基于多标签的内核配置图及其应用
2021-04-01侯朋朋武延军于佳耕苗玉霞
侯朋朋 张 珩 武延军 于佳耕 邰 阳 苗玉霞
1(智能软件研究中心(中国科学院软件研究所) 北京 100190) 2(中国科学院大学 北京 100049)
(pengpeng@iscas.ac.cn)
Linux作为开源软件基石其应用场景广泛,从资源匮乏的边缘计算到云计算中心、超算中心均有广泛应用,不同应用场景需求各异,如边缘计算场景更关注内核大小,超算中心场景更关注系统性能.为适应复杂的应用场景,Linux提供了数量巨大的内核配置项便于灵活设置个性化内核.内核配置项覆盖广泛,涉及体系架构、文件系统、内存管理、安全加密、驱动设置等.内核配置项可使能或禁用内核模块或机制,如CONFIG_USB设置为Y(yes)M(model)则表示将USB模块直接编译或以可加载模块的方式进入内核,设置为N(no)则在内核编译时禁用该模块.除Y(yes)M(model)N(no)外,内核配置项值也可设置为其他值,如设置默认IO调度策略时可将CONFIG_DEFAULT_IOSCHED设置为“cfq”或“deadline”.
Linux内核灵活的配置项机制在内核裁剪、内核安全增强、内核性能优化等应用场景中均有广泛应用.以内核性能优化为例,Ren等人[1]基于Ubuntu的v3.0至v4.20内核版本的研究发现,造成Linux内核性能下降的原因有11项,其中涉及到内核配置项有8项,且涉及内核配置项带来的性能损失大于其他因素,通过调整内核配置项值等操作可将Redis,Apache,Nginx工作负载提高56%,33%,34%.
虽然Linux内核提供了灵活、全面的内核配置项,但正确使用这些配置项门槛高,难度大.配置项的数量巨大且增长快速,配置项的默认值在不同内核版本中经常改变,即使专业的内核团队要能够正确设置配置项也面临很多挑战.如图1所示[2],横轴表示Linux内核版本号,纵轴表示内核配置项数量.

