图像风格迁移技术概况及研究现状
2021-03-24苗序娟余浩王露郭瑞佳杨天辉牛本杰
苗序娟,余浩,王露,郭瑞佳,杨天辉,牛本杰
(天津商业大学信息工程学院计算机系,天津300134)
早期的图像风格迁移技术算法适用风格范围窄,一个算法往往只能针对于一种图像纹理类型,而且迁移转换结果不理想,但随着近些年人工智能和深度学随习的兴起,赋予图像风格迁移技术新的生命力。基于深度学习的图像风格迁移技术的快速发展,使得该技术被广泛的应用于图片影像加工美化,最常见的就是根据真人照片生成卡通头像,深度神经网络特有的“学习”能力让图像风格迁移技术算法实现一个算法对应多个类型图像风格,迁移转换结果也能与原图像样本达到高度吻合,这使得图像风格迁移技术应用范围更加宽广,使用更加便捷高效。通过对图像风格迁移技术发展历程,以及卷积神经网络和对抗式生成神经网络的研究分析,了解并总结两种神经网络各自优缺点,对图像风格迁移这一研究领域的未来发展趋势做出合理推测。
图像风格迁移;深度学习;卷积神经网络;生成式对抗网络;VGG19;TensorFlow
0 引言
不同图像之所以带给人们不一样的感观,是因为图像的风格不同,特定的图像一般呈现出其专属的风格。通俗的讲,图像风格迁移是指利用计算机程序将图像A的风格特征提取出来,把该特征与图像B的内容相融合,最终得到一个全新的、拥有A的风格和B的内容的图像C,它是一项将某一图像的风格应用到另一图像内容上的技术。目前大部分热门的图像处理软件产品中都有图像风格迁移技术的应用,它能让用户更加方便快捷地得到自己想要的图像效果。
传统的图像风格迁移方法主要是采用对图像纹理和笔触建模的方式,通过所建的模型来表示一种风格的特征,以此来达到风格迁移的效果。传统方法中需要给特定图像风格建立唯一的数学模型,建模困难且费时费力,在应用上有很大的局限性,改变这种现状的是基于神经网络的图像风格迁移的思路的产生。在深度学习广受欢迎时,不断涌现出各种不同的图像风格迁移算法,如选用VGG19训练模型+TensorFlow深度学习框架进行图像风格迁移的算法[1];还有针对传统算法风格迁移后图像表现不自然的问题,基于Gram矩阵和卷积神经网络的图像风格迁移算法[2]等。
本文将从图像风格迁移技术的变迁历程,以及卷积神经网络等方面来阐述图像风格迁移技术的研究状况和相关理论,最后给出总结及应用前景。
1 图像风格技术的变迁
1.1 最初的图像风格迁移技术
图像风格迁移技术大概是在20世纪末出现的,主要通过图像纹理生成技术来实现风格的迁移。有关图像纹理的研究都需要研究人员手动建立模型,其中的核心思想就是通过对图像局部特征的统计来生成纹理,没有这个前提模型根本无法建立,而且一个模型只能做一种风格或场景。另外,当时计算机计算能力也不强,所以图像风格迁移技术发展十分缓慢。
1.2 图像风格迁移与深度学习
机器学习、深度学习、卷积神经网络三者之间的关系如图1所示。

图1 关系图
1997年,Mitchell教授在其著作Machine Learning中很专业地定义了机器学习:如果一个程序可以在任务T上,伴随着经验E的增加,效果P也会增加,那么这个程序就可以从经验中学习,称之为机器学习[3]。不过机器学习可以追溯到17世纪,贝叶斯、拉普拉斯关于最小二乘法的推导和马尔可夫链等奠定基础,到了1950年,图灵提议建立机器学习,再到后来深度学习的提出,使得机器学习有了很大的发展。
深度学习是机器学习一个新的研究方向,最初的深度学习受到了神经学科的启发,从生物神经网络中获得灵感,该方法具有提取抽象特征的能力。深度学习由Hinton等人在2006年提出后,在学术界等行业掀起了一波新的浪潮,人工智能度过了又一次寒冬,进入快速发展期,也开启了新的里程碑。
