基于FCM-IGA-FNN 的海洋蛋白酶发酵过程软测量
2021-03-25张卫国王维杰
张卫国,王维杰
(1.扬中市威柯特生物工程设备有限公司,江苏扬中 212200;2.江苏大学电气信息工程学院,江苏镇江 212000)
0 引言
海洋蛋白酶在发酵领域受到了广泛关注,相比陆生菌种产生的蛋白酶,其具有耐高压和耐低温的特性,被广泛运用于食品[1]、医学[2-3]、纺织[4-5]等领域。然而,海洋蛋白酶复杂的发酵过程令大规模工业生产受到限制,最主要的原因是其细胞生长情况复杂,并且关键生物参量没有对应的生物传感器,很难进行在线观测[6]。为了获取这些关键生物参量,通常采用人工取样方法,然后进行离线测量。离线检测具有较高的专业性,但在时间上严重滞后,容易造成较大的测量误差,若操作不当,甚至会引入人为污染,造成严重后果。为了能够反映海洋碱性蛋白酶发酵过程中的相关状态,并进行实时调节与控制,研究者们运用了基于软测量的各种控制策略。其中,模糊神经网络(Fuzzy Neural Network,FNN)由于具有较好的性能,得到了广泛运用[7]。
软测量技术的主要思想是通过构造不可直接测量的关键参量与直接可测参量之间的数学模型,用计算机软件实现对关键参量的预测[8]。其中,模糊神经网络应用广泛,针对模糊逻辑和神经网络的缺陷,将模糊理论与神经网络相结合,同时兼具两者的优势,不仅能将信息模糊化,之后进行模糊推理,而且具有良好的自适应能力,所以被广泛运用于复杂非线性系统的软测量建模中[8-10]。国内外不少学者对此展开了深入研究,并取得了诸多成果。如王永海等[11]采用混合群智能算法优化FNN,得到了结构简单、精度更高的模型;邹海英等[12]对建模参数进行特征提取,挑选合适的参数建立自适应模糊神经网络,将其应用于肾小球滤过率预测,结果表明,模型误差较小,泛化能力增强;孙玉坤等[13]提出在动态递归模糊神经网络中运用免疫遗传算法,并将该方法应用于赖氨酸发酵过程菌体浓度检测中,展示了较高的预测精度。之后也有不少发酵领域的学者对此进行了补充,取得了理想的预测效果[14-18]。
然而,由于海洋碱性蛋白酶是一种新型生物酶,相关专家经验是严重不全,甚至缺失的,以上方法在建立模糊神经网络初始模型时,其中的规则数和权值都没有可靠数据作为参考,因此不但会延长收敛时间,而且可能降低预测精度。基于此,本文提出一种FCM-IGA-FNN 软测量模型,利用模糊C 均值(Fuzzy C-means,FCM)对数据进行特征提取,并运用混沌算法优化遗传算法(Improved Genetic Algorithm,IGA)弥补了专家经验的缺失,避免了传统遗传算法后期陷入局部收敛的问题,然后将其应用于海洋蛋白酶发酵过程关键生物量预测中。仿真结果表明,对于缺乏经验知识的海洋蛋白酶发酵过程,该方法具有良好的建模精度与较强的实用性。