Fig. 1 Kernel configuration item growth trend图1 内核配置项增长趋势
内核v5.3版本有15 000多个内核配置项,从内核v4.0版本到v5.3版本间增长了3 000多个配置项.Ubuntu内核4.16版本中已设置的内核配置项有7 520项,而当前Linux内核代码仍在快速增长,平均每小时接受8.5次代码提交[3],可预见内核配置项的数量会同步增长.为了适应新硬件、新场景,内核配置项值需要适时进行调整,如Ubuntu v3.1版本和v3.0版本的配置文件相比,删除配置项100项,新增配置项117项,此外还有13个配置项的值变更[4].专业的内核团队在设置内核配置项时也会出现错误,Ubuntu曾在v3.10版本中无意打开配置项CONFIG_CONTEXT_TRACKING_FORCE,该配置项的错误设置导致系统性能下降,直到v3.16版本中该配置项才被修复[5-7].
针对当前内核配置项数量巨大、难以理解、设置困难等问题,提出了一种基于多标签的内核配置图,该图包含内核配置项间的依赖关系(从中可得到父配置项标签和子配置项标签)、功能标签、性能标签、安全标签和配置项使能率(配置项在各个内核版本中的使能(enable)比例)标签.其中依赖关系属于配置项之间的关系,使能率标签属于配置项自身属性,功能标签、性能标签和安全标签不仅是配置项属性,也可以通过此3种标签为不同的内核配置项建立关联关系.该内核配置图可辅助内核开发人员高效理解和设置内核配置项,在内核启动优化、内核裁剪、内核安全增强、内核性能优化、内核配置项异常检测,内核配置项智能问答和内核配置项推荐等场景均可应用.该内核配置图提供了可视化功能,更加直观、高效、人性化.此外,本文将内核配置图应用到检索场景,设计了面向内核配置项的检索框架KCIR(kernel config information retrieval),该框架基于内核配置图中的标签信息和依赖关系分别对查询语句和内核配置项描述文本进行了扩展.实验表明与传统检索框架相比,KCIR对检索效果提升显著,通过对KCIR的有效性评估验证了内核配置图在实际应用中的有效性.
本文的主要贡献包括3个方面:
1) 提出一种基于多标签的内核配置图,包含内核配置项的依赖关系、功能标签、性能标签、安全标签,此外还包含了基于内核社区和主流发行版(Ubuntu和Fedora)的各个内核版本的使能率.
2) 提供内核配置图的可视化功能:配置项间的依赖关系可视化,基于标签的内核配置项聚类可视化,围绕配置项的多标签可视化.
3) 基于内核配置图实现了面向内核配置项的检索框架KCIR,并通过与传统检索框架的对比实验,表明KCIR对检索效果有显著的提升.
1 基于多标签的内核配置图的设计和实现
内核配置图包含配置项间的依赖关系、功能标签、性能标签、安全标签以及基于内核社区和主流发行版(Ubuntu和Fedora)的使能率标签,其中依赖关系属于配置项之间的关系,使能率标签属于配置项自身属性,功能标签、性能标签、安全标签这3种标签则兼顾了配置项属性也为不同的配置项建立了关联关系.
1) 内核配置项间依赖关系.内核系统中模块间依赖关系广泛存在,如文件系统Ext4,XFS等均依赖于VFS(virtual file system)模块,同时模块内的子模块间也存在依赖关系,如配置项CONFIG_EXT4_FS提供对Ext4文件系统[8]的支持,配置项CONFIG_EXT4_FS_SECURITY提供Ext4安全标签功能,只有配置项CONFIG_EXT4_FS使能后,配置项CONFIG_EXT4_FS_SECURITY才能生效.内核配置项可能依赖于多个配置项,同时也可能存在多个配置项依赖于该内核配置项.为了便于后续描述,我们定义2个关键词:
定义1.父配置项.将当前配置项直接依赖的配置项称为其父配置项.
定义2.子配置项.直接依赖于当前配置项的内核配置项称为其子配置项.
基于依赖关系可为当前配置项创建其父配置项标签和子配置项标签.
2) 功能标签.即根据内核配置项功能特征为其创建1个或者多个标签,如配置项CONFIG_NETFILTER_NETLINK_LOG涉及到了网络和日志2方面的功能,为其创建“network”和“log”2个标签.
3) 性能标签.即根据内核配置项性能特性为配置项创建1个或者多个标签.若内核配置项会影响系统的性能,不论该影响为正面影响或负面影响,均为其创建性能标签.性能标签主要包含CPU、内存、磁盘、网络4种.
4) 安全标签.该标签涉及的内核配置项有2类.一类配置项自身属于安全增强机制,如配置项CONFIG_SECURI TY_NETWORK本身就是安全机制的一部分;另一类配置项包含潜在的安全缺陷,如CONFIG_KVM涉及的KVM(kernel-based virtual machine)模块暴露过CVE-2019-19332等漏洞.
5) 使能率标签.即包括基于内核社区[9]的使能率和基于发行版的使能率.内核配置项若未设置则默认是禁用的,只有经过使能(enable)的配置项才能生效,如将配置项设置为Y(yes)或M(model).基于各内核版本中该配置项的使能情况计算出该配置项的使能率,使能率是量化配置项在实际应用中重要性的一个指标.将内核社区和主流发行版(Ubuntu和Fedora)区别对待是因为即使对同一内核配置项,两者的使能状态会有不同,如配置项CONFIG_RCU_TRACE在内核社区发布的4.15版本中使能,而Ubuntu的内核4.15版本中禁用;反之,配置项CONFIG_INTEL_IDLE在Ubuntu发布的内核4.15版本中使能,而在内核社区的版本中禁用.
内核配置图中的功能标签、性能标签、安全标签和使能率标签属于传统标签,其值是属性值;通过内核配置项间的依赖关系得到的父配置项和子配置项属于特殊标签,该类标签本身是内核配置项,而不是纯粹的属性值.
内核配置项间关联.如图2(a)所示,内核配置项间的关联关系主要通过依赖关系和3种标签(功能标签、性能标签、安全标签)建立.其中有向实线表示依赖关系,由父配置项指向子配置项;虚线关联的内核配置项属于同一标签,不同的虚线表示不同的标签类型,可以通过标签将没有依赖关系的配置项联系起来.内核配置图通过依赖关系和多种标签为配置项之间建立多元的关联关系.内核配置图为配置项从不同维度建立关联关系,挖掘配置项之间更深层次的关系,其要比传统的树结构组织方式更加丰富.
内核配置项自身属性.如图2(b)所示,内核配置项属性主要包括父配置项标签(CONFIG_FATHER)、子配置项标签(CONFIG_SON1,CONFIG_SON2)、功能标签、性能标签、安全标签、使能率,围绕配置项提供不同维度的属性信息,在开发人员使能或者禁用该配置项时可辅助决策.
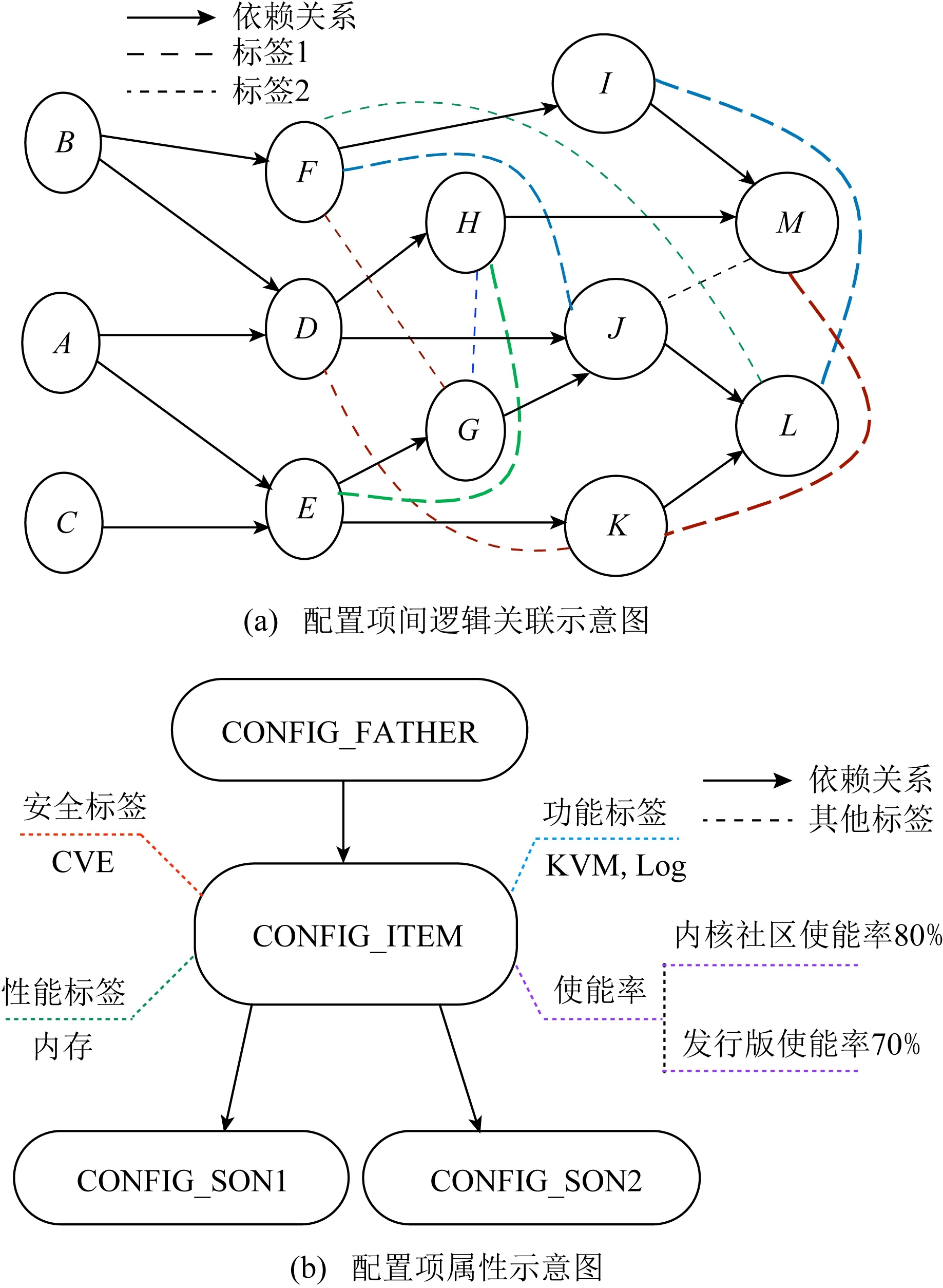
Fig. 2 Schematic diagram of kernel configuration items图2 内核配置示意图
内核配置图提供可视化功能,包括依赖关系可视化、功能标签聚类可视化、性能标签聚类可视化、安全标签聚类可视化和围绕内核配置项的多标签可视化,其可以辅助内核开发人员高效的理解和设置内核配置项,在内核启动优化、内核裁剪、内核安全增强、内核性能优化、内核配置项异常检测、内核配置项智能问答、内核配置项推荐等场景均可应用.
1.1 依赖关系
将内核配置项集合设为S={C1,C2,…,Cn},其中Ci表示第i个配置项,n表示集合中内核配置项的数目,依赖关系D定义为集合S上的二元关系,对于任意2个配置项Ci和Cj,且Ci,Cj∈S,若Ci的状态改变会影响Cj的状态,则配置项Cj依赖于配置项Ci,其依赖关系D定义为D={Cj,Ci|Ci,Cj∈S}.内核配置项间的依赖关系D是基于内核的Kconfig文件[10]抽取,内核配置项在Kconfig文件中的定义如图3所示,涉及到依赖关系的关键字有“depends on”“select”“imply”.其中“depends on”表示当前配置项依赖于其他配置项,CONFIG_NAME依赖CONFIG_A,即CONFIG_A为CONFIG_NAME的父配置项.“select”表示反向依赖关系即CONFIG_B依赖于CONFIG_NAME,即CONFIG_B为其子依赖项.“imply”是弱化版的“select”,表示反向依赖关系但强制性较弱.本文基于“depends on”“select”“imply”三个关键字构建配置项间的依赖关系.一个配置项可以有多个父配置项和多个子配置项,创建的内核配置项依赖关系图是一个有向无环图.

