一种面向对象结合变差函数的高分辨率遥感影像茶种植区自动提取方法
2021-03-30张世超王常颖李劲华张志梅
张世超,王常颖,李劲华,张志梅
(青岛大学 数据科学与软件工程学院,山东 青岛 266071)
0 引言
茶属于山茶科多年生常绿木本植物。作为一种植物饮料,因其含有多种营养物质,深受大众的喜爱与欢迎。改革开放40年来,我国茶产业发展取得了巨大的成就,产业规模、效益、质量均显著提高[1],因此,茶种植区的监测工作对我国经济发展具有重要意义。
茶种植区广泛分布于我国长江以南地区,传统的人工野外勘测方法需要耗费大量的人力物力,时效性差,精度低,不能及时有效地获取茶种植区空间分布信息。遥感技术具有准确、及时地获取信息的天然优势,故使用遥感监测的方法实现对茶种植区的自动提取是可行的。茶树属于灌木,大多数种植在山区、丘陵地区,茶树低矮且呈球形,以小规模种植为主,由于光谱特征与其他农作物种植区的相似性,茶种植区的遥感识别工作具有一定的难度。目前,基于遥感影像的农作物提取方法的研究多以常规作物为主,例如水稻、小麦、棉花、玉米等,对茶种植区的提取研究较少。邓媛媛等[2]使用QuickBird遥感影像,采用面向对象的分类技术,进行农用地精细分类;任传帅等[3]提出了一种利用单时相高分二号高分辨率卫星影像和随机森林算法的香蕉林信息提取方法;姬旭升等[4]利用高空间分辨率遥感影像对作物进行识别,更加快速、准确地获取枣树和棉花的种植面积及其分布区域;黄健熙等[5]利用GF-1 WFV数据实现了玉米与大豆的提取;徐伟燕等[6]使用资源三号影像数据,结合光谱特征、NDVI时相差异以及方向强度纹理特征,实现了茶种植区的提取;马超等[7]提出一种基于中尺度光谱和时序物候特征的茶园提取方法;Li等[8]引入了集成学习策略以在训练过程中改进经典的支持向量机和反向传播神经网络分类器,有效提高了农作物分类精度;Zhou等[9]提出了一种基于深度学习的时间序列分析方法,并应用于高分辨率ZY-3图像和Sentinel-1A SAR数据集,对湖南和贵州的农作物类型进行分类;Sun等[10]提出了一种基于层次感知的方法对VHR图像中的作物进行分类;周静平等[11]采用面向对象和决策树相结合的方法提取了作物分布信息。以上研究对农作物的提取取得了一定的成效。
本研究选取贵州省铜仁市4块矩形区域作为研究区,采用的影像数据为高分辨率航拍影像。提出了一种基于面向对象与变差函数的茶种植区自动提取方法。首先,利用eCognition 9.0软件对原始影像进行多尺度分割,采用面向对象的方法构建分类规则集,去除非植被区域,包括道路、建筑物、水体;然后,利用茶种植区与其他植被区域的变差函数纹理特征差异构建决策树分类模型,同时选择最合适的纹理提取窗口,得到最终的茶种植区的提取结果。本研究期望对茶种植区遥感监测提供借鉴,也为作物的种植管理提供帮助。
1 研究区概况及数据源
1.1 研究区概况
铜仁市位于贵州省东北部,武陵山区腹地,处于云贵高原向湘西丘陵过度的斜坡地带,西北高,东南低。全境以山地为主,占全境总面积的67.8%。铜仁市镜内地形复杂,气候立体分布特征明显,大多数地域属中亚热带季风湿润气候区。春温多变,绵雨较多;夏季炎热,光照充足;秋季阴雨天较多;冬季低温寡照,物长季长。年平均气温15 ℃到17 ℃。铜仁市境内降水充沛,平均降雨量为1 100~1 300 mm,地表河流密度高,地下补给基流多。由于这些外部环境条件优势,非常适合茶等常绿植物种植,其中铜仁市石阡县享有“最美茶乡”的美誉。贵州的茶树70%种植于海拔800~2 000 m的高原地区,茶种植区附近有大量林地、梯田、农田等其他植被区,茶树成排种植,非常适合采用遥感影像对茶种植区信息进行提取。
1.2 数据源
实验数据为获取于2014年6月6日的航拍遥感影像,总共包含3个波段,空间分辨率为0.5 m。本文首先选取了一景位于贵州省铜仁市、大小为25 292像元×19 192像元的影像数据作为面向对象方法的实验数据,经纬度范围为27°29′54″N~27°35′05″N,108°22′26″E~108°30′05″E。裁剪7景局部影像作为选择提取窗口大小的实验数据,之后,选取4块位于贵州省铜仁市的矩形区域作为测试数据,其大小分别为5 561像元×4 479像元、4 421像元×4 857像元、3 821像元×3 569像元、8 001像元×11 501像元。经纬度范围分别为:27°41′05″N~27°42′18″N,108°27′50″E~108°29′32″E;27°50′01″N~27°51′20″N,108°26′41″E~108°28′03″E;27°42′02″N~27°43′01″N,108°36′25″E~108°37′35″E;27°35′05″N~27°38′12″N,108°35′06″E~108°37′31″E。研究区总面积为37.98 km2。研究区内地物种类多样,适合做茶提取实验。
2 研究方法
2.1 基于面向对象的非植被区信息提取
1)影像分割。传统的基于像元的分类方法单纯考虑遥感影像的光谱信息,未利用纹理、形状等非光谱信息。由于高分辨率遥感影像中存在大量的同物异谱、同谱异物现象,分类精度往往不高,而面向对象的方法有效解决了这个问题。影像分割是面向对象分类方法的基础[12-14]。目前最常用的影像分割方法是eCongition软件中的多尺度分割,即分形网络演化法。分形网络演化法从像元层次开始,基于保证整体异质性最小的原则,采用相邻影像区域两两合并增长的方法形成更大影像对象,直到在规定的尺度上不能再进行任何对象的合并为止。面向对象分类方法以影像对象作为最小分类单元,综合利用光谱、纹理、形状等信息,有效提高了分类精度。本研究采用eCongition 9.0中的多尺度分割方法,分割参数设置如下:分割尺度为175;3个波段权重都为1;形状因子为0.4;紧凑度因子为0.5。
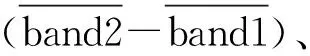
(1)亮度(brightness)。亮度是影像对象各波段光谱均值的加权平均值。本文所用遥感数据有3个波段,且设置各个波段权重都为1。
(2)形状指数(shape index)。反映了影像对象边界的平滑度。
(3)灰度共生矩阵标准差(GLCM StdDev)。反映了像元值与均值偏差的度量。
(4)灰度共生矩阵熵(GLCM Entropy)。反映了图像信息量的度量。

