基于深度卷积神经网络的图像目标检测算法现状研究综述
2021-03-24孟祥泽
孟祥泽
(吉林建筑大学电气与计算机学院,吉林长春 130118)
0 引言
图像目标检测是计算机视觉当中关键的研究领域,其中目标分类与目标定位是评判图像目标检测的重要标准。目前卷积神经网络(CNN)发展突飞猛进,成为当前图像分类的主流研究方法,C N N 通过多层神经网络提取出图像中大量特征信息,进行目标分类,具有极强的鲁棒性与泛化能力,对于多尺度多目标的检测具有重大意义。图像目标检测的研究热点也就在于, 如何使用更高效的C N N 对图像目标进行分类,如何在一张图片上快速准确的定位一个目标。
1 CNN简介
1.1 CNN基本网络结构
卷积神经网络(CNN)建立在认知机(Neocognitron)[1]基础上,把卷积运算和采样操作引入到人工神经网络,使提取出的特征具备一定的空间不变性。C N N 的核心设计思想包括以下几点[2,3]。
(1)局部连接。CNN具有很强的视觉局部性,即两像素点距离越近关联性越强,距离越远关联性就会越弱,CNN在对图像做处理时,只对局部邻域做稠密连接。(2)权重共享。C N N 采用卷积核做卷积处理,在局部连接中,每个神经元对应的卷积核参数相同。(3)多层卷积与池化。CNN通常由卷积层后面追加一个池化层,这种组合会重复多次,用以提取出图像的特征,通过边界扩充保证输入与输出的尺寸不发生变化进而还可以强化边缘特征。
1.2 CNN结构优化
为了提高网络精度前人学者进行大量研究以优化CNN,Lin等人[4]提出网中网(NIN)模型采用多层感知层(MLP)[5]代替传统CNN的卷积过程以提取图像当中高度抽象的特征。Zeiler等人[6]提出的反卷积神经网络模型,这是一种可视化的过程用来验证各层提取到的特征图,并在此基础上提高网络精度。Jaderberg等人[7]提出了空间变换网络(STN),能够自适应地将数据进行空间变换和对齐保持不变性,如今也有将卷积核参数放在神经网络当中一同训练得到一个提取特征能力更强大的卷积核。
Alexnet模型[8]在每一层卷积之后,都做了局部响应归一化(LRN),池化层采用最大池化法,使用ReLu激活函数来代替tanh函数,采用双GPU训练,引入Dropout随机失活[9]在训练阶段随机删除掉一些节点,减少神经元复杂的共同适应性,减缓了过拟合问题。
VGG模型[10]于2014年提出,其核心思想是利用较小的卷积核不断堆叠增加网络深度,以此提升整个网络架构性能。利用较小的卷积核代替更大的卷积核可以保证感受野范围不变的同时又减少了参数量,提高了训练速度[11]。
2014年出现了Inception系列,进一步使用更小的卷积核,更多的神经网络层,Inception-v1也就是GoogleNet通过引入Inception模块提取出不同尺寸的图像特征,并且为了防止深层而出现的梯度消失问题引入了SoftMax辅助分类网络[12]。
Google在GoogleNet的基础之上提出了BN-Inception[13]在每个卷积层后加入BN层(Batch Normalization),避免梯度消失问题。Inception-v3进一步将一个n*n的卷积核划分成了1*n和n*1的卷积核这种非对称的拆分方式,减少参数的数量,增加特征的多样性,进一步提高了分类精度。
