基于机器学习的找矿预测模型在湖南岳溪锑矿田的应用
2021-03-24秦耀祖吴伟成谢丽凤欧鹏辉黄小岚
秦耀祖,吴伟成,谢丽凤,欧鹏辉,黄小岚
(1.东华理工大学 江西省数字国土重点实验室,江西 南昌 330013;2.东华理工大学 地球科学学院,江西 南昌 330013)
随着地质勘查技术的发展和数据采集手段的更新,人们在矿产资源勘查开发过程中获取的地质信息量越来越丰富。通过地理空间数据挖掘,提取与地质找矿相关的多源地质空间信息,并揭示其与矿体之间的空间相关性,是开展地质找矿工作的一个重要前提(Agterberg et al.,1999;Yousefi et al.,2016;Qin et al.,2018)。这些多源空间信息可以分成两类:一类是与矿体形成及分布具有成因联系的地质体要素,如地层、岩体等地质实体和断层、褶皱等构造要素;另一类是有利于找矿的勘探数据和研究成果,包括地球物理、化学和遥感等探测数据,温度、应变和元素含量等场数据。从数据特征方面来看,包含这些信息的数据虽然很难满足狭义大数据的5V特征(Variety、Volume、Value、Veracity和Velocity),但其符合重全体不重抽样、重效率不重精确和重关联不重因果三个广义大数据的技术取向(张旗等,2017)。因此可将其归为地质大数据,可以利用大数据挖掘思维开展空间信息挖掘和资源预测评价(周永章等,2017,2018)。
在不同研究程度和信息结构的工作区,对于地质大数据的挖掘处理、空间相关性的定量分析以及矿产资源的预测评价,一般可通过知识驱动、数据驱动和混合驱动中一种或多种数学地质方法来实现(Yousefi et al.,2017)。如利用超平面进行数据分割分析的支持向量机(SVM,Boser et al.,1992),在地理空间相关性分析和成矿潜力图绘制中得到了广泛的应用(Smirnoff et al.,2008;Zuo et al., 2011;季斌等,2015);由多棵决策树构建而成的随机森林(RF,Breiman,2001),最近几年来逐渐应用于地质制图和成矿预测,并且在与多种机器学习算法应用的比较中表现出了一定的优势(Cracknell et al.,2014;Carranza et al.,2015;Wu et al.,2018;Sun et al.,2019)。这类方法通过对地质空间信息的样本数据集(每个样本由含矿标签及相应的特征变量属性构成)进行训练和学习,构建针对矿化是否发生的非线性高性能分类器,并将其应用于研究区的预测数据集,实现成矿概率定量化估算和成矿潜力精确制图。
湖南省安化县岳溪矿田位于雪峰弧形构造带中段之金锑钨多金属成矿带上,与其西南方向的渣滓溪、羊皮帽等锑(金)矿田一样,均具有较好的找矿前景(张建新,1993)。20世纪初,在该矿田的同心锑矿床就有民采活动,建国后逐步形成了具有一定规模的开采矿山,现已成为矿田中最大的生产矿山。截至目前,虽然先后有湖南地矿418队、414队及湖南有色地勘局二总队等多个勘探队伍对其开展了一定程度的地质调查和矿体勘查工作,并从地质特征和矿床成因方面定性地做了一些探讨(张建新,1993;刘光召等,2014)。但地质找矿工作未能取得突破性进展。为此,在对同心锑矿床主要地质体进行三维模拟和空间分析的基础上(秦耀祖等,2019),通过集成岳溪矿田的遥感矿化蚀变、构造缓冲区和地球化探数据等多个地质找矿因子,构建基于机器学习算法的分类预测模型,旨在开展基于数据驱动的定量找矿预测工作。
