通道注意力与残差级联的图像超分辨率重建
2021-03-23蔡体健彭潇雨石亚鹏
蔡体健,彭潇雨,石亚鹏,黄 稷
(华东交通大学信息工程学院,江西南昌330013)
1 引 言
图像超分辨率(Super-Resolution,SR)作为计算机视觉领域的一个重要分支,一直是研究者们关注的热点问题。单幅图像超分辨率的目的是提升图像分辨率,即将单幅低分辨率(Low-Resolution,LR)图像恢复成高分辨率(High-Res⁃olution,HR)图像,这是一个经典的不适定逆问题。由于其在监控设备、遥感卫星图像[1]和医学影像[2]等领域都有非常重要的应用价值,大量的相关算法不断涌现,从早期的基于插值法[3]到各种利用内部自相似性法[4]和稀疏表示法[5],再到现如今基于学习的方法[6]。图像超分辨率方法的性能越来越好,特别是深度学习的应用让超分辨率重建质量得到快速提升。
Dong等[8]首次提出一个只有三层的超分辨率卷积神经网络(Super-Resolution Convolution⁃al Neural Network,SRCNN)来完成低分辨率图像到高分辨率图像的映射,与之前的方法相比性能有了很大提升,但仍然存在一定局限性。随后,Kim等[9]又将SRCNN进行改进把网络加深到接近20层,并在最后重建层加入了一个跳连接使得网络VDSR(Very Deep Convolutional Net⁃works)只需学习残差。这样既可以减轻加深网络带来的梯度爆炸/消失的问题,又能避免重复学习,加快收敛。VDSR所带来的提升也证明了更深的网络能提高网络模型的表达能力,带来更好的超分辨率效果。残差学习所取得的显著效果使其被应用到越来越多的超分辨率网络模型。Shi等[10]极具创意地提出了一种有效的亚像素卷积网络模型(Efficient Sub-Pixel Convolutional Neural Network,ESPCNN),该网络可以将卷积后所得的特征进行像素重排直接得到高分辨率图像,并不需要像SRCNN那样对低分辨率图像进行插值预处理。这一改进让基于CNN的超分辨率网络模型能够学习更加复杂的映射关系,大大降低了放大图像的成本。后来出现的超分辨率方法很多都使用了这一操作来对图像进行重建。Lai等[11]提出了一种类似金字塔结构的超分辨率重构模型LapSRN(Laplacian Pyramid Net⁃works),该模型在放大倍数较高的情况下仍然能保持不错的重构效果。与之前这些追求高数据指标的方法不同,Ledgi等[12]构建了一个用于图像超分辨率的生成对抗网络SRGAN(Super-Resolution using Generative Adversarial Net⁃work)。虽然重建图像在客观评价上并不好,但可以给人带来更好的主观视觉效果。Lim等[13]以Resblock[14]为基础设计了一个非常深的网络模型EDSR(Enhanced Deep Residual Networks for Single Image Super-Resolution),并获得2017世界超分辨率重建挑战赛冠军。EDSR结构与SRGAN中的生成网络SRResNet[12]基本类似,但它将残差块中的批归一化(Batch Normalization,BN)[15]操作去除,因为实验表明BN操作并不适用低层计算机视觉,这一改进也让模型性能得到很大提升。同年,Tong等[16]结合DenseNet[17]提出了一种能充分利用不同层次间特征信息的网络模型SRDenseNet,但极端的连接性不仅阻碍了网络的可伸缩性还会产生冗余计算。
很多超分辨率方法都试图通过加深或加宽网络来提升算法性能,但这样往往会增加模型计算量,还不能很好地挖掘CNN的表达能力。在输入的LR图像中蕴含了丰富的特征信息,然而这些信息往往得不到充分利用甚至被忽略从而限制了网络的性能。另外,信息也分为不同种类,有的是低频信息,有的是高频纹理信息。目前的方法大多数都是平等对待特征通道信息,缺乏处理不同通道信息的灵活性。
为此,本文提出了一种通道注意力与残差级联超分辨率网络(Channel Attention and Residual Concatenation Network,CARCN)。本文的贡献主要如下:(1)将原始的特征信息通过融合节点(Fusion Node,FN)与各层进行融合,让LR图像中的特征信息得到更好的传递。(2)提出了残差级联组(Residual Concatenation Group,RCG)结构,通过每一层与输入的级联改善不同层次之间信息流动,充分利用LR图像中的特征信息的同时还能自适应地调整已融合的特征通道,大大提高网络对图像细节纹理等高频信息的重建效果。实验结果也表明:本文提出的方法与其他先进的超分辨率方法比较,无论是主观视觉效果还是客观数据评估都更好。
2 本文方法
2.1 网络结构
本文融合了通道注意力机制、级联操作和残差学习的策略,提出了CARCN,其整体结构如图1所示,该模型主要由浅层特征提取(Shallow Feature Extraction,SFE)、深层特征映射(Deep Feature Mapping,DFM)和重构(Reconstruction,REC)三个部分组成。
首先只用一个卷积层从输入图像提取浅层特征:

