一种支持海量数据以图搜图的通用技术架构
2021-03-24姜光杰
姜光杰
(青岛海信网络科技股份有限公司,山东青岛 266071)
以图搜图就是通过搜索图像的矢量特征,通过输入目标图片及图片中目标的属性描述,搜索出与其相似的一组图片,为用户提供相关图形图像资料检索服务的专业搜索引擎系统。以图搜图主要包括了两个主要部分,一部分是AI图片特征提取,另一部分是图搜引擎[1]。后者主要实现了特征向量的存储以及比对搜索等功能。近几年的技术在目标检索方面,尤其是如何在海量底库的情况下实现高效快速的检索,依旧是个难题。
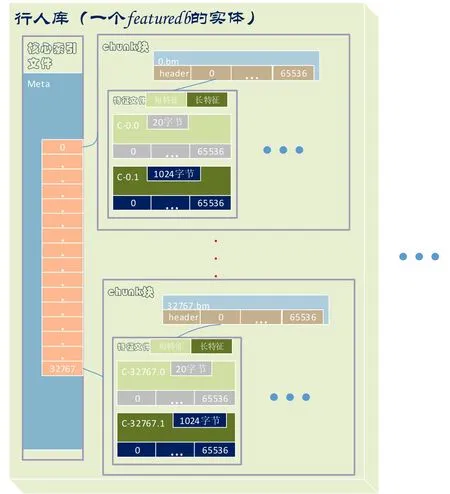
图1 featuredb 结构图Fig.1 Structure of featuredb
本文提出了一种分布式特征存储检索库featuredb,采用了基于LSM-Tree的结构,支持海量特征向量数据实时写入,并在此基础上构建了高效的特征索引。经过实际验证5亿图搜库1.2秒返回结果。下面从三个方面来介绍以图搜图通用架构。
1 向量特征存储及特征索引构建策略
Featuredb由三部分组成:meta主索引文件、chunk块索引文件(*.bm文件)、chunk存储块(C-*.0文件和C-*.1文件)。如图1所示,由于是顺序写入,一个特征chunk存储单元用完后,再顺序写入下一个chunk存储单元。因此整个架构是弹性伸缩的。
一个目标特征向量有一个唯一的索引号UID,UID的设计对应了两级索引,UID可以用公式表示为:
UID=cidx*65536+inner_idx
cidx表示chunk块索引,inner_idx表示chunk块内索引。
其中:cidx的范围[0,32767],inner_idx的范围[0,65535].
UID的范围[0,32767*65535=2,147,385,345],因此本特征索引设计规模支持单机存储特征向量可达2 1 亿规模。如果已知一个特征索引号UID,则cidx=UID/65536即UID高16位,inner_idx=UID% 65536,即UID低16位。
1.1 Meta主索引文件
主索引文件meta,采用bit-map映射,总长度为0x1018字节,其中文件头占0x18字节,文件体占0x1000字节,每个bit对应一个chunk块,bit值为0,表示其对应的chunk块不存在,bit值为1,表示对应的chunk块存在。整个meta文件可以用一个结构体core_meta_t描述出来。一个meta文件最多可以管理32768个chunk块。cidx就是该bit位在文件体中的偏移位置。
下面给出C++描述的meta文件结构如下:
struct bit_map_hdr
{
uint32_t scan_index_word;
uint32_t used_bits;
};
typedef struct{
int64_t _version_flag;
uint32_t next_alloc_chunk_id;
uint32_t _reserved;
bit_map_hdr _free_chk_hdr;
int64_t _freechkbs_data[512];
}core_meta_t;
_version_flag:占用8字节,固定内容:0x12366,主要用于校验库文件。
next_alloc_chunk_id:占用4个字节,表示下一个申请的chunk块号。通常用于遍历chunk块。例如:当前已经使用了10个chunk块,则next_alloc_chunk_id=11.
_reserved:目前未使用,暂时保留。占用4个字节。
_f re e_ch k_hd r:占用8 个字节。它是一个结构体bit_map_hdr,前面4个字节scan_index_word,是_freechkbs_data数组的索引,表示当前已经使用的chunk块簇的位置。used_bits:占用后面的4个字节。表示当前已经分配的chunk块数量。
_freechkbs_data:表示chunk块簇数组,数组总共包含了512个chunk块簇。其中,每个chunk块簇占用8个字节,包含64个bit,管理着64个chunk块,即每个chunk块占用1个bit位置。
1.2 ★.bm:二级索引文件,即chunk块内部索引
每个chunk块都有一个.bm索引文件,文件名是以cidx为名字,例如1.bm.