以上的模型大多从增加神经网络的层数来提高精度,然而网络的层数并非越多越好,深度神经网络随着网络层数的增加会导致神经网络的退化,使误差非常大。为了解决网络退化问题,2015年何凯明等人提出了深度残差网络(ResNet)[14],解决了网络退化的问题,使得增加神经网络的层数已不是问题,现如今的C N N 也一直在更新但都是基于ResNet,ResNet的提出极大的提高了系统的准确率,是图像分类领域的重大突破。
2 基于CNN的目标检测算法
在使用C N N 解决给定图片只有单个物体时的分类问题可以发挥很好的效果,但是一张图片往往有很复杂的背景包含数十种物体,CNN难以有所成效。所以需要目标检测算法将图像中的物体检测出来在交给C N N 进行分类。现今而言, 目标检测算法大致可分为三类, 一阶段(one-stage)检测算法,二阶段(two-stage)检测算法,anchor-free检测算法。two-stage的检测过程分为两个步骤。首先由算法生成若干个候选框,再通过C N N 对候选框当中的物体进行分类。one-stage则是对目标的边界框和类别概率进行回归,相对来说精度有所损失,但速度较twostage模式的算法更快。
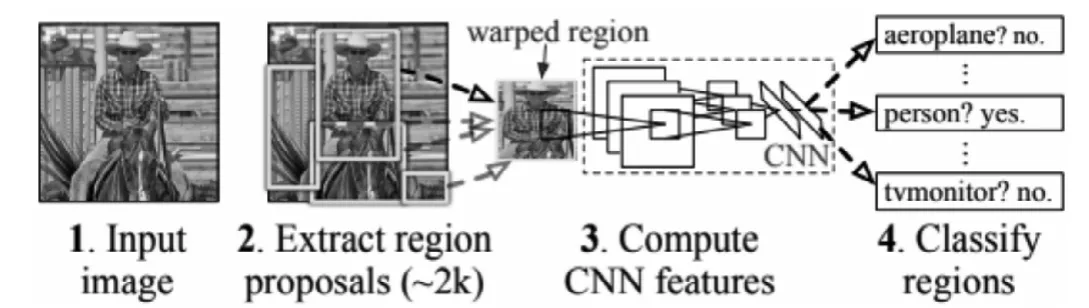
图1 R-CNN 流程图Fig.1 R-CNN flow chart
2.1 评价指标
首先介绍目标检测算法的评价指标:(1)IoU(交并比)指由目标检测算法产生的候选框与真正的标记框之间的重叠程度,也就是它们之间的交集和并集的比值,最理想的情况下IoU=1指完全重叠,通常而言IoU0.5认为定位比较准确。(2)mAP(mean Average Precession,平均精度均值)用来评价由目标检测算法对一张图片做出候选框的正确率。
2.2 two-stage检测算法
2014年Girshick等人[15]利用CNN提取图像特征替代传统的图像处理技术,并采用聚类搜索的Selective Search算法[16]代替滑动窗口提取候选区域,R-CNN处理流程比较复杂大概分成以下几步。(1)候选区域的提取,通过Selective Search从输入图像上提取2000个左右的候选区域。(2)特征提取,将所有区域裁剪或缩放到固定的227×227维度,利用C N N 提取特征,并输出到紧连的两个全连接层。(3)分类,使用SVM(Support Vector Machine,支持向量机)对特征进行分类,对于每一个类别都有一个SVM。(4)去掉冗余框,一个物体可能被多个不同的框选中,采用NMS(Non-Maximum Supression,非极大值抑制)[17]去掉冗余框。(5)边界框的回归,使用线性回归修正边界框的位置和大小,每一个边界框都要单独设置一个回归器,RC N N 算法流程如图1。
R-C N N 在图像目标检测领域取得了重大突破,但其仍存在缺点:输入图像经过剪裁和变形后会导致信息丢失和位置信息扭曲,从而影响了识别精度;由于R-N N 有大量的重复计算,需要对每张图片中的上千个变形后的区域反复调用C NN,计算非常耗时,速度较慢;S V M 更适用于小样本,在这个场景中效率准确率并不理想。
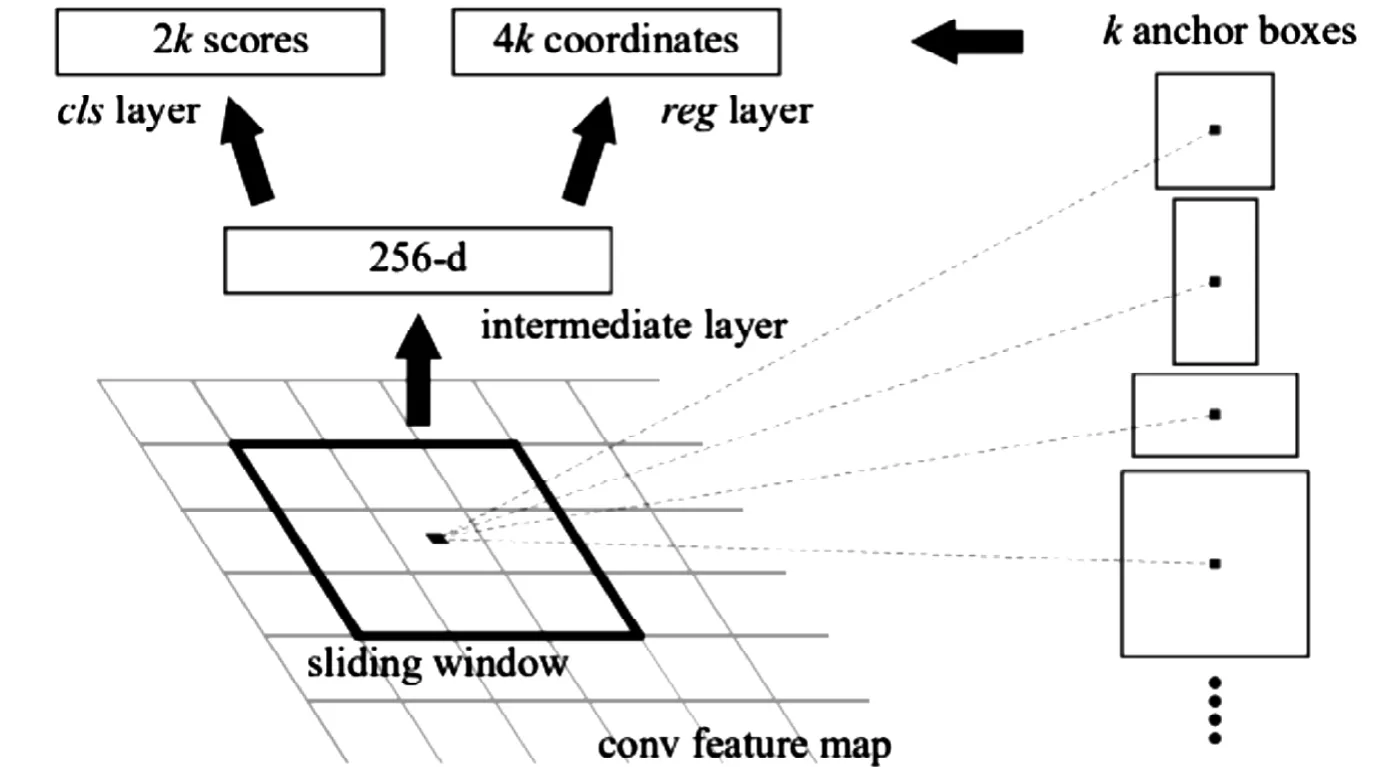
图2 RPN 结构Fig.2 RPN structure
