基于垃圾焚烧运行参数的主蒸汽参数预测研究
2021-03-25杨培培骆嘉辉张瑛华刘海威
杨培培,骆嘉辉,姚 心,张瑛华,刘海威
(中国恩菲工程技术有限公司,北京 100038)
0 引言
随着我国经济的高速发展和人民生活水平的显著提高,垃圾的种类和数量激增,垃圾处理越来越受到人们的重视,垃圾焚烧因具有最快速度实现垃圾无害化、减量化、资源化等优点而成为一般城市垃圾的主要处理方式[1]。其中,垃圾焚烧发电厂余热锅炉主蒸汽参数对下游汽轮机的发电效率、焚烧厂的经济效益、运营稳定性和安全性起着至关重要的作用。理论而言,主蒸汽参数越高,则垃圾焚烧发电厂的发电量越多,经济效益也越好。然而随着主蒸汽参数的提高,主要承压受热面的腐蚀问题也越来越严重,极易出现爆管等事故,对企业的财产和人身安全造成不可挽回的损失[2]。因此,合理的主蒸汽参数才能保证生产安全、高效、稳定的运行。
垃圾焚烧炉内的燃烧过程是非常复杂的物理化学过程,是一个强耦合的多输入多输出非线性系统[3]。垃圾焚烧炉运行过程中,影响主蒸汽流量、主蒸汽压力、主蒸汽温度等参数的因素有很多,如推料器速度、干燥段炉排阀门开度、燃烧段炉排阀门开度、燃烬段炉排阀门开度、一次风机频率、一级减温器入口调节阀阀位、二级减温器入口调节阀阀位等,各个变量对目标参数的影响很难通过传统定量关系式表述。
因此,本文基于垃圾焚烧现场运行参数,建立余热锅炉主蒸汽参数的LSTM(Long-Short Term Memory,长短期记忆人工神经网络)神经网络预测模型。通过预测模型对主蒸汽参数进行定量定性的物理分析和描述,了解其机理特性,探索各种扰动对发电效率和运行稳定性的影响,为制定、论证、修改垃圾焚烧运行规程提供理论依据。
1 LSTM 神经网络
LSTM 是一种升级改良后的时间递归神经网络(RNN),引入了内存单元使隐藏层神经元适时地“忘记”历史信息,且用新信息更新内存单元。由于结构设计独特,LSTM 适合于处理和预测时间序列中间隔和延迟较长的问题[4-5]。
LSTM 与RNN 相似,都是具有一种重复神经网络模块的链式形式,区别是重复模块拥有不同的结构,以一种特殊的方式进行交互,如图1 所示。
LSTM 的关键在于细胞的状态,不仅保留了之前的信息,也参与了新状态的计算,通过三个“门”结构实现信息的保护和控制,分别为遗忘门、输入门和输出门。
1.1 遗忘门
遗忘门决定了从细胞状态中丢弃什么信息,该门会读取ht-1和xt,输出一个0 到1 之间的数值给每个在细胞状态中的数字,其中1 表示“完全保留”。0表示“完全舍弃”,计算公式如公式(1)所示。

图1 LSTM 重复模块
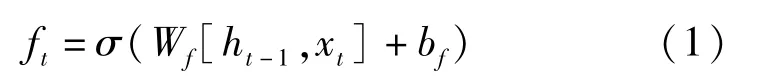
1.2 输入门
输入门决定了允许多少新的信息加入到细胞状态中,实现这个主要包括两个步骤:利用sigmoid 层决定哪些信息需要更新,计算公式如公式(2)所示;使用tanh 层生成一个向量,也就是候选的用来更新的内容Ct,计算公式如公式(3)所示。

1.3 输出门
输出门的作用机制是控制本层的细胞状态。通过Sigmoid 函数作用后得到Ot,计算公式如公式(5)所示。再用tanh 函数对新细胞状态Ct进行激活处理后与Ot相乘,即可得到本层最终的输出结果ht,计算公式如公式(6)所示。
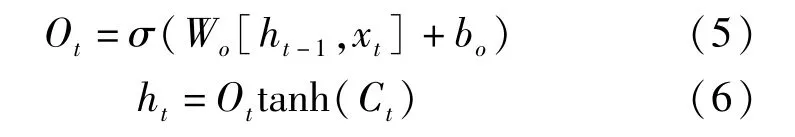
显然,LSTM 的状态是累加得到,避免了RNN倒数相乘的结果,进一步避免梯度消失。
2 神经网络预测模型的训练
2.1 激活函数的选取
选择合适的算法对神经网格的学习和训练非常重要,但每种算法针对特定的问题而提出,没有明确的判断标准来确定每种算法的优劣,因此本文通过试验来确定合适的算法。图2 所示为主蒸汽压力训练样本的损失函数,显然,Adam 算法对应的收敛速率和收敛精度最高。
2.2 隐含层数的选取