1 基于模糊C-均值聚类的模糊神经网络
基于FCM-FNN 的软测量建模流程如图1 所示。首先利用模糊C 均值对发酵过程中关键生物参量的样本数据空间进行聚类分析,每一个样本数据都可通过公式计算得出其与聚类中心相关数据,如两者间距离和隶属度关系等,根据这些数据挑选出更优的聚类中心,如此反复运算,当数据不再变化时迭代停止,对相关数据进行去模糊化处理,提取模糊规则;然后利用计算得到的初始参量构造初始模糊神经网络,并用混沌算法修饰免疫遗传算法,优化模糊神经网络的梯度信息获取。将该模型应用于海洋蛋白酶发酵过程中的关键生物参量在线预测,以验证提出的软测量建模方法的有效性。

Fig.1 Soft sensor modeling process based on FCM-FNN图1 基于FCM-FNN 的软测量建模流程
1.1 模糊C-均值算法
首先设定c个初始聚类中心,计算数据集中其它数据与c个初始聚类中心的欧氏距离函数以及隶属度关系,反复循环迭代。当聚类中心保持不变时,其划分结果达到最优。记录此时的模糊组,再通过一定规则使模糊聚类去模糊化,由此得到模糊规则数M[19-20]。FCM 规则流程如图2所示。
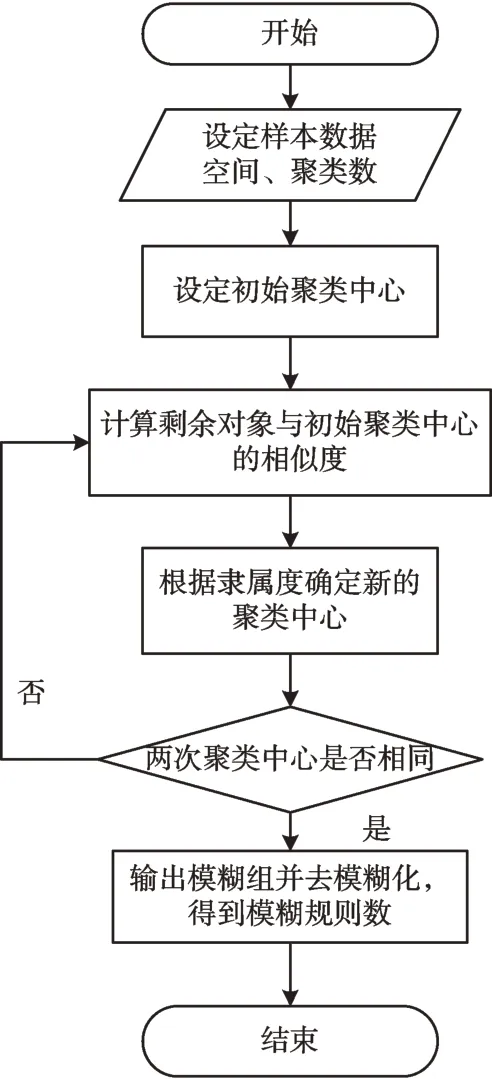
Fig.2 Flow of FCM rules图2 FCM 规则流程
考虑如下形式的模糊规则:
Rl:如果x1为,…,xn为,则y为Gl。
其中,,……,和Gl分别为u∈R与v∈R上的模糊集合,且x=(x1,x2,…,xn)T∈u1×u2× …×un和y∈R是语言变量;l=1,2,…,M,M为模糊规则库中包含的模糊规则总数,x、y分别为模糊逻辑系统的输入和输出。
设数据x={x1,x2,…,xn}是n个待聚类样本,算法如下:
(1)固定聚类数c和模糊加权指数b(1 <b<!),随机设置v(0),置k=1,取ε>0。
(2)计算隶属度矩阵u(k)如下所示:
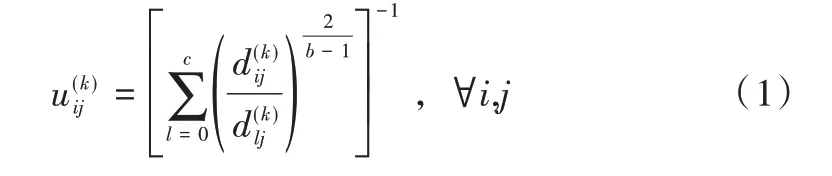
(3)计算新的聚类中心v(k+1)如下:

利用FCM 算法对海洋蛋白酶发酵过程的样本数据空间进行聚类分析,聚类个数M取12,并通过反复迭代,直到数值不再改变,求解得到聚类中心。每一个样本点都与聚类中心存在偏差,通过该偏差可获得隶属度函数的宽度,构建的最终隶属度函数如图3 所示。
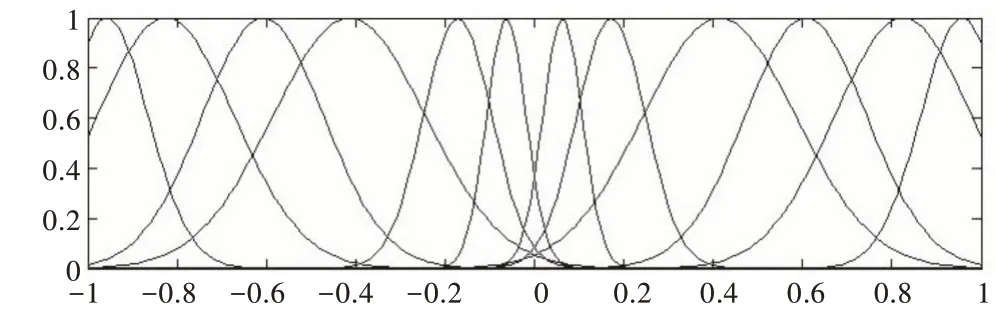
Fig.3 Initial membership function图3 隶属度函数
1.2 基于改进免疫遗传算法的模糊神经网络
1.2.1 模糊神经网络