基于R-CNN的问题Girshick等人又提出了Fast RCNN[18],相对于R-CNN主要进行了三方面改进。直接对原始图像做卷积操作,而不再是对每个候选区域都做一次卷积,减少了大量的重复计算;同时引入了ROI Pooling(Region of Interest Pooling,感兴趣区域池化),根据映射关系可以将不同尺寸的候选区域对应到固定尺寸的特征图,然后放入到全连接层中做处理;使用了SoftMax层代替了SVM进行分类。但是Fast R-CNN沿用此前的Selective Search的方法挑选候选区域,仍旧耗费时间,对于实时性要求很高的场景Fast R-CNN无法满足。
为了解决Fast R-CNN无法满足实时性要求的缺陷,也就在于如何更高效的生成候选区域,在2016年Ren等人[19]提出了Faster R-CNN,在原有的Fast R-CNN基础上结合了区域候选网络(Region Proposal Network,RPN)。R P N 通过共享卷积层特征。
RPN通过滑动窗口输出一个256维的向量,然后兵分两路做处理,一路走cls层,该层由一个1*1的卷积和一个SoftMax构成,用SoftMax来判断候选框是前景还是背景,另一路走reg层做边界框回归来调整边界框大小和位置,如此便可快速确定候选区域。在有了RPN之后,Faster RC N N 首先输入图片经过C N N 得到特征图,通过R P N 快速得到候选区域,在通过R O I 以及全连接输出最终分类结果。利用滑动窗口方法,采用锚框机制(anchor box)和边界框回归方法快速获得多尺度的候选区域RP N的结构如图2所示。
two-stage目标检测算法不断向前发展还出现了FPN[20],深层特征和浅层特征融合提升了检测小目标物体精度。Mask R-CNN[21]在Faster R-CNN基础上使用ROI Align替换ROI Pooling增加了目标掩膜输出支路进行像素级的预测,其在实例分割,关键点检测有很大应用。Cascade R-CNN[22]使用多个不同的IOU阈值,训练多个级联的检测器,其mAp达到了50.9%。TridentNet[23]利用空洞卷积构建的一个三分支网络,相比之前的算法如FPN,更好地解决了多尺度检测问题。
2.3 one-stage检测算法
为了使检测速度更快, 学者们提出了一阶段检测器,舍弃了二阶段检测器中的提取候选区域费时的步骤。其核心思想是将目标检测问题转换为回归问题求解,利用权重参数将分类和目标框的预测相关联,进行回归分析。
一阶段检测算法的先河之作就是YOLO(You Only Look Once)[24],主要思想就是把目标检测问题转换为直接边界框选取和类别概率的问题,省去了候选框的选取,YOLO的运行速度可以达到45f/s,真正实现了端到端的目标检测算法,可以满足实时性的要求。
2017年Redmon等人[25]提出了YOLOv2,大致做了以下几点改进:(1)对于每一个卷积层都使用了BN操作,舍弃Dropout操作,使模型收敛性显著提高。(2)采用锚框来预测边界框。(3)使用Darknet-19(19个卷积层和5个最大池化层构成)作为YOLOv2主干网络并用用1*1卷积替换YOLO中的全连接层。
2018年Redmon等人[26]又提出了YOLOv3,大致做了以下几点改进:(1)参考FPN采用了3个不同尺度的特征图进行目标检测。(2)使用Darknet-53(借鉴ResNet设计,精度与ResNet-101相当)作为YOLOv2主干网络。(3)使用多标签分类器代替SoftMax进行分类。(4)改进YOLO的损失函数,采用了二元交叉熵作为损失函数进行训练,实现了对同一个边界框进行多个类别的预测。
