基于Word2Vec的藏文文本语义预测分析研究
2021-03-29丁海兰
丁海兰
(兰州交通大学 文学与国际汉学院,甘肃 兰州 730070)
0 引言
1 词向量
介于计算机只能识别1和0进行自然语言处理,那么想让计算机处理文本,就必须把文本转化成计算机所能识别的语言,其最直接的方法就是把词转化成词向量.词的向量化是指把词进行数学化表示,主要有one-hot representation、Distributed representation和word2vec模型训练词向量三种表示方式.第一种方式是用一个很长的向量来表示一个词,其分量为1,其余全部为0,1,其缺憾是无法提供语义信息;第二种方式是由Hinton最早提出,他是将词映射到一个低维且稠密的100~200大小的实数向量空间中,这样使得词义越相近的词距离越近;第三种方式是借鉴Bengio提出的NNLM模型(Neural Network Language Model)以及Hinton的Log-Linear模型、Mikolov模型等,都提出了Word2Vec的语言模型,Word2vec可以高速有效地训练词向量[1].
2 Word2Vec工具

2.1 Word2Vec的两种训练模型
词向量其实是将词映射到一个语义空间,得到的向量.Word2Vec则是借用神经网络的方式实现的,考虑文本的上下文关系,Word2Vec有CBOW 和Skip-gram共两种模型,这两种模型在训练的过程中类似.Skip-gram 模型是用一个词语作为输入,来预测它周围的上下文,CBOW模型是拿一个词语的上下文作为输入,来预测这个词语本身.
2.1.1 Skip-gram训练模型
如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做Skip-gram 模型.首先确定窗口大小Window,对每个词生成2*window个训练样本,(i,i-window),(i,i-window+1),…,(i,i+window-1),(i,i+window).紧接着确定batch_size,注意batch_size的大小必须是2*window的整数倍,这确保每个batch包含了一个词汇对应的所有样本.训练算法有两种:层次Softmax和 Negative Sampling[2].最后将神经网络迭代训练一定次数,得到输入层到隐藏层的参数矩阵,矩阵中每一行的转置即是对应词的词向量,具体模型如图1.

图1 Skip-gram模型
