无人机与深度学习在建筑物实时检测中的应用
2021-03-25张阳阳孙晨帆
张阳阳,詹 炜,孙晨帆
(长江大学计算机科学学院,湖北荆州 434023)
0 引言
本文基于深度学习方法,通过无人机采集城市建筑图像,经过筛选和标注构造数据集,在tensorflow 深度框架下构建神经网络对建筑图像数据集进行训练,得到高鲁棒性的检测模型,从而实现对目标建筑物的实时检测。
在深度学习技术出现以前,传统的建筑监测方法主要是利用遥感影像数据检测[1],由人工对遥感影像[2]进行解释。对违建问题由群众监督举报,再由主管执法部门到现场确认,其缺点显而易见:①取证难;②成本高,巡查速度慢、效率低;③发现、过程处理及事后监管难,易反复。识别违章建筑的关键是检测建筑物的变化情况。早期建筑物变化检测大都通过人工解释,效率较低且存在建筑物遗漏问题。
20 世纪90 年代以来,学者通过遥感影像数据检测城市建筑物变化。通过分析在相同地区不同时间段所获取的遥感图像中光谱的变化情况,比较不同时间段图像的差异从而检测发生变化的地物并区分变化类别[3]。该方法实现路线是:首先计算同区不同时段两期影像的变化矢量,然后利用直方图阈值、贝叶斯最小错误率、经验公式、人工判别等阈值法设置变化量阈值,将遥感影像分为变化区域和未变化区域两部分,最后通过分析变化区域内像素的变化方向对变化类别进行区分。基于遥感影像的城市建筑物变化检测方法缺点是:①该方法是一种对比方法,需要规划部门提供原始的建筑物规划数据用于对比,规划数据难以获得;②遥感影像成本高,分辨率低;③对比算法的很多参数和阈值需要人工定义,影像检测效果较差。
近年无人机航测航拍科技、深度学习和计算机视觉技术的蓬勃发展,为建筑的快速准确识别提供了新的检测和监控技术手段[4],提高了城市建筑的识别效率[5],降低了管理成本,提升了城市建筑管理水平,为构建智慧城市提供了理论和技术支持。
本文针对传统的城市建筑物检测方法缺陷,创新性提出城市管理中应用无人机视觉数据深度学习识别技术的新方法,利用最前沿的深度学习算法[6]实时分析无人机拍摄的视频流,自动识别目标区域各种建筑物或城市中的特定目标,为城市管理提供一种全新的技术手段[7]。该方法实施步骤如下:①编程操控无人机飞控平台API 接口,设定飞行区域及参数,根据设定的参数引导无人机至目标区域内采集训练所需要图像数据,筛选有用的图像数据建立深度神经网络训练所需的数据集;②设计合适的网络结构,通过第①步制作的“城市管理平台”数据集训练深度神经网络;③深度学习算法训练的检测器自动识别目标区域内的建筑物并标记,为后续城市管理提供决策支持,提高城管执法精准性和效率。
1 相关工作
目前,计算机视觉已广泛覆盖工业、医疗、军事、农业、商业等领域,与人们的社会活动紧密相连。作为基础的技术支持,深度学习和计算机视觉与人工智能的发展紧密相关。
