一种增强贝叶斯网络结构学习的自动变量序调整算法
2021-03-25许国强余长州周春蕾
许国强 ,余长州 ,王 林 ,周春蕾 ,高 阳*
(1.江苏方天电力技术有限公司,南京,211102;2.南京大学计算机科学与技术系,南京,210023)
贝叶斯网络(Bayesian network)又称“信念网”(beli ef network),它是定义在一组随机变量X={X1,X2,···,XN} 上的有向无环图(Directed Acyclic Graph,DAG).每一个变量与图中的某一节点相关联,图中节点间的弧表示对应变量之间的依赖关系,每个节点都有一个概率分布θ.因此一个贝叶斯网B由其结构G和参数Θ两部分构成,可记作贝叶斯网结构能够很好地体现变量之间的条件独立性,其假设每个节点所对应的变量与它的非后裔节点所对应的变量独立[1],因此可将联合概率分布定义为:

从数据集学习贝叶斯网络结构是贝叶斯网络研究的重要内容之一.目前贝叶斯网络结构学习方法主要分三类[2]:(1)基于约束的结构学习算法,它使用条件独立性检验的方法去学习数据的依赖结构;(2)基于评分的结构学习算法,它定义一个目标评分函数来衡量结构和数据的拟合程度,学习的目标是使结构的评分最大化;(3)混合结构学习算法综合使用上述两类算法,通过约束方法缩减搜索空间,然后基于评分方法搜索最优结构.Scutari et al[2]的实验研究发现:在小样本上基于约束的结构学习算法比基于评分的结构学习算法更加精确,甚至有时会和混合结构学习算法有同样的准确率;但在基于约束的结构学习算法中,因其需要执行大量的条件独立性检验运算,时间复杂度较高.总体来说混合结构学习算法的准确率和计算效率更高.
目前以MMHC(Max⁃Min Hill⁃Climbing)算法[3]为代表的混合结构学习算法在贝叶斯网络学习任务中取得了较优秀的表现.MMHC算法在约束学习阶段首先获得每个变量的父子节点集,即该节点的邻居集,为后续进行评分算法降低了搜索空间,因此该算法在约束学习阶段获得节点的邻居集的准确性对于整个贝叶斯网络结构学习至关重要.因为在评分阶段,只从变量的邻居集中寻找候选节点,当变量的邻居集没有包含真实结构的节点,该节点将再也不会被考虑.本文的目标是尝试解决“找回丢失的节点”,为此探索了贝叶斯网络结构图与节点影响度之间存在的可能性关系,并提出一种基于约束学习结果快速生成变量序的方法,即将学习到的只考虑邻居集搜索空间的“紧约束”转变为基于变量序的“宽松约束”.本文的主要贡献如下:
(1)探索贝叶斯网络结构与节点影响度之间存在的可能性关系.
(2)提出一种基于节点影响度的变量序调整方法,并通过实验证明将该变量序作为贝叶斯网络结构学习的搜索空间能有效提升贝叶斯网络学习的精度.
1 相关工作
近年来,通过学习贝叶斯网络来探索数据中因果关系的问题得到了广泛的研究[3-13].基于约束的结构学习算法如PC算法[14-15]和TPDA算法[16]等,主要包含两个步骤:一是网络骨架的识别,二是边定向.以典型的PC算法为例.首先,它从完全无向图出发,通过使用条件独立性检验找出在变量集S下独立的变量对()Xi,Xk,并将该变量对之间的边删除,生成贝叶斯网络结构的骨骼.其次,进行边定向,也就是确定V结构.在确定V结构时,对上一步生成的网络框架进行搜索,对于元组()Xi,Xj,Xk,如果出现Xi与Xj有边,Xj与Xk有边,但Xi与Xk无边,且Xj∉S则将无向的Xi-Xj-Xk确定为有向的基于约束的结构学习算法具体实现有多种,对于典型的PC算法,学者们在诸多方面也进行了研究与改进[18],如PC⁃Stable算法通过多核并行化处理的方式极大地提升了算法的执行效率.