其中:HSFE()表示一个3×3的卷积操作,ILR为输入的低分辨率三通道图像,X0为提取到的浅层特征。随后,将X0用作深度特征映射模块的输入:
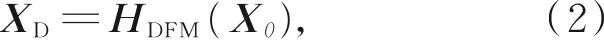
其中:HDFM()表示整个深层特征映射模块。如图1所示,深层特征映射模块由多个残差级联组(RCG)、融合节点(FN)、长跳连接和一个常规卷积层组成。融合节点由一个级联层和一个1×1的降维卷积组成,将残差级联组的输出特征与提取到的浅层特征进行级联特征融合并降维处理传递给下一个网络层,保证信息在传递过程中不被丢失,从而让原始特征得到最大化利用。卷积层后的长跳连接可以通过残差学习提升网络性能。XD为提取到的深层特征,最后进行重构得到超分辨率图像:
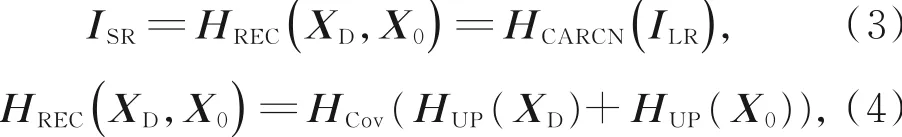
其中:HREC()表示整个重构部分函数,HUP()为上采样操作,HCov()是末端的卷积层,输出通道数为3。很多方法可以完成上采样功能,比如转置卷积和亚像素卷积[10]。考虑到亚像素卷积在执行上采样操作方面比较灵活,能够平衡计算效率和性能。本文也选择使用亚像素卷积实现重构部分的上采样操作。此外,与许多网络不同,为了使训练更加稳定,本文不仅对深层特征上采样,对前面提取的浅层特征也进行上采样操作,通过长跳连接一起进行特征重构并输入到整个网络的最后一个卷积层,得到高分辨率图像ILR。
2.2 注意力模块
很多基于CNN的超分辨率算法对所提取的特征通道都是同等对待,限制了网络的重构性能。为此,本文构建了一种有效的注意力模块(Attention Block,AB),能自适应地对特征通道进行校正。

图1 网络整体结构图Fig.1 Overall network architecture of proposed CARCN model
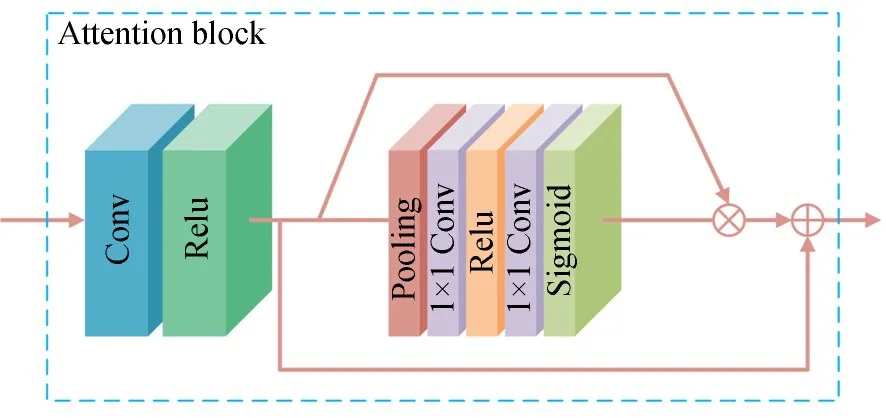
图2 注意力模块结构图Fig.2 Structure of the attention block
注意力模块结构如图2所示,一开始用一个卷积层对模块的输入进行特征映射,经过Relu函数激活后得到一个大小为H×W×C的特征,记作F=[f1,f2,…,fc−1,fc],其中fc是第c个特征通道。然后采用全局平均池化对每个通道的信息进行全局压缩,获得一个能够代表这些通道的向量,即:其中:Hsq()表示全局平均池化操作,fc(i,j)是坐标(i,j)上的像素值,zc为对第c个通道进行全局平均池化得到的值。可以将上面的操作看作是对输入特征通道信息的初步统计,压缩得到的信息具有全局的感受野。
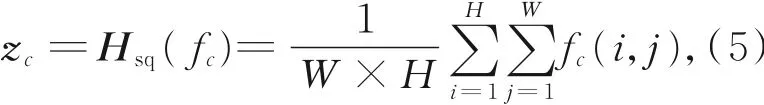
紧接着,用两个1×1卷积来学习不同特征通道的相关性。第一个卷积将特征维度压缩到原来的1/r(r为维度压缩比例r=16),经Relu函数激活后,第二个卷积将特征维度复原。这种类似沙漏的结构具有更多的非线性映射,可以更好地拟合通道间的复杂关系,同时还能够减少参数与计算量。随后,用Sigmoid函数对特征通道信息进行重新表示,即:

其中:δ()与σ()分别表示Sigmoid函数与Relu激活函数,CD()与CU()分别为前后两个卷积操作。最后用获得的特征通道相关性信息s对原始输入特征进行重新校正,即:

其中:fc和sc分别是第c个特征通道和校正因子,xc则为校正后的特征通道。同时加入短跳连接让低频信息快速通过,专注于高频信息的校正。整个过程其实就是一个给特征通道重新加权的过程,权值代表通特征通道的重要性,再根据其重要性来进行调整。
2.3 残差级联组
在之前的超分辨率方法中,随着网络的不断加深,特征信息在传递过程中会被网络层逐渐忽略甚至遗漏,以至于最后用来重建的特征非常少。蕴含在LR图像里的丰富特征信息没有得到很好的传递和充分的利用,这很大程度上限制了网络模型的性能。
本文构建了一种残差级联组(RCG),结构如图1所示。从图中可以看出每一层由注意机力模块(AB)映射得到的特征都会与最开始的输入特征进行通道级联,并传递到下一层:

其中,C()表示级联操作,HAB,n()为第n个注意力模块函数,总共有4个注意力模块,X0是整个残差级联组的输入。随后用一个1×1的卷积对级联后的特征进行降维,最后通过一个跳连接加速低频信息的传递,可用式(9)表示:

其中:Cdown()表示卷积降维,X为最后的输出。残差级联组中各层参数设置如表1所示,H,W分别是输入特征图像的高度和宽度。
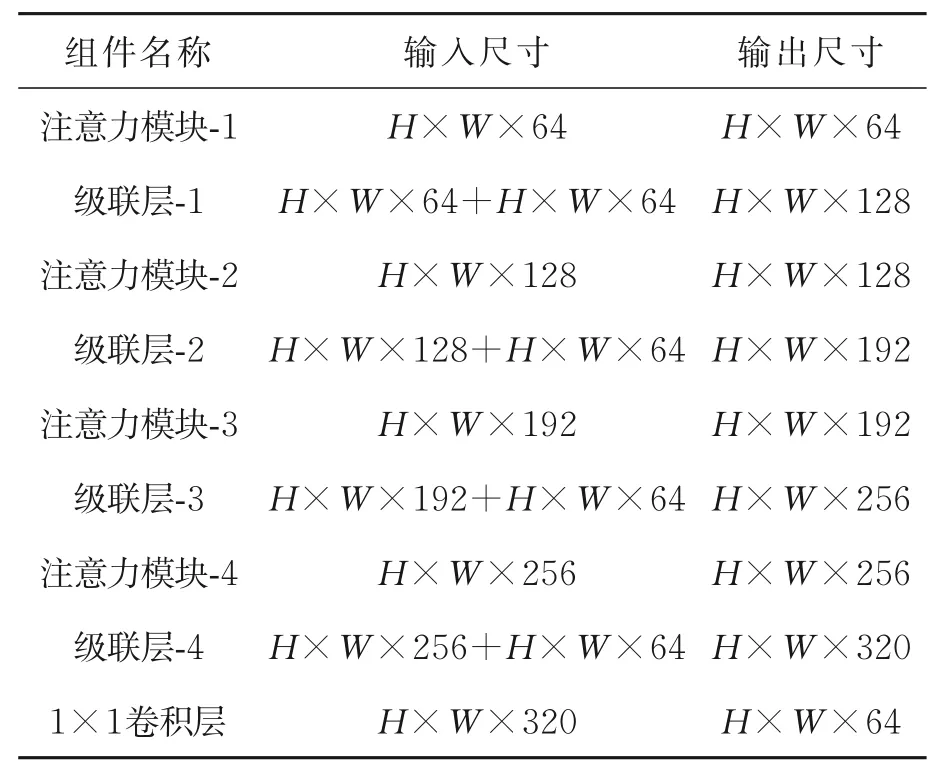
组件名称输入尺寸输出尺寸注意力模块-1级联层-1注意力模块-2级联层-2注意力模块-3级联层-3注意力模块-4级联层-4 1×1卷积层H×W×64 H×W×64+H×W×64 H×W×128 H×W×128+H×W×64 H×W×192 H×W×192+H×W×64 H×W×256 H×W×256+H×W×64 H×W×320 H×W×64 H×W×128 H×W×128 H×W×192 H×W×192 H×W×256 H×W×256 H×W×320 H×W×64
在残差级联组中,初始输入直接连接到所有输出层,与残差网络那样直接算术相加不同,这里是进行通道级联,再将融合后的特征映射传递给后续的网络层。这种不同层次间的级联设计结构可以改善不同网络层间的信息流动,保证特征信息传递过程中的完整性。另外,残差级联组中每一层的注意力模块可以自适应地调整已融合的特征通道,这也让它能够在充分利用LR图像中大量特征信息的同时,对每个卷积层的通道信息进行调整,有效提升了CNN的图像重构能力。
2.4 损失函数
众所周知,损失函数对神经网络模型的训练非常重要,合适的损失函数可以使网络模型得到更好的训练,提高网络性能。本文使用L1损失函数来训练模型。