*.bm文件总长度为0x2010字节,其中文件头占0x10字节,文件体占0x2000字节。采用bit-map映射,文件体每个bit表示一个特征向量的状态,用一个c++结构体完整表示为:
struct bit_map_hdr
{
uint32_t scan_index_word;
uint32_t used_bits;
};
typedef struct{
int64_t _ver_flag;
bit_map_hdr _record_bmhdr;
int64_t _recbm_data[1024];
}chk_meta_t;
_ver_flag:占用8个字节,固定内容0x3001。用于校验chunk文件真伪。
_record_bmhdr:它对应一个结构体bit_map_hdr,结构内开头4个字节是scan_index_word,表示_recbm_data数组的索引,表示已经使用到的特征簇的位置。后面的4 个字节是used_bits,用于表示本chunk块中已经存储的特征向量数。
_recbm_data:特征簇数组,每个特征簇占用8个字节,总共1024个特征簇。
一个特征簇管理着6 4 个特征向量,即8 个字节的特征簇,总共包含64bit,每个bit对应一个特征向量。比特值为1,表示该位置存储了特征向量,比特值为0,表示该位置没有存储特征向量。1个bm 文件可以管理65535个特征向量。
1.3 特征存储文件C-★.0, C-★.1
每个chunk块都有一个C-*.0和C-*.1特征存储文件,文件名是以cidx为名字。
本文设计的深度学习特征模型,特征提取后包括两种特征,长特征是256个float,占用1024字节。短特征是256个bit,占用32个字节。由于这部分不在本文论述范围,读者可以根据自身应用场景需要,选择决定自己特征模型输出的长短特征向量。
C-*.0文件:短特征文件,步长为32字节,文件名是以UID的高16位cidx为文件名。例如:0号chunk块的短特征,存储于C-0.0文件,1号chunk块的短特征,存储于C-1.0文件,由于特征的长度固定,通过特征向量的UID,可以很方便的存取特征向量。
每个文件存储65536个特征,每个特征长度32字节,因此C-0.0文件长度为0x 200000字节。0.2M大小。
C-*.1文件:长特征文件,步长为1024字节,文件名是以UID的高16位cidx为文件名。例如:0号chunk块的长特征,存储于C-0.1文件,1号chunk块的长特征,存储于C-1.1文件。由于每个文件存储65536个特征向量,因此,C-0.1文件长度为0x400*65536=0x4000000字节。4M大小。
由于本文特征向量索引UID的设计非常灵活,使得根据UID读取特征向量可以在o(1)时间内完成。根据UID取高16位,就是对应的chunk索引文件及chunk特征文件的名字,特征在chunk块中的偏移值就是UID的低16位。
特征入库时,步骤如下:
(1)在meta文件找到文件体内最后出现的bit值为1的块,找出块对应的b m 文件,在b m 文件文件体内从后往前找最后出现的bit值为0的位置,如果已经满了,就在meta文件中选择bit值为0的块,创建一个新的chunk块,返回bm文件最先bit为0的位置,这个就是新申请的UID。
(2)UID申请到,将两级索引文件对应的bit位设置为1。