Fig. 3 Configuration item definition in Kconfig图3 Kconfig中内核配置项定义
基于依赖关系可获取内核配置项的父配置项和子配置项,父子配置项可看作特殊标签,其本身是内核配置项,同时也是当前配置项的标签.基于父子配置项通过递归操作可进一步得到其祖父配置项和子孙配置项,依赖关系具有传递性.在内核裁剪、内核优化等应用场景中,通常需要使能或禁用某内核配置项,基于依赖关系便于获取当前配置项的所有子孙配置项,利于分析该配置项变更的影响范围,如CONFIG_AUDIT配置项表示内核审计功能,若使能该配置项会给系统调用带来性能开销,但基于依赖关系易知SELinux[11]等安全机制均依赖于该配置项,若启用SELinux相关安全机制则不能禁用CONFIG_AUDIT配置项.此外,子孙配置项数目也是衡量配置项重要性的一个指标,若某内核配置项有30个子孙配置项,则其重要性通常大于没有子孙的内核配置项.
构建内核配置项间依赖关系时需关注不同体系架构带来的依赖关系差异,否则会引入潜在错误依赖信息.同一个内核配置项在不同平台下定义经常有差异,如图4中为内核配置项CONFIG_ARCH_HIBERNATION_POSSIBLE在ARM和ARM64架构下的定义,该配置项在ARM架构下依赖于配置项CONFIG_MMU,在ARM64架构下依赖于CONFIG_CPU_PM.若忽略不同架构差异则会引入错误的依赖关系,甚至导致依赖关系图从有向无环图变为有向有环图,而有向有环图会导致创建或获取依赖关系时陷入死循环,程序崩溃.
如图5所示,依赖关系构成一个有向有环的循环图(由父配置项指向子配置项),为了清晰展示图中省略了配置项的名称前缀“CONFIG_”,依赖关系中的“comm”表示该依赖关系属于多个体系架构的公共依赖关系,“ARM”表示该依赖关系针对ARM架构,“ARM64”表示该依赖关系针对ARM64架构.图5中产生循环的原因是将内核配置项CONFIG_CPU_PM和CONFIG_ARCH_HIBERNATION_POSSIBLE在ARM64架构中存在的依赖关系引入到ARM架构的依赖关系图中,而如图4所示,基于ARM架构的内核配置项定义中此两者并不存在依赖关系.

Fig. 4 CONFIG_ARCH_HIBERNATION_POSSIBLE under different architectures图4 不同架构下内核配置项CONFIG_ARCH_HIBERNATIO_POSSIBLE定义
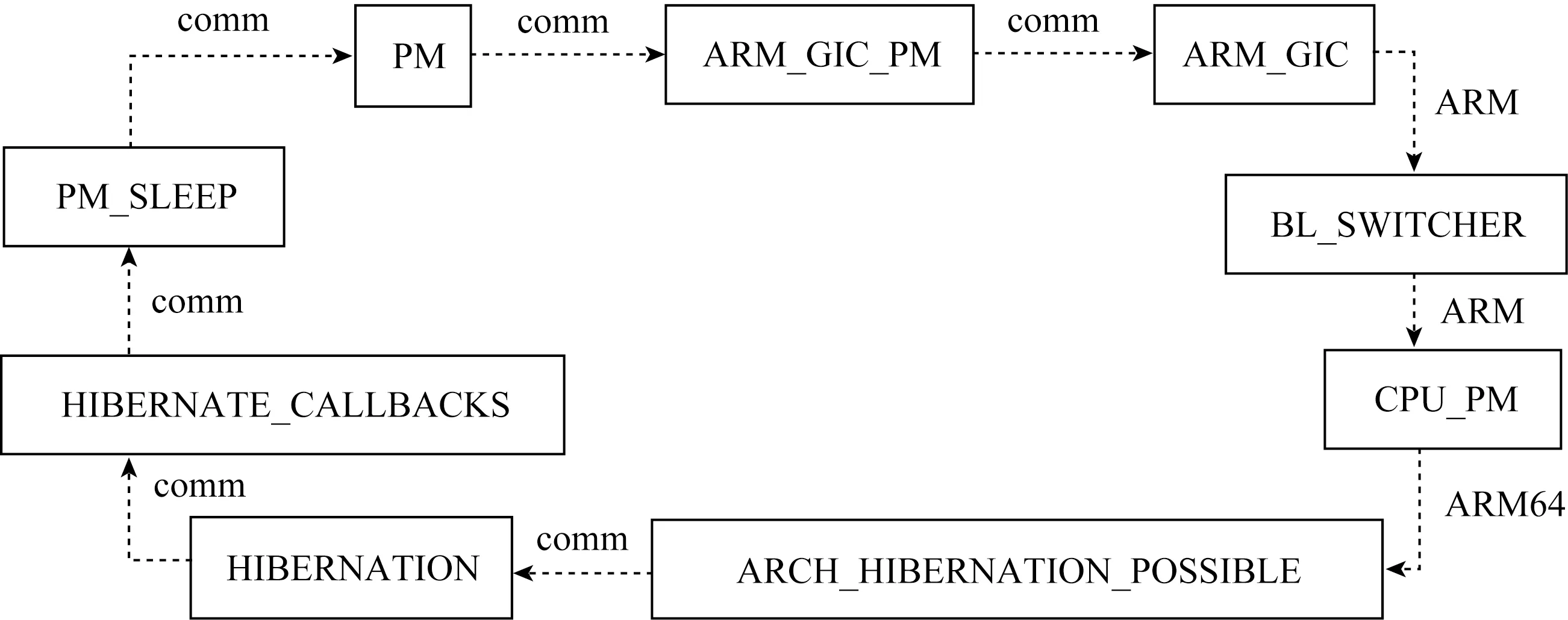
Fig. 5 Diagram of abnormal kernel configuration dependencies图5 内核配置项异常依赖关系图
1.2 功能标签
功能标签是基于内核配置项的功能描述生成的标签,其功能描述主要从内核自带的Kconfig,Documents,Git log等文档中抽取.功能标签的类型不仅包含内核模块中常见的机制如Filesystem(文件系统)、Memory manage(内存管理),也包括非模块功能如Log(日志)、Debug(调试)等标签,部分功能标签示例如表1.一个内核配置项可以有多个功能标签,如CONFIG_BFQ_CGROUP_DEBUG涉及Debug,Schedule,Cgroup这3个标签.
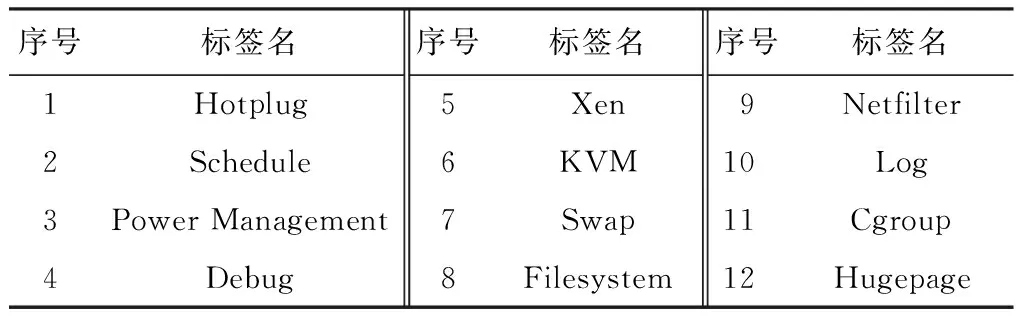
Table 1 Function Label Example表1 功能标签示例
功能标签等信息和依赖关系相互补充.很多内核配置项间没有依赖关系,但是存在其他潜在关联.如配置项CONFIG_XEN_MCE_LOG涉及Xen日志功能,配置项CONFIG_SCSI_LOGGING涉及SCSI(small computer system interface)日志功能,从依赖关系分析,CONFIG_XEN_MCE_LOG和CONFIG_SCSI_LOGGIN没有依赖关系,但是两者均涉及日志功能,可通过标签“Log”将2个配置项关联.相比依赖关系中的直观联系,标签更能深层挖掘出配置项间的潜在关联关系.
内核配置项采取多标签策略而不是分类策略是由于Linux内核功能复杂,很多功能模块或者机制并不能清晰归为某一类别,如内核源码文件夹中Ceph在Fs和Net目录下均有子目录;Bluetooth在Drivers和Net目录下均有子目录.配置项存在同样问题,一个配置项通常涉及多个子模块或机制.以CONFIG_PCI_XEN为例,其既可以归为Xen子类别,也可以归为PCI(peripheral component interconnect)子类别.内核配置项分类时,从不同角度会将配置项分入不同的类别,难以处理跨模块的配置项,而标签方式更加灵活,可以通过多标签将跨模块的配置项关联起来.
内核配置项数量巨大,仅Ubuntu 4.16版本中使能的有7 520个配置项,人工创建多标签工作量大、易出错.可借助Scikit-learn[12]中的多标签算法(如OneVsRest策略+支持向量机算法)来辅助多标签的生成:首先Linux专家创建标签并为每个标签挑选初始配置项,然后依据多标签算法为剩余配置项生成标签.在后续的性能标签和安全标签中均可借助Scikit-learn中的多标签算法辅助创建标签.
1.3 性能标签
研究显示内核配置项的错误设置已是当前内核性能降低的主要原因,Ren等人[1]发现内核配置项的错误设置会导致核心系统调用性能降低或波动,很多系统调用性能相比老版本显著下降,如poll,mmap,select等系统调用在内核V4.20比内核V4.0版本性能开销成本增长了100%.内核配置项对于系统性能影响很大,且内核系统很难优化,Red Hat和Suse通常需要6~18个月来优化上游Linux内核的性能[1];Google组织100多名工程师团队对数据中心的内核进行性能调优,对每个新内核的优化需要6~18个月的时间[1].为了辅助内核开发者通过配置项调试系统性能,本节针对配置项创建性能标签.
本文基于Linux内核提供的Kconfig,Documents,Git log等信息,评估配置项对系统性能的影响并生成标签,性能标签主要分为4种:内存、磁盘、网络、CPU.若某内核配置项对内存、磁盘、网络、CPU中的某一种或多种硬件资源性能有提高或降低,则为该配置项贴上相应的标签.性能标签示例如表2所示:

