基于卷积神经网络的交通标志识别方法
2021-03-25申元,赵芸
申 元,赵 芸
(浙江科技学院 信息与电子工程学院,杭州 310023)
近年来,随着人工智能的迅速发展,无人驾驶离人们的生活越来越近。交通标志识别技术在自动驾驶的发展过程中起着关键作用,可以为处在无人驾驶中的车辆提供道路状况的相关信息,同时提醒无人驾驶系统调整驾驶行为,以确保车辆遵守交通规则。为了实现自动驾驶,对交通标志的准确识别极为重要。
上述研究大多数在模型的实时性能上展开研究,得到的模型识别精度不高。针对此问题,本研究提出了一种基于深度相互学习模型(deep mutual learning,DML)[9]的改进的交通标志识别方法,即改进的深度相互学习模型(improved deep mutual learning,IDML)。在IDML中,使用2个ResNet-19网络作为特征提取器进行特征提取,全局平均池化层(global average pooling,GAP)[10]代替全连接层(fully connected layer,FC)作为分类器,以此来减少参数量;模型训练时的损失函数同时使用了交叉熵损失和相对熵损失,并增加超参数α与δ来衡量这两个损失在训练中的权重,相比较于直接使用二者之和,这两个超参数平衡了模型训练中两个损失在总损失中的占比,进而确保最终得到的模型是最好的。此外,还引入不同初始值的批量归一化层(batch normalization)[11]的训练技巧来提高模型的收敛速度。在特征提取阶段,没有使用池化层,而是使用步长为2的卷积进行下采样,避免了池化层带来的分辨率下降的问题。将改进后的IDML在德国交通标志识别数据集上进行验证,结果表明其有效性。
1 数据集和预处理
1.1 数据集
本研究使用德国交通标志识别数据集进行模型训练和性能测试,该数据集图片的存储格式为可携像素图格式(portable pixelmap,PPM),图片的场景包含了汽车在行驶过程中可能遇到的各种情况,图片的尺寸从15×15像素到250×250像素。数据集由43个类别的51 839张图片组成,这些图片被划分为训练集和测试集,其中训练图片39 209张,测试图片12 630张。
1.2 预处理方法介绍
在预处理阶段,主要解决以下两个问题:一是图片格式的转换。相比较于PPM格式,JPG格式占用内存小,又便于查看其内容,因此将PPM格式转化为JPG格式。二是图像的增强。在传入模型之前,为了丰富数据的多样性,将JPG格式的图片再进行一系列的数据增强,以便得到一个更丰富的数据集,增强模型的识别性能[12]。预处理的主要过程如图1所示。

图1 预处理的主要过程Fig.1 Main process of preprocessing
2 试验方法
深度相互学习模型的最大特点如下:在训练时,将预处理后的图片同时输入到多个网络模型进行同时训练(本研究采取同时输入到两个网络模型的方式);在损失函数部分,同时使用交叉熵与相对熵之和来更新网络模型的损失。交叉熵损失用于计算预测类别和标签之间即网络内部的差异,相对熵损失(Kullback-Leibler divergence,KL)用来计算两个网络模型之间的差异。图2为深度相互学习模型的工作流程。由于原模型使用的特征提取网络为参数量较多的ResNet-32,分类器使用了全连接层,在进行了大量的参数计算之后,无法使参数更新的作用最大化,因此本研究对特征提取网络和分类器进行改进。在改进的深度相互学习模型中,对原来的特征提取模块、分类器模块和损失函数部分都做了相应的改进。

图2 深度相互学习模型的工作流程Fig.2 Workflow of DML
2.1 改进后网络的特征提取器
2.1.1 ResNet-19骨干网络
在改进后的网络中使用ResNet-19网络作为特征提取模块,图3为ResNet-19网络的结构。该模块由1个卷积层和9个残差组成,每3个残差构成一个块,第一块由3个1模块的残差块组成,第二块和第三块的第一个残差均为2模块,后两个残差为1模块。其中1模块进行正常的特征提取,表现为不改变特征图尺寸的操作;2模块则使用步长为2的卷积来降低图像分辨率,表现为特征图尺寸减半的操作。每个残差包含3个卷积层和2个批量归一化层,主线上的顺序是卷积层、批量归一化层、卷积层、批量归一化层。残差边上只含有卷积层。