基于评分的结构学习算法的主要思想是通过评分函数来衡量所学的网络结构与真实数据的拟合程度.主要任务分两步:一是确定打分函数,二是制定搜索策略.以K2算法为例[19],它是基于CH评分和贪婪搜索的结构学习算法,但出于计算复杂度考虑,K2算法并不是寻找CH评分最高的模型,而是寻找在一定条件下的CH评分最高的模型.网络结构整体得分:
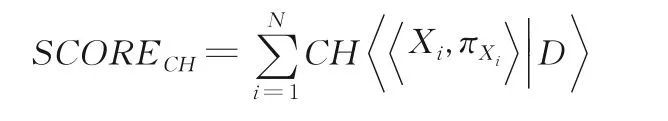
从上式可以看出,网络的整体得分可以看作是每个节点的家族评分之和.为减轻K2算法的计算复杂度,通常给定两个条件,变量排序ρ和一个正整数μ来限制搜索空间.可以认为ρ是最终生成的贝叶斯网络的一种拓扑排序,μ限制任一节点的父节点的最大个数,通常ρ和μ都是根据经验给出.K2算法按顺序逐个考察ρ中的变量Xi,确定Xi的父节点,然后添加相应的边.因为有ρ和μ的限制,其父节点的个数不得超过μ,且只可以在Xi的左边寻找那些能使该节点的家族评分更高的节点作为父节点.
MMHC是典型的混合结构学习算法[3],它综合运用基于约束和基于评分的结构学习算法.首先使用Max⁃Min Parents and Children(MMPC)算法[20]找出节点Xi的可能的全部父或子节点作为候选节点集;然后执行搜索评分算法,进行增边、删边、改边,但在MMHC中搜索空间被限制在仅需要考虑在时,添加边Xj→Xi;最后找到最大评分的贝叶斯网络.因为搜索空间的限制使运算效率得到了极大的提高.
2 autoVOA算法
前文讨论了三种结构学习算法.其中基于评分的结构学习算法需要专家根据先验知识预先对变量进行排序作为评分搜索的约束空间,当变量较多、关系复杂时,这是一个极其耗时又难以给出准确答案的工作.混合结构学习算法因其充分利用基于约束和基于评分的结构学习算法的优点,通过自动寻找节点的邻居集作为评分阶段的搜索约束空间,使其学习的准确率和计算效率均得到大幅提升,可见良好的搜索约束空间对贝叶斯网络结构学习的准确性和运算效率有极其重要的影响.但在MMHC算法中,为了减少假阳性节点的出现,在计算时对全部元素执行了条件独立性检验,检验次数是CPC规模的指数级;同时因约束阶段寻找的是节点的邻居集,这严格地限制了后续评分阶段的搜索空间,极易导致假阴性节点.为了寻找真实贝叶斯网络结构的拓扑排序或者尽可能找到接近真实网络的拓扑排序,将其作为评分阶段的搜索空间,提出自动变量序调整(autoVOA)算法,通过数据分析自动找出一种尽可能接近真实网络结构拓扑的变量排序ρ,并将其作为评分算法的搜索空间.
2.1 算法思想从所有可能的网络结构空间搜索最佳贝叶斯网络结构已被证明是NP⁃Hard问题,所以一般使用启发式搜索算法,通过给定先验知识或者通过依赖分析方法缩减搜索空间,然后采用基于评分搜索的方法进行贝叶斯网络结构学习.
以图1为例,MHC算法在约束学习阶段对于节点2尝试寻找其邻居集.可以看到,节点2的真实邻居集节点为{1,3,4,5},一旦其中的任一邻居节点在该阶段遗漏之后,后续阶段将无法找回,容易导致假阴性节点.对于基于评分的结构学习算法,以K2算法为例,算法需要专家依据先验知识预设变量序,对于贝叶斯网络的结构学习来说,一个较高质量的先验变量序则为真实贝叶斯网络结构的拓扑排序.图1中的变量序可以设置为[3,2,4,5,1,6 ],当K2算法在搜索网络结构时,对于节点5,只会尝试在节点5左边的变量[3,2,4]作为节点5的父节点.但当节点较多且关系复杂时,在众多变量中找到一个质量较高的或完全符合真实贝叶斯网络结构的拓扑的变量序是一个很难的工作.autoVOA算法的提出就是为了解决这一问题.该算法基于数据依赖分析确定的节点影响度去自动找到一个质量相对较高的变量序,当该变量序越接近于真实贝叶斯网络结构的拓扑排序时,越能为贝叶斯网络结构学习算法提供较高质量的搜索空间,进而提升网络结构学习质量.

图1 贝叶斯网络结构图Fig.1 Bayesian network
2.2 算法描述在确定变量序ρ上,分以下几步来考虑:首先,根据独立性检验结果,依据变量Xi邻接点个数由高到低进行排序,得到变量的初步排序ρi;其次,根据独立性检验结果生成的无向图矩阵与最终的贝叶斯网络结构的拓扑排序之间的关系进行观察分析,总结出一个关于从无向图矩阵生成贝叶斯网络结构拓扑排序的算法.