1 地质概况
1.1 区域地质概况


图1 同心锑矿及其周边区域地质简图(据刘光召等,2014修改)Fig.1 Regional geological sketch map of the Tongxin Sb deposit and its surrounding areas 1.二叠系;2.石炭系;3.泥盆系;4.奥陶系;5.寒武系;6.震旦系;7.板溪群五强溪组;8.板溪群马底驿组;9.断裂;10.锑矿床(点)
1.2 矿田地质特征
1.2.1 出露地层
矿田内出露的地层有板溪群五强溪组(PtBnw)、震旦系下统江口组(Z1j)、震旦系下统洪江组(Z1h)、震旦系上统金家洞组(Z2j)、泥盆系中统跳马涧组(D2t)、泥盆系中统棋子桥组 (D2q)以及石炭系中统黄龙组(C2h,如图2所示)。其中板溪群五强溪组沉积韵律特征明显,下段以灰绿色石英砂岩、砂质板岩及板岩为主,是主要含矿地层;中段为一套白色、灰白色的巨厚层石英岩、厚层变质石英砂岩,并夹有砂质板岩和粉砂质板岩,常见有浸染状或细脉状锑矿化。

图2 岳溪矿田地质图(据刘光召等,2014修改)Fig.2 Geological map of the Yuexi orefield1.石炭系中统黄龙组浅灰色白云岩,底部紫红色砂岩等;2.泥盆系中统棋子桥组浅灰色生物碎屑灰岩,白云质灰岩;3.泥盆系中统跳马涧组浅紫红色陆源碎屑岩系;4.震旦系上统金家洞组浅灰色冰碛砾岩;5.震旦系下统洪江组黑色炭质板状页岩;6.震旦系下统江口组灰绿色纹带板岩;7.板溪群五强溪组中段灰白色巨厚层石英砂岩;8.板溪群五强溪组下段灰绿色石英砂岩夹板岩;9.同心锑矿矿区界限;10.次级破碎带;11.断层;12.河流;13.矿体或矿化区
1.2.2 主要成矿构造
矿田内与成矿有关的构造主要为贯穿矿田的岳溪深大断裂(F1),其为成矿流体的运移提供了通道。F1为NE—SW走向的逆断层,地表出露宽度约20 m,其SW盘(即上升盘)地层被剥蚀至板溪群五强溪组下段(刘光召等,2014)。F1在上部(标高-400 m以上)陡倾斜,下部变缓,且在上盘面出现一个凹糟。在同心锑矿床及其外围,F1的次级破碎带群(如1#至8#破碎带)是主要的导矿和赋矿构造。这些次级断裂间距小,倾角大,NE部收敛于F1,SW逐渐散开,呈扫帚状分布,整体呈陡倾斜,在深部依次交汇至F1。
1.2.3 矿体产出特征
矿田内已发现的矿体主要以团块状、细脉状及浸染状产出于F1的次级破碎带群及其附近。破碎带内的矿体主要呈浸染状或细脉状,陡倾斜。在破碎带转折处或相邻破碎带之间,常有似层状矿体产出,倾向较缓,延伸30 m左右,走向方向与破碎带相近,延伸长度40~100 m。其中心位置矿石以高品位的团块状为主,边缘位置呈细脉浸染状或网脉状。
2 方法与途径
矿体的形成是一个极其复杂的非线性过程。对于矿体定位和资源评价,需要考虑到研究区的矿床地质背景、地质勘探程度以及前期的研究成果和认知。本次研究是在地理信息系统(GIS)平台上,选用合适的方法和技术,对与成矿及赋矿相关的地质信息进行挖掘、集成和分析,建立地质数据库,进而构建数学地质模型,开展空间相关性分析、成矿预测及资源评价工作(图3)。

