基于MIMO-CNN的多模态坐姿识别
2021-03-23黄安义
黄安义,沈 捷,秦 雯,王 莉
(南京工业大学 电气工程与控制科学学院,江苏 南京 211816)
0 引 言
目前国内外对人体姿态识别的研究,如文献[1-5],都是基于计算机视觉的人体姿态识别。相比而言,坐姿的识别对人体姿态细节特征提取的方法有着更高的要求。目前从数据获取方式上主要分为基于人体半接触的传感器和基于视觉的坐姿识别两类。
朱卫平等和Qian等[6,7]通过压电类传感器获取的数据和其它数据相融合进行坐姿识别。但这类方法因为人的体重和在椅子上坐的面积等差异因素,导致产生的数据不具有规律性,使其精度大打折扣。
而基于视觉的坐姿识别,如袁迪波等[8]提出基于肤色的YCbCr的BP神经网络的坐姿识别。张鸿宇等[9]通过提取坐姿的深度图像的Hu矩,采用SVM分类坐姿。Yao等[10]通过Kinect深度摄像头捕获的实时骨架数据估算颈部角度和躯干角度来判断坐姿。曾星等[11]对坐姿深度图像采用阈值进行前景提取并进行三维投影和降维,最后运用随机森林对姿进行分类识别。
综上所述,目前的方法主要有以下缺陷:第一,对于复杂背景下的抗干扰性较差;第二,不同人体坐姿多样性和拍摄角度变化适应性较差;第三,坐姿的分类问题的类间区分方法具有模糊性。而本文提出的基于MIMO-CNN的多模态特征的坐姿识别在解决以上问题上提供了一个可行的方法。
1 系统框架
本文所提出的坐姿识别方法流程如图1所示。
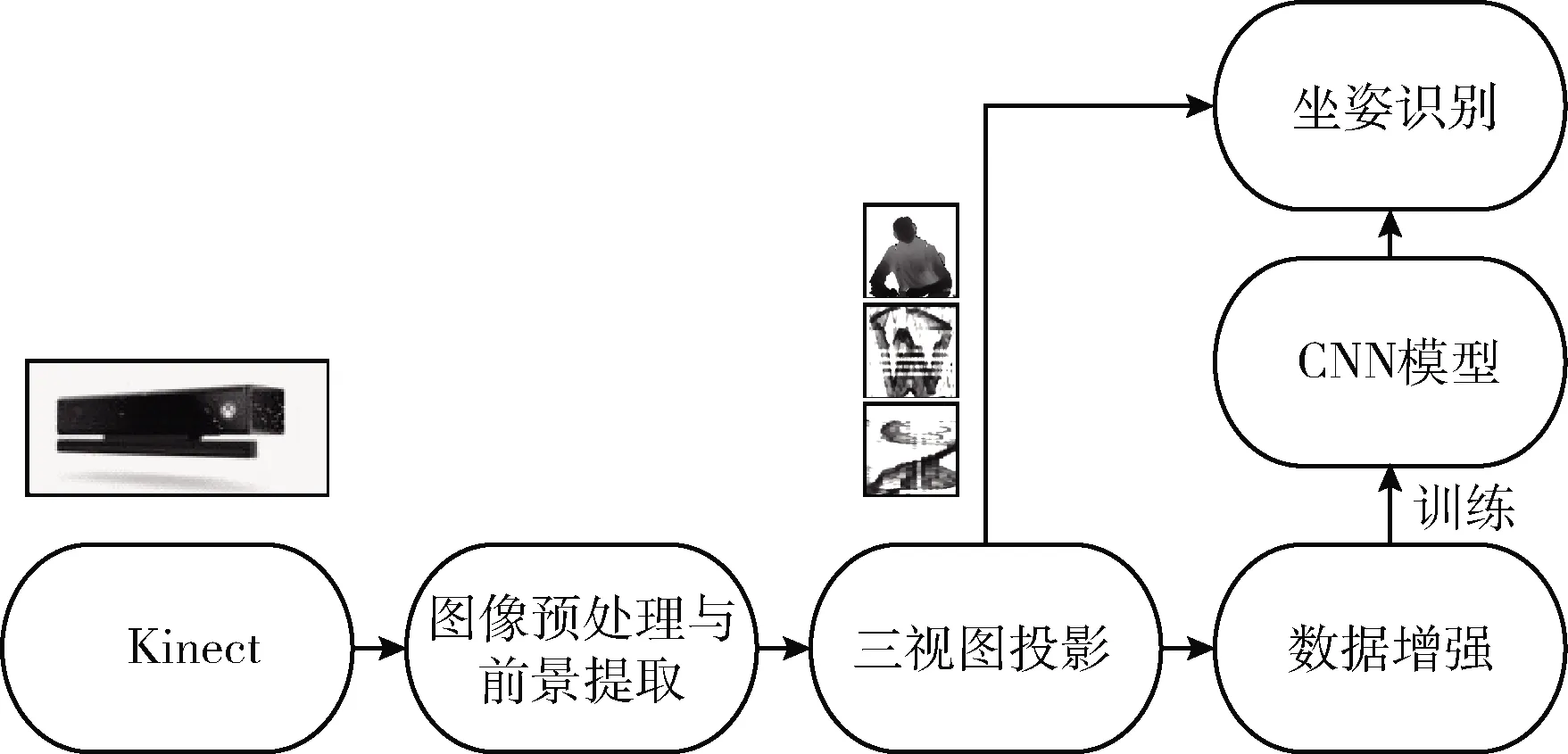
图1 坐姿识别方法流程
首先通过Kinect深度摄像头获取初始图像,并对其进行预处理,并以预处理后的图像为基础进行三视图映射。为了达到训练含有大量参数的网络,对数据集进行数据增强达到扩展数据集的目的,并使用增强后的数据集进行模型训练,最终使用训练后的模型进行左右和前后方向的坐姿识别。10种坐姿可分为前后和左右方向的识别,前后分为正坐、低头、后仰和趴桌,左右方向分为左偏、居中和右偏。考虑到趴桌的特殊性不再进行左右方向判断,具体分类如图2所示。