图3 ResNet-19网络的结构Fig.3 Structure of ResNet-19 network
2.1.2 批量归一化
批量归一化一般会在卷积层之后,激活函数之前进行,它可以减小特征图的变化范围,加速网络训练,提高收敛速度。批量归一化的操作步骤一般为:1)将一批数据输入;2)求取这批数据的平均值;3)求取这批数据的方差;4)进行归一化;5)尺度变换。假设归一化结果输出为x,则尺度变化可以记作γx+β,γ和β均为可学习参数,分别初始化为1与0。本研究将所有残差块的最后一个批量归一化层的γ参数在初始化时都设为0,这样设置可以使得所有残差块在训练时都只返回它们的输入,模型训练时模拟了较少的网络层数,在初始阶段更易于训练。
2.2 改进后网络的分类器
图4为全连接与全局平均池化过程的对比。一般而言,卷积神经网络在经过卷积的特征提取之后,会连接图4(a)所示的全连接层进行分类,其作用是将特征图进行拉伸,进而得到单个神经元,之后这些神经元与下一层进行逐个连接。神经元连接会产生大量的参数,同时连接过于紧密在一定程度上会导致过拟合,模型的泛化能力随之降低。使用图4(b)的全局平均池化作为分类器会在一定程度上解决上述问题。全局平均池化的主要思路是视每个特征图为一个整体,对这个特征图进行平均池化,池化的尺寸即为特征图的尺寸。全局平均池化将每个特征图上所有像素值的均值作为输出结果,它是一个将特征图融合为特征点的过程。使用特征图融合为特征点过程代替了特征图拉伸过程,可以避免中间参数的计算与更新,同时也避免了特征图拉伸带来的大量特征的冗余,减少了过拟合,提高了模型的泛化能力。最终,全局平均池化输出的结果输入到softmax层中得到类别概率。

图4 全连接与全局平均池化过程对比Fig.4 Process comparison of FC and GAP
上文定性地描述了全局平均池化相较于全连接层的优势,下面将定量阐述全局平均池化的作用。在分类器模块中,假设模型要预测出n个类别,特征提取网络最后一层输出的特征图尺寸为o×m×m,在全连接层中,将特征图进行拉伸,可以得到o×m×m个神经元,假设只连接一个全连接层,接下来是连接n个神经元进行分类,这样就会产生o×m×m×n个参数。如果用m×m的卷积核进行全局平均池化,最终得到n×1×1,即n个神经元,该操作将不产生任何参数。
总之,相比较于全局平均池化层,使用全连接层不仅参数量过大,而且容易过拟合。因此全局平均池化的使用,减少了参数量,可以节省模型参数的存储空间,同时可以作为正则,防止过拟合。此外,它还加强了特征图和类别之间的关联性,使分类性能得到提升。
2.3 改进后网络的超参数设置
本研究以深度相互学习网络中使用的两个相同的网络θ1与θ2为基础。网络模型的损失函数由两部分组成,一部分是网络模型预测的输出和标签之间的交叉熵损失LC1,另一部分损失是为了测量两个预测网络预测结果的匹配度引入的KL散度DKL(p2|p1),它是θ1与θ2两个网络之间的KL散度。LC1计算公式如下:
(1)
式(1)中:M为类别,N为样本数,I(yi,m)(yi∈{1,2,…,M})为判断标签值和预测值是否相同的函数,

(2)
(3)
改进方法使用的损失函数是将两个超参数α和δ分别添加在这两部分损失前。模型训练时这两个参数也被训练,以此来获得最佳的分类性能,总损失:
Lθ1=αLC1+δDKL(p2|p1)。
(4)
式(4)中:α+δ=1。将这个总损失作为目标函数,对其求最小值来更新模型。另一个网络模型的损失同理可得。值得注意的是DKL(p1|p2)和DKL(p2|p1)是不同的,它们分别代表自身与另一个网络模型间的差异。
3 结果与分析
本研究使用设备的处理单元为G7 7790,处理器为Intel(R)CoreTM i7-9750H,CPU主频率为2.6 GHz,内存为16 GB,显卡为NVIDIA GeForce RTX 2070,显存为8 GB。操作系统为Microsoft Windows10,编译器为pycharm 2019.3.2,相关库有python 3.6.10、pytorch 1.2.0、torchvision 0.4.0,同时在数据集进行格式转化时用到了Pillow7.0.0。
3.1 数据预处理结果
按照1.2节的方法对一张示例图像进行预处理,图5是数据增强的示例,以数据集中一张图片转换为JPG后的处理流程为例,详细展示了预处理阶段图片的转换、重置、垂直翻转、旋转过程。其中,为了适应模型的输入,将原始JPG图片的尺寸重置为32×32像素,然后按照0.5的概率进行垂直翻转或旋转,旋转角度在-10°~10°之间。处理完的图片就可以传入模型进行训练。