3)分类规则构建。本研究基于不同地物在6种特征上的差异性,实验了每个特征的阈值,通过构建分类规则集来对非植被区进行高精度提取。构建的分类规则如表1所示。

表1 分类规则
4)非植被区提取结果。本文选取一景25 292像元×19 192像元大小的影像数据作为面向对象方法的实验数据,图1展示了原始影像和去除非植被区后的掩膜结果。

图1 原始影像和去除非植被区后的掩膜结果
2.2 基于变差函数的茶种植区信息提取
1)变差函数。地统计学中的变差函数(variogram function,VF)是对区域化变量结构分析的工具,同时也是描述对象非均质性的手段。从地统计学的角度看,遥感影像的像元灰度值可以看作是满足内蕴假设的区域化变量,它既具有随机性,又具有空间相关性[15-16]。本文采用3个波段下的像元值计算影像的变差函数值。
2)变差函数纹理分析及决策树模型构建。本文选取了茶种植区与包括农田区、梯田区及林地区在内的其他植被区的7处感兴趣区域,其中包括3处茶种植区、2处农田区、1处梯田区及1处林地区。感兴趣区域如图2所示。由于滞后距离h具有方向性,本研究计算了0°、45°、90°和135° 4个方向上,滞后距离h从1到40之间不同地物的变差函数值。构建的变差函数曲线如图3所示,其中水平轴代表滞后距离,垂直轴代表变差函数值,即VF值。

图2 感兴趣区域
图3 茶区和其他植被区的VF曲线
从滞后距离4个方向上茶区和其他植被区的VF曲线可以看出,对于茶区来说,由于茶树成排种植方式的缘故,在某些滞后距离方向上,变差函数曲线为波浪状的曲线;以第2景茶的感兴趣区域为例,茶的种植方向为90°方向,当滞后距离方向同样为90°方向时,即当茶的种植方向与滞后距离方向平行时,其变差函数曲线是呈现一个逐渐上升的趋势,变差函数曲线没有呈现波浪状,而在滞后距离为其他3个方向时,变差函数曲线均呈现波浪状。对于其他植被区,在任何一个滞后距离方向上,变差函数曲线均呈现持续上升的趋势,最后趋于一个较为稳定的值。由此得出,至少存在一个滞后距离方向上,茶区在滞后距离h在[3,7]范围内变差函数值取得第一个极大值,在[8,13]范围内变差函数值取得第一个极小值,且从极大值到极小值有较大下降幅度,而其他植被区在任一滞后距离方向上,此滞后距离大小范围内不存在极大值和极小值。
本文定义了滞后距离在[3,7]范围内变差函数值取得的最大值A,滞后距离在[8,13]范围内变差函数取得的最小值B,以及滞后距离在[3,7]范围内的取得的最大值A和滞后距离在[8,13]范围内的取得的最小值B之差与滞后距离在[3,7]范围内的取得的最大值A的比值descender 3个特征变量,表达如式(1)至式(3)所示。
A=max{γ(3),γ(4),γ(5),γ(6),γ(7)}
(1)
B=min{γ(8),γ(9),γ(10),γ(11),γ(12),γ(13)}
(2)
(3)
式中:γ(x)为当滞后距离为x时的变差函数值。
以A和descender作为输入特征,构建了茶区与其他植被区的决策树分类模型,如图4所示。