Table 2 Performance Label Example表2 性能标签示例
本文对内核配置项的性能影响没有依据性能提升或降低进一步创建标签,因为并非所有配置项对性能的影响都很明确,很多配置项对性能的影响与其使用的具体应用场景紧密相关.一些内核配置项对系统性能的影响比较明确,如CONFIG_AIO配置项支持异步IO,常被高性能多线程使用,使能后有利于提高CPU的性能,CONFIG_CONTEXT_TRACKING_FORCE配置项负责上下文的强制跟踪,该配置项使能后将会降低系统调用性能.另一些内核配置项对系统性能影响比较模糊,需要根据硬件环境、应用场景才能确定.如通过配置项CONFIG_DEFAULT_IOSCHED将IO调度策略设置为CFQ(completely fair queuing),该调度策略有利于提高传统机械磁盘的性能,但对SSD硬盘并不是最优调度策略,该配置项对系统性能的影响跟硬件紧密相关;配置项CONFIG_PARAVIRT_SPINLOCKS支持半虚拟化自旋锁,使能该配置项后可以提高KVMXen虚拟机CPU性能,但对宿主机性能有负面影响,该配置项带来的性能影响跟应用场景紧密相关.
1.4 安全标签
内核配置项对系统安全的影响有2种:
1) 配置项涉及安全模块或机制,使能该配置项后即为内核提供相关安全机制,该类为安全增强标签;
2) 配置项关联的功能模块本身存在潜在的安全隐患,使能该配置项后会将该模块中的安全隐患引入内核,该类为安全削弱标签.
2种安全标签分类基于内核的Kconfig,Docu-ments,Git log信息以及CVE(common vulnerabilities & exposures)[13]信息.
1) 安全增强标签.Linux内核核心安全机制均需要配置项支持,如SELinux机制需要CONFIG_SECURITY_SELINUX支持;AppArmor安全机制需要配置项CONFIG_SECURITY_APPARMOR支持.对系统安全有增强作用的内核配置项示例如表3所示,相关配置项使能后,其相关的安全机制会编译进内核,否则内核无法提供相关安全机制.安全增强标签有助于内核工程师判断该内核配置项对系统安全的影响.

Table 3 Security Enhancement Configuration Example表3 安全增强配置项示例
2) 安全削弱标签.一些模块包含潜在的系统漏洞,如KVM模块存在CVE-2019-14821系统漏洞,该漏洞可能导致主机内核崩溃,配置项CONFIG_KVM_GUEST使能后KVM模块会编译进内核,从而将该潜在漏洞引入内核.对系统安全有削弱作用的内核配置项的示例如表4所示,安全削弱标签可辅助内核工程师根据应用场景对配置项进行设置,如应用场景为边缘计算,则可考虑禁用CONFIG_KVM_GUEST避免安全隐患;如应用场景为云计算则应确认KVM模块中的潜在漏洞都已修复.