图3 找矿预测模型的构建方法和流程Fig.3 Methods and procedure of mineral prospectivity modeling
2.1 随机森林
2.1.1 概念
随机森林算法通过使用计算机对样本进行训练并学习,构建一系列的分类回归决策树(CART):h(x,θk),并通过某种策略把这些决策树进行整合,组成一个树型分类器{h(x,θk),k=1,2,…,n}的集合,进而获得更好的学习效果。其中θk作为独立分布的随机向量,决定了每棵树的生长;x为分类器的输入向量(Breiman,2001)。随机森林在决策树的基础上,引入了引导组合法(Bagging)和随机子空间(Random subspace)两个过程,从而使每棵分类树具有不同的分类能力,从而减少了决策树因生长过程的不稳定性所带来的差异, 从而改善了预测精度。
CART是一种典型的二叉决策树。决策树是一种{h:x-y}形式的树型结构预测器。通过某种策略,从根节点开始,对观测实例x的一个或多个属性进行测试比较,最终将其属性标签预测至叶子节点(Swain et al.,1977)。CART利用树的结构将数据记录分成三类节点:根节点、中间节点和叶节点。对一个多维特征空间,在根节点和中间节点寻找最优特征(维)并对该特征的取值进行二叉树分裂。当待预测结果是离散型数据时,CART采用Gini指数作为节点分裂依据(蒋艳凰,2009),生成分类决策树。如果是连续型数据时,则通常采用样本的最小化误差平方和(SSE)作为节点分裂的依据,生成回归决策树。
2.1.2 构建过程
在数据集D中,带有标签(目标变量和特征变量)的样本总数为S个。构建随机森林的方法途径如下:
(1)Bagging法构建决策树样本集。采用Bootstrap采样法(随机有放回抽样)从样本集DS中选出n(约为70%)个训练样本,作为训练集DT(剩余的30%称作袋外数据,可作为测试集DV用来无偏估计模型误差),用来训练一棵决策树。
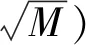
(3)按照步骤2的分裂过程,采用Bagging法,构建Ntree棵不需要剪枝的决策树(弱学习器)(方匡南等,2011)。
(4)将构建的多棵决策树对测试集进行测试,根据所有树分类结果的多数投票法(分类问题)或算术平均法(回归问题)构建随机森林模型(强学习器),应用于预测集Dp(即数据集D)进行分类预测。
2.1.3 特征变量重要性评估
在基于R环境的分析平台(https://www.r-project.org)上,可用基尼系数下降平均幅度(MDG)和模型准确度下降平均幅度(MDA)来评估随机森林模型的特征变量重要性。MDG表示每个特征变量在每棵决策树节点上对Gini指数平均减少量所做的贡献,即每个变量对树节点上观测值异质性的影响;MDA表示将变量随机化后对模型准确性降低程度的影响。这两个指标值越大,表示相应变量的重要性越大(李欣海,2013)。
2.2 支持向量机
2.2.1 概念
支持向量机是一种二分类模型算法,其核心思想是使用核函数为高维度原始样本(输入空间观测值)的映像构造一个最优超平面,通过空间变换,实现分离重排和线性可分。这个超平面就是最大可能的分类安全边际,最接近这个边际的观测值就是支持向量。对于线性可分的数据,支持向量机可通过学习得到分离超平面及相应的分类决策函数;当为线性不可分时,则对松弛变量引入调优参数,使其满足新的约束条件。对于线性支持向量机分类器,其公式为:
(1)
式中,(x,xi)是支持向量的内积,即对应向量的乘积之和,αi为该内积的最优参数,β0为域值。
对于非线性问题,需进行低维到高维的空间映射变换,实现线性可分。由于变换后维数增加导致内积计算量增大,故引入核函数(周永章等,2018),使其不用将观测值转换到高维空间,就可以计算其在高维空间中的内积。用xi和xj代表向量,将核函数(K)、调优参数(γ,用于非线性分类器) 和违反约束时的成本函数(记为c) 作为关键参数。
线性核函数:
K(xi,xj)=xi·xj
(2)
Sigmod核函数:
K(xi,xj)=tanh(γxi·xj+c)
(3)
多项式核函数:
K(xi,xj)=(γxi·xj+c)d(d≥1)
(4)
径向基核函数:
K(xi,xj)=exp(-γ|xi-xj|2)
(5)
2.2.2 过程构建
支持向量机数据集的划分(包括DT、DV和DP),同随机森林一样。构建支持向量机模型,可先从线性分类器开始,再转入非线性分类器。对于线性分类器来说,只需要选取最优c值,使误分率达到最小。对于不同的非线性分类器,需要调试多项式的阶(degree)、核系数(c0)及γ等多个参数,使其误分率达到最小。其中γ过小,分类器就不能很好地处理决策边界复杂性问题,但若γ过大,则会出现过拟合。将构建的分类器,应用于验证集进行性能测试,选取最合理的参数,构建分类预测模型。
2.3 模型性能度量
数据结构的复杂性和模型构建的随机性,都影响着所构建模型的拟合效果。多使用一个特征,在减少SSE的同时,会相应增加R的平方。对于模型的拟合度和可解释性,应采用多种方式相结合去评估。
随机森林和支持向量机,均可通过分析混淆矩阵来评估其分类预测性能。混淆矩阵是一个误差矩阵(图4),它可对分类结果进行观测类和预测类的交叉可视化描述(Loomis,1982)。在混淆矩阵中,真阳性(TP)和真阴性(TN)表示预测分类判断正确,假阳性(FP)和假阴性(FN)则表示预测分类判断错误(Marom et al.,2010)。

图4 二分类的混淆矩阵Fig.4 Binary confusion matrix
通过混淆矩阵,可以计算出下列指标:
灵敏度(TPR):
(6)
特异度(TNR):
(7)
准确率(A):
(8)
误分率(CE):
(9)
其中TPR和TNR是一个此消彼长的关系。通过设定一系列预测结果阈值,可得到一系列相应的TPR和TNR。以TPR为纵轴,1-TNR为横轴,可绘制受试者工作特征曲线(ROC,Provost et al., 1997)。ROC曲线下方面积(AUC),即ROC曲线与X、Y轴所围绕的面积,可用来表征分类器预测精度,其值在0.5和1之间。AUC越接近于1,说明分类器诊断效果越好(Delong et al.,1988)。
Kappa系数常用来判断不同模型在预测结果上是否具有一致性,是一种重要的基于混淆矩阵的分类精度评价指标(Eugenio et al.,2004)。Kappa系数取值区间为[-1,1],当Kappa>0时,说明该模型分类是有意义的,且分类可信度跟其值大小成正比,Kappa=1,说明判断结果完全一致;当Kappa=0时,即一致性与偶然性相同,说明该模型的分类判断具有偶然性;当Kappa<0时,说明该模型分类在实际运用中没有意义。