而卷积神经网络是深度学习的代表算法之一,尽管卷积神经网络在上世纪80年代到90年代就被提出,但是一直没有应用在图像风格迁移领域。
2012年,深度学习的潜力被证明,其在图像识别方面有着惊人的表现,到2015年Gatys等人提出了一种基于卷积神经网络的图像风格迁移算法,把图像的内容特征和风格特征进行分离,通过独立处理深层特征来实现风格迁移,这才将卷积神经网络和图像风格迁移连接了起来,极大地改变了图像风格迁移技术的旧状,使得该技术有了很大的发展。因此,2015年也被称为图像风格迁移技术的元年。
2 卷积神经网络
卷积神经网络的前身是Hubel和Wiesel记录特定模式下对猫的刺激形成的大脑反馈从而创建的视觉皮层地图。1980年Yann Lecun提出了LeNet-5[4]形成了当代卷积神经网络的雏形,基于LeNet-5模型,在科研人员的潜心研究下卷积神经网络有了更系统的定义和精准的结构。
卷积神经网络是一类仿造生物视知觉机制构建的包含卷积计算且具有深度结构的前馈神经网络(Feed⁃forward Neural Networks)[5],因为能够稳定学习数据被大范围应用于图像识别、行为认知、姿态估计和自然语言处理等领域。
2.1 基于卷积神经网络的图像风格迁移技术
风格迁移是卷积神经网络(CNN)面对计算机视觉领域的一项特殊应用,充分体现出了卷积神经网络表征学习的能力,能够学习特征并且学习提取特征的过程避免手动提取特征的麻烦。
CNN网络由多层神经网络构成,主要包含了输入层、卷积层、激励函数、池化层和全连接层。卷积层是CNN的重要组成部分,用于提取特征值。不同的卷积核可以提取不同的特征,低层的卷积层只能提取边缘、线条和角等低级特征,高层的网络能够利用低层特征获取更加复杂的特征。池化层是在卷积核进行特征提取后的一个下采样操作,主要用来进行特征降维,通过压缩数据和参数的数量的方式提高计算速度,能够控制过拟合、提高网络的鲁棒性[6]。
基于已发布的结构模型,2015年Gatys等人[7]在纹理合成的基础上通过引入目标内容图像,修改了损失函数使算法同时针对风格和内容进行优化[8],将任意一张图像内容与《神奈川冲浪里》、《星空》、《呐喊》中的风格结合在一起形成具有艺术风格特色的图像,如图2所示。

图2 Gatys等人生成艺术风格图像
Gatys等人提出的Neural Style方法,模拟了人类视觉的处理方式,经过训练多层卷积神经网络[9],使计算机辨别并学会艺术风格。但是从生成图像中可以明显看出部分图像内容扭曲、细节丢失的问题,并且训练的卷积网络的时间耗费长,迁移程度不能控制。
随后,Gatys等人又对自己的方法进行了改进,加强了风格迁移中对细节的控制,但是仍对图像内容没有把控。在此之后,Johnson等人提出Fast Neural Style的方法[10]改善了原始风格迁移训练耗时长的缺陷,每训练好一个风格模型之后,GPU通常只需要运行几秒便生成对应的风格迁移结果,但生成图像效果仍没有得到改进。Luan等人[11]在Gatys的工作基础上加强改进,能够控制风格迁移的内容细节[12]。
随着科技不断的发展,图像风格迁移技术越发成熟,但图像扭曲和细节丢失的问题仍然存在,今后基于卷积神经网络的图像风格迁移技术的主要突破点在于得到合成匹配度最佳、损失度更低的图像。
2.2 经典的卷积神经网络模型
经典的卷积神经网络模型有LeNet-5、AlexNet、VGG、NiN、GoogLeNet、ResNet、DenseNet等,本文将介绍AlexNet和VGG模型,并且对VGG中的两种模型进行对比。