图2 训练样本的损失函数
通常认为,增加隐含层数可以降低网络误差,提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向。本章主要对比了包含一个隐含层与两个隐含层时的网络性能(主要以损失函数的变化情况为指标)。由图3 可知训练步数都为20 000 步时,只包含有一个隐含层的神经网络收敛到了更小的损失函数。说明对于主蒸汽压力预测模型来说,两个隐含层使预测结果出现了过拟合的现象,即增加网络复杂性的同时,降低了网络的泛化能力。

图3 隐含层数对损失函数的影响
2.3 隐含层神经元个数的选取
若隐含层节点数太少,网络可能根本不能训练或网络性能很差;若隐含层节点数太多,虽然可使网络的系统误差减小,但一方面使网络训练时间延长,另一方面,训练容易陷入局部极小点而得不到最优点,也是训练时出现“过拟合”的内在原因。因此,合理隐含层节点数应在综合考虑网络结构复杂程度和误差大小的情况下用节点删除法和扩张法确定。
根据神经网络理论知识,隐含层单元数一般与输入层特征数m相匹配,输入层m+1 时,隐含层km+1 个。本模型输入层特征数为21 个,根据该理论,主要选取了包含21 个、42 个以及位于这两个数中间包含31 个节点的三种隐含层结构来配置网络并比较了三种结构之间的网络预测性能(主要以损失函数的变化情况与网络训练耗时为指标),主要指标如表1 所示。综合考虑损失函数和训练耗时的影响,隐含层选用31 个节点。

表1 隐含层节点与损失函数的关系
2.4 模型验证
选择推料器速度、燃烧炉排一次风挡板位置、燃烬炉排一次风挡板位置等21 个值作为输入变量,主蒸汽参数作为输出变量,训练神经网络模型,随机选取80%的样本作为训练样本,剩余20%作为测试样本,如图4~6 所示。显然,主蒸汽温度预测值和实际值吻合的很好,除个别点外,两者的相对偏差在±4%以内;主蒸汽压力预测值和实际值吻合的极好,两者的相对偏差在±1%以内;主蒸汽流量预测值和实际值吻合的极好,两者的相对偏差在±2%以内。因此可以断定该神经网络模型训练良好,具有很强的容错和泛化能力。

图4 主蒸汽温度(℃)的模型计算值与实际值
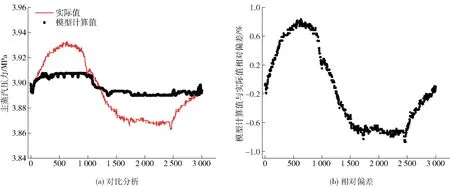
图5 主蒸汽压力(MPa)的模型计算值与实际值
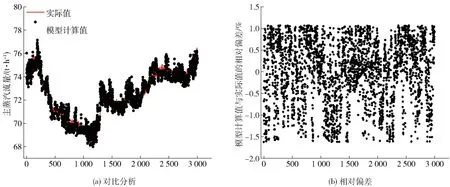
图6 主蒸汽流量(t/h)的模型计算值与实际值
3 主蒸汽参数预测
图7~9 所示为基于上述训练的神经网络模型得到的未来250 s 的主蒸汽温度、主蒸汽压力、主蒸汽流量的预测结果和实际运行值的对比分析。显然,上述模型总体预测效果很好,可以精准预测未来生产工况,为生产决策提供参考依据,提高燃烧物稳定性、安全性和经济效益。

图7 主蒸汽温度未来250 s 的预测结果
4 结论
本文依据现场收集的调控策略,从垃圾焚烧系统的运行数据中选取合适的建模变量,建立多输入多输出的LSTM 神经网络模型,对主蒸汽参数进行建模预测,为现场人员调整控制策略提供指导,保证焚烧炉高效、清洁、稳定的焚烧。主要得到如下结论:

图8 主蒸汽压力未来250 s 的预测结果
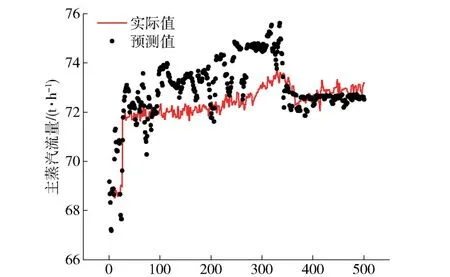
图9 主蒸汽流量未来250 s 的预测结果
(1)通过不断调整、反复优化,最终确定模型包含一层隐含层、优化函数为adam、隐含层神经元个数为31 时模型预测结果最优。通过对比分析主蒸汽温度、主蒸汽压力和主蒸汽流量的模型计算值和实际值发现,模型计算精度高、容错性好,泛化能力强;
(2)基于上述模型对主蒸汽温度、主蒸汽压力、主蒸汽流量等目标变量进行精准预测,用于智能分析和智能决策,预判未来生产工况变化,推荐最佳操作方式,推进生产安全、高效、稳定的运行。