Table 4 Security Weaken Configuration Example表4 安全削弱配置项示例
1.5 使能率标签
内核配置项的依赖关系和其他标签均依据配置项本身的客观特性创建,未从实践应用的角度对配置项进行分析.提出内核配置项使能率,该指标对配置项在实践中使能情况进行统计,从实际应用角度衡量配置项的重要性.内核配置项的使能状态在不同版本中通常会有改变,如配置项CONFIG_UEVENT_HELPER在内核社区发布的v3.16至v5.1版本中均为使能状态,而在v5.2,v5.3,v5.4版本中则禁用.此外不同内核配置项间的使能率差异显著,如Ubuntu发行版v3.0至v4.20总计41个版本中,配置项CONFIG_KVM_GUEST均被使能,配置项CONFIG_IIO_HRTIMER_TRIGGER总计被使能14次,配置项CONFIG_IIO_STM32_TIMER_TRIGGER被使能0次.内核配置项的使能率反映其在所有内核版本中总的使能情况.内核配置项使能率越高,则认为其重要性越高,反之则认为其重要性越低.内核配置项使能率从实践应用角度为内核配置项的重要性提供一个可量化参考指标.
内核配置项使能率以各内核版本中的配置项的使能状态为基础,同时基于内核版本的发布时间引入时间权重.新版本的内核配置项的设置更适应当前硬件特性和功能需求,其参考价值大于老版本内核中的设置,因此新版本的权重大于老版本的权重.为了对不同内核版本的权重进行量化,本文引入了牛顿冷却定律,该定律描述物体温度随着时间的衰减情况,在计算机领域常被用来量化文章热度随着时间的衰减情况[14]等场景,本节利用该定律计算内核版本随时间衰减后的权重.内核版本vi的权重wi计算为
wi=wcur×exp(-α×(tcur-ti)),
(1)
其中,wcur表示最新发行版权重,默认值为1,tcur表示当前最新版本号,ti表示内核版本vi的版本号,α为衰减因子,当有新的内核版本发布时,所有老版本的权重均会衰减.引入权重后的配置项使能率(config enable rate, CER)RCER计算公式为
(2)
其中,RCER表示内核配置项基于各个内核版本计算出的使能率,enable为配置项在版本vi中的使能值,若配置项在该版本中使能则enable=1,否则enable=0.
本文分别基于内核社区和主流发行版(Ubuntu和Fedora)发布的内核版本计算内核配置项使能率.
1) 基于内核社区的使能率.Linux内核社区是Linux内核最权威研发机构,负责Linux内核版本的开发、维护和发布.该社区聚集了最权威的内核开发人员,且有严格的开发流程保障内核代码质量,所以内核社区发布版中的配置项设置具有极高的权威性和参考价值,因此本文基于内核社区发布的各版本计算内核配置项使能率.
虽然内核社区发布的版本具有极高权威性,但由于内核应用场景广泛,从简易IC卡到超级计算机均有应用,为覆盖复杂的应用场景,内核社区对配置项设置时通常比较保守,故本文还参考了Ubuntu和Fedora发行版的内核配置项设置.
2) 基于主流发行版使能率.主流发行版选择了Ubuntu和Fedora,Ubuntu是服务器市场应用最广泛的Linux发行版[15],且在个人用户市场占据较大的份额.Fedora由全球最大开源软件公司红帽支持开发,其特色为追求并吸纳最新技术,该发行版也是RHELCentos系发行版的试验田.发行版针对内核进行多方面调整和优化,很多配置项的设置与内核社区存在差异.如内核配置项CONFIG_BLK_DEV_RAM_SIZE负责设置RamDisk的大小,内核社区为适应资源匮乏的应用场景如边缘计算,将其设置为16 384,Ubuntu的应用场景资源通常比较充足,因此将其设置为65 536;选择磁盘调度策略时,内核社区使能内核配置项CONFIG_IOSCHED_CFQ,选择对传统机械磁盘友好的策略CFQ,而Fedora新版本中使能内核配置项CONFIG_IOSCHED_BFQ选择对新兴固态SSD硬盘更友好的BFQ(budget fair queueing)策略.基于Ubuntu和Fedora发行版的使能率可以从实践应用角度为内核开发者提供参考.
内核配置图中包含了内核配置项的依赖关系、功能标签、性能标签、安全标签、使能率的信息,可广泛应用在很多场景,如内核优化时可借助内核配置图的性能标签对内核配置项进行筛选;内核裁剪时可借助内核配置图的依赖关系了解禁用某配置项带来的影响;内核编译失败时可借助内核配置项使能率辅助检查配置项设置是否异常.此外,内核配置图在内核配置项的推荐、检索、智能问答等场景也可应用.下一节将以内核配置图在内核配置项检索场景应用为例,进一步说明和验证内核配置图在实际应用中的有效性和实用性.
2 内核配置图在检索场景中的应用
本节将以内核配置图在内核配置项检索场景中的应用为例,说明内核配置图的实用性.当前Linux内核v5.3版本已有超过15 000个配置项,导致内核工程师很难熟悉和掌握,查找目标配置项时存在时间成本高、效率低的问题.主流Linux发行版自带的搜索工具apropos等仅支持对于本地命令、文本等搜索,并不支持内核配置项的搜索,且Linux现有的文本内容检索工具都是关键字匹配,检索效果不佳,为高效查询内核配置项,本节基于内核配置图实现了一个面向内核配置项的本地检索框KCIR.
传统信息检索框架如图6(a)所示,将查询语句query和内核配置项的描述文档config_doc作为入参,经过相似度算法计算得到查询语句和配置项的相似度.本文基于内核配置图提出检索框架KCIR,该框架的优化主要包括查询语句扩展和配置项描述信息文档扩展.
1) 查询语句扩展.研究表明,用户输入的查询语句通常较短,包含关键字平均仅有2.4个单词[16],只有约25%的查询语句能够清晰表达用户意图[17],即使用户清楚自己查询目的,也通常无法输入准确的查询关键字[16],本文借助内核配置图对于查询语句进行扩展,有助于提高查询效果.
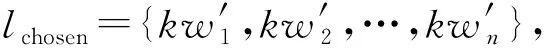
qenhance=qinit∪lchosen.
(3)
2) 内核配置项描述信息扩展.配置项的描述信息主要来源于Linux内核官方自带的Kconfig及Documents等文档,相比第三方信息源,内核官方文档更加专业可信,但存在自然语言中不可避免的语义模糊、描述不够准确等问题.
基于内核配置图中的依赖关系对配置项描述信息进行扩展:从配置项依赖关系图中可获得当前配置项的父子配置项信息,可使用父子配置项描述信息对当前配置项的描述信息进行补充和扩展.如内核配置项CONFIG_MEMCG_SWAP跟Cgroup的内存功能紧密相关,但其在Kconfig中描述信息不够充分,如图7所示,其描述信息中缺少“memory”等相关关键字,其父配置项CONFIG_MEMCG和其子配置项CONFIG_MEMCG_SWAP_ENABLED在Kconfig中的描述如图7,其中包含“memory”等关键字,父子配置项描述信息可对配置项CONFIG_MEMCG_SWAP的描述信息进行补充.
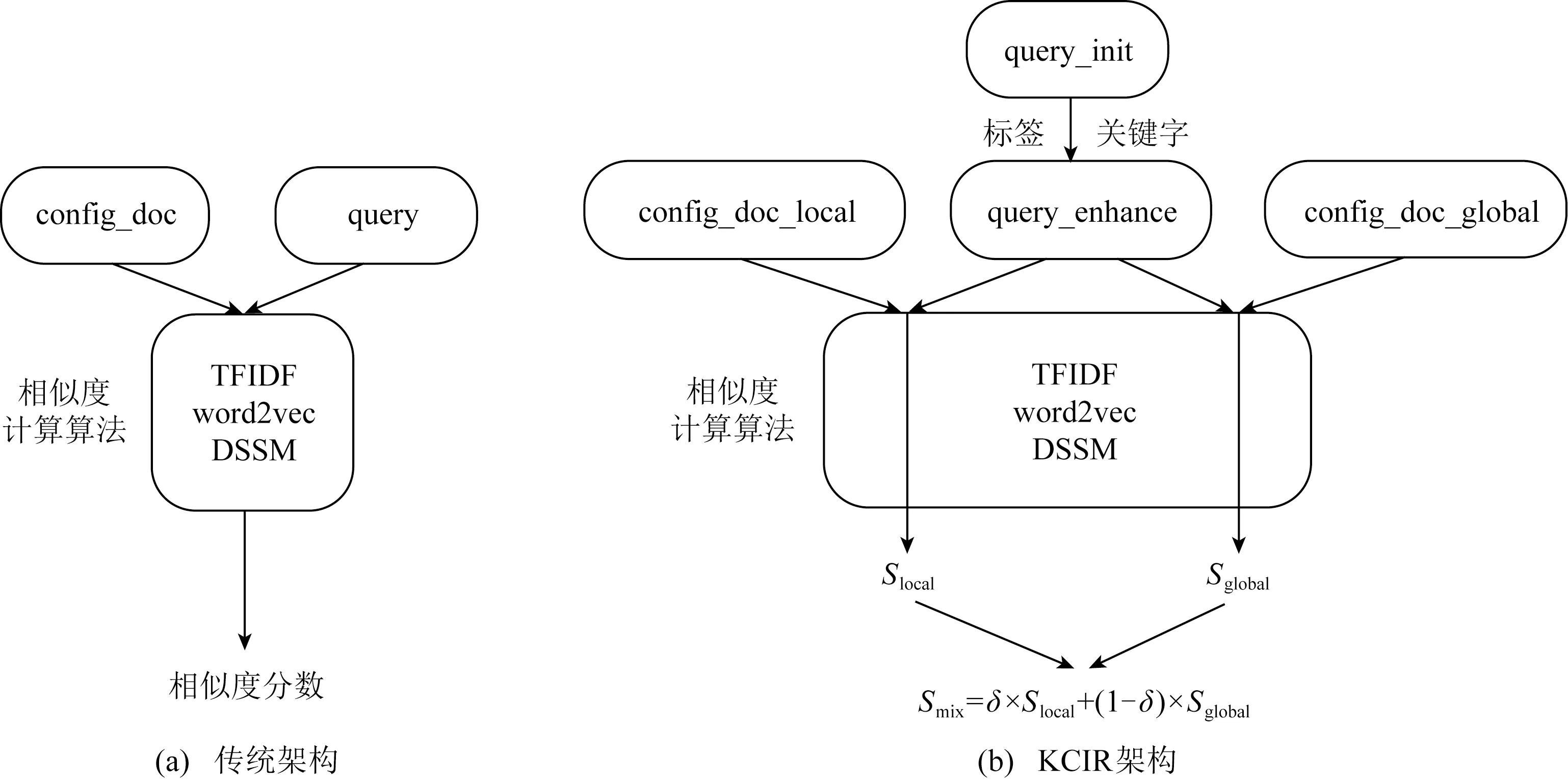
Fig. 6 Configuration item retrieval tool architecture图6 内核配置项检索工具架构
将配置项本身的描述信息称为局部配置项信息,将融合了父子配置项的描述信息称为全局配置项信息,CONFIG_MEMCG_SWAP的全局配置项信息扩展示意图如图7所示.在检索时分别基于局部和全局的配置项描述信息进行相似度计算,然后将两者得到的相似度加权相加,得到最终相似度.
基于查询语句扩展和内核配置项描述文档扩展后的检索框架KCIR的逻辑架构图如图6(b)所示.首先将初始查询语句qinit扩展后得到新查询语句qenhance,将qenhance和配置项局部描述信息dlocal通过相似度算法得到相似度分数Slocal,将qenhance和配置项全局描述信息dglobal经过同样的相似度算法得到相似度得分Sglocal,最后基于Slocal和Sglobal得到混合后相似度分数Smix.
Slocal=sim(dlocal,qenhance),
(4)
Sglobal=sim(dglobal,qenhance),
(5)
Smix=δ×Slocal+(1-δ)×Sglobal,δ∈(0,1),
(6)
其中,式(4)(5)中的相似度算法sim可以是传统算法如TF-IDF(term frequency-inverse document frequency)[18]或基于深度学习算法DSSM(deep structured semantic models)[19]等.
此外,若实际场景中更注重应用频率较高的内核配置项,则可基于配置项使能率对内核配置项设置权重.应用频率越高的内核配置项的使能率越高,则其权重越高.
本节以检索场景为例描述了内核配置图在实践中的应用,基于内核配置图实现了检索框架KCIR,该框架主要优化点是:1)使用功能标签对查询语句进行了扩展;2)使用依赖关系对配置项的描述文档进行扩展.
3 实验与评估
3.1 内核配置图可视化
内核配置图提供的可视化功能包括依赖关系的可视化、功能标签聚类可视化、性能标签聚类可视化、安全标签聚类可视化、内核配置项的多标签可视化.鉴于很多内核配置项名较长,如CONFIG_ACPI_TABLE_OVERRIDE_VIA_BUILTIN_INITRD和CONFIG_AMD_MEM_ENCRYPT_ACTIVE_BY_DEFAULT,为了展示更清楚,可视化图中省略了内核配置项的前缀“CONFIG_”.由于内核配置项数量巨大,为了较清晰地显示相关可视化信息细节,对可视化图进行适当简化.
1) 依赖关系可视化.在实际应用中常需要了解某一内核配置项的依赖关系,以评估该内核配置项的影响,因此提供了配置项依赖关系可视化.对某一内核配置项,可根据设置的祖先配置项和子孙配置项的递归深度对其依赖关系进行可视化展示,默认可视化显示当前配置项的父配置项和其所有子孙配置项.图8为内核配置项CONFIG_CPU_FREQ的依赖关系可视化图,有向连接从父配置项指向其子配置项,图8中显示了内核配置项CONFIG_CPU_FREQ的直系父配置项CONFIG_SCHED_MC_PRIO和14个子孙配置项.从图8中也可看出依赖关系并不符合树结构逻辑,树结构一般仅有1个父节点,而图8中配置项CONFIG_CPU_FREQ_GOV_ATTR_SET有2个父节点CONFIG_CPU_FREQ_GOV_COMMON和CONFIG_CPU_FREQ_GOV_SCHEDUTIL.

