服务于拼写检查的伪语料生成方法实现*
2021-03-24胡睿
胡睿
(北方工业大学信息学院,北京 100144)
0 引言
目前对于中文文本拼写检查的研究已经持续了相当一段时间。通过人工方法手动识别并纠正出版物中所有的拼写错误,往往效果并不理想,而这项工作本身也十分耗费精力[1-2]。随着深度学习领域的不断发展,越来越多的研究表明在某些事情上神经网络可以比人类做的更加出色。如何以较小代价训练语料库来支撑深度学习等先进的学习方法是急需解决的难题。
本文在前人工作的基础上,提出结合词的拼音混淆,与字的字形混淆,两种混淆方式的伪语料生成方法。该方法可以应用于任意句子级别的生语料库,并快速生成大量包含带有字和词级别拼写错误的伪语料。
1 主要方法
1.1 生成混淆项
本文研究自动构造伪语料库,将正常语料库中混杂按照一定方法生成的错误例子。预处理中将维基语料预处理为句子级别的语料库[3-4]。
过程中进行如下操作:进行繁体中文到简体中文的转换;规范标点、数字:将数字统一到半角,标点统一到全角;剔除包含日韩文字的句子,剔除外文占比过大的句子。提取语料库中所有单词和拼音对,整理为字典。
对于给定的任意两个拼音,计算二者的Levenshtein编辑距离,该距离越小则表示两个单词的相似度越高。对于给定拼音,遍历所有不同的拼音组合,两两计算编辑距离,随后将各编辑距离除以其中的最大值并用1 减去结果,将结果映射到区间[0,1]上,该值定义为拼音相似度。相似度越大,与原拼音越相似,值越接近1;相似度越小,与原拼音越不相似,值越接近0。随后按照相似度随机抽取备选拼音,该过程中相似度越大,被选取的概率越大。根据备选拼音找出所有可能的备选词,按均匀分布随机选一个作为混淆词。在语料足够大的情况下,可以平滑随机抽取混淆词带来的负面影响(例如拼音相似但字形相差甚远),如果生语料不够大,可以考虑在备选词中计算与源词的字形相似度,并以该相似度作为基准随机选取一个作为混淆词。
本文使用CHISE提供的基础字符集IDS,在计算距离之前,首先将IDS从序列转换为树。除了字符之外,每个节点还带有一个层级数字,该数字表征其所属节点对于字形的贡献级别。例如数字1表示该节点的内容直接决定字形,而数字2 表示该节点需要先构成一个字,以该字作为部分构成其他字,以此类推。考虑原子字形,即字符本身不可拆分(存在于叶子节点的字符),在解析成树时其单独地位于根节点,但并不属于任何表意文字描述符,没有字形结构,此时层级数字定义为0。
给定任意一个字符,遍历其他所有已知IDS的字符,两两计算树编辑距离,随后将各距离除以其中最大值,并以1减去结果,得到结果在区间[0,1],定义该值为字形相似度,字形相似度越接近1 表明该字与原字越像,相似度越接近0则表示该字越不像原字。按照相似度筛选后(剔除值小于给定阈值的结果)按照概率随机选取一个字作为混淆字,过程中相似度越大,被选中的概率就越大。
1.2 伪语料库生成
由于目前尚未有针对中文母语者录入文字时产生的错误的相关统计研究,因此下面所使用的参数全部是经验参数,需要根据模型的训练情况进行调整。首先定义三个比率:拼音变异率、字形变异率、字形相似度阈值。对于语料库中的句子处理如下:
(1)从语料库中取出一个尚未被处理过的句子。
(2)分词,遍历每一个单词,以拼音变异率为概率,根据拼音替换原单词为选出的混淆词,标记未替换的单词为O,替换的单词为W。
(3)按字遍历步骤2)的结果,每个字以字形变异率为概率,以字形相似度阈值为选择混淆字时的相似度阈值,根据对应的IDS替换原字为选出的混淆字,标记未替换字为原有词的标签,替换的字为W。
(4)将步骤3)的结果转换为BIO标记,即连续的W将第一个W 替换为B,随后的W 为I,单独的W 只替换为B。标记O 不变。
(5)回到步骤(1),直到所有句子被处理完。
处理结束后得到BIO标注的拼写错误对照语料,其中由标签B和I标注拼写有误的部分。
1.3 伪语料库效果展示
在两个变异率都为0.1、字形相似度阈值为0.45的条件下,有如下句子:
(1)所以武林盟主是典范楷模,沩天下江湖人索厄信服。
所以武林盟主是典范楷模,为天下江湖人所信服。
(2)男女刵刖均外西装夹呈。
男女制服均为西装夹克。
(3)即是奡偶5天工作,珻天最高巿时7小时。
即是每周5天工作,每天最高工时7小时。
(4)世民大悦,赐以小宴,引为右一府童军。
世民大悦,赐以曲宴,引为右一府统军。
上述各例从生成的语料库中随机选出,第一行为生成的伪语料,其中加粗字为混淆项,第二行是原始句子。通过上下参照可以看出随机产生的句子并不完美,但可以轻易的产生大量语料。
2 训练模型
2.1 模型概览
本文使用如下图1所示的神经网络结构图,以前述随机语料为例:
字符首先转换为词向量,经由一层双向长短期记忆网络(BiLSTM)之后传入循环注意力层(Recurrent Multi-Head Attention),原始句子在输入神经网络前需要先转换为数字形式的表示。
该词向量在百度百科、中文维基百科、人民日报、搜狗新闻、知乎问答等大量语料上,在字和词级别上使用负采样Skip-gram(SGNS)进行训练,每一个字向量或词向量的维度是300维。结果最终经过一个前向传播的多层感知机(MLP)输出为标签。
2.2 模型效果展示
在现实语料上表现如下(斜体加粗为模型标注出来的拼写错误):
(1)即是奡偶5天工作,珻天最高巿时7小时。
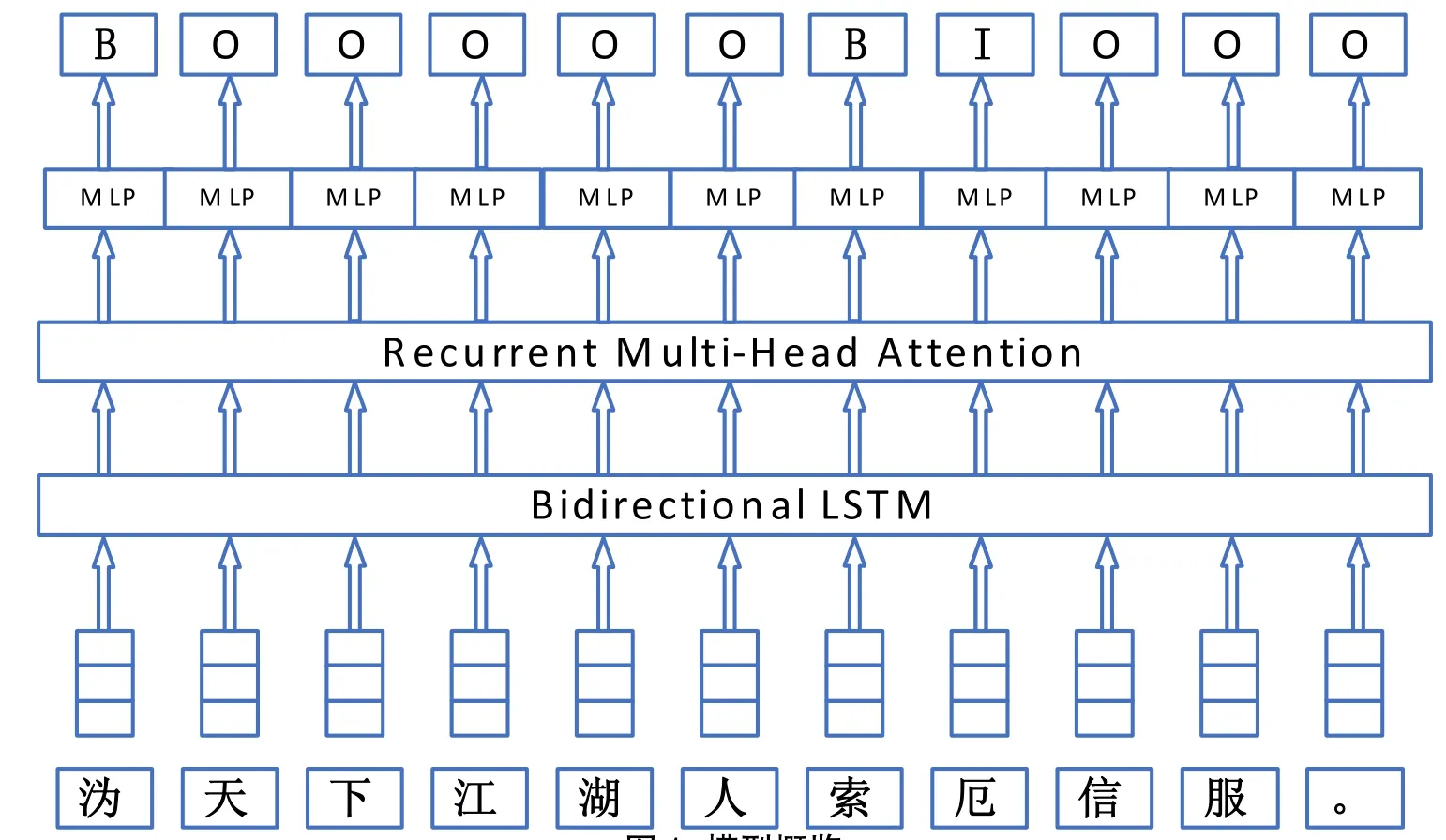
图1 模型概览Fig.1 Model Overview
(2)所以武林盟主是典范楷模,沩天下江湖人索厄信服。
(3)这是罕有中文拼写错误的一段文字。这句话中有中文措别字一个。
(4)次の曲が始まるのです
(5)其实答案很简单啊,因为我跟你做了同样的事情。
(6)修桥补路双瞎眼,杀人放火子孙多。
(7)天匠染青红,花腰呈袅娜。
3 结语
本文倾向于将模型解释为对语言模型的学习。通过对正常句子的加工,标注出其中故意引入错误的位置,在学习的过程中模型能够学习到哪些情况下句子的某个部分很奇怪,并对正常的句子建立一个模式。而诸如楷模、江湖人等词在维基语料中出现的比例不大,因而很容易被误判为错误句,而当句式符合训练语料的句式时(例如c句),模型能够较好的判定拼音混淆(含有-罕有)和字形混淆(错别字-措别字)。而一旦句式脱离了模型熟悉的陈述句(例如人物对话、俗语或古诗文),则误判较多。
