基于YOLOv3 改进的交通标志识别算法*
2021-03-24徐迎春
徐迎春
(江海职业技术学院智能信息学院,江苏扬州 225001)
0 引言
交通标志识别在无人驾驶和驾驶辅助领域有着重要的应用,它为车辆提供准确的交通标志信息。该任务实质是计算机视觉中的实时目标检测。传统的目标检测算法是用SIFT(Scale-Invariant Feature Transform,尺度不变特征变换)和HOG(Histogram of Oriented Gradient,方向梯度直方图)对图像进行特征提取,最后使用SVM、Adaboost等分类器进行分类[1]。这些传统操作在速度和准确性方面很难达到满意的效果。近年来,基于卷积神经网络的深度学习算法[2]在计算机视觉目标检测中取得了很大的成功。其检测算法大致可以分为两大类:基于区域生成的二阶段目标检测算法:如R-CN N[3]系列。基于回归的单阶段目标检测算法:如YOLO系列、SSD、Retina-Net。对于交通标志识别,在实际应用中快速准确地检测非常重要,单阶段检测算法比二阶段算法更能满足实时的需求。YOLOv3[4]模型是一个精度与速度性价比很高的算法,然而深度学习算法的检测准确率仍有很大地提升空间。本文对YOLOv3算法进行改进,用于道路场景下的4种主要的交通标志识别。
1 YOLOv3目标检测原理
YOLO(you only look once) 模型把目标检测当做单一的回归任务,将图像划分为S×S网格,物体bbox(边界框)中心落到哪个网格上就由该网格对应的锚框负责检测该物体。YOLOv3模型在满足精度要求的情况下能实时检测,在工业界实际项目中大量应用。
1.1 YOLOv3网络结构
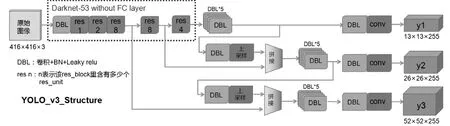
图1 YOLOv3 网络结构图Fig.1 Network structure of YOLOv3
YOLOv 3 结合了残差网络、特征金字塔以及多特征融合网络等优秀的方法,具备较好的识别速度和检测精度[5]。网络结构如图1[6]所示。
骨干网络采用全卷积网络Darknet-53,主要由卷积层、Batch Normalization(批标准化)及跃层连接组成,激活函数采用Leaky Relu[7]。输入图像(416×416×3)经过5个阶段,每个阶段进行2倍下采样。在第5个阶段得到32倍下采样,第4阶段16倍下采样、第3阶段8倍下采样。32倍下采样经过做一系列的卷积得到y1特征图,同时把32倍下采样,再经过2 倍的上采样得到和1 6 倍下采样相同的宽(w)、高(h),然后在C通道上张量拼接,再经过卷积得到y2特征图,同理得到y3特征图。这就实现了多尺度预测,同时还进行跨尺度融合。
1.2 锚框
锚框是先验框,在数据集上聚类生成的,能使模型收敛更快,效果更好。YOLOv3中作者在COCO数据集上设置了9种(3×3)的锚框尺寸,应用在不同的特征图上,每个特征图上3个锚框。
1.3 边界框
锚框的尺寸是[pw,ph],起始点在对应网格的左上角,YO LO v3 直接预测出边界框中心点相对于网格单元左上角的相对坐标和大小[tx,ty,tw,th]。边界框的中心点、大小在锚框的基础上通过“微调”得到,即[tx,ty,tw,th]→[bx,by,bw,bh],推导公式如图2。