Fig. 8 Visualization of CONFIG_CPU_FREQ dependency图8 CONFIG_CPU_FREQ依赖关系可视化图
2) 功能标签聚类可视化.功能标签聚类可视化主要围绕功能标签显示相关内核配置项,如图9所示.在图9中以实线六边形表示功能标签,Cgroup(控制组)、Debug(调试)、Sched(调度)分别表示3个功能标签.一个内核配置项可有多个相关标签,如配置项CONFIG_BFQ_CGROUP_DEBUG同时和Cgroup,Debug,Sched这3个标签均有关联.

Fig. 9 Visualization of function label图9 功能标签聚类可视化图
3) 性能标签聚类可视化.性能标签聚类可视化主要围绕CPU、内存、网络、硬盘4个维度显示相关内核配置项.以CPU性能标签为例,如图10所示,以虚线椭圆表示性能标签,CPU标签关联的内核配置项均和CPU性能相关,如配置项CONFIG_SCHED_MC针对多核CPU进行调度策略优化.

Fig. 10 Visualization of CPU label图10 CPU标签聚类可视化图
4) 安全标签聚类可视化.安全标签分为2个子标签,即安全增强标签和安全削弱标签.安全增强标签如图11,secur_en表示安全增强,跟该标签关联的内核配置项均对系统安全有积极意义,如配置项CONFIG_SECCOMP使能则允许使用SECCOMP技术安全的运行非信任代码.安全削弱标签如图12,secur_wk表示安全削弱,跟该标签关联的内核配置项存在潜在的安全漏洞,如配置项CONFIG_KVM存在过CVE-2019-7221漏洞.

Fig. 11 Visualization of security enhanced label图11 安全增强标签可视化示意图

Fig. 12 Visualization of security weakened label图12 安全削弱标签可视化图

Fig. 13 Multi-label visualization of CONFIG_BFQ_GROUP_IOSCHED图13 CONFIG_BFQ_GROUP_IOSCHED多标签可视化图
5) 内核配置项多标签可视化.多标签可视化主要包括父配置项标签、子配置项标签、功能标签、性能标签、安全标签、使能率.以内核配置项CONFIG_BFQ_GROUP_IOSCHED为例,其多标签可视化图如图13所示,该配置项对于Disk(硬盘)性能(虚线椭圆)有影响,其功能标签(实线六边形)涉及Cgroup和Sched,其父节点包括配置项CONFIG_BLK_CGROUP和CONFIG_IOSCHED_BFQ,子配置项为CONFIG_BFQ_CGROUP_DEBUG.以实线椭圆标签表示使能率,其中“0.00L”中的L表示Linux社区,0.00为相应使能率;“0.40U”中U表示Ubuntu,“0.56F”中的F表示Fedora.因此图13中的0.00L_0.40U_0.56F表示该配置项在内核社区中的使能率为0,在Ubuntu发行版中加权后的使能率为0.40,在Fedora发行版中加权后的使能率为0.56.内核社区的内核配置项策略比较保守,更倾向选择传统调度策略CFQ而不是对新兴SSD硬盘更友好的BFQ策略,因此基于内核社区的内核配置项CONFIG_BFQ_GROUP_IOSCHED的使能率为0,Ubuntu发行版对SSD硬盘提供了一定的支持,其对内核配置项CONFIG_BFQ_GROUP_IOSCHED的使能率高于内核社区,Fedora发行版更倾向于新技术的应用,在新版本中均选择策略BFQ,因此对内核配置项CONFIG_BFQ_GROUP_IOSCHED的使能率较高.
内核配置项CONFIG_BFQ_GROUP_IOSCHED不涉及安全相关特性,故图13中并没有安全标签,我们以配置项CONFIG_SECURITY_SELINUX多标签可视化图为例展示安全标签,如图14所示,其中虚线六边形标签为安全标签,标签secur_en表示该配置项对安全有增强作用,标签secur_wk表示该配置项涉及潜在安全隐患,隐患信息为CVE-2017-2618.