2.1.2 CBOW训练模型
CBOW(Bag-of-words model)模型是拿一个词语的上下文作为输入,来预测这个词语本身.首先,确定窗口大小window,对每个词生成2*window个训练样本,(i-window,i),(i-window+1,i),…,(i+window-1,i),(i+window,i).其次,确定batch_size,注意batch_size的大小必须是2*window的整数倍,这能确保每个batch包含了一个词汇对应的所有样本,训练算法有两种:层次Softmax和 Negative Sampling.最后是将神经网络迭代训练一定次数,得到输入层到隐藏层的参数矩阵,矩阵中每一行的转置即是对应词的词向量,具体模型如图2.
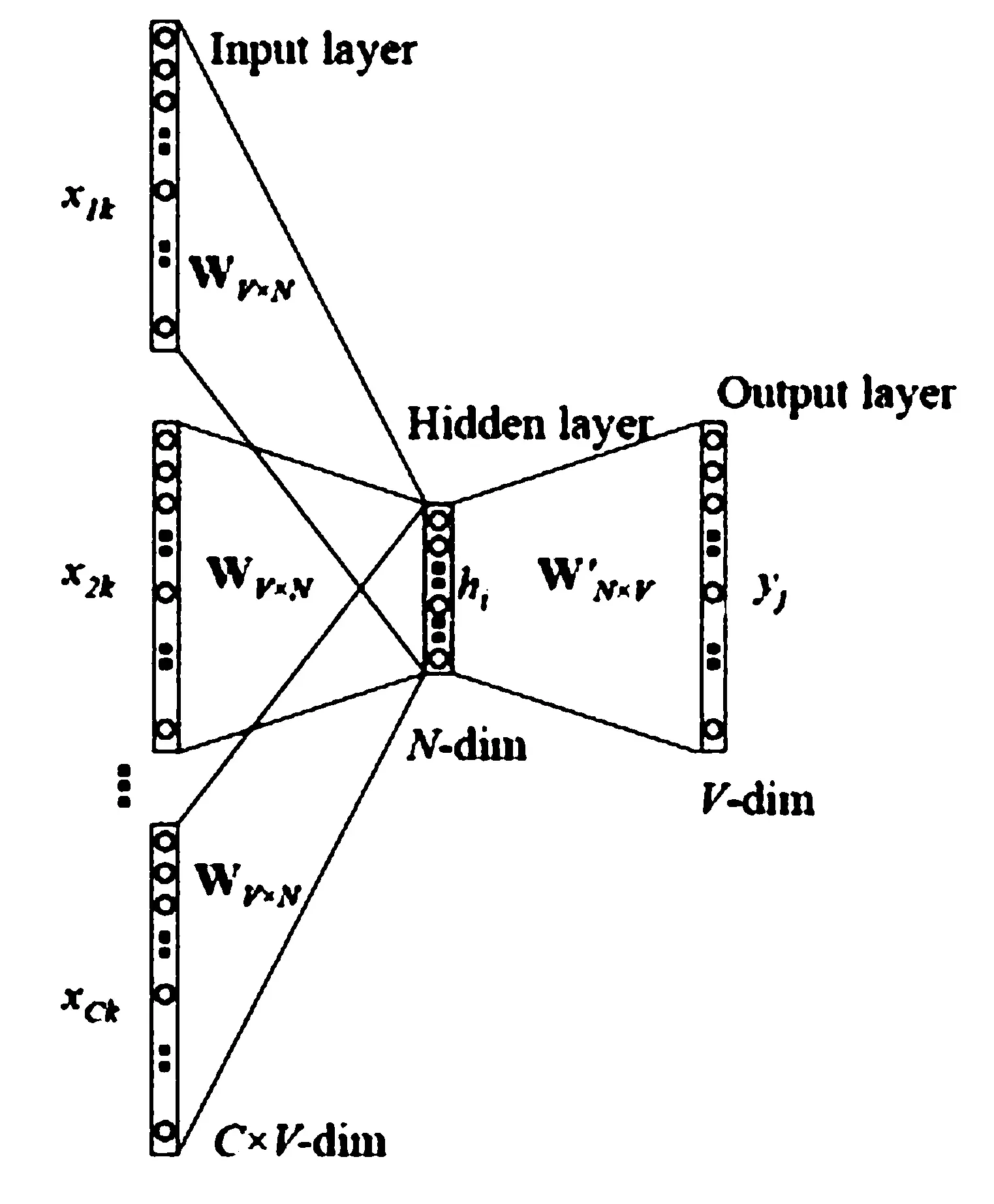
图2 CBOW模型
Word2Vec的Skip-gram和CBOW两种训练模型中,训练的语料较多时建议使用Skip-gram训练模型去训练,而语料相对较少时建议用CBOW训练模型去训练.总体来说,Word2Vec就可以利用训练好的词向量模型,通过输入词转化成词向量再经过模型训练,最后输出按照距离远近的词类,将这些单词变成了近义词集.
3 实验过程及结果分析
3.1 实验步骤
终端搭建好环境变量后在Anaconda3的spyder开发环境中,使用python程序设计语言编写词向量测试代码.调用Gensim工具包中的Word2Vec的CBOW模型算法去训练,训练的词向量大小(size)为50,训练窗口(window)为5,最小词频为5.首先,计算两个词的相似度,再计算一条词的相关词,最后再输出与两个词在语义上距离最接近的词集.使用python程序设计语言编写的词向量测试的核心代码如下:
# genism modules
from genism.models import Word2Vec
from genism.models.word2vec import Text8Corpus
import os.path
import sys
import numpy as np
训练的语料是经过分词核对后,批处理为每行一句,共有33244句,接着去除语料中的所有词性标注并以空格代替词性标注,每句保留藏文句子中的终结符号即单垂符作为句子的单位.最终,得到一篇文本的特征列表.在词袋模型(CBOW)中,文档的特征就是其包含的词(word).具体步骤如图3所示.