图2 预测框位置和大小计算Fig.2 Prediction box position and size calculation
预测框的中心点移动上用了Sigmoid激活函数,Sigmoid函数取值在(0,1)之间,保证中心点不会偏出网格;在宽、高缩放上用EXP函数,函数值在(0,+∞),保证缩放不会出现负数。
1.4 YOLOv3模型的输入输出
根据YOLOv3 的网络结构和预测框的信息, 得出YOLOv3的输入为[N,3,416,416],N为Batch Size一次输入的图像数,经过特征提取得到三个输出分支13×13,26×26,52×52三个尺度的特征图,每个输出分支上3个锚框,每个锚框对应预测框有85个信息。85=4坐标+1目标概率+80分类,255=85×3锚框,(COCO数据集上有80个分类)最后网络的输出是[[N,255,13,13][N,255,26,26][N,255,52,52]]。
1.5 损失函数计算
在目标检测任务里,有几个关键信息是需要确定的:(x,y,w,h),confidence,class。根据关键信息的特点,损失函数应该由目标框位置损失、目标置信度损失、类别损失组成[8]。在YOLOv3的论文里虽然没有明确列出所用的损失函数,但可以从代码分析出它的损失函数公式(1):
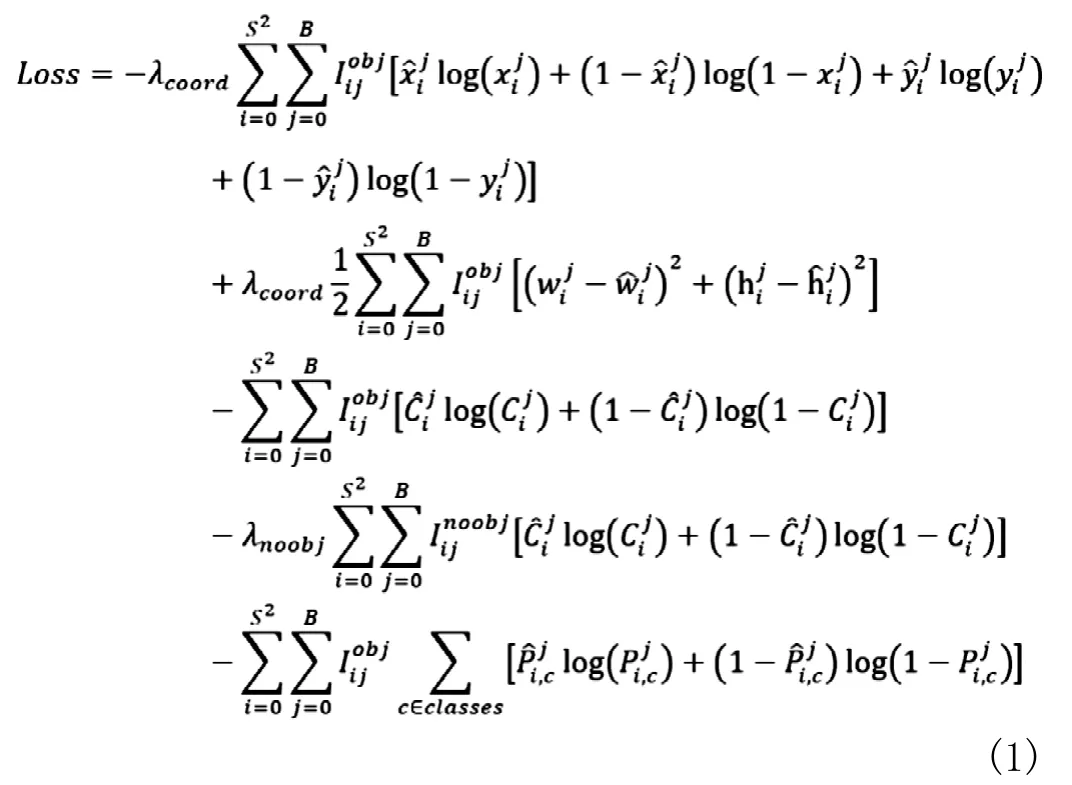
YOLOv3损失函数中w,h依然采用总平方误差,其他部分的损失函数改为采用二值交叉熵。λcoord表示中心坐标误差的权重;S表示图像的网格数;B表示每个网格所预测的框的个数;Iijobj表示第i个网格的第j个预测框是否检测到了目标(1或0);λnoobj表示当预测框没有预测到目标时,其置信度误差在损失函数中所占权重[9]。表示预测框坐标。为预测框内含有目标物体的概率得分。表示第(i,j)预测框属于类别C的概率。( xi, yi, wij,是训练标记的值,表示真实目标框坐标、置信度和类别。
1.6 NMS后处理
NMS(non maximum suppression)非极大值抑制,是目标检测框架的后处理模块,用来删除检测器输出的冗余预测bbox。先对预测框进行评分,条件是有物体有对应类别,计算公式是Scorebbox=Scoreobject×Scoreclass,按类别进行分组,按Score进行排序,选取当前类别中Score最大的那一个,按x,y,w,h计算它与其余的bbox的IoU。IoU值大于我们设定的阈值的框舍去。IoU是两个区域的重叠部分(交集)除以两个区域的集合部分(并集)所得到的比值。
2 改进的YOLOv3算法
2.1 K-means算法聚类anchor尺寸