图5 数据增强示例Fig.5 Examples of data augmentation
3.2 细节设置
训练时,网络模型的优化配置如下:优化器算法使用牛顿动量法,动量设置为0.9;批大小为512,即网络模型每次读取512张图片;迭代次数为200,即每张图片共输入模型200次。此外,本研究使用动态的学习率进行训练,初始值设置为0.1,每迭代50次,学习率减少为原来的1/10。改进后特征提取网络的细节设置见表1。

表1 改进后特征提取网络的细节设置Table 1 Detail setting of improved feature extraction network
3.3 消融试验
表2是各方法的精度与相比于原模型的参数节约量。下面对表2中的内容展开详细介绍:首先,原模型中使用的ResNet-32网络特征提取器与改进后模型使用的ResNet-19网络特征提取器的区别在于,前者在每个块中使用5个残差,而后者只使用3个残差,去掉了后两个残差,因此每个块后由这两个残差带来的参数就可以被去掉;通过在原模型上使用德国交通标志测试集进行测试,可以得到96.73%的识别精度,融入改进后的特征提取器后损失了0.05%的识别精度,但节约了大量的参数,权衡利弊,我们的改进整体上不影响模型的性能。接着在原模型中加入改进后的分类器——全局平均池化层,从表1可以看出第三块的输出为8×8×43,因此使用8×8的卷积核进行全局平均池化,进一步将特征提取器得到的8×8×43特征图融合为1×1×43的特征点;改进后分类器的使用,可以舍去由全连接层带来的巨大参数量,通过在原模型上使用德国交通标志测试集进行测试,得到的识别精度为98.88%,提高了2.15%。最后加入批量归一化策略,模型的精度提升了0.02%,达到了98.90%的识别精度,是本试验获得的最佳结果。

