一种基于XGboost的异常检测算法
2021-03-24陈适宜
陈适宜


摘要:为了提高异常检测的准确性和高效性,提出了基于xgboost的异常检测算法。首先对异常检测当前遇到的挑战进行分析,指出缺少样本和模型泛化是异常检测中的难点。在此基础上设计了异常注入算法,利用3sigma原则对数据集进行扩充;然后设计特征提取器,针对正常数据和异常数据的特点设计相关特征;最后选择xgboost模型对时序数据进行异常检测。此异常检测流程提高了异常检测的准确性和泛化能力。通过在KPI公共数据集上进行实验,验证了该设计的准确性和有效性。
关键词: 异常检测; xgboost; 异常注入; 特征提取; 智能运维
中图分类号: TP311 文献标识码:A
文章编号:1009-3044(2021)02-0188-02
Abstract:In order to improve the accuracy and efficiency of anomaly detection, an anomaly detection algorithm based on xgboost is proposed. First, analyze the current challenges of anomaly detection, and point out that lack of samples and model generalization are the difficulties in anomaly detection. On this basis, an anomaly injection algorithm is designed, and the data set is expanded using the 3sigma principle; then a feature extractor is designed to design related features according to the characteristics of normal data and abnormal data; finally, the xgboost model is selected to perform anomaly detection on time series data. This anomaly detection process improves the accuracy and generalization ability of anomaly detection. Through experiments on the KPI public data set, the accuracy and effectiveness of the design are verified.
Key words:anomaly detection; xgboost;anomaly injection;feature extraction;AIOPS
計算机硬件和软件的飞速发展带来了功能强大的应用,但是由于硬件、软件和人为等原因,程序时刻都有可能发生故障。及时发现并快速介入故障,能最小化对用户体验的损害。为了能够及时发现故障,需要对系统进行连续监控,系统监控从数据分析的角度来看,即意味着需要不间断地监控大量时序数据,以检测出潜在的异常。由于需要监控的时序数据规模很大,通过人工的方式是几乎不可能的,这就要求我们使用机器学习和数据挖掘技术进行自动异常检测。
异常或者异常点是指与其他数据明显不同的数据点,异常检测旨在发现这些异常点。通常,时序数据是由一个或多个反映系统功能或业务能力的应用程序创建的,当这些应用程序发生行为异常时,就会产生异常点。准确的异常检测可以快速准确的定位故障并进行故障排除,对入侵检测、信用卡欺诈、医疗诊断等[1]等实际应用有重大意义。但是,当前时序数据的自动化异常检测服务面临着许多挑战。
挑战1:缺少样本。在实际中,故障发生的概率较低,从而导致很难积累大量异常样本。这就要求我们必须具备自动化构建样本的能力以支持异常检测模型的训练。