预测效率曲线图(PEC),也是度量模型预测性能的一个重要指标。PEC曲线,其横轴是预测数据集(Dp)的累计百分比,纵轴是事件发生的累计百分比(Fabbri et al.,2008)。在同样的数据范围内,预测到已发生事件比例高的模型,其预测性能就越好。
3 地质找矿因子
3.1 研究区划分
F1是岳溪矿田主要的控矿因素,已发现的矿体主要赋存在F1以南板溪群五强溪组的砂岩中。开展的地质调查与资源勘查工作也集中在该地段内。因此,本次工作将矿田内F1断裂以南作为研究区,其范围及地表高程模型如图5所示。考虑到研究区范围大小和所获取数据的密度结构,利用特定尺寸(20 m×20 m),对研究区进行网格划分。每个网格将包含目标变量(矿化发生与否)及其相应的特征变量(地质找矿因子)属性,将包含矿化的网格选定为正样本,随机选定同等数量不包含矿化发生的网格作为负样本,共同构成样本集。
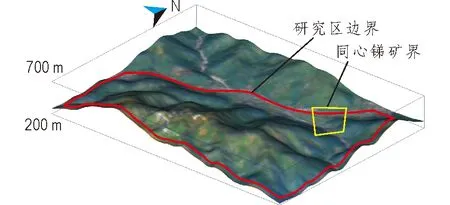
图5 岳溪矿田的数字地形模型Fig.5 Digital terrain model of the Yuexi orefield
3.2 特征变量
3.2.1 化探数据
该矿田所实施的化探工程网度为20 m×100 m,分析了地表Sb、As、Hg、Ni、Pb、W、Zn、Cu、Ag和Au等10种元素的含量(图6)。本次工作在剔除了民采、水流冲刷等干扰因素异常值的基础上,对各个元素的含量进行统计分析,计算其变异函数,得到变程、块金效应及基台等参数,然后根据相关地质要素的产状,通过ArcGIS软件开展了基于球状模型的克里金(Krige,1951)插值处理(搜索半径为150 m),以保证研究区每个网格单元里均有数据。

图6 岳溪矿田化探元素含量图示Fig.6 Representation of element content from geochemical exploration in the Yuexi orefield
3.2.2 遥感矿化蚀变信息
从地理空间数据云(www.gscloud.cn)下载的Landsat8-OLI遥感影像数据,包含了地表(或近地表)物体丰富的空间信息。根据遥感技术工作原理和地质异常成矿理论得知,与成矿预测有关的地质信息(成矿、控矿因子和找矿指示标志等)会在遥感影像上表现为“异常”;不同的矿化蚀变信息具有不同的反射、辐射电磁波特性,在遥感影像上表现为不同的反射波谱曲线(吴志春等,2010;秦耀祖,2011;赵志芳等,2014)。硅化、黄铁矿化、绢云母化、白云石化和绿泥石化等围岩蚀变信息,或多或少会以铁染和羟基蚀变的形式在相应的OLI影像波段上显示出反射和吸收的特征现象:铁染异常在波段Band 2和Band 5上具有明显的吸收谷,在Band 4上反射率较高;羟基异常在Band 7上有较强的光谱吸收带,在Band 6反射率较高(马威等,2016);通过对不同波段组合进行主成分分析(Byrne,1980),可实现羟基及铁染蚀变信息提取。