表1 实验数据集anchor 尺寸Tab.1 Anchor size of experimental data set
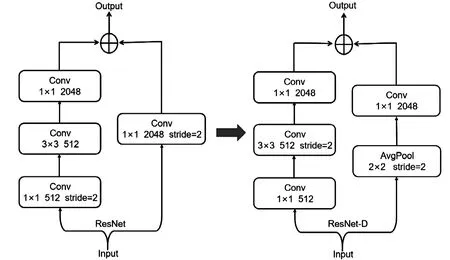
图3 ResNet 和ResNet-D 网络结构对照Fig.3 Comparison of RESNET and resnet-d network structures

表2 算法改进实验结果对照Tab.2 Comparison of experimental results of algorithm improvement
anchor值的大小对目标检测网络十分重要。合适的anchor值能加快网络的收敛速度,降低误差。本文中采用Kaggle数据集,为了提高本次实验检测的定位精度,需要使用K-means算法重新对anchor值进行更新。更新后的anchor尺寸如表1所示。
2.2 Image Mixup数据增广
训练深度卷积神经网络时,网络的规模受限于样本的数量,而训练样本的多样性又直接关系到深度卷积神经网络的识别能力。本文在构建虚拟样本时采用了I mage Mixup方法,将2张图像合并,增加样本多样性,提高模型抗空间扰动的能力,对样本泛化能力有着明显的提升作用。
2.3 骨干网络ResNet50-D
ResNet50模型在计算机视觉中广泛运用,它提出后许多研究者对它进行了一系列的改进,依次提出了B、C、D三种改进结构。原始ResNet50每个阶段的下采样block会丢失3/4的信息。本文将骨干网络改为ResNet50-D。如图3,左边分支将stride=2从1×1的卷积核上调整到3×3上;右边分支将原来1×1 stride=2的卷积改为先2×2 stride=2的平均池化,然后接1×1 stride=1的卷积,进行全量信息计算,增强特征提取能力。
3 实验与分析
3.1 数据集
本文使用Kaggle数据集road-sign-detection 比赛数据。划分成训练集和测试集,总共877张图,其中训练集701张图、测试集176张图。4个类别:speedlimit、crosswalk、trafficlight、stop。VOC数据格式是指每个图像文件对应一个同名的xml文件,xml文件中标记物体框的坐标和类别等信息。
3.2 评测指标
本文采用平均精度均值(Average Precision,mAP)和FPS两个指标对算法模型进行评估。mAP指标通过首先计算每个类别的平均精度(Average Precision,AP),再对所有类别的平均精度求取均值得到[10]。在验证集上采用mAP作为评价指标,数值越高模型效果越好。FPS(Frames Per Second,FPS)是每秒处理帧数,用于评估一个检测器的实时性,是检测速度的直接体现。FPS值越大,说明检测器的实时性越好。

图4 trafficlight、stop 检测效果Fig.4 Detection effect of traffic light and stop
3.3 实验过程
为了验证提出的改进网络的有效性, 在百度的aistudio平台上完成所有与原算法的比较实验。该平台搭载有Intel Xeon@2.60 GHz 4 Cores的处理器,内存32GB,图像处理单元(GPU)采用NVIDIA Tesla V100显卡,显存16 GB大小,操作系统为Ubuntu5.4.0终端,深度学习框架为PaddlePaddle1.8.4。载入COCO上的预训练模型作迁移学习,[9]在训练阶段,初始学习率设置为0.0001,学习率调整倍数gamma设置为0.1,设定批处理参数Batch Size=8,最大迭代次数2000,每200次保存模型。
3.4 结果分析
为了验证改进之后网络模型检测的效果,先用原始YOLOv3模型检测,在本文数据集上mAP(IoU=0.5)精度为72.3;然后对数据集上anchor重新聚类,用新尺寸检测,模型的mAP值提升0.8%。采用了Image Mixup图像增广技术,模型精度有0.4%的小量提升。采用ResNet50-D作骨干网络,模型检测精度提升约1%。最后分别选取改进前和改进后网络训练得到的权重进行最终对比实验,改进后模型检测精度提升2.1%。实验对比见表2。
由此可以看出:这些技巧对模型精度提升有帮助。因为它们在训练过程中使用,且并没有引入额外计算量,所以预测速度几乎不变。由于深度学习模型的训练依赖大量数据,本数据集图片数量不多,所以预测精度还有待提升。
改进后的网络模型的检测效果如图4、图5[10],模型能准确识别标志。

图5 speedlimit、crosswalk 检测效果Fig.5 Detection effect of speedlimit and crosswalk
4 总结
本文提出了一种基于YOLOv3改进的目标检测算法,在交通标志识别任务中取得较好的效果,能够准确快速地检测出四种交通标志。交通标志识别易受到光照环境,遮挡、重叠,大、小目标等多因素影响,算法还需继续优化,从而满足实际需要。