在第一步独立性检验算法中,借鉴一种可度量的贝叶斯网络结构学习方法(BNSvo⁃learning算法)的思想[21].这一算法的优点是并未盲目地进行条件独立性检验,而是根据变量互信息[7,12]利用“偷懒”启发式策略有序进行.它首先初始了两个矩阵mN×N和GN×N,mN×N是变量间的互信息矩阵,该矩阵是动态变化的,m(i,j)=k表示变量Xi与Xk的依赖强度排在第j位.假设按依赖强度升序排列,j=1依赖强度最低,j=N依赖强度最高.GN×N是对称矩阵,它是最终的每个变量的邻居集,G(i,j)=1表示变量Xi与Xj互为邻居.算法根据互信息矩阵mN×N选择依赖程度最弱的变量对Xi与Xm(i,j)进行条件独立性检验,如果Ind(Xi,Xm(i,j)|S)=1,S⊆V{Xi,Xm(i,j)},则 令G(i,m(i,j))=0,同时设置m(i,j)=0.如果mN×N中有m(i,j)=0,在进行条件独立性检验时,在条件集中应排除Xm(i,j),如当检验Xi与Xm(i,j+k)的条件独立性时,应满足S⊆V{Xi,Xm(i,j+k),Xm(i,j)}.

根据GN×N的邻接点的个数,对节点按降序排序得到并输出ρ.
2.3 算法改进为了介绍变量序的调整算法,首先介绍几个符号:
ρ:初始的变量序,也即算法1中的输出.
ρnew:调整后的变量序经过算法调整最终确定的变量序.
本文中节点的影响度指该节点邻居集中节点个数,也就是与该节点未通过条件独立性检验的节点的个数.算法1可以通过GN×N计算每个节点的影响度.节点的依附节点是指该节点的邻居节点,依附节点的个数等于节点的影响度.
图2是一个无向图矩阵的示例,其节点编号从1开始.对于节点1,与其有关的节点为{2,6,7,8,10},也即节点{2,6,7,8,10}依附于节点1,因此其影响度为5;类似地,如节点4,其影响度为4.无向图矩阵也就是算法1中的GN×N.通过对大量的GN×N与最终生成的贝叶斯网络结构进行观察,可以发现以下主要的特点:
(1)影响度较大的节点多数情况下比影响度小的节点所处的层级更高;
(2)影响度大的节点的依附节点,其所处的层级也通常比影响度小的节点的依附节点更高.

图2 无向图矩阵GN×NFig.2 Undirected graph matrix GN×N
基于上述观察总结,提出变量序的调整算法.
从算法1可以得到初始的变量序ρ以及无向图矩阵GN×N.变量序调整算法的主要思想是:
(1)依次遍历ρ,将其插入ρnew.
(2)遍历的当前节点为ρi时,先将ρi插入ρnew;同时找到的ρi依附点,按照其在ρ中的先后次序依次插入ρnew.
(3)根据情况调整插入位置.
以图2的无向图矩阵为例,其初始的变量序ρ应为[1,2,4,5,6,7,8,3,9,10 ],每个节点的影响度分别为(5,5,4,4,4,4,4,2,2,2).首先遍历ρ1,第一个节点为1,把1插入;然后依次遍历{ρ2,ρ10},将其中属于节点ρi的依附点但不在ρnew中的点依次插入ρnew.插入的时候可以向前移动,满足以下几个条件之一则可继续向前移动:
条件1:前一个节点不是待插入节点的依附点,仅当前一个节点的影响度比待插入节点小;
条件2:若前一个节点是待插入节点的依附点,仅当越过该点后,仍能保证待插入点之前的依附点个数大于或等于节点之后的依附点个数则允许越过;
条件3:特殊情况,对于ρ1,要找到其依附点中影响度为1的点放置到ρ1前.

在步骤6中,插入算法在确定插入位置时要满足前面的三个条件,最后输出ρnew.
为进一步说明调整算法的执行步骤,以图2中的GN×N为例.首先根据算法1得到初始变量序ρ=[1,2,4,5,6,7,8,3,9,10 ].根据算法2,先遍历ρ1=1,节点1的依附节点为{2,6,7,8,10} .根据条件3,节点1的五个依附节点中并没有影响度为1的节点,因此可以直接将ρ1=1插入ρnew中,此时ρnew=[ 1 ].向ρnew中依次插入节点1的依附节点,首先需要考虑的就是依附节点2,将依附节点2插入ρnew后ρnew=[1,2 ],依附节点2是否应该向前移动应通过条件2来判断.可以看到,依附节点2的影响度为5,此时在依附节点2之前有一个依附节点1,在依附节点2之后还存在四个依附节点尚未插入,因此不满足条件2,即不能将依附节点2移动到节点1之前.