图2 坐姿分类
2 深度图像的采集
本文使用二代Kinect进行坐姿采集,因其强大功能的SDK,其可在深度数据的基础上,应用骨骼评估算法获得人体骨骼信息,生成人体外骨架图像。
而本文所用的基本特征为深度图像,深度图像是指将从传感器中得到它到场景中各点的距离信息并归一换算为像素值的图像。本文使用Kinect强大的SDK,获得其人体轮廓图和人体深度图像,如图3所示。

图3 (左)人体轮廓图和(右)人体深度图像
3 坐姿识别算法
3.1 图像获取与预处理
本文通过Kinect获取深度图像和人体轮廓图,并以此为基础进行预处理。首先对深度图像进行直方图均值化,使得深度信息可以更好地在直方图上分布。在增强局部对比度的前提下而不影响整体对比度,使得深度图像能更清晰表达距离信息
(1)
g(x,y)=Sf(x,y)*(L-1)
(2)
式中:L是图像中的灰度级总数,原图像f的像素总数为n,nj为灰度值为j的像素数量。f(x,y)为原图(x,y)位置的原像素值,g(x,y)为直方图均值化后的像素值。均值化后的结果对比,如图4所示。

图4 直方图均值化前后对比
接着对人体轮廓图使用5*5的核进行开运算及中值滤波操作,减少图像的噪声和填补部分深度图像小缺块,对比结果如图5所示。

图5 开运算与滤波后的前后对比(左为原图)
最后将前面预处理完的轮廓图和深度图像进行掩模操作,形成所需的人体深度前景图像

(3)
式中:F(x,y)为生成的人体前景深度图像,G(x,y)为深度图像,D(x,y)为人体轮廓图,rows为图像的行数,cols为图像的列数,结果如图6所示。