其中:θ代表网络的参数集,D()代表了整个网络模型。
3 实 验
3.1 数据集
在实验中,本文选择了高质量的DIV2K[18]数据集用作训练,该数据集总共有1 000张2K分辨率的高清图像,其中800张为训练图像,100张为验证图像,以及100张测试图像。评估测试方面,采用4个被广泛使用的标准数据集:Set5[19],Set14[20],B100[21]和Urban100[22]来测试模型性能。为了便于与其他先进方法比较,本文和其他算法一样使用峰值信噪比(Peak Signal to Noise Ra⁃tio,PSNR)和结构相似度(Structural Similarity Index,SSIM)[23]来对模型性能进行评估。所有的实验结果都是在YCbCr颜色空间中的Y通道上计算得到的。
3.2 实验细节
实验对DIV2K数据集的800张训练图像进行了数据增强。通过将原始图像随机旋转[90°,180°,270°]和水平翻转,可以从每张原始图像中获得额外的7张增强图像。在每次小批量(Minbatch)训练中,从LR图像中随机截取16个大小为48×48的LR图像块作为网络的输入。初始学习率设置为10−4,每2×105次迭代学习率衰减一半,总共进行106次迭代训练。本文采用Adam算法对所提出的模型进行优化,相关参数设置如下:β1=0.9,β2=0.999,ε=10−8。整个实验采用tensorflow框架,在单个NVIDIA 2080Ti GPU上训练3天完成。
在整个网络模型中,除了文中说明外,其他的卷积核大小都为3×3,通道数设置为64,级联与降维操作依次计算。残差级联组与融合节点的数量均为10。
3.3 客观结果比较
表2 显示了本文所提超分辨率方法与现有8种超分辨 率 方法Bicubic[3],SRCNN[8],FS⁃RCNN[24],VDSR[9],DRRN[25],LapSRN[11],ED⁃SR[14]和RDN[26]在×2,×3,×4这3种不同放大倍数时进行定量比较的结果(最优值加粗表示)。从表中可以看出,本文提出的CARCN网络在测试集上的PSNR和SSIM值很多要高于其他方法。特别是在Urban100数据集上×3,×4超分辨率的结果,本文方法在PSNR指标上比第二的RDN[26]分别高出了0.09与0.10。且Ur⁃ban100数据集中的图像都是一些包含很多纹理细节的建筑物图像,这也充分说明本文所提方法在复杂图像的超分辨率重建上性能比其他方法更好。
3.4 主观视觉比较
本文分别从B100与Urban100数据集中总共选取了四张图片用于与其他超分辨率方法在主观视觉上比较,如图3~图6所示。这些方法包括Bicubic[3],SRCNN[8],FSRCNN[24],VD⁃SR[9],LspSRN[11],DRRN[25]6种现有的经典超分辨率方法。从图3和图4中能够看出,本文提出的CARCN网络重建后的图像要比其他方法更加清晰。再观察图5可以发现,其他方法重建后的图像在纹理上都是较模糊甚至有些错乱的,本文的方法可以相对清晰且准确地恢复图像中的纹理部分。同时图6也显示了本文方法的视觉效果要好于其他方法,特别是在细节纹理的恢复上相比其他方法的效果更加细腻丰富。