(3)将短特征向量写入到C-cidx.0内存文件中偏移32*UID低16位位置。
(4)将长特征向量写入到C-cidx.1内存文件中偏移1024*UID低16位位置。
由于所有的chunk特征向量文件都通过内存映像到内存中,因此可以实时序列化到文件中。
2 向量特征检索策略
本文自主设计了基于openMP的多线程任务调度及并行处理模式,如图2所示,步骤如下:
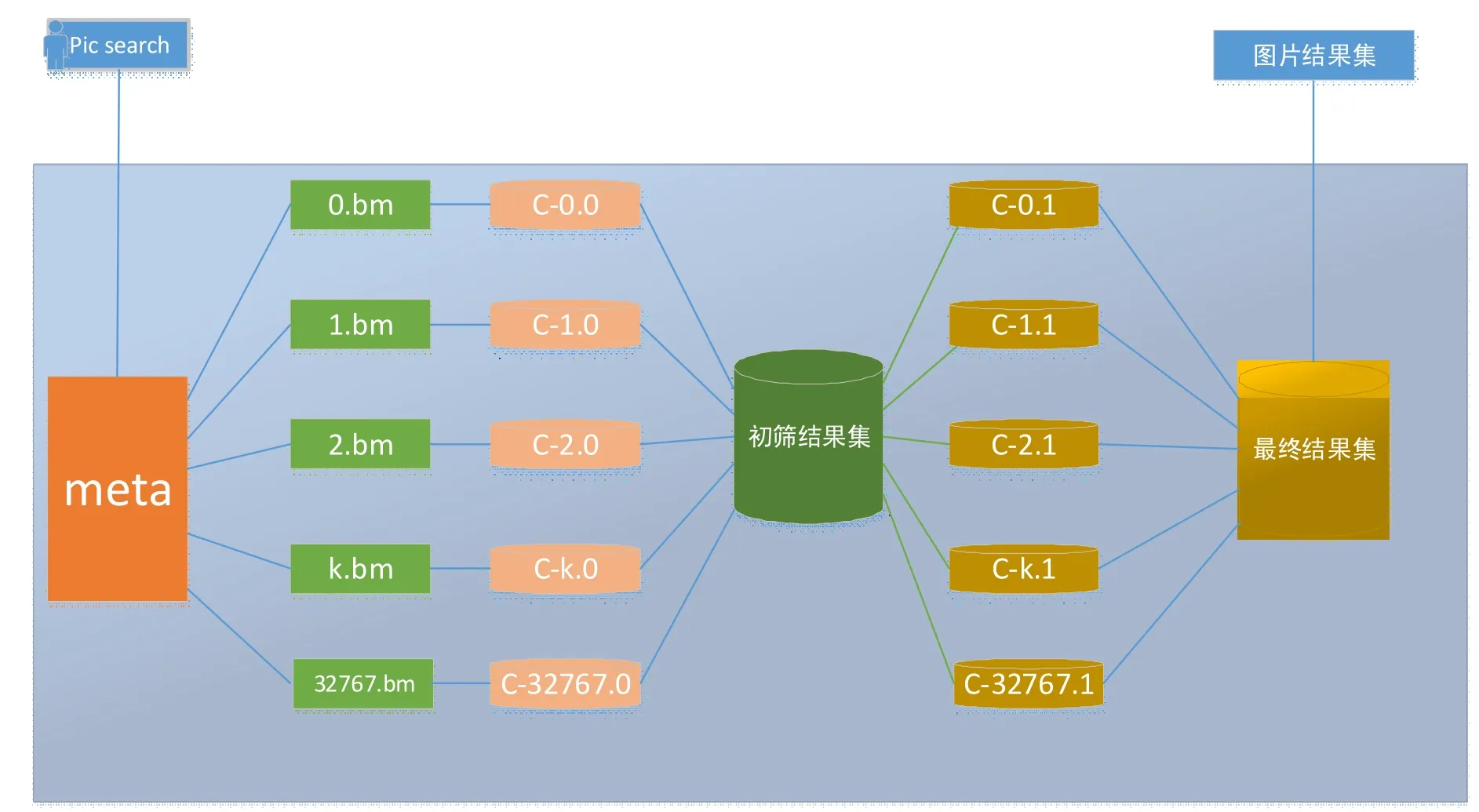
图2 特征检索Fig.2 Feature retrieval

图3 带属性的以图搜图检索Fig.3 Graph search with attributes
(1)遍历featuredb库,分组并行处理将每个chunk块存储的图片短特征与目标图片短特征进行汉明距离比对,根据相似度,筛选出最相似的前2000个结果集。
(2)在第一次初筛的基础上,分组并行处理将初筛结果集分布在每个chunk块中存储的图片长特征与目标图片进行余弦夹角的计算,筛选出最相似的400张图片作为结果集返回给用户。
3 带目标属性值过滤的以图搜图策略
为了支持带目标属性值的以图搜图,本文设计了采用clickhouse列式数据库存储目标的结构化属性值,用UID作为key值字段,Clickhouse支持sql语句,可以根据目标属性值完成快速属性过滤,返回对应的UID列集合。同时为了以图搜图输出结果中包含目标的结构化属性值,特别的设计了使用内存数据库rocksdb用于在featherdb检索返回的结果集中,补齐结果集中目标的结构化属性值[2]。
Rocksdb是一个高性能的key-value数据库,主要用于存储建库时表字段列表,用于用户需求字段筛选,以UID为key值,存储了特征向量对应的所有属性值,中间用逗号隔开。
以图搜图分为两种场景,一种是带目标属性值的图搜,一种是纯以图搜图。
带属性图搜步骤如图3 所示。步骤如下:
(1)Clickhouse主要用于属性值的过滤。根据want Param和whereStm以及dbname,完成属性值记录检索,返回UID列的结果集。
(2)Featuredb:根据clickhouse返回的UID列的结果集以及目标图片的长短特征,进行特征检索,完成特征比对score打分,同时根据返回记录数n的要求,根据score值排序,返回相似度最高的前n项。
(3)Rocksdb:获取featuredb返回的n条结果集,根据UID,取出存储的属性记录,同时根据wantParam和rocksdb存储的fieldlist,将客户感兴趣的字段值填充的返回结果集。
纯以图搜图则只需要执行前面的向量特征检索策略再加上步骤3即可。
4 总结
整套图搜架构,无论是列式存储还是kv存储,对库的选型方面,适应了海量数据存储及高可靠性、高并发的需求。同时满足了弹性可扩展,以及高性能索引和高性能存储。主要特点如下:
(1)featuredb架构灵活,UID线型索引方案,任意access时间复杂度为O(1)。
(2)基于位图(bit-map)与分块(chunk)的索引组织与划分方案。极低的内存占用,高效磁盘同步机制,接近常数量级时间复杂度。
(3)采用了基于mmap的“磁盘-内存”数据映射方案,解决特征数据快速读写访问问题,实现极高效的内存-磁盘IO机制。