图6 人体前景深度图像
接着进行阈值自动裁剪,裁减掉多余的白色背景,得到224×224的图像,如图7所示。

图7 阈值自动裁剪效果
最后以裁剪后的图像为基础进行三视图映射,并进行归一化,最终得到224×224的人体坐姿深度三视映射,如图8所示。

图8 人体坐姿深度三视映射
3.2 数据增强
目前没有关于坐姿的深度开源数据集,所以在确保我们能在较少的样本中较好地训练和验证所提方法,对其进行数据增强显得尤为重要。因此在训练过程中我们对数据集中每一张图片进行50%概率的随机裁剪。设原始图像的宽度W和高度H,本文将以(0.85 W)×(0.85H)的滑动窗口对图像进行自动随机裁剪,并将裁剪后的图像重新插补为W*H大小的图像。
3.3 MIMO-MobileNet模型
考虑到本问题的特殊性,不同于传统的分类问题,其在人体姿态的坐姿方面的差异性与传统的图像分类相比,更加侧重于更加细致深度信息的变化,而不是传统的色彩、轮廓和纹理。因此也需要更多特征信息,所以本文将坐姿深度图像的三视图的多模态信息分别输入到3个不同的通道中。
另一方面,本文考虑到坐姿的特殊性,其在左右方向和前后方向的识别具有差异性,因此本文的模型结构在输出端使用的是双通道输出,分别对应坐姿的左右方向和前后方向的坐姿姿态的判断。
而目前较为出色的网络结构主要针对彩色图像为场景。因此本文提出MIMO-MobileNet模型,搭建了一个适用于坐姿识别的三输入两输出网络结构,后期实验也验证了此结构的可行性。
其主要以MobileNet V2的Inverted Residual Block结构块为基础,结构块先用point-wise convolution将输入的feature map维度变大,然后用depth-wise convolution方式做卷积运算,最后使用point-wise convolution将其维度缩小。注意,此时的point-wise convolution后,不再使用ReLU激活函数,而是使用线性激活函数,以保留更多特征信息,保证模型的表达能力,同时也具有Resnet的思想,其结构如图9所示。