深度学习和计算机视觉技术是人工智能技术的重要分支。计算机视觉用计算机模拟人视觉神经处理图像,通过计算机设备实现人的视觉功能,从而认识、分析外界环境。简而言之,物体识别、物体定位以及对于物体运动状态进行判断是深度视觉系统主要解决的3 个问题。计算机视觉作为计算机的眼睛,是机器认识外部环境、分析外部环境的一种方式。而认识、分析外部环境是实现人工智能不可或缺的重要部分。看见是第一步,只有看见才能进一步去分析然后做出判断,进而代替人类完成各种任务。它与语音识别一起构成人工智能的感知智能,赋予机器探测外部世界的能力,进而做出判断,采取行动,让更复杂层面的智慧决策、自主行动成为可能。
深度学习视觉算法在检测精度方面可以做到传统视觉识别方法无法企及的高度。不同于传统的机器学习,深度学习网络包含了更多的隐层结构,通过多层隐层网络的复杂连接,不断加深网络层数,可更加深入地挖掘训练数据之间的内在联系,实现复杂函数的近似逼近,通过建立鲁棒性更高的模型对非标签数据进行预测。深度网络往往拥有比浅层网络更好的拟合能力,其原因在于每个隐层都对上一层输出进行了非线性变换,多次非线性变换使模型找到一个合适的表达。深度学习通过多种基础的函数组成更加复杂的函数关系,以表达较为复杂的问题。
深度学习的出现大大提高了视觉识别准确率。计算机视觉[8]技术发展大致经历两个阶段:①人们通过经验归纳提取,进而设定机器识别物体的逻辑,通过人为设计合适的特征识别算法让机器识别物品。由于认识物体的逻辑是人为设定的,不能穷举各种复杂的情境,因而鲁棒性较差,识别准确率较低;②深度学习的出现让识别逻辑由人为设定变为反馈式自学习状态,数据量的爆发式增长和计算机算力的大幅提升驱动了物体识别率提升。目前深度学习持续突破性发展,尤其在计算机视觉领域有重大突破。
得益于深度学习算法模型、数据量增加以及CPU、GPU等计算硬件支撑[9],计算机视觉技术得以更加高效地实现,并最终集成于多类产品和应用场景之中(如机器人、无人驾驶等)。当下,结合人工智能的深度学习技术,无人机越来越广泛地应用于农业、商业、军事、工业等行业[10],人们将其统称为专业应用级无人机[11],该类无人机已经被应用在一些行业,如对城市建筑进行合理监控。该方法首先通过无人机获取建筑图像并进行数据处理,然后设计深度学习算法及网络模型,最后运用建筑图像的检测模型对需要检测的建筑物体进行识别和分类。这项技术可应用于高层建筑的违建检测[12]、建筑的破损程度检测、高层建筑火灾检测等众多领域。这项技术的研究重点是对建筑进行快速有效识别,其难点在于:一是动态视频识别过程中对光线变化、遮挡等干扰难度更大,这对机器实现图像识别、滤除干扰提出了很高要求;二是动态视频识别对机器识别速度要求较高。一些公司通过智能前端化方式来提升分析速度,即在智能前端摄像头搭载强并行计算能力处理器,以提供更实时、更高效、不依赖无线网络传输的智能服务。
深度学习具有较强的泛化能力和迁移能力[13],通过迁移学习保留其他数据集的有效特征,并对原始数据集采用翻转、旋转、缩放、随机拼接等数据增强操作扩展数据集的丰富性,同时强化对建筑物特征的学习能力,提高神经网络模型的鲁棒性,从而使其有效克服光线的明暗变化、建筑物之间的遮挡等场景变化的差异所带来的影响;数据集中无人机拍摄的高分辨率图像样本输入神经网络之前,先将像素缩小为224*224 大小,这一操作虽然损失了原始图片中的部分特征,但大大减少了神经网络的计算量。为了保证建筑物的检测精度,在设计神经网络结构时采用5 层卷积层的设计方式,有效提高了模型的检测速度。