表2 各方法的精度与相比于原模型的参数节约量
3.4 超参数试验
在这一阶段,将对两个超参数α和δ的值进行研究。按照α和δ之和为1的原则,进行了以下试验,α∈{0.25,0.5,0.75},对应的δ∈{0.75,0.5,0.25}。总之,我们赋予所使用的两个损失函数不同的权重,测试损失函数的不同占比在模型训练中的作用。图6为α和δ在分别取不同值时,模型的训练损失和训练精度曲线,其中图6(a)为训练损失,图6(b)为训练精度。由图6可以看出,虽然三个不同α和δ取值的模型都可以达到收敛效果,但是α和δ取值分别为0.75和0.25时,模型最先收敛至最佳;在取值分别为0.5时,模型不稳定;α和δ分别取值为0.25和0.75时,模型收敛较慢。由此可得,当两个超参数α和δ的值分别为0.75和0.25,即交叉熵损失在总损失中占比为0.75,相对熵损失占比为0.25时,所得到的模型性能最好。
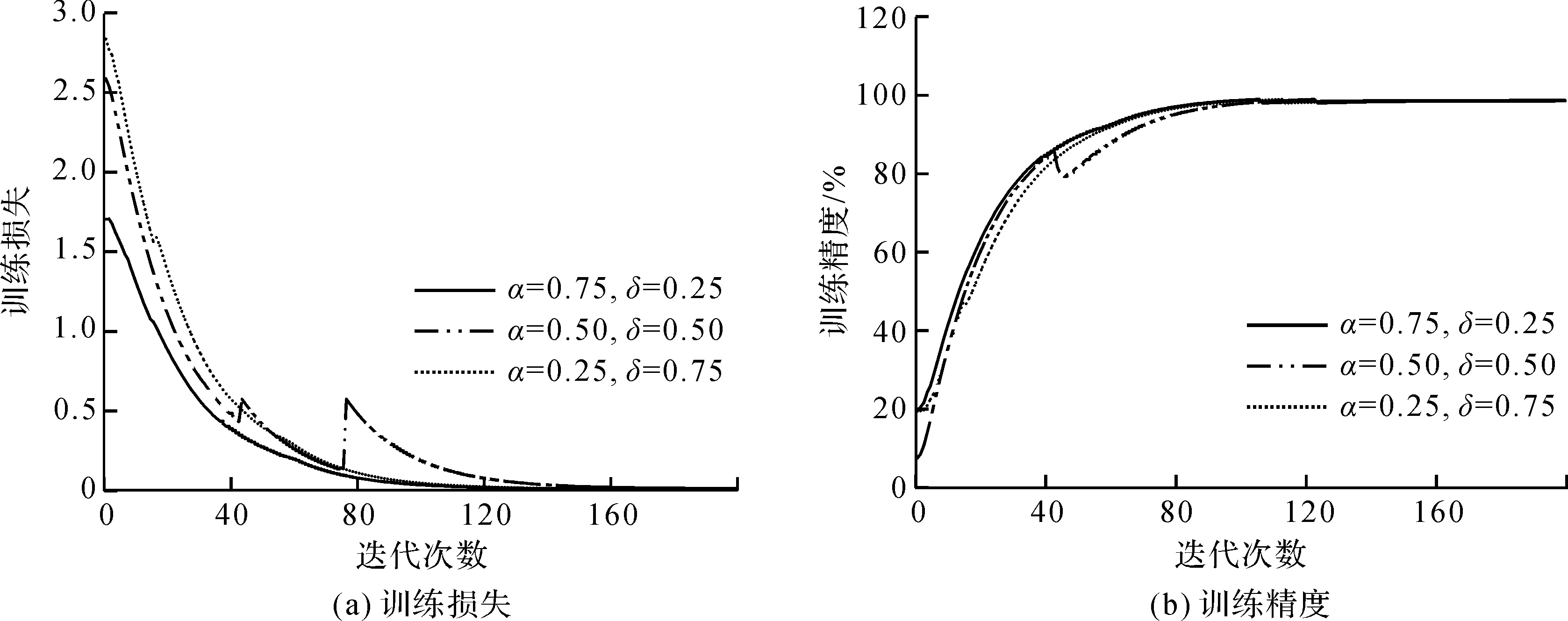
图6 训练损失和训练精度曲线Fig.6 Training loss and training accuracy curves
3.5 不同方法下的识别精度对比
经试验可得,当两个超参数α和δ的值分别为0.75和0.25,即交叉熵损失在总损失中占比0.75,相对熵损失占比0.25时,在德国交通标志数据集测试集上可以取得模型的最高识别精度为98.90%。同时,为了验证此方法的可靠性,在该测试集使用当前优秀的交通标志模型进行比较。不同模型的精度对比见表3,从比较结果可以看出:Arcos-Garcia等[13]使用的方法比我们提出的方法精度低0.16%,Zhou等[14]使用的方法比我们提出的方法精度低0.03%,Aghdam等[5]使用的方法比我们提出的方法精度低0.7%,Meng等[15]使用的方法比我们提出的方法精度低0.2%。我们提出的方法准确性最多提高了0.7%。对比结果表明我们提出的方法在精度方面有优势。

表3 不同模型的识别精度对比
在测试集的12 630张图片中随机读取15张,将得到的预测结果和原标签信息进行可视化,图7即为可视化结果。图片上显示的两个数字分别代表预测类别和图片实际所属的类别。绿色数字表示预测与标签匹配,即预测正确的情况;红色则相反。从图7中可以看出,15张图中有一张预测错误,该图片中所属类别为23,模型将其预测为20。如果用人眼去识别它,由于光线过暗,也无法确定这张图片的具体类别。其他的图片不论是在清晰度不高还是强光下,网络模型均有较好的识别效果。

图7 可视化结果Fig.7 Visualization results
4 结 语
针对当前交通标志识别精度低的问题,笔者提出了一种改进深度相互学习模型的交通标志识别方法。在改进后的网络中,使用ResNet-19网络作为特征提取器进行特征提取,全局平均池化层作为分类器,以此来减少参数量;损失函数同时使用了交叉熵损失和相对熵损失,并增加超参数α与δ来衡量这两个损失在训练中的权重;引入了不同初始值的批量归一化层的训练技巧,以此来提高模型的收敛速度。另外,特征提取过程中没有池化层,而是使用步长为2的卷积进行下采样,从而大幅减少了图像分辨率的损失。正是图片在特征提取过程中保留了尽可能多的特征信息,才确保了模型的分类准确性。尽管本模型取得了不错的识别效果,但研究过程中也遇到了一些问题,从识别错误的那些图片来看,多数还是光线较暗导致的,后期的研究会结合一些可以调亮光线的机器学习方法进行研究。除此之外,更轻量化的网络也可能成为下阶段的研究目标。