图9 Inverted Residual Block结构
MIMO-MobileNet模型结构如图10所示,上层3个通道的网络net_L、net_M、和net_T分别以坐姿深度图像的左视图、主视图和俯视图为输入,并独立对其进行特征提取,并将提取后的特征用于后面通道的网络的输入,使得浅层网络能更充分的单独对3个视图不同的信息进行提取,而不进行权值共享。接着将net_L、net_M和net_T 的输出进行通道合并作为net_pred_v的输入,net_M、和net_T的输出进行合并作为net_pred_h的输入。最终net_pred_v输出坐姿在前后方向的识别结果,net_pred_h输出坐姿在左右方向的识别结果。其依据在于前后方向的坐姿变化在主视图、左视图和俯视图都有明显的变化,而在左右方向的坐姿变化,图像信息变化主要体现在主视图和俯视图。
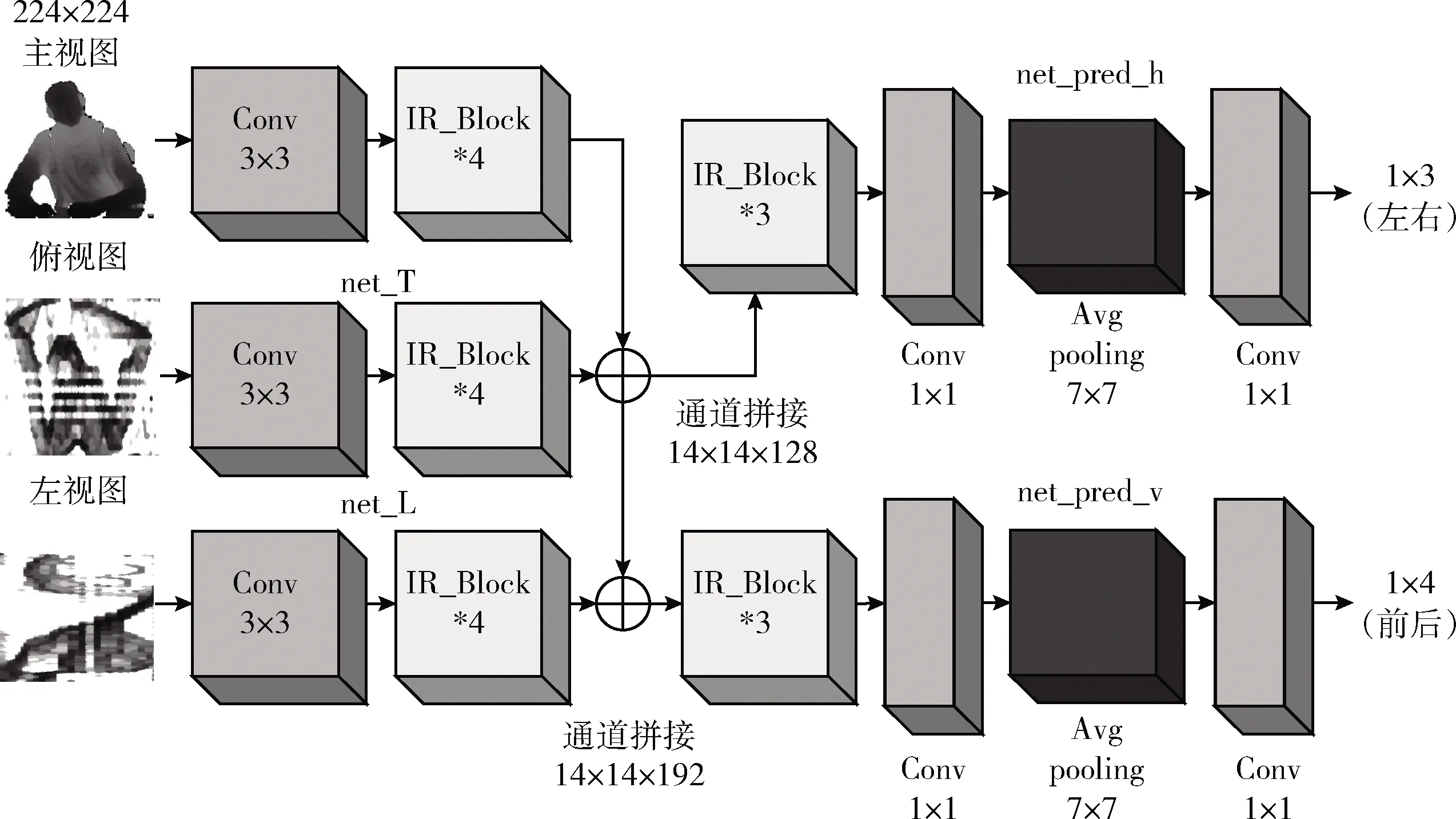
图10 MIMO-MobileNet模型结构
MIMO-MobileNet模型的网络框架参数见表1、表2和表3。
3.4 损失函数的定义
本文提出的MIMO-MobileNet模型为双输出网络,因此在损失函数上,我们分别计算两个输出的交叉熵。交叉熵其本身具有较好的计算概率分布差异的能力,且利于梯度下降。所以在模型输出后,本文对其进行softmax回归处理后,得到输出的概率分布,再进行交叉熵计算
(4)
式(4)为softmax公式,yi为原始输出,y′i代表经过softmax回归输出后的概率分布,c表示分类问题的类别数