通过以上FCM 算法可得到用于搭建模糊神经网络的初始参数。本系统采用经典的模糊神经网络结构(见图4),该结构共有4 层,第1 层将控制变量x1、x2、…、xn输入网络;第2 层对输入数据x1、x2、…、xn进行模糊化处理,对应的隶属度函数采用exp(-(x-a)2/b2);第3 层对应模糊推理;第4 层对应去模糊化。该网络各层之间的相互关系如下所示:
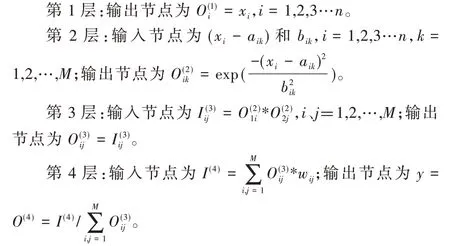
其中,xi为网络输入和wi为网络连接权值,其中规则数M是由前面的模糊C 均值算法确定的,即M=12。
1.2.2 改进型免疫遗传算法设计与实现
针对模糊神经网络在收敛过程中往往难以获得相应梯度信息的问题,遗传算法不依赖梯度信息的特性很好地弥补了这一缺陷。免疫遗传算法IGA 基于生物体中的免疫原理对遗传算法加以改进,当外来抗原入侵生物系统时,对其进行识别,判断“异己”,从而产生对应的抗体以抵抗抗原。通过两者间的相互刺激与抑制,解除抗原对抗体的威胁,并有部分产生抗体的细胞以记忆细胞的形式保留下来,能更好、更快地处理相应抗原。
免疫遗传算法大体步骤如下:①随机获取初始群体;②计算抗体浓度及适应度;③对抗体进行促进与抑制处理;④群体更新(交叉和变异)。
虽然IGA 在避免“早熟”方面有了很大提升,但还存在收敛于局部值的缺陷,对此采用混沌算法加以补充,并在算法结束前进行早熟判断并作相应处理。具体方法如下:
采用混沌算法对初始种群进行优化:
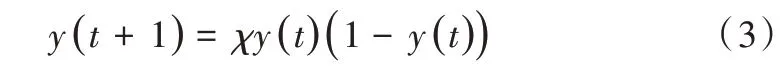
当迭代次数不断增加时,“聚集现象”难以避免,只能对早熟现象加以判断并作相关处理,计算单独粒子在群体中的适应度方差:
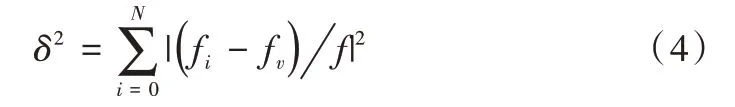
其中,fi是第i个粒子的适应度值,fv是当前粒子群体的平均适应度值。引入因子f对作归一化处理,使其取值在[ 0,1 ]之间。
设ε、fep分别为适应度定值和适应度精度,若满足条件,连续有N0代符合δ2<ε,且>fep,则可判断算法陷入局部最优。
当算法陷入局部最优时,可按照式(5)调节变异因子FG。其中,g为种群迭代次数,gm为最大迭代次数,从而摆脱局部最优。

在改进的免疫遗传算法中,染色体由3 组基因组成,分别由神经网络中的参数wij、aik、bik表示。参数选择如下:取抗体种群规模Mpop=34,交叉与变异概率分别为Pc=0.80,pm=0.02,进化截止代数为100;在抗体浓度计算中,取亲和力常数为0.9。
2 仿真验证