AlexNet与前文提到的LeNet-5,设计理念十分相似,但AlexNet模型具有更深的网络结构,这个改进增加了卷积通道数让模型拥有更多路径提取图像特征,并且提高了可捕捉物体的像素大小[13]。同时,AlexNet引入了大量的图像增广,如裁剪、调整亮度和色彩,从而进一步扩大数据集来缓解拟合。AlexNet是第一个证明学习到的特征可以超越手工设计特征的模型,突破了当时计算机视觉研究的现状。
Oxford Visual Geometry Group自2014年先后发布了网络模型VGG11-VGG19。在下文将简单介绍VGG16和VGG19,并对两者之间差异进行对比。
VGG16模型[14]采用了5段卷积,对于每一段,其基本结构均由卷积(第1、2段的卷积次数为2,第3、4、5段的卷积次数为3)、池化和ReLU激活函数组成。VGG19模型与VGG16结构类似,只是卷积部分有所不同。VGG19第1、2段的卷积次数为2,第3、4、5段的卷积次数为4。
通过对比两个模型可以看出VGG结构非常一致,从头到尾都采用3×3大小的卷积核,核尺寸2×2的池化层,能较好地捕捉图像的梯度特征,从而高效地对边缘纹理等语义细节信息进行描述[15]。对比VGG16和VGG19两者没有本质区别,只是VGG19拓展性较强,迁移到其他图片数据集上的泛化性较好[16];拥有更强网络深度,可以合理分配各层的学习任务,学习到更复杂的变换,从而拟合更复杂的特征输入,提高图像识别的精度。
2.3 卷积神经网络的常用框架
在深度学习的研究中,研究者们为了提高编写代码的效率避免编写大量重复代码,将代码列为框架发布出去作为共享资源。目前常用的深度学习框架有TensorFlow、Caffe、Torch、Keras、PyTorch和DeepLear⁃ing4j等。本文将介绍基于卷积神经网络常用的三种框架TensorFlow、Caffe、Torch,并做出比较。
TensorFlow是Google推出的深度学习框架,可以部署各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算[17]。而且其拥有自带的可视化工具TensorBoard,具有展示数据流图、绘制分析图、显示附加数据等功能[18]。
Caffee是由伯克利人工智能研究小组和伯克利视觉和学习中心开发的C++/CDUA构架,支持命令行、Python和MATLAB接口,可以在CPU和GPU直接无缝切换。Caffee是目前计算机视觉领域最流行的框架,但是它对递归网络和语言建模的支持较差。
Torch是Facebook的开源机器学习库、科学计算框架和基于Lua编程语言的脚本语言。Torch可以最大化地保证算法的灵活性和速度,同时可以使用并行的方式对CPU和GPU进行更有效率的操作。但是Torch使用Lua作为脚本语言比较小众,并且不支持Win⁃dows。
针对三种不同的深度学习框架的各个属性总结如表1。
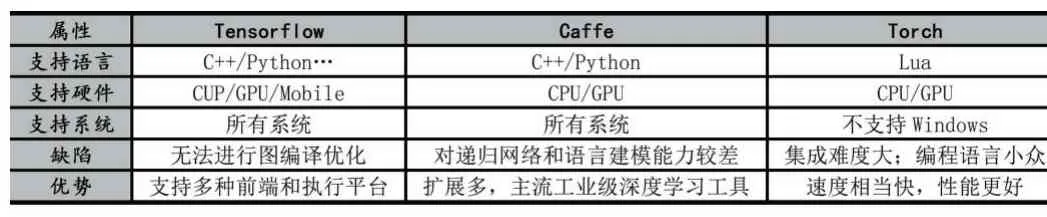
表1 三种框架的属性表
为了更直接更客观的对比三种框架,通过soumith/convnet-benchmarks给出的各个框架在AlexNet上单GPU的性能评测结果如表2所示,从表中可以看出TensorFlow的训练更加迅速。同时通过在GitHub上查询的数据显示,TensorFlow的性能、贡献和总评优于Caffe、Torch。
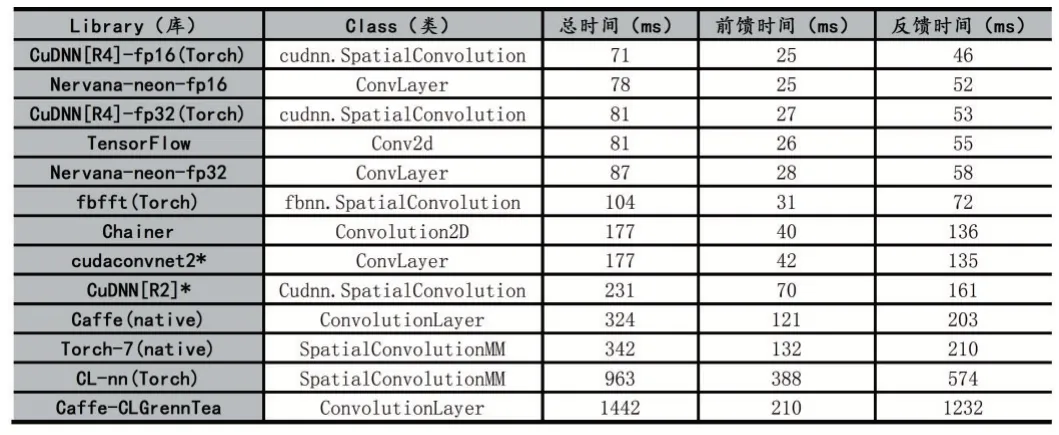
表2 各个深度学习框架在AlexNet上单GPU的性能对比
3 生成式对抗神经网络
3.1 生成式对抗神经网络的含义
在基于深度学习的图像风格迁移中,除了卷积神经网络被广泛应用,生成式对抗神经网络也相当热门。