2 方法实现
2.1 实现框架
本文采用最前沿的人工智能及深度学习技术[14]建立模型。深度学习(Deep Learning)能够自主地从训练数据集上学习已有数据集的有用特征(Feature),特别是在一些不知道如何设计特征的场合,如建筑物特征等。深度学习本质上是通过构建具有多隐层的神经网络模型,对海量训练数据自主学习并从数据中提取出能够描述被检对象的主要特征,从而大幅增加模型的识别准确率。和传统的机器学习相比,深度学习网络模型最大的特点是多层网络结构。
本文提出一种无人机视觉数据深度学习识别技术模型,模型实现框架如图1 所示。
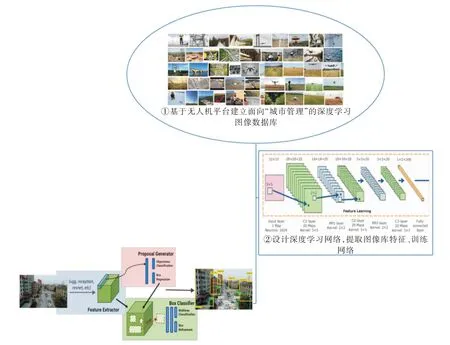
Fig.1 Implementation framework图1 实现框架
2.2 实现方案
基于上述框架实现步骤如图2 所示。
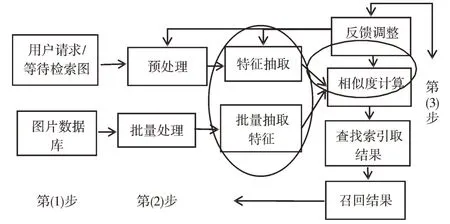
Fig.2 Implementation route图2 实现路线
(1)基于无人机平台建立训练图像数据集。对飞控平台API 编程,设定目标飞行区域和参数;无人机图像采集;按照统一格式提取每张图像的关键信息并打标签;按照规则建立图像训练及测试数据集以备用。
(2)训练深度学习网络。采用现有深度学习算法框架Tensorflow[15]设计深度学习网络;将第(1)步建立的图像数据集输入到深度学习算法的训练模块中,进行大量有效的算法训练。
(3)无人机采集待分析区域里的图像数据。基于第(1)步的数据集和第(2)步的深度训练网络,自动检测并识别目标区域中建筑物的变化情况并做标记,供管理部门参考。
2.2.1 建立城市建筑图像数据集
(1)无人机飞行区域及参数API 编程。为避免无人机无规则“乱飞”(采集的图像数据无效),采用大疆飞控平台,调用大疆官方提供的飞控API 参数,通过程序设计设定飞行参数,划定无人机飞行区域,设定高度、飞行速度、相机云台倾斜角度、相机拍照频率等关键数据采集,让无人机按照既定参数飞行,采集有效图像数据。
(2)如图3 所示,按照树结构建立可扩充的图像数据集作为算法的训练数据集。树根分为违章建筑和占道经营两个一级分支:①违章建筑分支下根据建筑物高度分为20m 以下、50m 以下和100m 以下3 个二级分支;②占道经营分支下建立一个二级分支;③每个二级分支下存储500~1 000 张相关航拍图像;④为保证算法的训练效果,每张存入数据集的图像都经过人工筛选和打标签,否则不能入库;⑤该数据集的各级分支都是可扩充的,方便项目延伸到其他应用。
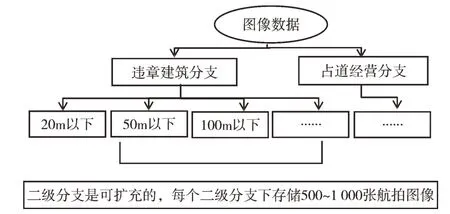
Fig.3 Branch structure of urban management image dataset图3 城市管理图像数据集分支结构
(3)标记数据集。用程序或人工为图像集打标签,为网络训练做数据准备,如图4 所示。