挑战2:模型泛化。时间序列有不同的模式:周期型、稳定型和无规律波动型,系统需要能够对这些不同模式的时间序列识别出异常。
为了解决上述问题,本文开发了一种准确、高效、通用的异常检测方法,解决了样本缺少与模型泛化问题。本文重点研究了针对时间序列数据的异常检测服务的机器学习算法,包括样本增强,样本特征设计和基于xgboost的异常检测。
1 基于3sigma原理的异常注入算法
基于机器学习的异常检测算法缺乏训练数据,数据集中包含的异常点比例总是远远少于正常点,这阻碍了算法的训练和实用性,同时,依赖人工标注异常数据工作量大且不易完成。虽然可以通过传统的机器学习过采样或欠采样来动态调整正负样本比例,但是过采样会使异常样本过于单一,最终导致分类器过拟合。因此,本文开发了一种自动异常注入算法,在保证异常注入的随机性和多样性的同时有效地扩充数据集。
1.1 3sigma原理
3sigma原则[2]是一种最常使用的处理异常值数据的方法。3sigma原理可以简单描述为:若数据服从正态分布,则异常值被定义为一组结果值中与平均值的偏差超过三倍标准差的值。即在正态分布的假设下,距离平均值三倍标准差之外的值出现的概率很小,因此可认为是异常值。数值分布在[(μ-3σ,μ+3σ)]中的概率为0.9973其中,[μ]为平均值,[σ]为标准差。
一般可以认为,数据的取值几乎全部集中在[(μ-3σ,μ+3σ)]区间内,超出这个范围的可能性仅占不到0.3%,这些超出该范围的数据可以认为是异常值。
1.2 基于3sigma原理的异常注入算法
根据3sigma原理,我们可以根据原始数据生成异常数据,生成的异常数据插入原始数据中可以生成异常样本。通常异常的产生会持续一段时间,然后逐步恢复,恢复过程会影响异常两侧的值。异常注入算法步骤如下:
首先给定一段时序值S,确定注入的异常个数N,将时序数据划分为N块;对每一块数据X进行异常注入:
①随机选定一个点Xi作为异常种子;
②设定异常点数目范围[2,15],基于此范围,产生随机异常点数anomaly_count;
③异常点随机分布在异常种子两侧,左侧和右侧的数目均随机产生;
④异常数据的产生基于异常种子点两侧的值,设定种子点两侧范围区间为[15,30],两侧的数目由上述区间随机产生,异常点的基础数据anomaly_base_data。
接下来确定异常点的数据,基于3sigma原理,异常点的大小计算如下:
①产生一个随机数,若为奇数,该次为异常上涨,否则异常下跌;
②利用异常基础数据产生异常值。根据数据波动范围的不同,可将数据分为不同的类型比如成功率、延时型和0值突刺型,三种类型数据特征如下:成功率型,取值范围大多在40-100之间,少部分在0.5-1之间,数据波动小,标准差较小,经常为0;延时型,在一定范围内波动,波动较小,标准差基本不随时间变化;0值突刺型,多为0值,偶有突刺,突刺不一定是异常值。根据不同类型的数据取不同的均值和方差生成异常数据。
异常点会引起异常两侧的值有波动,设定一个影响范围,随机产生影响的范围大小,使用3sigma原理生成异常点附近的波动值。
确定好左右两侧影响范围后,随机产生异常衰减的方式,分三种:简单移动平均、加权移动平均、指数加权移动平均。左侧影响的值的产生由其右侧的值移动平均产生,对于右侧影响范围的值的确定,直接由左侧的值移动平均产生。
2 特征提取
2.1 孤立森林
孤立森林,由周志华教授等人于2008年提出[3]。在孤立森林中,认为异常是“少且不同于其他值”,因此异常值更容易被隔离。在生成随机树的过程中,递归随机地重复进行数据集的化分,在这种随机分割的策略下,异常点通常具有较短的路径。
2.2 特征设计
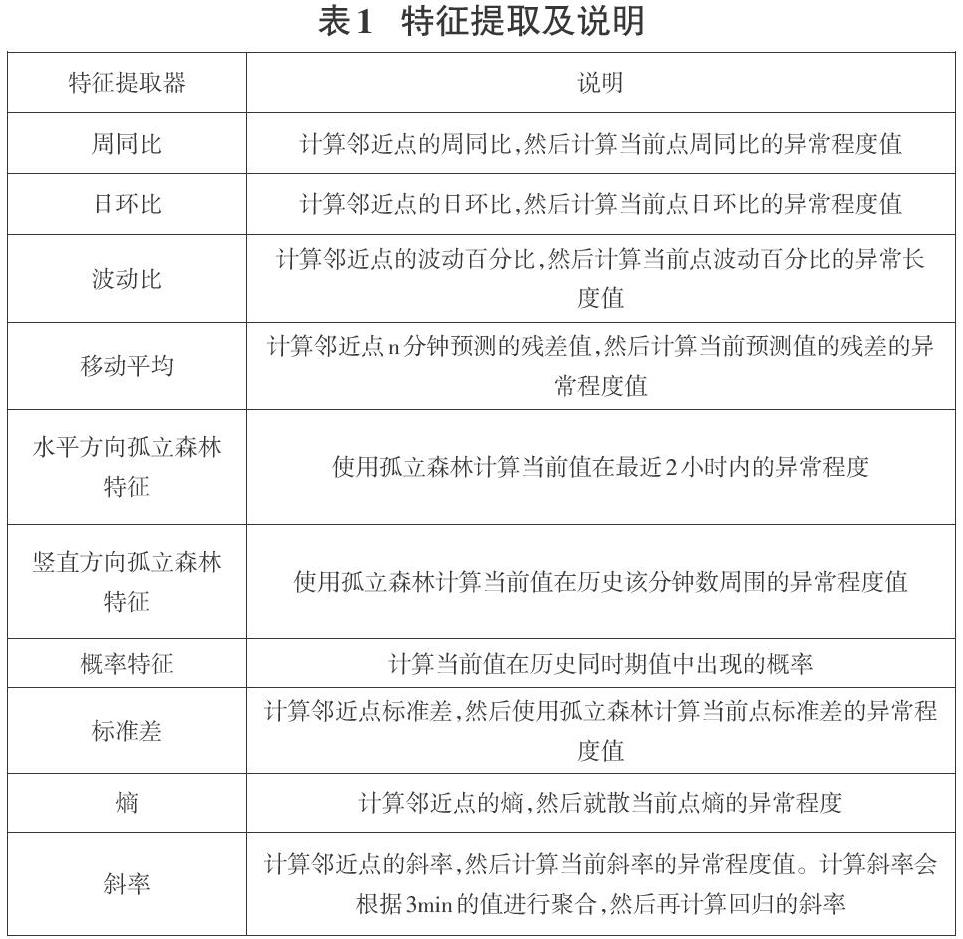
由于数据值大小、波动情况均有所不同,设计提取数据特征是提高异常检测泛化能力的前提。腾讯Metis[4]将其分为三种特征,一是统计特征,包括方差、均值、偏度等统计学特征;二是拟合特征,包括如移动平均、指数加权移动平均等特征;三是分类特征,包含一些自相关性、互相关性等特征。参考Metis的特征提取方法,本章设计了一套特征工程,区别于上述特征提取方法,本文对提取的结果用孤立森林进行了一层特征抽象,使得模型的泛化能力更强,所选择的特征及说明如表1所示。