Fig. 14 Multi-label visualization of CONFIG_SECURITY_SELINUX图14 CONFIG_SECURITY_SELINUX多标签可视化图
3.2 内核配置图在检索中应用评估
本节对基于内核配置图的面向内核配置项的检索框架KCIR进行评估,KCIR逻辑架构如图6(b)所示,该框架分别对查询语句和配置项描述文本进行扩展增强,适用于多种文本相似度算法.本节分别基于4个具有代表性文本相似度算法VSM[20],LSI[21],Word2vce[22],DSSM[19]对KCIR和传统检索框架进行对比评估.本实验中KCIR的局部配置文本和全局配置文本的权重值即式(6)中统一设置δ=0.3.
1) VSM(vector space model)算法.VSM是20世纪70年代被提出,是信息检索中的经典检索算法,该算法将文本内容的处理简化为向量空间中的向量运算,以空间上的相似度表达语义的相似度.本实验中VSM算法没有设置超参数.
2) LSI(latent semantic indexing)算法.LSI是主题模型的代表算法,简单实用、逻辑清晰,基于奇异值分解得到主题模型,同时解决词义的问题.本实验中LSI算法中的主题参数设置为500.
3) Word2vec算法.Word2vec是词嵌入代表算法,该算法可将词语映射为词向量,其核心思想是利用简单神经网络对词的上下文训练得到词的向量化表示.可基于词向量计算文本间的相似度.本实验中Word2vec算法中的特征维度设置为71,移动窗口设置为10,采用skip-gram训练算法.
4) DSSM算法.DSSM是基于深度神经网络计算文本相似度的代表算法,基于深度神经网络把查询和文本转化为低纬语义向量,并通过余弦相似度计算2个语义向量的距离,此外根据用户的点击进行有监督学习,最终训练出语义相似度模型.本实验使用微软提供的基于DSSM模型已训练好的文本转化向量工具[23]对查询和文本进行转换.
本文基于4个算法进行实验评估,介绍实验中的基准数据.
1) 基准数据.当前针对文本相似度评估有很多可用的数据集,但已有的数据集如新闻数据和内核配置项的文本数据特征差异较大,针对内核配置项检索缺少可用的基准数据集,因此我们邀请Linux专家提供了一个针对内核配置项的包含178条query-doc数据的数据集,该数据集覆盖内存、虚拟化、文件系统、网络、进程、安全、电源、调试等内核模块,平均每个模块20条左右基准数据.基于该数据对检索结果评估.该基准数据格式如表5所示,包含查询语句和相应的目标配置项.

Table 5 query-doc Example表5 query-doc示例
2) 评估指标.在基准数据中,每组基准数据包含查询语句和目标配置项信息,本实验将查询语句作为入参,查看返回的TopK结果中是否包含目标配置项,若包含则该query-doc为命中状态,统计命中状态的query-doc条目数量作为评估指标,其中TopK的K取值分别为1,3,5,7,9.
3) 结果分析.本实验使用的基准为传统检索框架,其逻辑架构图如图6(a)所示,使用该框架与本文提出的KCIR框架对比评估.检索框架KCIR主要包含2点优化策略:
1) 基于内核配置图中的标签对查询扩展;
2) 基于内核配置图中的依赖关系对内核配置项描述信息扩展.
评估时首先对KCIR中的2个优化策略分别评估,然后对KCIR进行总评估.实验使用内核社区发布的v5.4版本内核,基于VSM,LSI,Word2vec,DSSM这4个相似度算法分别对检索框架KCIR和传统检索框架进行对比评估,以验证框架KCIR的有效性.
基于VSM算法评估结果如图15所示,对于TopK(1,3,5,7,9)分别统计:传统检索框架、KCIR中查询扩展优化、KCIR中描述文档扩展优化、KCIR框架(综合查询扩展和描述文档扩展)共4种情况的检索结果,其中传统检索框架作为基准数据.从图15易知KCIR的查询扩展和描述文档扩展策略均可提高检索效果.与传统检索框架相比,KCIR中的查询扩展策略可将TopK命中率提升5.26%~18.18%,KCIR中的描述文档扩展策略可将TopK的命中率提升3.92%~7.27%,KCIR检索框架可将TopK命中率提升8.27%~27.27%.
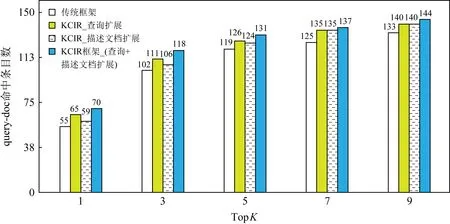
Fig. 15 Retrieval results based VSM图15 基于VSM算法评估结果
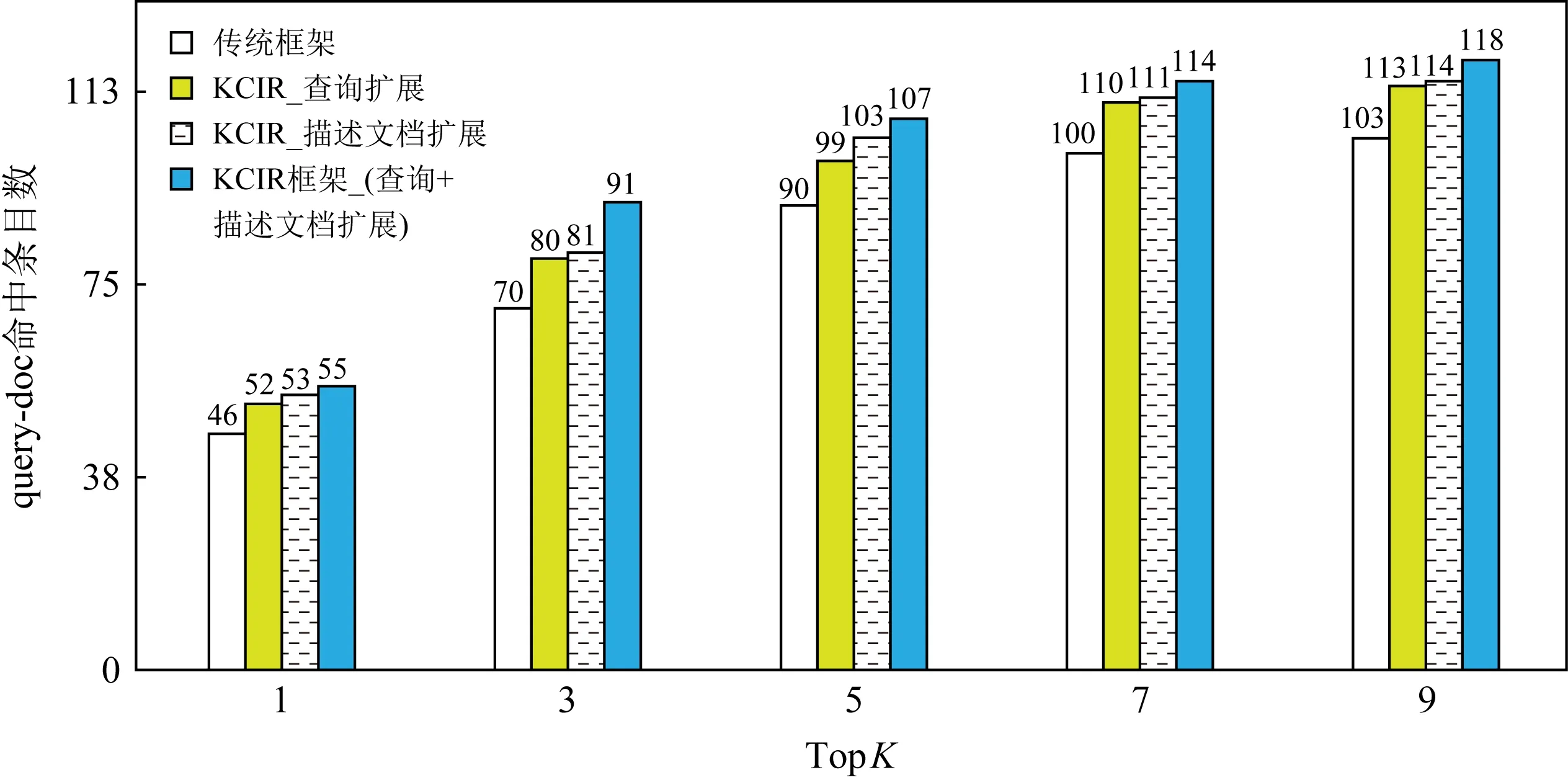
Fig. 16 Retrieval results based LSI图16 基于LSI算法评估结果
基于LSI算法评估结果如图16所示,与传统检索框架相比,KCIR中的查询扩展策略可将TopK命中率提升9.70%~14.28%,KCIR中的描述文档扩展策略可将TopK的命中率提升10.67%~15.71%,KCIR检索框架可将TopK命中率提升14.00%~30.00%.
基于Word2vec算法评估结果如图17所示,与传统检索框架相比,KCIR中的查询扩展策略可将TopK命中率提升3.09%~15.87%,KCIR中的描述文档扩展策略在Top1上带来了4.44%的下降,在Top3~Top9将命中率提升5.00%~12.79%,KCIR检索框架可将TopK命中率提升6.66%~22.22%.