Fig.4 Annotation process of deep learning city management image dataset图4 深度学习“城市管理”图像数据集标注流程
2.2.2 深度学习网络
采用卷积神经网络(Convolutional Neural Nets,CNNs/ConvNets)进行数据集网络训练,提取图像特征,其数据集网络训练过程如图5 所示。

Fig.5 Network training process图5 网络训练过程
深度学习网络结构按不同的方向分为以下几类:①典型生成型深度结构,其主要代表有深度置信网络[16](DBN)。DBN 通过一系列限制型玻尔兹曼机组成,用来处理深度多层神经网络架构在进行特征学习过程中产生的标签数据需求量大、模型收敛速度较慢以及陷入局部极值等问题。DBN 可以同时对先验概率和后验概率进行估计,因为其网络是对训练数据以及标签进行联合学习得到的概率;②区分型模型。典型代表是CNNs,其结构不同于DBN,CNNs 只能对后验概率进行估计,所以CNNs 多用来解决神经网络的目标识别和分类问题;③混合型结构。当生成型深度结构用于分类模型问题时,网络后期利用分区结构进行参数优化,所以称作混合型结构。
通过上述分析可知,在图像识别和目标检测领域中卷积神经网络(CNN)是最适合于深度学习的神经网络结构,CNN 卷积神经网络比普通神经网络增加了隐藏层,其间包含了多个卷积层和下采样层的组合。首先,卷积层能够通过卷积核较好地提取输入图片的局部特征,卷积层具有进行权值共享的特性,能大大减少神经网络在训练过程中所需参数计算的数量;其次,下采样层可以忽略目标的倾斜。旋转之类的相对位置变化在不改变特征图大小的同时还可进一步减少特征图的分辨率,帮助神经网络提取高层次的语义特征,提升检测精度,避免过闭合情况发生。该卷积神经网络主要层次结构如图6 所示。

