城市轨道交通司机驾驶水平评价模型研究
2021-03-30刘杰,徐敏
刘 杰, 徐 敏
(1.重庆工程职业技术学院 智能制造与交通学院, 重庆 402260;2。重庆公共运输职业学院 运输贸易系,重庆 402247)
随着城市轨道交通的迅猛发展,列车自动驾驶系统(以下简称:ATO系统)技术也广泛应用在城市轨道交通日常运营中,尽管ATO技术已经相当成熟,但仍不能完全替代人工驾驶。司机驾驶的主要目的是当控制系统出现故障或发生突发事件时,可由人工驾驶列车完成运营任务,否则会造成列车滞留区间或车站,从而阻塞整个线路。多数地铁公司规定晚8点后全部正线列车切换为人工驾驶模式。在人工驾驶模式下,对乘客提供的服务水平质量完全由司机驾驶水平决定。随着大数据和人工智能时代的到来,基于数据趋动的城市轨道交通智能化管理将成为未来发展方向,而司机驾驶水平管理将会成为其中重要的一部分,因此设计以列车数据为基础的司机驾驶水平评价模型,不仅可以提高运营风险抵御能力,而且可以作为司机岗位管理的重要依据。
1 问题描述
司机驾驶水平的好坏可以从安全、准点、舒适和节能4个指标来评判,列车行车记录系统记录的时间速度时序是最能体现上述4个指标的数据,而且数据较易获得[1]。人工驾驶和ATO时间速度数据绘制成坐标曲线的形式如图1、图2所示。

图1 人工驾驶过程
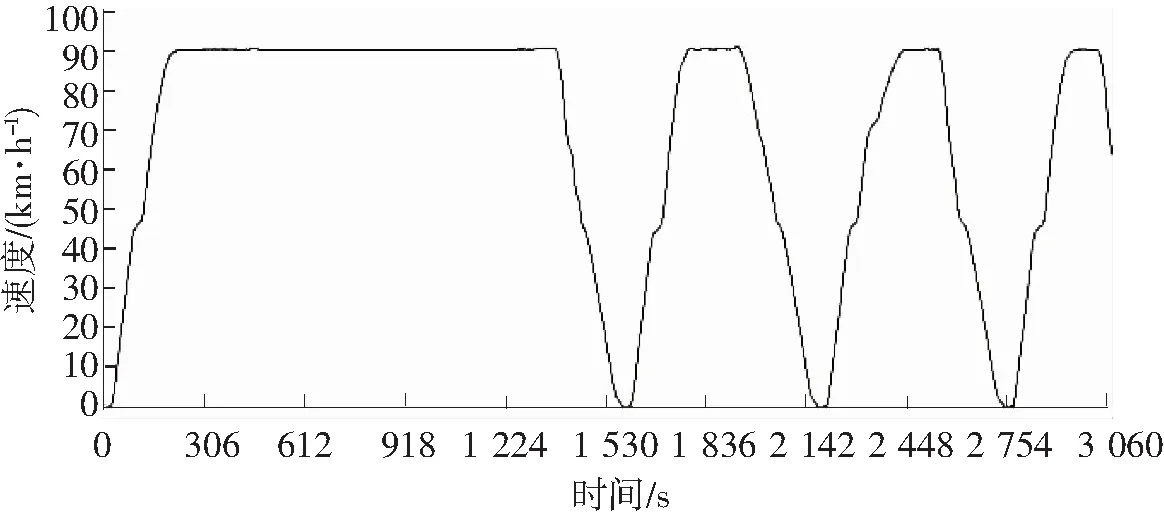
图2 ATO自动驾驶过程
从图1和图2可看出,时间速度曲线分为人工驾驶和ATO 2种。根据经验,ATO驾驶水平普遍高于人工驾驶。以ATO自动驾驶时序数据为标准,研究如何对人工驾驶时序数据等级评价的问题。具体方法是:利用程序从行车系统导出的文件中抽取原始数据,再用数据挖掘技术提取原始数据特征信息得到特征时序,再用降维技术降低数据复杂度得到样本集,然后构建聚类算法和模糊综合评价混合模型对样本集做出评价,最后分析评价结果。
2 数据处理
2.1 特征提取
直接采用行车记录系统提取的原始数据作为样本会产生2个问题。一是特征信息量不够导致聚类效果不明显;二是维度不一致导致数据无法统一处理。采用python语言编写的tsfresh包提取时序数据特征,tsfresh能够提取出超过64种特征,这样既能挖掘原始数据潜在特征信息,又能统一所有时序数据维度[2]。原始序列表达式如下
(1)
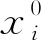
经过特征提取后的时序表达式如下
(2)
(3)
(4)
式中,f为tsfresh特征提取作用函数;D为原始时序集;M为样本总数;S′为特征提取后的时序集。
2.2 降维
采用聚类算法对时序数据进行等级划分,而聚类的效果很大程度取决于样本的维度,特征提取后的样本维度通常较高,如果直接聚类不仅效果不佳,模型复杂度也显著增加,影响算法效率,因此需要对特征提取后的样本降维。考虑到高维空间可能存在的流形结构 ,采用非线性t-sne降维算法[3],表达式如下
(5)
S={x1,x2,…,xM}
(6)
式中,xi为样本;g为t-sne降维算法作用函数;S为样本集。
3 模型建立
规定评价等级为5级,分别为优、良、一般、及格、差。模型分为3个阶段,第一阶段用一种聚类算法将样本集按规定等级数量聚为5类,模型表达公式如下
(7)
(8)

