基于文本挖掘的客户重复诉求智能分析应用
2021-03-25师娅杰
师娅杰
(广东电网有限责任公司肇庆供电局,广东 肇庆 526060)
0 引言
重复诉求是指客户在某一时段内,对同一事件多次致电,要求处理的诉求。在分析客服工单时发现,部分重复诉求存在“同一事件有不同来电号码、不同客户名称”的情况或者“同一来电号码在某一时段内反映不同事件”的情况。由于第二种情况较为常见,故本文主要针对第二种情况介绍智能分析方法。其中,客户反映问题是否为“不同事件”主要根据业务归口部门来判断,即同一号码在某一时段内多次致电反映同一归口部门的问题,认定为重复诉求[1]。
在客服工单中,同一业务子类可能涉及2-3个归口部门。如故障停电,需要现场调查后才能确定停属于一户还是一带,电压等级属于高压还是低压,归口部门属于营销、生产还是基建。这样的业务子类还有很多,如电网建设、安全隐患、服务态度等,由于归口部门的不确定性,我们定义这些业务子类的归口部门为“模糊边界归口部门”。归口部门的确定对于重复诉求的判定具有重要意义,传统模式下对“模糊边界归口部门”的判断,通常需要人工阅读“来电内容”及“处理意见”等大量长文本,效率低下且准确率无法保证。为确保“模糊边界归口部门”智能分类的准确率,本文使用公司大数据平台的敏捷挖掘工具(SmartMining),构建以数据挖掘和机器学习为主要分析方法的数据科学工作流,对“模糊边界归口部门”设置4次判断,其中首次判断1次,校验判断3次,将该流程定义为三级校验。具体操作如下:使用ansj分词器将长文本拆解成短词汇,再与关键词词库做匹配,若文本包含词库中的关键词,则输出相应的判定结果,并校验上一级结果,若三级校验中各级校验结果相同,则判定结果输出正常,实现“模糊边界归口部门”的智能分类,否则当异常值输出,需人工判断。

?
在三级校验中,首次判断、一级校验属于事件调查前对归口部门的判断,在客服工单下发时进行;二、三级校验属于事件调查后对归口部门的判断,在客服工单归档后进行。工单下发至归档间隔3天左右,判定规则由粗到细,关键词词库也由少变多,若某些关键词同时出现在3次校验的判断中,会导致计算机无法准确识别归类,因此在设置关键词词库时对这类词要谨慎取舍。总的原则是,在同一业务子类的各级校验中设置关键词时,关键词不能重复[2]。
1 数据获取、清洗和预处理
1.1 数据获取
采集营销系统全量客服工单,可通过两种方式获取数据:一是在公司大数据平台通过后台获取,使用标准查询语言SQL语句,对关系型数据库中的表记录进行查询和操纵;二是通过营销系统直接导出数据,再通过“用户输入”导入大数据平台,生成数据源。