表1 net_L、net_M、net_T网络框架参数
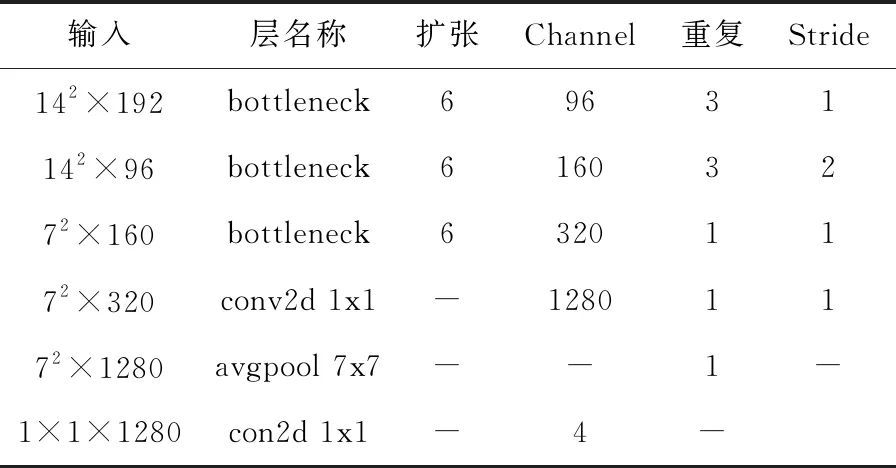
表2 net_pred_v网络框架参数
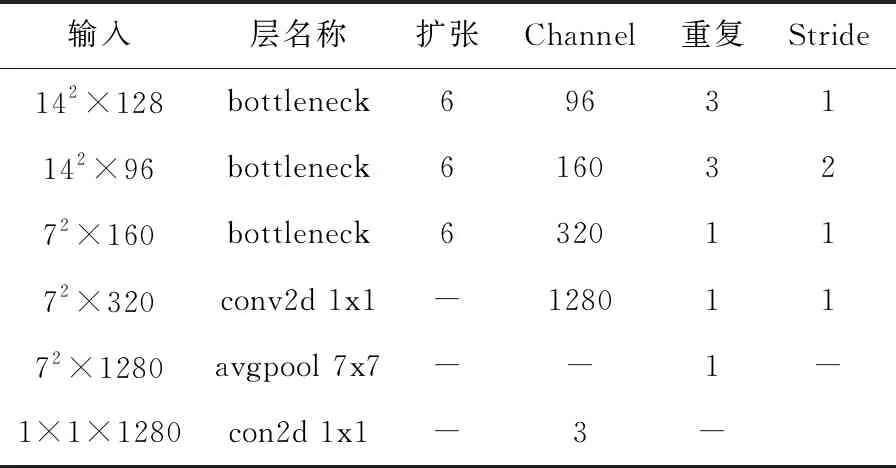
表3 net_pred_h网络框架参数
(5)
式(5)为交叉熵公式,其中labeli表示为one-hot编码后的标签,m为训练batch的样本数
(6)
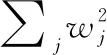
4 实验仿真与分析
4.1 实验方法和数据集
本实验中,以云端服务器作为工具,处理器型号为E5(8核),内存10 GB,显卡为RTX2080Ti。linux系统作为基本系统环境,以python语言调用谷歌tensorflow进行网络搭建及训练。
验证的数据集方面,因为目前没有公开的坐姿数据集,所以本文自定义了10种人们最常见的坐姿状态,并在摄像头固定在离人座位1 m远的位置处的条件下录制了15个男性女性志愿者的坐姿数据。每种坐姿有30个样本,前15张为正对摄像头的录制样本,后15张为人体正对摄像头并左右旋转(小于45度)的录制样本,训练样本共4500张样本,在训练过程中使用上文提到的方法进行数据增强,因此实际训练样本远多于此数。另外录制5名志愿者的有视角变化的和无视角变化的两个小样本集分各750张,一共1500张坐姿数据测试集。以(正坐、左偏)坐姿为例的具有摄像头角度变化的样本,如图11所示。

图11 不同摄像头角度的(正坐、左偏)样本
同时本文数据集将不仅具有角度变化,人体坐姿也更加接近真实环境中的坐姿,坐姿数据复杂度高于近几年其它方法,数据样本与文献[8]和文献[11]的样本进行对比,如图12所示。因此不再将本文的结果与其它方法进行对比。