生成式对抗神经网络(GAN),是伊恩·古德费洛(Ian Goodfellow)在2014年提出的。一个GAN主要包含两个独立的神经网络:生成器网络(Generator)和判别器网络(Discriminator)。生成器的任务是,从一个随机均匀分布里采样一个噪声z,然后输出合成数据G(z);判别器获得一个真实数据x或者合成数据G(z)作为输入,输出这个样本为“真”的概率。
物理学家理查德,费曼有一句名言:我不能创造的东西,我就不能理解。这与GAN的创造思路相符。当我们要计算机理解一类事物时,生成器就负责大量输入这类事物的数据,而判别器的任务就是甄别多个实例之间的异同与真假,然后保留判断为真样本的共同点,建立模型,最后输出。生成器提供的数据越复杂,判别器最后输出的模型结构就越精确,越趋向真实样本情况。
3.2 生成式对抗神经网络在图像上的相关应用
GAN主要应用于超分辨任务、语义分割、数据增强。
对于超分辨率任务,GAN工作原理简单的来讲,就是生成器负责通过输入的低分辨率图片生成高分辨率图片,然后交给判别器辨别是否符合原图,如果为否,那么生成器会再次进行训练生成,直到符合判别器标准再输出。
语义分割,就是识别图片中的不同物体,将不同的颜色填充,将它们各自区分开,让计算机对客观世界,拥有像人一样的辨别能力。
数据增强就是当数据样本数量不足,种类单一时,通过一定的方法将样本容量进行扩充丰富,以满足需求。
数据增强的作用:
(1)增加训练的数据量,提高模型的泛化能力。
(2)增加噪声数据,提升模型的鲁棒性。
由GAN训练得到的数据集与原数据样本有着较高的相似性,这是它在数据增强领域受欢迎的主要原因。
3.3 对抗式生成神经网络在图像风格迁移上的应用
GAN将一个对抗性判别器模型(判别器)巧妙地结合到一个生成模型(生成器)中,生成器生成数据,判别器判断该数据的真伪,二者相互竞争,相互促进,生成器产生的结果愈来愈真,达到以假乱真的程度;判别器的能力也愈来愈强,对于真假数据的判别越来越强。GAN训练过程是一个全自动的非监督性的学习过程,几乎无需人工干预。已有的研究表明,GAN在诸如图像生成、图像超分辨和半监督学习等各种任务中发挥着重要作用[19]。
GAN不仅在传统图像风格迁移上,有着极强的风格纹理抓取能力,能输出与原图像样本风格极为相似的产品;在抽象画系风格迁移上,通过模型的改进,GAN也能通过其独有的对抗训练能力,高效地抓取其纹理特点,然后输出效果理想的图像。
3.4 生成式对抗神经网络在图像风格迁移上的优劣势
优势:
(1)GAN能生成的图像数据与真实样本极为接近,几乎以假乱真。
(2)理论上,GAN能训练任何图像风格生成网络。
(3)不必遵循任何种类的因子分解设计模型,所有生成器和鉴别器都可以正常工作。
(4)模型只用到了反向传播,不需要马尔科夫链。
劣势:
(1)可解释性差,生成模型的分布Pg(G)没有显式的表达。
(2)比较难训练,D与G之间需要很好地同步。
(3)GAN很难学习生成离散性数据,例如学习生成一类带文字的图像。
4 结语
本文介绍了图像风格迁移技术的发展历程,详细分析了基于深度学习的图像风格迁移技术现今较热门的两种神经网络模型,即卷积神经网络模型和生成式对抗网络模型。通过对这两种模型多个方面的分析我们发现,随着社会的进步与发展,卷积神经网络应用领域越来越广阔,再加上人工智能的不断发展,卷积神经网络在诸多研究方向上都大放光彩,用户对卷积神经网络模型的要求也会越来越高,今后很长一段时间内卷积神经网络依然是深度学习领域研究的重点。
总而言之,今后对于卷积神经网络的研究必定会持续下去,且会在很长一段时间内占据研究者们的视线。