1.2 数据清洗和预处理
(1)剔除噪声数据。对客服工单中的全量字段进行功能划分,筛选出有意义的字段,剔除噪声字段。
(2)处理丢失数据。对关键字段“来电号码”中的缺失项进行填充,从“来电内容”的长文本中用公式提取“来电号码”,节约人工补录成本。
(3)数据精简。对于不同的分析目标,仅筛选与目标相关的列字段,避免数据过大、数据不集中导致的分析速度慢[3]。
2 数据分析
在分析阶段,设计三种模型来实现“模糊边界归口部门”的智能分类,并根据不同模型的准确率进行组合优化。
2.1 词频向量模型
(1)构建关键词词库。现实状态下,客户“来电内容”通常由杂乱无章的长文本构成,其中包含诸多噪声词,单纯依靠分词器进行词频统计无法识别关键信息。为提高分词的准确性,首先需要在统计词频的基础上,综合业务经验,人工筛选具有意义的高、低频词汇,剔除无意义的噪声词,形成关键词词库(客户情绪词库、同义词库、电力术语词库),通过关键词词库反向识别和修剪噪声词。其次,应针对不同类型的文本内容,在几十种开源的和商用的分词工具及分词处理方法中选择合适的工具模型。本文依据敏捷挖掘中的分词节点ansj分词器对长文本进行拆解,统计词频[4]。
(2)模型准确率。经验证,在一级校验中使用“词频向量模型”判断归口部门的准确率为68.58%。
2.2 TF-IDF模型
上文中,三级校验模型的准确度较低,经测试,关键词词库的变更对于模型准确性影响最大。人工构建关键词词库较为主观,需要采用更科学的文本分析技术,对词的权重进行分配。本文依据向量空间模型TFIDF进行权重分析。
向量空间模型TF-IDF:评估一个单词或字对于一个文档集或一个语料库中的其中一份文档的重要程度。
定义:Tf-Idf(w)=Tf(w)*log(N/Df(w))。其中,Tf(w)是词w在文档中出现的次数,Df(w)是文档集中包含词w的文档数目,N代表文档的总数。Tf-Idf(w)代表词w对某个文档的相对重要性。如果一个词对于某个文档越重要,那么它就越多地出现在该文档中(Tf(w)值较大),并且越少地出现在其余的文档中(Df(w)值较小)。
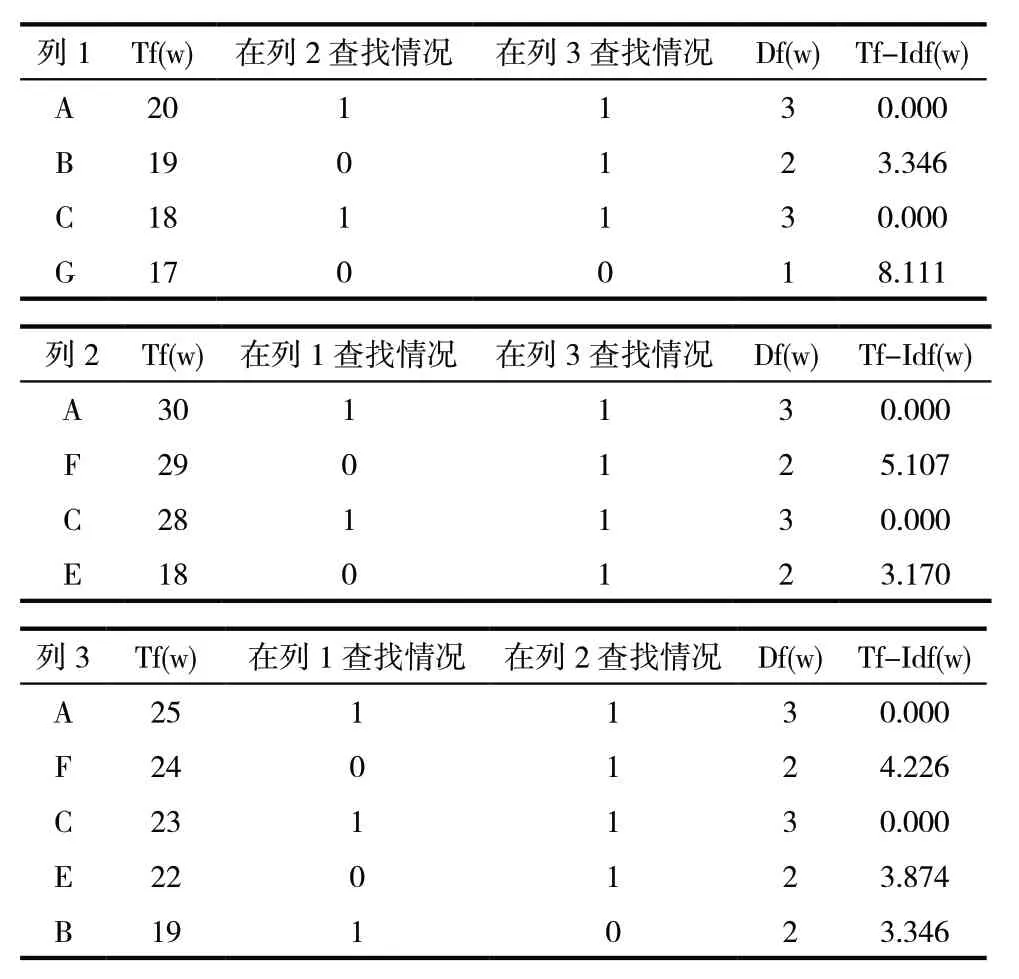
(1)模型理解。设置三个文档,其中:
列1:由字母ABCG构成
列2:由字母ACEF构成
列3:由字母ABCEF构成
Tf(w)是词w在文档中出现的次数,通过分词及词频统计可以实现。
N代表文档的总数,N=3。
Df(w)是文档集中包含词w的文档数目,取值范围为1、2、3。
?