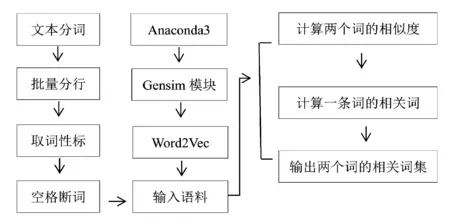
图3 Word2Vec实验步骤

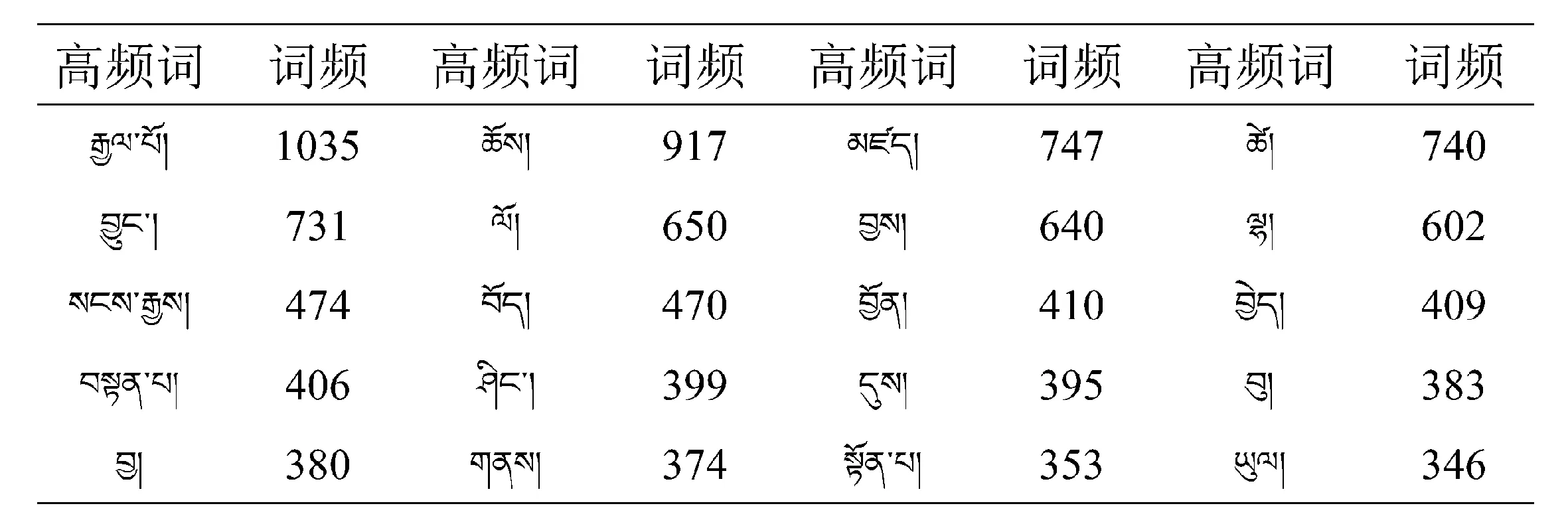
表1 文本《贤者喜宴》高频词汇表
以10组高频词汇作为训练目标输入Word2Vec model进行训练,得出的训练结果见表2~表5.