实验室使用100L 容积的小型发酵罐作为海洋蛋白酶发酵装置,根据发酵机理及相关经验选择电机转速、溶氧量、温度、pH 值、碳源(琼脂粉)流加速率fap(u1)、氮源(蛋白胨)流加速率fp(u2)、无机盐(K2HPO4)流加速率fk(u3)作为输入量,菌体浓度X(x1)、相对酶活P(x3)和基质浓度S(x2)作为输出量。根据海洋蛋白酶发酵的工艺要求,发酵罐内压强维持在0.1MPa,pH 稳定在9.5 左右,温度控制在25℃。每2h 取样一次,并离线分析菌体浓度、产物浓度及相对酶活。
共采用10 批次数据,4 组作为训练数据,其中2 组数据用来确定FCM 算法中的模糊规则数和隶属度函数,2 组用来确定模糊神经网络初始结构;再取4 组数据用于网络模型测试,建立FCM-IGA-FNN 软测量模型;最后2 组数据作为验证数据,检测网络模型的泛化能力并计算预测误差。两种不同预测模型仿真结果如图5-图7 所示(彩图扫OSID 码可见)。
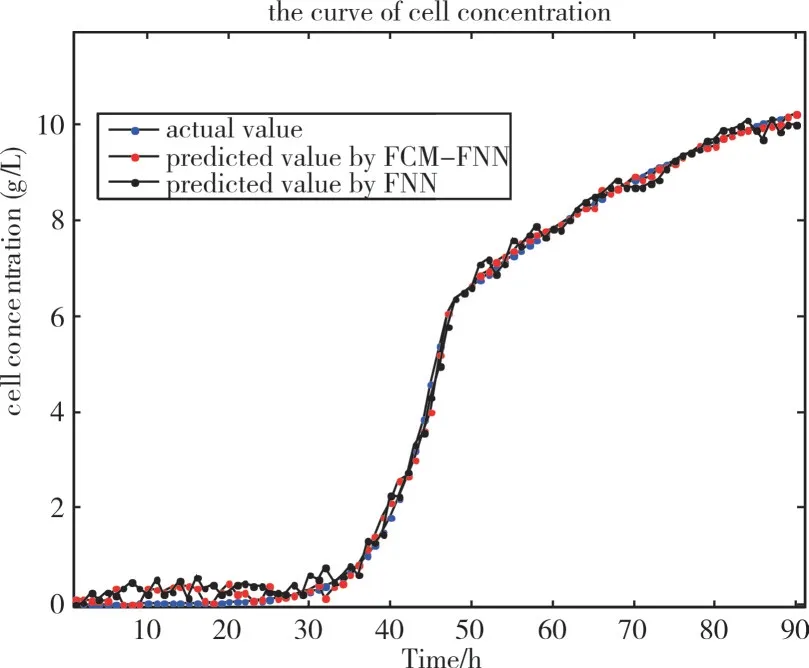
Fig.5 Prediction results of bacterial concentration图5 菌体浓度预测结果

Fig.6 Prediction results of matrix concentration图6 基质浓度预测结果
为了更好地进行评估,本文从数据上比较FCM-IGAFNN 模型与传统神经网络的性能,指标为均方误差(RMSE),具体对比结果如表1 所示。
通过仿真图中的曲线对比可知,基于模糊C 均值的模糊神经网络模型具有更好的拟合精度和泛化能力。通过均方误差的对比分析可知,FCM-FNN 方法相较于传统FNN,对于菌体浓度、基质浓度和相对酶活的预测精度分别提高了0.234、0.190 和1.00,体现出较好的预测精度。

Fig.7 Relative enzyme activity prediction results图7 相对酶活预测结果
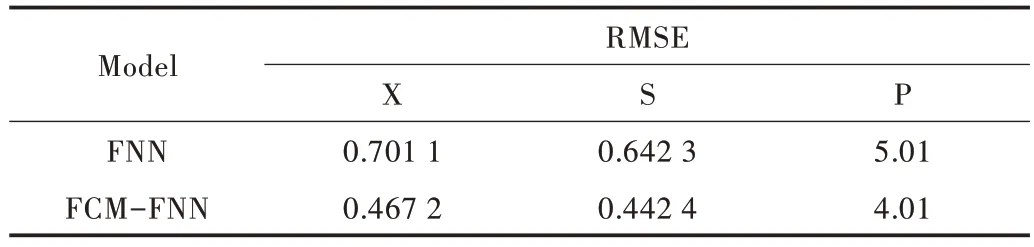
Table 1 Comparison of RMSE for two different models表1 两种不同模型均方误差对比
3 结语
本文提出一种基于模糊C 均值的免疫遗传模糊神经网络软测量建模方法,用于海洋蛋白酶发酵过程参量预测。该方法首先利用模糊C 均值对输入及输出数据进行处理,运用改进的免疫遗传算法调整隶属度函数参数和模糊神经网络连接权值,然后建立模糊神经网络模型,解决了其过早收敛的问题。将提出的FCM-IGA-FNN 方法应用于海洋蛋白酶发酵过程关键生物量预测,并与传统模糊神经网络进行比较,仿真结果表明,FCM-IGA-FNN 方法的预测精度更高,鲁棒性更强,对海洋蛋白酶的发酵过程具有指导意义。另外,在发酵关键参量预测研究中,动态优化问题将是未来的研究重点。