如图,Df(w)=E2=1+C2+D2
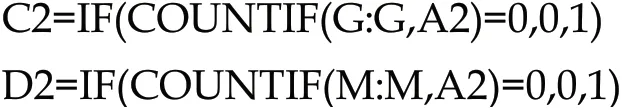
其中,Df(w)=1时,log(N/Df(w))=0.477
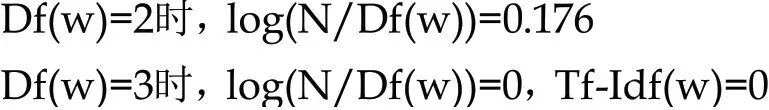
如上图所示,Tf-Idf(w)值成功过滤掉字母AC,字母G最重要,字母BEF的重要性仅由Tf(w)决定。
同理,将归口部门为营销、生产、基建的工单设置为三个文档,可依据TF-IDF重新构建关键词词库。分词汇总后选择词频大于2,即Tf(w)大于2的词汇,将Df(w)=1的词作为关键词词库。
(2) 模型准确率。经验证,在一、二级校验中使用“TF-IDF模型”判断归口部门的准确率分别为75.62%、81.83%。
2.3 机器学习模型
(1)建立训练集与测试集。以80:20的比例,对数据建立训练集和测试集,通过归纳思想推测相关结论。
(2)分类预测算法。
朴素贝叶斯:为名义型字段计算其所有值的记录数,为数值型字段计算高斯分布概率。
随机森林:利用随机的方式将许多决策树组合成一个森林,每个决策树在分类的时候投票决定测试样本的最终类别。随机森林同时训练多个决策树,模型的结果由多个决策树基于投票策略决定[5]。
C4.5:在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性。
(3)模型准确率。经验证,C4.5模型对于测试值和训练值的预测准确度达79.4%、78.6%,预测水平最优。
2.4 模型组合及优化
(1)模型组合。针对一、二、三级校验的数据特点,结合不同模型的准确率,选取最优组合构建三级校验模型。其中,一级校验因文本较短、数据信息不全,采用机器学习C4.5模型;二级校验文本信息量充足,采用TF-IDF模型;三级校验直接使用工单回复内容判断。
(2)模型优化。对异常值进行统一分析,修正关键词词库,提高“模糊边界归口部门”智能分类的准确率。

?
3 总结
重复诉求是生成客户投诉的一个重要原因,人工逐宗进行历史来电的筛选及分析效率低下,导致重复诉求管控难度大,投诉数居高不下。本文通过文本挖掘和机器学习算法确定归口部门,重点解决了长文本分析效率低、机器识别并修剪噪声词困难、模糊边界归口部门判断不精准的问题。通过建立三级校验模型,实现了客户重复诉求智能分析[6]。该应用可以实时查看客户重复诉求的变化趋势,把数据分析交给数据应用后台,对敏感客户及关联事件升级风险提前预警,引起监控人员的重视,将员工的精力投入解决实际问题当中,为基层减负增效。实时、准确的数据应用加快整体应急响应速度,提升客户重复诉求管控工作成效,提高了客户满意度。