表2 Word2Vec模型训练两条词的相关词表
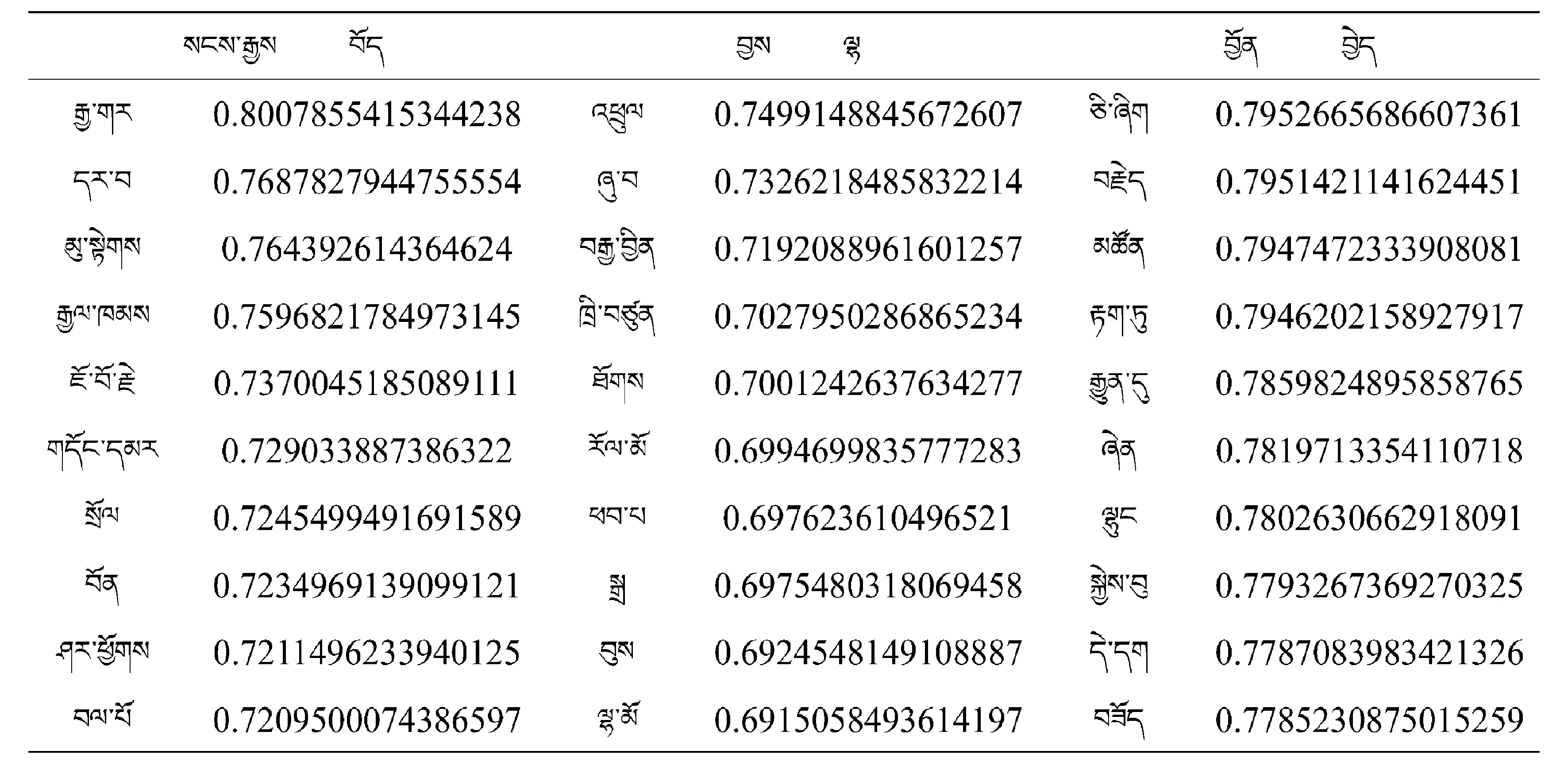
表3 Word2Vec模型训练两条词的相关词表
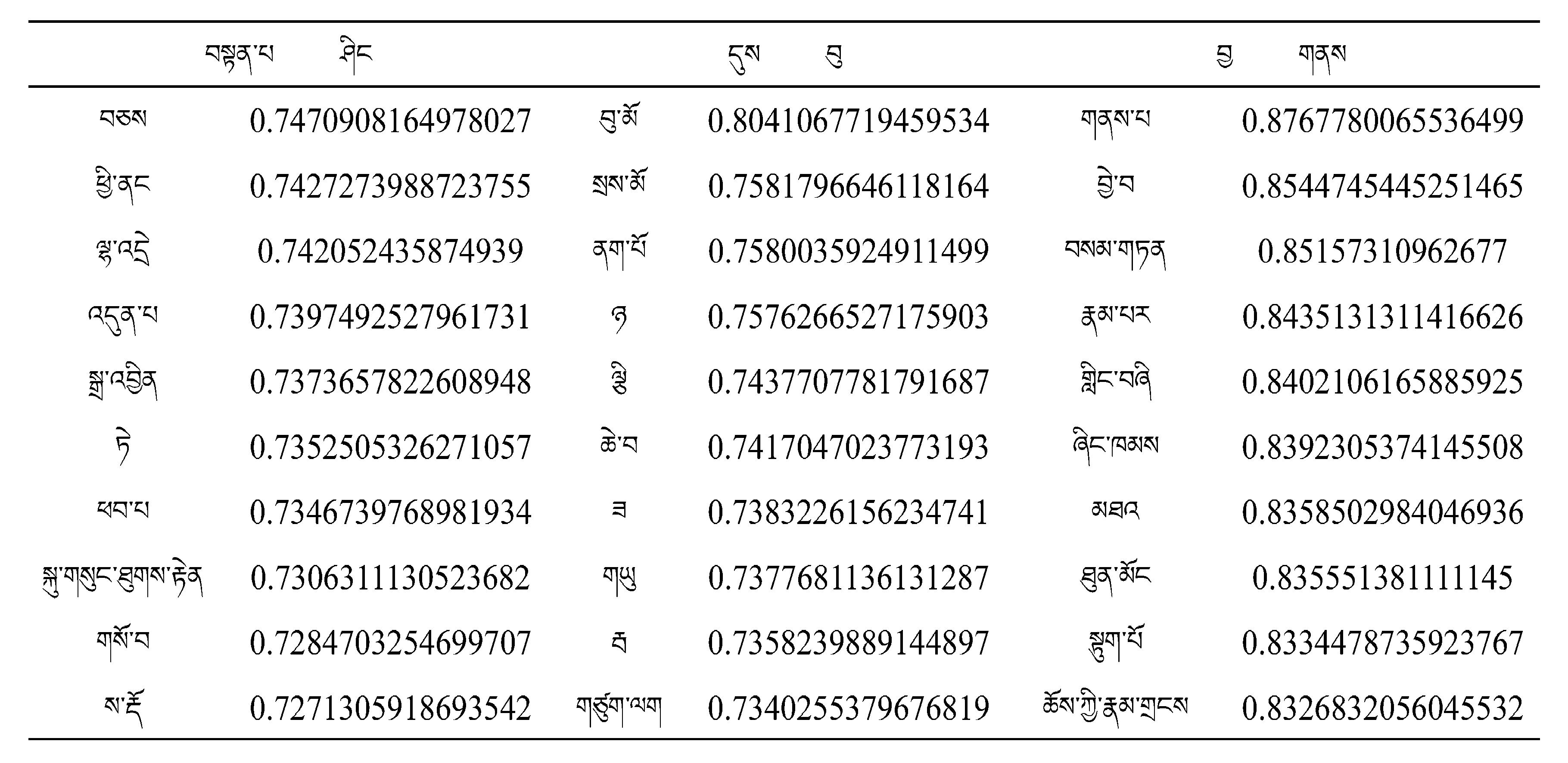
表4 Word2Vec模型训练两条词的相关词表



表5 Word2Vec模型训练两条词的相关词表

4 结束语
本文用GOOGLE下开源的Word2Vec工具把藏文文本作为语料进行输入,将文本中的词利用词汇的上下文信息转变为词向量,通过用Word2Vec中的CBOW模型算法模型训练得到许多语言规律,从而得出词与词之间的距离即相似度.进一步通过高频词汇作为输入,通过训练即可输出与高频词汇距离最近的词汇,以高频词和与其相近的词汇作为重要信息去预测文本的语义.此方法为快速掌握长篇语料中的主旨语义起到了快速且便捷的作用,同时通过训练可以发现许多有趣的语言规律,避免了人工翻译持续时间长和主观判断的问题.但是,在训练中发现许多词汇并未在语境中显现,这给语义预测带来了些许误差.总体来说,基于Word2Vec工具可以有效地预测文本语义.
猜你喜欢
——三份医学英语词表比较分析