Fig.6 A typical convolution neural network structure图6 典型的卷积神经网络结构
在深度学习网络中,通过大小不同的卷积核对上一层特征图依次进行卷积操作可提取不同的目标局部特征,同时这些不同的局部特征图共同作为神经网络下一层采样输入数据。卷积l中第j个神经元公式如下:

其中,k表示卷积核,M表示输入层的感受野,b为偏置,f(·)表示卷积网络的激活参数。一个卷积层设计由多个特征图构成,且各个特征之间权值共享,这样可以显著降低网络中自由参数的数量。
下采样层(又称池化层)一般设计在卷积层的后面,可以采取最大池化和平均池化等算法将多个像素值压缩成一个,其功能是提取特征以减少数据规模,降低网络分辨率,从而实现畸变、位移稳健性,避免网络过拟合发生。下采样计算公式如下:

其中,pooling(·)代表池化函数,β代表权重系数。
卷积神经网络训练过程由前向传播和反向传播两个阶段组成。在前向传播阶段,信息从输入层开始向前逐层传播,经过多个卷积、池化、连接操作和全连接层直至网络最后的输出层,前向传播过程中网络通过下式计算:

其中,yi表示卷积网络第i层的输出,fi(·)表示卷积网络第i层激活函数,wi为第i层卷积核的权值向量。
反向传播过程中,计算实际输出(预测值)与标签信息(真实值)之间的差值,然后按照极小化误差策略设计模型的误差函数,反向传播调整网络各层参数的权值,采用随机梯度下降法[17]等优化函数进行参数调整。
采用卷积神经网络结构设计的深度学习神经网络模型具有权值共享[18]、模型复杂度低和权值参数少的优点。相较于传统图像识别算法[19],该模型能够避免复杂的人工手动特征提取以及数据重建过程,可通过深度神经网络的正向和反向传播过程自动学习特征[20],在数据集规模较大的目标检测及识别项目中具有显著优势。
2.2.3 城市建筑图像数据自动识别
建立样本数据集和模型后即可自动识别,本文深度学习网络如图7 所示。
输入层:输入224×224×3 的图像,其原因是彩色图像有3 个通道。
卷积层1+下采样:由96 个11×11×3 的滤波器、步长为4对输入层进行卷积,卷积后得出96 个55×55 大小的特征图。接着采用Maxpooling 方法进行特征图下采样,其下采样窗口为3×3,步长Stride 设计为2,最终得出96 个27×27 大小的特征图像。
卷积层2+下采样:首先由256 个5×5×48 的滤波器对卷积层1 下采样,需要注意的是该层为图像两边各补充2 个像素点,所以按照公式(27-5+2×2+1)/1 的数据进行卷积,得出256 个27×27 的特征图。然后采用Maxpooling 方法进行特征图下采样,其下采样窗口为3×3,步长Stride 设计为2,最终得出256 个13×13 大小的特征图像。
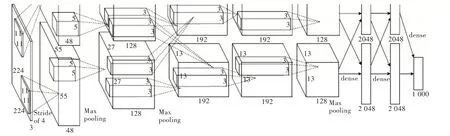
Fig.7 Deep learning network model图7 深度学习网络模型
卷积层3:用384 个3×3×256 的滤波器对卷积层2 下采样后的特征图像进行卷积操作,注意为图像两边各补充1个像素点,采用公式(13-3+2×1+1)/1 得出384 个13×13 的特征图,结果在两个GPU 共同存储,这是两个GPU 进行的唯一一次数据交流。
卷积层4:除了卷积对象是卷积层3 的数据GPU 不进行数据交流,其余步骤和卷积层3一样,得384个13×13特征图。
卷积层5:用256 个3×3×192 的滤波器对卷积层4 的数据进行卷积,同时在这一步骤中会对图像进行Padding 操作,为图像两边各补充1 个像素点,得到256 个13×13 特征图。然后采用Maxpooling 方法进行特征图下采样,其下采样窗口为3×3,步长Stride 设计为2,最终得出256 个6×6 的特征图。
全连接层1:将卷积层5 下采样后的256 个6×6 特征图的像素排成一列,即共有9 216 个元素作为输入,然后调用神经网络设计全连接层的参数将之维度下降到4 096 维。
全连接层2:将全连接层1 的特征数据通过全连接神经网络后,输出得到4 096 维特征数据。全连接层3:将全连接层2 的特征数据经过全连接神经网络降维后,输出得到1 000 维特征数据。
3 实验结果
实验平台见表1,预测类别准确率见表2,训练和验证损失函数曲线见图8,检测结果见图9。

Table 1 Experimental platform表1 实验平台

Table 2 Accuracy of prediction categories表2 预测类别准确率(%)

Fig.8 Training and validation loss function curve图8 训练和验证损失函数曲线

Fig.9 Test results图9 检测结果
4 实验分析
实验使用乌班图16.04 操作系统,tensorflow-GPU 版本深度学习开发环境,CPU 采用英特尔9900K,GPU 采用11G显存的Nvdia RTX2080Ti,如表1 所示。经过30 个epoch 训练之后检测模型对所有类别的检测平均准确率可以达到94%,尤其是对建筑的检测率最高,达到98%,可以满足建筑物检测需求,但是对树的检测准确率只有92%,如图8 所示。经过实验数据分析,数据集中建筑物样本分布更加平均,样本数量更加丰富;树样本分布集中在部分图片中,样本分布密集且数量较少,所以导致树的检测率较低,这是后期数据集需要改进的地方。
5 结语
本文创新性地将“无人机”和“深度学习”两大新兴热门技术应用到城市管理工作中。通过无人机飞控API 函数设计并编程实现划定无人机飞行区域、高度、图像数据采集频率,避免“乱飞”,采集有效的无人机视觉数据;拓展深度学习应用领域,建立城市管理深度学习图像数据集;设计适合城市管理需要的深度训练和识别网络,建立城市管理深度学习模型;利用无人机的飞行优势,对城市中特定区域内的建筑进行识别,及时、准确、直观地掌握城区建筑物现状,有效拓展城市建筑管理执法视野和效率,使城市建设监管更加科学有效。
本文提出的设计框架和实施路线具有极强的通用性,除了检测建筑,该技术还可以拓展到其他领域,如基于无人机平台的城市交通拥堵自动识别;基于无人机航拍的人体异常行为检测;基于无人机的农业病虫害预防应用等。通过对不同场景下的数据进行训练,实现无人机在不同场景的识别功能,发挥该模型丰富的应用潜能。