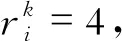
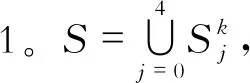

(9)
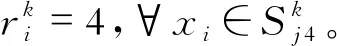

每一种聚类算法都有其应用局限性,并且不同聚类算法对相同样本集都会有不同聚类结果,因此采用单一聚类算法其结果可靠性不高。为了解决这一问题,模型第二阶段将多种聚类算法的结果用模糊综合评价算法处理,最后确定样本等级,公式表达如下
(10)
式中,φ为模糊综合评价算法作用函数。
具体算法如下[4]:
步骤1。确定评价因素集U={u1,u2,…,uK},这里的因素集元素就等同于聚类算法,确定评语集V={0,1,2,3,4}。
步骤2。确定评价因素权重向量W=[w1,w2,…,wk…,wK],wk由聚类算法本身效果决定。无标签聚类算法效果评价指标主要有SC(Silhouette Coefficient),CH(Calinski-Harabasz Index),DB(Davies-Bouldin Index)3种,其中,SC、CH值越大表明效果越好,而DB值越接近于0效果越好,综合3个指标的信息给出权重公式如下[5]
(11)
(12)
(13)
(14)

Akv为第k种聚类算法对第v等级隶属度
(15)
由模型第一和第二阶段得出的ri是一次实验结果,因为各种聚类算法内部随机因素的存在,导致每次实验结果会有所不同,因此考虑到模型的稳定性,在模型第三阶段采用多次实验取众数的方法最终确定评价结果,公式表达如下
(16)
(17)

因为司机的整个驾驶过程由若干条人工驾驶样本组成,所以形成一条评价等级序列,再利用模糊综合评价算法对该等级序列进行处理,得到司机驾驶水平评价等级结果。
(18)
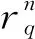
这里算法和模型第二阶段类似,唯一改变的是评价因素权重向量W的计算方法
(19)
4 实例分析
随机抽取某地铁6号线17个车运行记录数据为研究对象,采用python3.6编程抽取得到4 219条时序原始数据,即M=4 219,其中,ATO自动驾驶3 407条,人工驾驶812条。经过tsfresh特征提取后每条时序数据维度统一为794维,再用t-sne算法将其降至2维。所有人工驾驶样本属于8位司机,即N=8。聚类算法选择K-means[6]、层次聚类[8]、谱聚类[7]和高斯混合聚类[9],即K=4。运用提出模型计算得到4种聚类算法一次实验结果见图3[10-11]。

图3 一次聚类实验结果
从图3可看出,4种聚类算法的聚类效果都很明显。再设H=1 000, 8位司机驾驶过程等级变化情况见图4。

图4 8位司机驾驶过程等级变化情况
最终司机的评价等级如表1所示。

表1 司机驾驶水平评价等级
5 结论
多种聚类算法和模糊综合评价混合模型可以规避单一聚类算法自身缺点,同时能定量给出最终评价结果。从结果来看,抽样的8位司机当中3位处于中等水平以下,3位中等水平,2位中上水平,没有优秀。这说明司机驾驶水平整体偏低,平时的训练力度不够。从每个司机驾驶过程来看,其波动性普遍较大,等级评价为良的2位司机其驾驶波动性也较高,这说明司机的驾驶不稳定,起伏较大。由于人的主观评价波动性更加复杂,因此结论的实际验证是很困难的,但从总体上而言,以上结论得到了司机管理部门人员的认可。针对上述情况给出如下建议:
(1)购买模拟驾驶仿真设备,加强司机技能训练力度。
(2)制定合理的奖惩措施,激励司机提高其驾驶水平。
(3)加强司机的心理疏导,缓解工作压力。