图12 样本复杂度对比
实验一,将人体深度前景图像进行通道复制为三通道的图像作为输入,选用MobileNet-V2模型进行坐姿识别。而实验二,将三视图合并为一张三通道的图像作为输入,具有更丰富的特征信息,仍使用MobileNet-V2模型进行坐姿识别。实验三(本文方法),为本文提出的MIMO-MobileNet 模型方法,以上文的三视映射图作为输入。并分别在无角度变化的测试集和有角度变化的测试集上进行验证。
4.2 实验结果
实验结果见表4,实验一和实验二在无摄像头视角变化的测试集中,表现较为相似。但在更加复杂的视角变化的测试集中,我们发现具有更多信息的三视图映射图像作为输入的实验二,其81%的识别率明显高于实验一仅以人体深度前景图像为输入的74%的识别率。因此也验证了三视图映射图像作为输入,对于坐姿识别精度具有显著的提升。但识别率依然不是特别突出。
而对比实验二和实验三(本文方法)可知,本文提出的网络结构在各个测试集上识别精度都高于传统的MobileNet-V2网络。其总识别率也比实验二高出3%。因此验证了本文方法的合理性和优势。
表5、表6分别为无视角变化测试集上各个方向识别的混淆矩阵,在前后方向的坐姿识别上,依然存在一部分的正坐被识别为相近的后仰或者低头坐姿的情况。而在左右

表4 实验准确率对比结果/%
方向,左偏和右倾被识别为居中,可能是与左右倾斜程度较小导致一定的混淆。
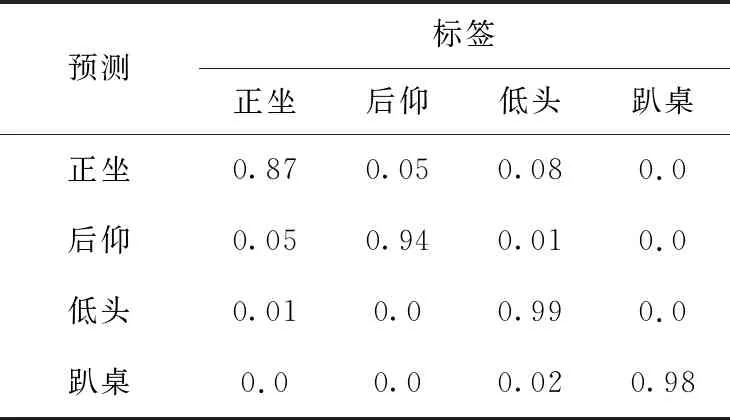
表5 无视角变化的前后方向混淆矩阵

表6 无视角变化的左右方向混淆矩阵
表7、表8为有视角变化测试集上各个方向识别的混淆矩阵。表中尤为明显的是正坐被识别为低头的错误,原因可能是某些的视角下,正坐的图像特征与低头极为相似。但在前后方向的其它坐姿下,识别率尤为出色。
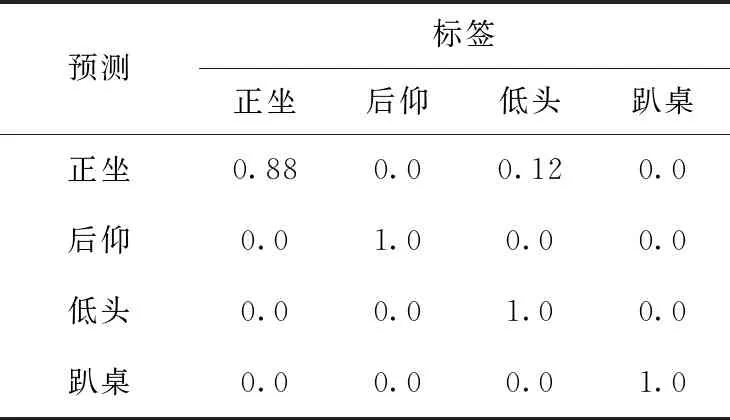
表7 有视角变化的前后方向混淆矩阵

表8 有视角变化的左右方向混淆矩阵
5 结束语
为应对人体坐姿多样性和拍摄角度变化,本文提出了基于MIMO-CNN的多模态特征人体坐姿识别方法。相比于单纯的使用物理接触式传感器,基于视觉方案的坐姿识别具有更好的性能和可实现性。另一方基于多模态深度信息,和识别过程中使用具有分类性能更加突出的深度学习网络的坐姿识别方法的确具有较高的识别率和鲁棒性。需要指出的是本文所提出的坐姿识别方法主要适合用在单人坐姿识别的情况。接下来将对复杂的多人坐姿识别和更加复杂的三维多视角问题进行进一步的研究。