由于岳溪矿田位于气候湿润的湘中西地区,植被覆盖率高,因此在ENVI(https://www. harrisgeospatial.com/Software-Technology/ENVI)平台上,通过计算大气阻力植被指数(Kaufman et al.,1992),选取适当分割阈值,对影像数据进行掩膜处理(马建文等,1994),以减少植被信息的干扰。本次工作分别选取B2、B4、B5和B6四个波段及B2、B5、B6和B7四个波段分别进行主成分分析,根据蚀变信息的吸收和反射特性分别将这两次主成分分析的PC3和PC4主分量,作为铁染和羟基蚀变信息,并用其PN值表征蚀变强度,如图7所示。
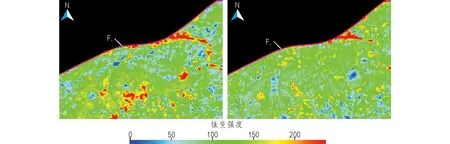
图7 铁染和羟基蚀变信息强度图示Fig.7 Representation of the ferric-alteration and hydroxyl-alteration information intensity in study area a.铁染蚀变;b.羟基蚀变
3.2.3 岳溪断裂缓冲区
岳溪矿田内矿体的形成和赋存空间,与到F1的距离关系密切。对F1和矿体开展基于距离缓冲区的空间相关性分析,有利于构建更为合理的找矿预测模型。因此,以F1所处的单元网格为中心,采用欧氏距离算法(李芳玉等,2005)计算研究区内每一个网格单元到F1的最短距离,构建的F1以南的缓冲区(即距离场),如图8所示。

图8 F1以南的缓冲区Fig.8 South buffer zone of the F1
4 找矿预测模型
4.1 分类模型
4.1.1 数据集划分
在构建基于机器学习算法(如RF和SVM)的分类与预测模型时,经过预处理的化探数据、遥感蚀变强度和F1缓冲区等三类地质找矿因子,无需确定阈值划分异常区,直接选区作为研究数据集D,数据结构包含:坐标信息(E和N)、F1缓冲区(Dist)、铁染蚀变(Fe-)、羟基蚀变(—OH)、10类化探元素含量数据(Sb、As、Hg、Ni、Pb、W、Zn、Cu、Ag和Au)和目标变量(记为Ore)。将矿化发生的数据单元(358)选定为正样本,矿化未发生的数据单元作为负样本,其中负样本最好是通过工程实施确定矿化未发生的数据单元,并且正负样本数量应大体一致(同为358个)。在R平台上,将样本集DS随机划分为训练集DT(约70%)和测试集DV(约30%)
4.1.2 构建参数优化
依次选取1至13个特征变量,分别构建决策树,并计算其整体误差率。当变量个数为5时,误差率最小,约为0.032,故将用于判断树节点分裂的Mtry值确定为5(图9a)。将Ntree值初定为2 000,计算得出所构建的随机森林模型的袋外误差率为1.54%;从模型的稳定性图示可以看出(图9b),模型误差在Ntree为500以内均处于震荡状态;在此基础上,找出的最优树数量Ntree为113,重新生成随机森林模型,其袋外误差率被改善为0.96%。

图9 模型构建参数图示Fig.9 Diagram of model construction parametersa.模型整体误差率;b.模型稳定性
使用最优构建参数,分别构建了线性和非线性(引入Polynomial、Radial和Sigmoid三种核函数)向量机模型。通过分析其性能参数(表1)得知,基于Radial内核的向量机模型具有最优的分类性能,其准确率值为0.987,Kappa系数为0.973,均为最高。因此,笔者以γ=0.5、C0=0.1,构建了向量机个数为271的分类模型。

