Review)按学科进行划分(ESI下设22个学科),使用strcmp函数将3.4节获取的raw1中存储的数据信息按学科进行划分,得到22个学科每个学科下的各机构发表的论文信息。该模块的核心代码由以下程序实现:
#按22个学科进行划分
j =2;
for i =2:row
if strcmp(raw1{i , Area_col1},'subject')
raw3(j,:)=raw1(i ,:);
j=j+1;
end
end
2.6 数据计算分析模块
若该篇论文的首机构数目为n,引用次数为m,则每个首机构的该篇论文被引频次为m/n,该篇论文的占比为1/n。
最后计算每个学科下各二级单位的论文数N,被引频次M(N篇论文的引用次数和),得到篇均被引频次M/N。
本节以某学科为例,用表格和饼状图的形式分别直观的展示不同二级单位在论文数贡献度以及被引频次贡献度情况,如表4、图2、图3所示。
3 结 论
随着“双一流”建设步伐的加速,各高校对ESI学科建设日益重视。图书馆可通过模拟分析研究本校各学院机构对ESI不同学科的论文贡献度,作为评估学院及学校教师科研水平的重要指标,对学校潜力学科的挖掘及学院自身学术科研水平的发展有很大的指导意义。
本文主要设计实现了一种基于MATLAB的WOS地址字段数据提取与分析方法,通过分析本校各二级单位在ESI不同学科下的发表论文数贡献度及被引频次贡献度,以图表形式对比展示,了解某ESI潜力学科在不同二级单位的科研产出情况。
参考文献:
[1] 桑莱丝.SCI论文在科研水平评价中的地位和作用 [J].统计与决策,2007(15):59-60.
[2] 张宁,梁盟.高校图书馆服务ESI潜力学科建设探索——以山东农业大学图书馆为例 [J].图书馆学刊,2021,43(5):55-59.
[3] 毕玲玲,孙海燕,李延刚,等.基于ESI和InCites的高校潜力学科发展预测——以中国海洋大学为例 [J].内蒙古科技与经济,2021(12):113-116.
[4] 刘勇.“双一流”建设背景下高校图书馆服务ESI学科建设的内容与策略 [J].图书情报工作,2017,61(9):53-58.
[5] 何春建.从WOS地址字段提取二级机构数据的半自动数据清洗方法 [J].新世纪图书馆,2017(8):56-58+70.
[6] 刘贤玉,周小东.基于WebofScience快速统计学校(学院)论文的技巧 [J].图书情报工作,2013,57(S2):210-212+207.
[7] 谢群.在WebofScience中准确进行中文机构检索的方法研究 [J].图书馆论坛,2011,31(1):155-157+154.
作者簡介:颜斌(1996.02—),女,汉族,江苏省淮安人,助理馆员,硕士研究生,研究方向:图书馆、计算机。