类似地,依次处理节点1的依附点后得到ρnew=[1,2,6,7,8,10 ].当前并没有全部将ρ中的元素添加到ρnew中,因此进行下一轮处理.遍历ρ2=2,节点2的依附点为{1,5,7,8,9}.此时节点2和节点1已经在ρnew中.对节点5进行处理.节点5的影响度为4,节点10的影响度为2,且节点10不为节点5的依附点,因此根据条件1,可以将节点5移动到节点10之前.再次将节点5与节点8进行比较,最后得到ρnew=[1,2,6,7,5,8,10 ].然后再将节点7插入,而节点7此时已存在,则依次考虑下一个依附点.
经过上述处理,当ρnew长度等于ρ时可以认为算法调整结束.表1是算法主要步骤的执行结果,可以看到,当遍历到ρ3=4,并处理完该节点的依附节点后,算法已满足退出条件.
3 实验与结果
为了验证该算法在贝叶斯网络结构学习上的有效性,从常用的贝叶斯网络知识库中[22]选择六个不同规模网络的数据集进行实验.表2展示了这六组数据集的样本数量、节点数以及弧数信息.
在六个数据集上分别采用三种算法进行实验来进一步证明autoVOA算法在贝叶斯网络结构学习上的有效性.算法一是经典的MMHC贝叶斯网络结构学习算法,算法二是使用MMPC+autoVOA+K2评分函数的算法,算法三是选择基于BNSvo⁃learning算法思想获取初步的变量序ρ+autoVOA+K2评分函数的算法.后两组实验都引入本文提出的autoVOA算法.
实验选用假阴性边即缺边(真实网络结构中存在,但是算法输出中缺少的边)、假阳性边即多边(真实网络结构中不存在,但是算法输出中存在的边)以及方向翻转(真实网络结构与算法输出方向相反的边)三个指标来评价算法的优劣.以算法三的实验结果作为标准,记为1,其他算法的实验结果记为其与算法三实验结果的比值.若算法三的实验结果为0时,则记为0,同时其他算法结果不为0时记为1.

表1 本文算法的主要步骤及结果Table 1 Main steps and results of our algorithm
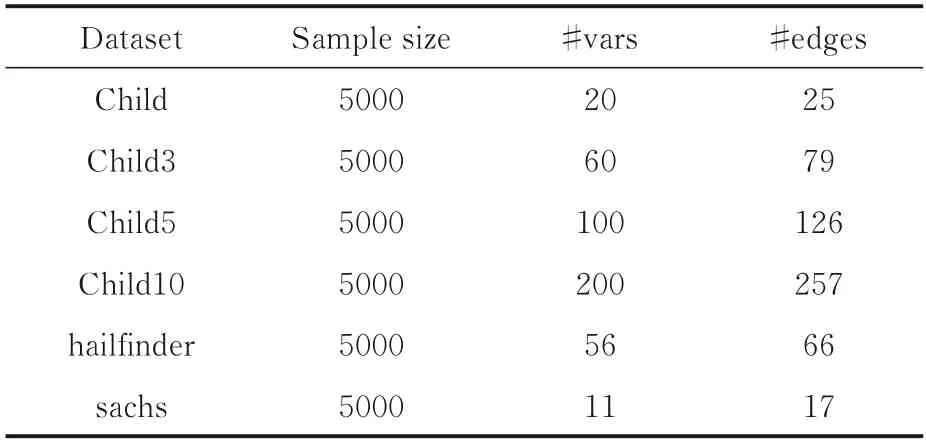
表2 在评估研究中使用的数据集Table 2 Datasets used in the evaluation study
表3展示了三种算法在六个数据集上的实验结果.可以看到,在六组实验数据中,有五组引入autoVOA算法的实验结果优于经典的MMHC算法.其中在数据集Child5上,autoVOA算法和MMHC算法相比,在衡量贝叶斯网络结构学习的准确性的三个指标上都表现出非常明显的优势.
实验结果证明本文提出的基于自动变量序调整算法autoVOA,在提升贝叶斯网络结构的准确率上有很大的帮助.同时也证实,从数据本身去挖掘节点之间的拓扑关系,进而优化搜索空间增强贝叶斯网络结构学习结果有更高的准确性.