表1 支持向量机模型参数表Table 1 Construction and performance parameter of the SVM based models
4.1.3 模型性能评价
根据上述参数构建的基于随机森林和支持向量机的分类模型,对训练集和验证集进行分类的混淆矩阵如表2所示。随机森林模型对训练样本实现了完全正确的分类,且在验证集上获得了高达0.973的准确率和0.950的Kappa系数,说明其分类效果优良;支持向量机模型在训练集和验证集上均取得了极高的性能指标,而且其在验证集上的准确率和Kappa系数均高于随机森林模型,说明该模型具有良好和稳定的分类性能。通过绘制模型在测试集上的ROC曲线(图10),计算得出两个模型的AUC值均为0.998。这些参数一致表明,构建的两个模型均具有良好的分类性能。

表2 随机森林和支持向量机模型的混淆矩阵Table 2 Confusion matrix of the constructed RF and SVM based models

图10 模型在测试集上的ROC曲线Fig.10 ROC curve of the constructed model on the test-seta.随机森林模型;b.支持向量机模型
4.1.4 变量重要性评估
随机森林模型中影响矿化发生的自变量排序如图11所示,其MDA和MDG值所表现出的地质找矿因子对矿体定位所作的贡献基本一致。由此可分析得出:F1缓冲区和化探获取的As、Sb含量对找矿预测的重要性要远大于其他因子,与笔者在实际工作中的认知相符。从多光谱遥感影像中提取的铁染和羟基蚀变信息,与矿体定位的关联不大,原因可能有二个,一是该区植被覆盖强烈,无法提取真实的矿化蚀变信息,二是大规模民采导致矿渣废渣广泛分布,且经水系搬运和沉积,导致提取的蚀变信息成矿指示意义不大。
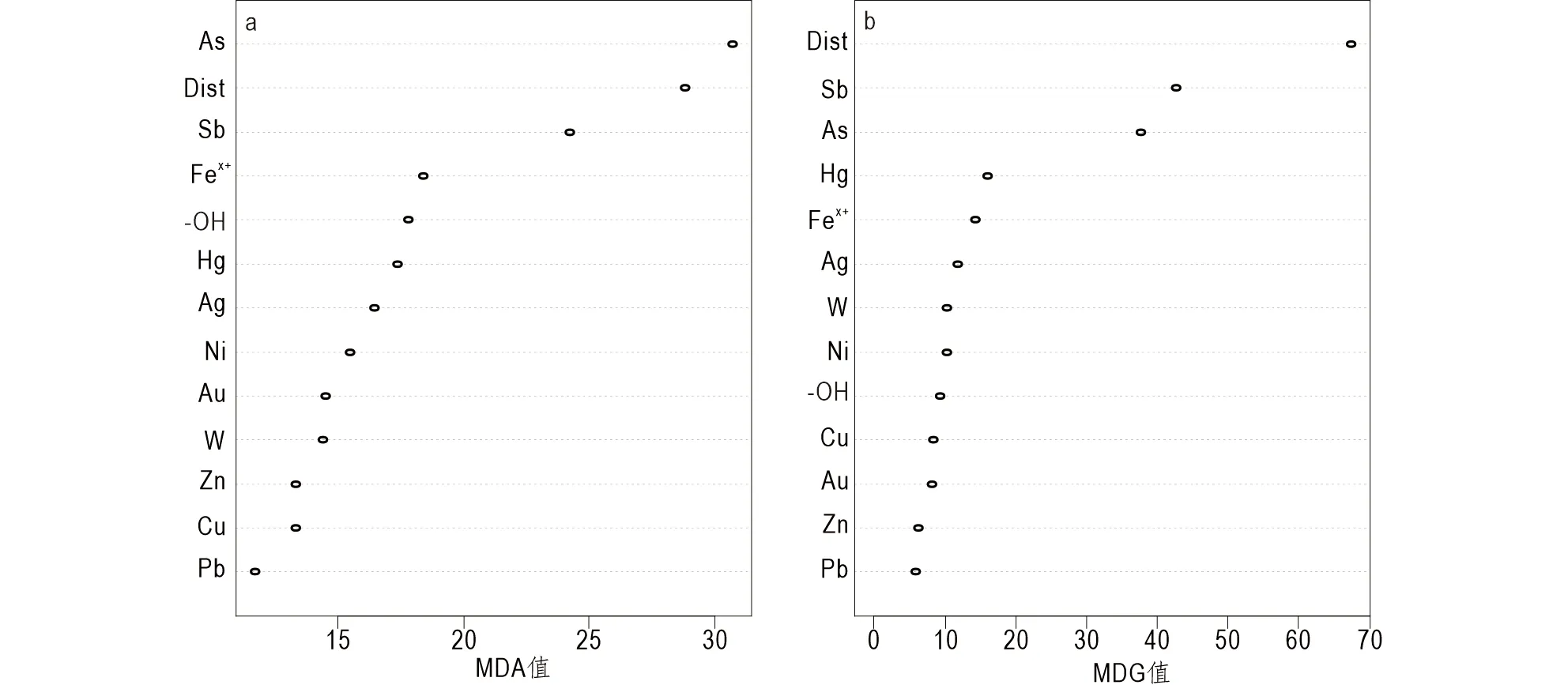
图11 随机森林模型中影响矿化发生的自变量排序Fig.11 Ranking of variable importance that associated with mineral occurrence by random forest
4.2 成矿潜力制图
4.2.1 成矿概率估算
将上述构建的随机森林和支持向量机模型,分别应用于DP中,对每一个数据单元格进行目标变量分类,并估算出正确分类的概率(即预测成矿概率),其中二者的分类精确度均很高,随机森林模型为0.918,支持向量机模型高达0.954。从基于这两个预测模型绘制的成矿概率图(图12)中可以看出,概率高值区位于F1大断裂附近及矿田东南部,已知矿床(体)均位于预测概率高值区。基于随机森林模型的预测概率高值区具有较好的分带性,而基于支持向量机模型的预测概率高值区仅位于已知矿床(体)所在区。由此可见,支持向量机模型虽然在训练集和测试集上表现出优良的分类性能,但其用于测试集后,预测功能很弱;通过调整核函数及构建参数,分类性能有所下降,预测功能也未能得到改善。

图12 岳溪矿田成矿预测概率图Fig.12 Metallogenic prediction probability map of Yuexi orefielda.随机森林模型;b.支持向量机模型