Fig. 17 Retrieval results based Word2vec图17 基于Word2vec算法评估结果
基于DSSM算法评估结果如图18所示,与传统检索框架相比,KCIR中的查询扩展策略可将TopK命中率提升0.00%~14.51%,KCIR中的描述文档扩展策略可将TopK的命中率提升4.34%~11.29%,KCIR检索框架可将TopK命中率提升6.08%~29.03%.

Fig. 18 Retrieval results based DSSM图18 基于DSSM算法评估结果
本文研究点是检索框架而不是具体算法的改进优化,重点关注检索框架KCIR和传统检索框架的对比分析.通过4个相似度算法的评估可见,与传统检索框架相比,基于内核配置图的检索框架KCIR对检索效果有显著提升:将基于VSM算法的TopK命中率提升了8.27%~27.27%,将基于LSI算法的TopK命中率提升了14.00%~30.00%,将基于Word2vec算法的TopK命中率提升了6.66%~22.22%,将基于DSSM算法的TopK命中率提升了6.08%~29.03%.
4 下一步工作
在内核裁剪、内核优化等场景常需要对内核定制化的设置和修改,内核配置项数量巨大,人工修改会引入一些错误的设置[24],并对系统造成严重负面影响,如CONFIG_CONTEXT_TRACKING_FORCE设置不当会严重影响系统的性能.基于内核配置图可对修改后的配置项值进行异常检测,从内核配置图中可抽取配置项的多种特征信息如基于内核社区和发行版的使能率、子孙配置项数量等,然后借助异常检测算法如Isolation Forest算法等对内核配置项进行异常检测并生成最终的检测报告表,示例如表6所示,表6包含了配置项当前的设置值、核心特征数据以及最后的检测建议(是否).

Table 6 Example of Abnormal Detection Report表6 异常检测报告示例
5 相关工作
5.1 内核配置项
当前针对内核配置项的研究工作比较多元,研究者从配置文件Kconfig语法、内核配置项对Linux系统性能和安全的影响、内核配置项和源代码的关联等不同角度进行多样化研究.文献[25]中,El-Sharkawy等人对内核配置项的定义文件Kconfig语义进行分析,发现Kconfig存在语义模糊的现象,且说明文档中对于一些特殊情况缺少相关描述.此外他们对现有的Kconfig分析工具的有效性进行了评估,分析结果有助于Kconfig分析工具的改进.文献[1]中,Ren等人对Ubuntu v3.0至v4.20横跨7年的不同内核版本的系统调用性能进行分析对比,发现内核配置项的错误设置是导致系统性能波动或下降的重要原因,同时Linux内核优化成本很高,并不适合个人或小团队去做.文献[2]中,Acher等人针对内核构建中出现的因内核配置项错误设置导致的构建失败问题,提出了一个TuxML工具框架,该框架可以辅助内核配置项的设置,避免内核构建错误.文献[26]中,Walch等人提出了一个基于SAT的内核配置项形式化分析方法,该方法帮助开发者了解内核配置项的相关问题,如针对特定架构的处理器哪些选项是必须配置的,哪些选项是不能设置的.文献[27]中,Ziegle等人对内核配置项和其影响到的代码文件的关联关系进行分析,发现大部分内核配置项仅影响较少的代码文件,仅有少数内核配置项会影响到几乎所有代码文件.文献[24]中,Melo等人对内核配置项的相关警告进行分析,通过对40万条警告信息进行统计和分类,发现Linux中包含大量与内核配置项相关的警告,且很多警告对系统影响严重.文献[28]中,Acher等人对基于内核配置项的内核裁剪进行研究,发现基于机器学习对配置项进行设置时由于内核配置项数量巨大,导致算法搜索空间随之变大,对于配置项的预测结果误差很大;当缩小内核配置项的范围后可有效提高内核配置项的预测,并对内核裁剪提供帮助.
5.2 Linux检索工具
当前针对Linux的检索工具基本可以分为2类:1)针对文本内容的检索工具;2)针对文件名的检索工具.文本内容检索的代表工具有Grep[29]和Apropos[30].Grep是本地查询工具,在指定目录和文件中根据关键字进行匹配,Apropos根据关键字在系统的文档和手册中进行匹配,跟Grep相比,Apropos有2个区别:1)Apropos不需要指定目标目录和文件,搜索范围为系统自带的文档和手册;2)Apropos的检索目标是命令行或者函数等,查询相关帮助文档.Grep和Apropos均是系统自带的本地检索工具.文件名检索的代表工具有Find[31],Locate[32],Fsearch[33],这些工具主要基于关键字对文件名进行匹配,而不是文本内容检索.Find根据用户指定目录进行检索,Locate和Fsearch会进行整个系统检索.此外还有专有检索工具如Which[34]专门搜索系统命令的绝对路径地址,Lawall等人[35]针对Linux驱动信息检索进行了研究.当前还没有针对内核配置项的检索工具,现有Linux检索工具并没有针对内核配置项的数据特征(如配置项间存在依赖关系)进行优化,本文基于内核配置图,提出了针对内核配置项的检索框架KCIR,该框架属于文本内容检索.
6 总结与展望
本文提出了一种基于多标签的内核配置图(1)基于多标签的内核配置项及KCIR的开源版本代码参见https:gitee.comkcirkcir,该图包含内核配置项的依赖关系(从中可得父配置项和子配置项标签)、功能标签、性能标签、安全标签、配置项使能率标签.此外,内核配置图提供可视化功能,更加直观、高效、人性化.该内核配置图在内核裁剪、内核安全增强、内核性能优化、内核配置项异常检测、内核配置项智能问答和内核配置项推荐等场景均可应用.为了验证内核配置图在实际应用中的有效性,将内核配置图应用到检索场景,设计实现了面向内核配置项的检索框架KCIR,该框架使用内核配置图对查询和配置项文本信息分别扩展,实验评估表明该框架相比传统的检索框架可显著提升检索效果,也从实践角度证明内核配置图的有效性和实用性.未来工作中,将内核配置图的信息进一步增强,如添加内核配置项带来空间大小信息,同时将内核配置图应用到更多的场景,如内核配置项异常值检测等.