4 结论
本文从节点影响度的角度探索贝叶斯网络结构与节点影响度之间的可能性关系,并设计了基于节点影响度的变量序调整算法autoVOA来获取与真实贝叶斯网络结构拓扑排序尽可能相近的变量序,并将该变量序引入贝叶斯网络结构学习中作为网络结构学习的搜索空间.实验证明,au⁃toVOA的引入可以明显提升贝叶斯网络结构学习的准确度.和经典的混合学习算法如MMHC相比,该算法能更好地改善当变量邻居集不精确时带来的对网络结构质量的影响,但在某些数据集上没有呈现更好的结果,这可能是由于在调整变量序的前一步获取的节点影响度的准确度不够.如何从数据中获取更加准确的节点影响度以及进一步挖掘节点的影响度与最终的贝叶斯网络结构之间的关系,需要更深入的研究.
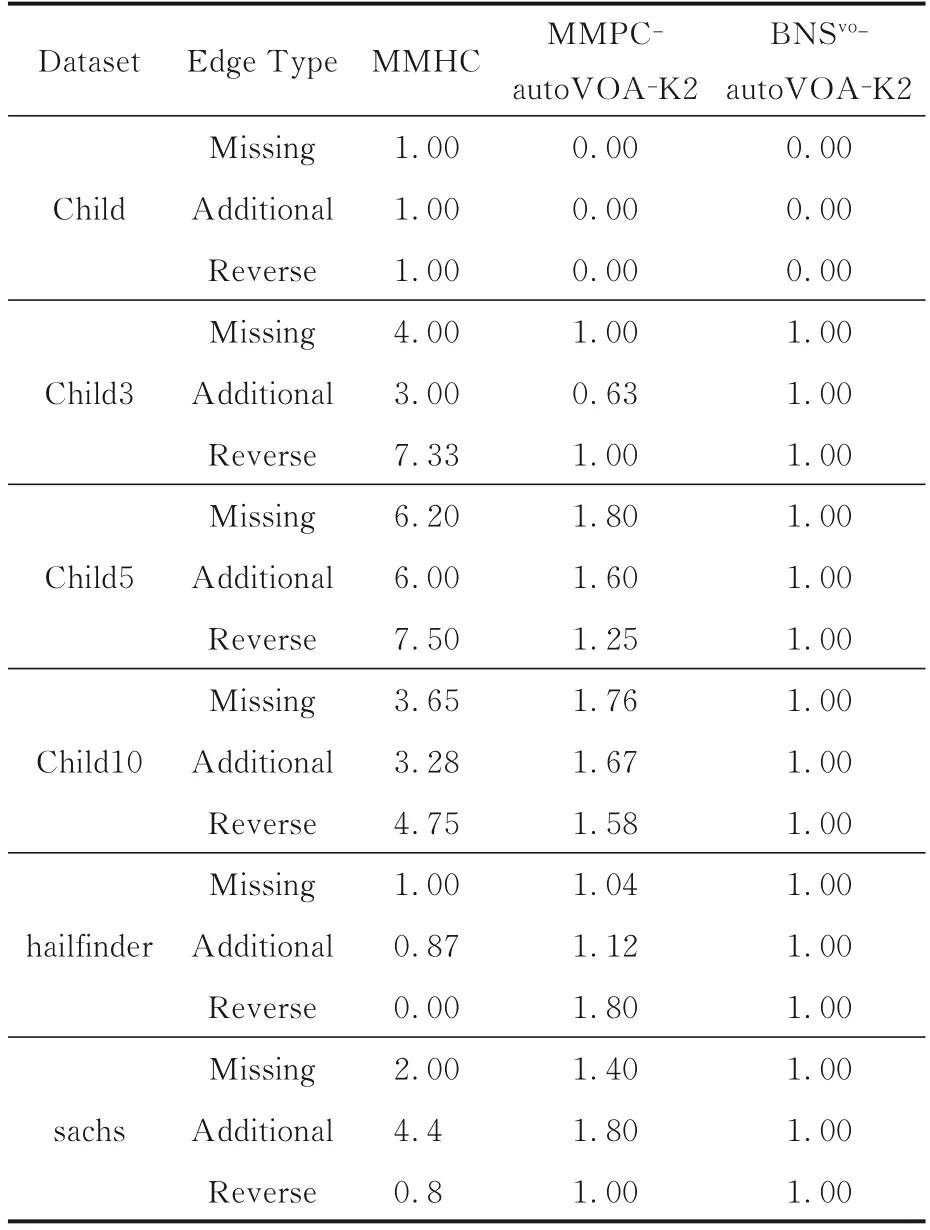
表3 和经典算法的对比实验结果Table 3 Experimental results of our method and other classical algorithms