3 基于xgboost的异常检测
Xgboost[5]是基于决策树的集成机器学习算法。2015年Kaggle发布的29个获胜方法里有17个用了Xgboost。Xgboost具有高可扩展性和高计算速度,广泛被应用在实际中。使用Xgboost进行异常检测流程如下图所示。
在训练阶段,首先将进行异常注入的数据集标注好,然后通过章节2设计的特征提取器构建特征数据集,再将特征数据集输入xgboost模型训练,最后保存训练好的模型。在测试阶段调用保存好的xgboost分类模型进行预测,最终得到异常检测结果。
4 实验结果
我们使用KPI数据集来评估我们的模型。KPI由AIOPS数据竞赛发布[6-7],通常用于评估时间序列异常检测的性能。该数据集由多个KPI曲线组成,这些曲线从各个互联网公司(包括搜狗,腾讯等)收集。异常点被标记为正样本,正常点被标记为负、正样本。本章从精确性、召回率和F1分数来表示模型的准确性。
首先,将KPI数据集分为训练集和测试集,训练集和测试集比例为7:3。经过章1的异常注入算法处理训练集并标注,特征提取后输入xgboost进行训练。测试集使用FFT[8]、Twitter-AD[9]、xgboost异常检测模型结果如表2。
5 总结
智能化以及数据化是未来 IT 运维的总体趋势,互联网业务的连续性保障的方方面面将依靠智能运维。异常检测是智能运维的首推场景。本文首先介绍了基于3sigma原理的异常注入算法,接着介绍了异常检测的特征提取器,最后确定基于xgboost异常检测的整体流程。将设计的特征提取器应用到数据集上得到特征数据集,特征数据集输入xgboost进行训练和测试,与现有模型相比获得了更好性能。
参考文献:
[1] C. Aggarwal. Outlier Analysis. Springer New York, 2013.
[2] https://www.cnblogs.com/hellochennan/p/6706884.html.
[3] Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou. “Isolation forest.” Data Mining, 2008. ICDM08. Eighth IEEE International Conference on. IEEE, 2008.
[4] https://github.com/bchretien/metis4.
[5] Chen T , Guestrin C . XGBoost: A Scalable Tree Boosting System[J]. 2016.
[6] [n. d.]. http://iops.ai/dataset_detail/?id=10.
[7] [n. d.]. http://iops.ai/competition_detail/?competition_id=5&flag=1.
[8] Faraz Rasheed, Peter Peng, Reda Alhajj, and Jon Rokne. 2009. Fourier transform based spatial outlier mining. In International Conference on Intelligent Data Engineering and Automated Learning. Springer, 317–324.
[9] Owen Vallis, Jordan Hochenbaum, and Arun Kejariwal. 2014. A Novel Technique for Long-Term Anomaly Detection in the Cloud. In 6th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 14). USENIX Association, Philadelphia, PA.
【通聯编辑:唐一东】