表2 在4个测试数据集上,各种方法×2,×3,×4超分辨率的比较(PSNR/SSIM)Tab.2 Comparison of various methods×2,×3,×4 super resolution on four test data sets(PSNR/SSIM)

图3 B100数据集中69015放大倍数×3的超分辨率结果对比Fig.3 Super-resolution results comparison of imgae 69015 in B100 for scale factor×3

图4 Urban100数据集中img_050放大倍数×3的超分辨率结果对比Fig.4 Super-resolution results comparison of imgae img_050 in Urban100 for scale factor×3

图5 Urban100数据集中img_089放大倍数×4的超分辨率结果对比Fig.5 Super-resolution results comparison of imgae img_089 in Urban100 for scale factor×4

图6 Urban100数据集中img_046放大倍数×4的超分辨率结果对比Fig.6 Super-resolution results comparison of imgae img_046 in Urban100 for scale factor×4
3.5 参数与性能比较
图7 显示了本文提出的CARCN模型与其他先进超分辨率模型在Set5数据集上,4倍超分辨率情况下结合性能与对应参数的比较结果。

图7 不同模型性能与参数量的比较Fig.7 Comparison of performance and the number of pa⁃rameters of different models
图中参与比较的模型包括SRCNN[8]VD⁃SR[9],LapSRN[11],DRRN[25],MemNet[27],DB⁃PN[28],EDSR[14]及RDN[26]。可以看出本文提出的模型在测试数据集上的PSNR指标是最高的,但参数却几乎只有EDSR[14]的1/4,RDN[26]的1/2,这也说明了本文所提模型在性能上要优于其他模型。
3.6 消融分析
为了探究残差级联组(RCG)和融合节点(FN)对本文提出的CARCN网络性能的影响,本文将保留RCG与FN和去除RCG与FN的四种网络在Set5数据集上×2超分辨率的实验结果进行比较,本次实验进行了4×104次迭代训练。由于去除RCG模型参数会相应减少,为了公平比较,对去除RCG的网络增加相应的通道数来保持两种情况下的参数一致,并保留注意力模块。结果如表3所示,可以看出,同时保留RCG和FN的网络比其他三种网络重构能力更好。其中,RCG的去除对模型性能影响较大,FN影响相对较小。图8显示了四种网络的收敛曲线(图中FN-1-RCG-1表示同时保留FN和RCG的收敛曲线,数字1表示保留,0表示去除)。从图中也可以看出FN与RCG都去除的网络训练稳定性最差,效果也较差;FN与RCG均保留的网络训练更加稳定,性能也最好。这表明本文提出的残差级联组结构和融合节点对提升网络模型性能有不错的效果。

表3 Set5数据集上RCG和FN的实验对比Tab.3 Experimental Comparison of RCG and FN on Set5
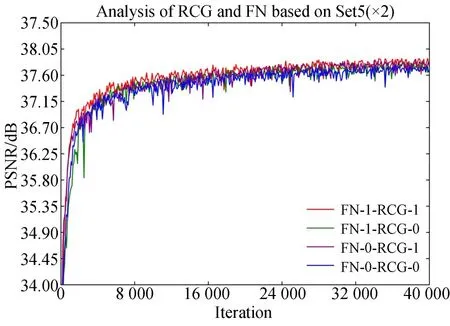
图8 RCG和FN的收敛分析Fig.8 Convergence analysis on RCG and FN
4 结 论
本文提出了一种通道注意力与残差级联超分辨率网络CARCN来改善超分辨率重建效果。利用融合节点将原始浅层特征传递给其他网络层,构建了残差级联组,通过级联结构让每一层充分利用LR图像中的特征信息并有进行有效传递,同时注意力模块可以自适应地对特征通道间的相互关系进行校正,提升网络对细节纹理的恢复能力。在Set5,Set14,B100,Urban100 4个基准数据集上的测试结果表明,本文提出的方法与其他方法相比,无论是在客观数据评估还是主观视觉比较中性能都要更好,在Ur⁃ban100数据集4倍超分辨率的PSNR指标上比第二高出了0.1 dB,有效提高了图像超分辨率重建质量。未来将进一步对网络结构进行优化,提高其综合性能。