2020年Bochkovskiy等人[27]提出了YOLOv4使用CSPDarknet53作为主干网络,通过引入Mosaic数据增强方法与使用GA算法选择最优超参数,并且使用PANet网络代替FPN,提高小目标检测物体的检测效果。YOLOv4其在COCO数据集上的检测精度达到了43.5%。
2.4 anchor-free检测算法
无论是one-stage还是two-stage都采用锚框机制,生成的锚框较多而目标物体却很少。就会造成正负锚框失衡,增加训练时间。锚框的使用会引入了很多超参数,当与多尺度目标检测结合使用时会变得更加复杂。自CornerNet开始,目标检测已迈入anchor-free时代。
2019年提出CenterNet[28],该算法首先通过全卷积神经网络得到热点图找到目标中心点,再基于目标中心点回归得到目标尺寸、3D坐标方向、姿态信息等。该算法通过三个网络(Rsenet-18、DLA-34、Hourglass-104)来输出预测值,整个过程舍弃了锚框机制,NMS操作,大大减少了网络的计算量和训练时间。同年提出一种基于全卷积神经网络的逐像素目标检测算法FCOS[29],与基于锚框的算法不同的是其直接对特征图的每个位置与原图边框进行回归。为了提高检测精度,引入center-ness(中心度) 用于降低检测效果不理想的目标框权重, 通过N M S 确定最终检测结果。在检测时由于目标真实框重叠,可能会出现的语义模糊情况,FCOS采用多级预测方法解决语义模糊问题。同样不引入锚框机制,节省了大量时间。
2.5 CBNet目标检测
在2019年9月,北京大学和纽约州立大学石溪分校的研究者提出CBNet(Composite Backbone Network)[30],其思想就是通过多个相同且彼此相邻的主干网络(backbone)相互连接构成的一个性能更优的主干网络来对特征图进行目标检测。这种集成的主干网络的初始化仅需要单个主干网络的预训练即可完成,而单个主干网络的预训练如Re sNe t等早已研究透彻。对于前述的各种目标检测算法在使用C B N e t 后在C O C O 数据集上m A P 提升大概1.5%~3%,截止到2020年基于CBNet改进后的Cascade Mask R-CNN算法已是最优。
3 结论
本文首先简单介绍在C N N 发展历程当中具有里程碑意义的AlexNet,VGG,Inception,Resnet等网络结构。随后从候选框提取,回归,anchor-free三个方面综述目前基于C N N 的目标检测算法,最后简单介绍了逐渐火热起来的CBNet模型,可以看到图像目标检测在未来仍然具有很大的发展潜力和提升空间。
CNN在训练时需要占用大量的内存,耗费大量时间,随着移动互联网技术的不断发展,用户对便携性设备的需求量增加单独使用某种CN N网络结构进行分类时可能会存在一定的局限性。为了提高目标检测在特殊环境下的识别率,如在目标与背景颜色一致,多个目标又重叠在一起,要识别的目标被严重遮挡等极端情况下,可将不同的卷积神经网络技术相结合,充分利用各自的优点,同时针对不同物体的特殊结构设计相应的神经网络,来提高极端情况下的目标检测精度。