图4 决策树分类模型
3 结果与分析
3.1 最佳茶区提取窗口大小及窗口滑动步长分析
本文在采用面向对象的方法剔除非植被区的基础上,利用决策树中的分类规则区分茶区与其他植被区。采用滑窗法进行茶区检测,对于影像中的每一个像元,在包含这个像元的所有正方形窗口(边长为k)中,如果其中超过一半的窗口被判断为茶区,则将该像元归为茶区。提取窗口大小k及窗口滑动步长s的选择直接影响到最终的提取精度。本文选取了7景含有茶的局部影像,采用40×40、50×50、60×60、70×70、80×80、90×90和100×100共7种尺寸窗口,每种尺寸窗口下采用10、15、20、25 4种窗口滑动步长来对茶种植区进行提取,并对每种情况下的提取精度进行评价。原始影像、目视解译图及当窗口滑动步长为10,不同窗口大小下的茶提取结果如图5至图11所示。
为了衡量不同窗口大小与窗口滑动距离下的提取精度,本文采用查准率(precision)和查全率(recall)作为参考,F1度量作为主要评价依据,其定义分别如式(4)至式(6)所示。
(4)
(5)
(6)
式中:TP为真正例,表示提取的茶区为真实茶区的像元数目;FP为假正例,表示提取的茶区为非茶区的像元数目;FN表示假反例,表示提取的非茶区为茶区的像元数目。
构建了窗口滑动距离为10、15、20、25下的3种评价指标随窗口大小的变化曲线图,如图12所示。分析4张曲线图可以得出,在任意一种窗口滑动距离下,均为当窗口大小为60像元×60像元时F1度量达到最大值。同时,当窗口大小为60像元×60像元时,窗口滑动距离为10,F1度量是最高的,达到81.34%。这说明窗口滑动距离选择10,窗口大小选择60像元×60像元提取效果是最佳的。

图5 原始影像1、对应的目视解译结果及滑动步长为10时不同窗口大小下的茶区提取结果

图6 原始影像2、对应的目视解译结果及滑动步长为10时不同窗口大小下的茶区提取结果

图7 原始影像3、对应的目视解译结果及滑动步长为10时不同窗口大小下的茶区提取结果

图8 原始影像4、对应的目视解译结果及滑动步长为10时不同窗口大小下的茶区提取结果
图9 原始影像5、对应的目视解译结果及滑动步长为10时不同窗口大小下的茶区提取结果

图10 原始影像6、对应的目视解译结果及滑动步长为10时不同窗口大小下的茶区提取结果

图11 原始影像7、对应的目视解译结果及滑动步长为10时不同窗口大小下的茶区提取结果

图12 提取精度变化曲线
3.2 本文方法提取结果与精度分析
采用本文方法对研究区域进行茶区提取实验。原始影像、目视解译图、采用本文方法茶区提取结果及局部提取结果如图13至图21所示。

图13 研究区1结果

图14 研究区2结果

图15 研究区3结果

图16 研究区4结果

图17 局部区域1结果

图18 局部区域2结果

图19 局部区域3结果

图20 局部区域4结果

图21 局部区域5结果
为了客观评价本文方法的提取精度,将目视解译结果作为评价样本,统计得到茶区的提取精度,同时与文献[6]的方法进行对比,如表2所示。可以看出,使用本文方法茶区的生产者精度达到74.50%,用户精度达到83.69%,与文献[6]的方法相比,生产者精度和用户精度均有所提高。本文方法依旧存在不足之处,有部分分布比较稀疏的茶区没有提取出来,主要原因是这部分茶区排与排之间的距离偏大,导致这部分茶区的变差函数值在指定距离范围的下降幅度不够或没有出现下降趋势。另外,还有少量的林地被错分为茶区。

表2 茶提取的精度评价结果 %
4 结束语
本研究基于高精度提取茶种植区的实际需要,采用0.5 m空间分辨率的航拍影像,选择贵州省铜仁市4块矩形区域,提出了一种面向对象结合变差函数的茶种植区自动提取方法。得出了以下结论。
1)采用面向对象的方法实现了非植被区的高精度提取,综合利用影像的光谱、纹理、形状等信息,有效解决了基于像元的方法由于高分辨率遥感影像中同物异谱、同谱异物现象的存在而出现大量错分的问题。此外,排除了非植被区的干扰,为下一步茶种植区的提取奠定了基础。
2)基于茶区与其他植被区在变差函数纹理特征上的差异,构建了决策树分类模型,采用滑窗法对茶种植区进行高精度提取。经过精度评价得出本文方法茶区提取的生产者精度达到74.50%,用户精度达到83.69%,说明本文方法对茶种植区进行提取是可行且有优势的。
3)从实验监测的结果来看,本文方法依旧存在少量林地被错分为茶区,少量较稀疏茶区漏分的情况。在下一步的研究工作中将考虑融合更多的辅助特征数据,进一步提高茶区提取精度。