4.2.2 成矿潜力制图
鉴于上述研究,随机森林模型的预测概率被选择用于成矿潜力制图。按照概率从大到小的顺序,对研究区数据单元格进行排列,计算出含矿单元和预测单元的累计百分比,制作预测度曲线图(图13a)和预测概率曲线图(图13b)。在预测度曲线中,其拐点所对应的预测单元累计百分比为7.69%,包含着98.60%的含矿单元,在概率曲线上确定其所对应的概率为62.83%。由此概率阈值可将研究区划分为成矿高、低两个潜力区(图13b)。同时,从这两条曲线上也可以看出,支持向量机模型除了已知含矿单元外,几乎没有预测出潜力含矿单元。

图13 找矿预测模型的预测度曲线图(a)和预测概率曲线图(b)Fig.13 Prediction-rate curve(a) and prediction probability curve(b) of the mineral prospecting models
从成矿潜力图(图14)上可以看出,已知矿体基本赋存在所划分的高潜力区内;北部高潜力区靠近F1且走向与F1相近,呈跳跃式分布;南部高潜力区位于矿田东南部,呈近EW向。
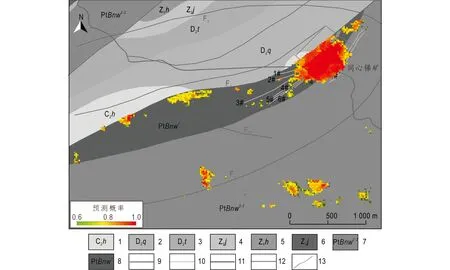
图14 岳溪矿田成矿潜力图Fig.14 Mineral prospectivity map of the Yuexi orefield1.石炭系中统黄龙组浅灰色白云岩,底部紫红色砂岩等;2.泥盆系中统棋子桥组浅灰色生物碎屑灰岩,白云质灰岩;3.泥盆系中统跳马涧组浅紫红色陆源碎屑岩系;4.震旦系上统金家洞组浅灰色冰碛砾岩;5.震旦系下统洪江组黑色炭质板状页岩;6.震旦系下统江口组灰绿色纹带板岩;7.板溪群五强溪组中段灰白色巨厚层石英砂岩;8.板溪群五强溪组下段灰绿色石英砂岩夹板岩;9.同心锑矿矿区界限;10.次级破碎带;11.断层;12.河流;13.矿体或矿化区
由此可见,同心锑矿床深边部,依然是开展找矿工作的重点所在;同心锑矿床外围西南部,在3线施工的钻孔,已揭露到矿体,使该预测得到了验证;矿田东南部有很多民采老窿,本次工作也做出了高潜力预测。在后续勘查工作的部署上,可以优先考虑将预测高概率区作为找矿靶区,利用槽探和钻探工程进行揭露和控制,继而根据施工效果,可向其深边部拓展。
5 结论
(1)通过优化构建参数,基于随机森林和支持向量机的分类预测模型,在训练集、验证集上均表现出了优良的分类性能;支持向量机模型由于过度训练,存在着过拟合现象,即便在预测集上取得了极高的分类精度,但其预测功能欠佳。
(2)在所有的地质找矿因子中,构建的岳溪断裂以南的距离场、地球化学勘探取得的As、Sb含量,对矿体定位有较高的贡献;从Landsat8-OLI遥感影像中提取的铁染和羟基蚀变信息,与矿化发生的关联较弱,说明在该研究区,难以提取真正与矿化相关的蚀变信息。
(3)随机森林模型在预测集上取得了0.918的分类精度,以预测概率62.8%为阈值划分高、低潜力区,其中高潜力区占研究区的7.69%,包含着98.60%的含矿单元,预测效果优良;部分预测高潜力区已经得到了实际工程验证,因此下一步勘查工作可重点部署在本次研究所预测出的高潜力区。
致谢:感谢湖南金诺矿业有限公司和安化县同心锑业有限责任公司为本次研究安排实地调研事宜及提供相关材料和数据。
