基于改进NeXtVLAD的视频分类
2021-03-23陈意,黄山
陈 意,黄 山
(四川大学 电气工程学院,四川 成都 610065)
0 引 言
视频分类不同于静态图像的分类,视频会随着时间的变化引起行为动作变化、场景变化和光线变化。目前基于深度学习的视频分类的代表性方法大致分为4种:基于双流的卷积神经网络模型[1-3]、三维卷积神经网络模型[4,5]、二维卷积与三维卷积结合的神经网络模型[6,7]和基于局部特征融合的神经网络模型[8-10]。文献[1]基于双流的思想提出TSN(temporal segment networks)模型,对视频稀疏采样的RGB图像和光流图像分别提取空间域和时间域的特征。为了对视频的时序信息建模,文献[5]提出P3D(pseudo-3D)模型。P3D利用三维卷积来实现对视频时间序列的建模,但是三维卷积需要消耗大量的显存和计算量。文献[6]将二维卷积和三维卷积相结合提出高效的ECO(efficient convolutional network for online video understan-ding)模型,即保证了模型的精度又降低了计算成本。以上方法都致力于时间序列的建模,文献[11]将传统的局部聚合描述子向量(vector of locally aggregated descriptors,VLAD)结构嵌入到卷积神经网络中得到可训练的特征融合模型NetVLAD(CNN architecture for weakly supervised place recognition),NetVLAD模型将视频的采样帧进行特征融合从而实现视频分类。NetVLAD编码后得到的特征维度太高导致网络参数量太大,于是文献[10]利用ResNext[12]的思想结合NetVLAD模型提出了参数量更少的NeXtVLAD模型。相比于前3种方法,基于特征融合的神经网络模型更加适合于时长较长的视频数据。本文主要针对时间长度不定的几分钟到几十分钟的视频进行分类研究,对NeXtVLAD算法进行改进,设计出一个精度更高的视频分类网络。
1 NeXtVLAD算法
NeXtVLAD算法是由NetVLAD算法改进而来,NetVLAD算法利用局部聚合子向量将视频帧的深度特征进行特征融合后得到视频级特征,然后利用视频级特征进行分类输出。NeXtVLAD针对NetVLAD编码后特征维度太高导致分类输出层参数量庞大的缺点,将输入数据x进行升维后再进行分组,最终减少编码后的维度从而大大减少参数量。
1.1 局部聚合子向量
局部聚合描述子向量最初用于图像检索领域,通过统计特征描述子与聚类中心的累计残差,将若干局部特征压缩为一个特定大小的全局特征。在视频分类任务中,可以将视频的一个采样帧所提取的深度特征看作一个局部特征,那么利用局部聚合描述子向量即可获得视频的全局特征。假设每个视频随机采样N帧作为视频表达,利用特征提取模块提取每一帧图像的深度特征得到F维度的局部特征,那么传统局部聚合描述子向量做法是将N*F的局部特征进行K-Means聚类得到K个聚类中心,记为Ck,则全局特征V如式(1)所示
(1)
式中:k∈{1,…K},j∈{1,…F},xi代表第i个局部特征,Ck为第k个聚类中心,αk(xi) 为一个符号函数,当且仅当αk(xi) 属于聚类中心Ck时,等于1,否则为0。可见式(1)累加了每个聚类中心的特征的残差,得到一个K*F维度的全局特征。
1.2 NeXtVLAD算法
显然式(1)中αk(xi) 不可微从而不能进行反向传播训练且最终全局特征维度过大会导致参数量大,NeXtVLAD将αk(xi) 函数可微化且将特征分为G组从而减少参数量,于是将全局特征表达为式(2)
(2)
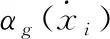
(3)
(4)
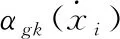
NeXtVLAD算法简要流程如图1所示。输入x的维度为Nsample*F,代表Nsample张采样帧的F维特征向量,经过NeXtVLAD特征融合后得到的全局特征向量维度为2F*K/G。
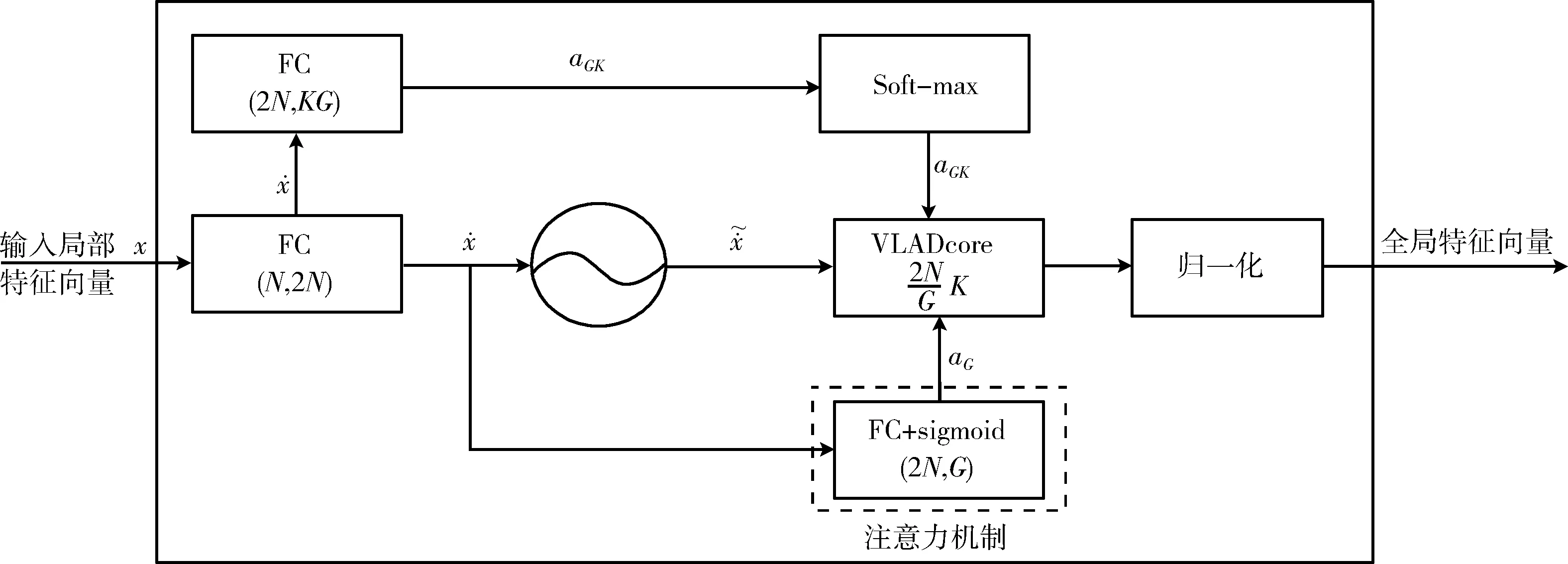
图1 NeXtVLAD流程
2 算法的改进
2.1 整体网络设计
本文基于NeXtVLAD算法进行改进提出GNeXtVLAD算法,实现对局部特征进行特征融合,设计出一个端到端训练视频分类网络如图2所示。本文模型主要由3个模块组成:特征提取模块、特征融合模块和分类输出模块。
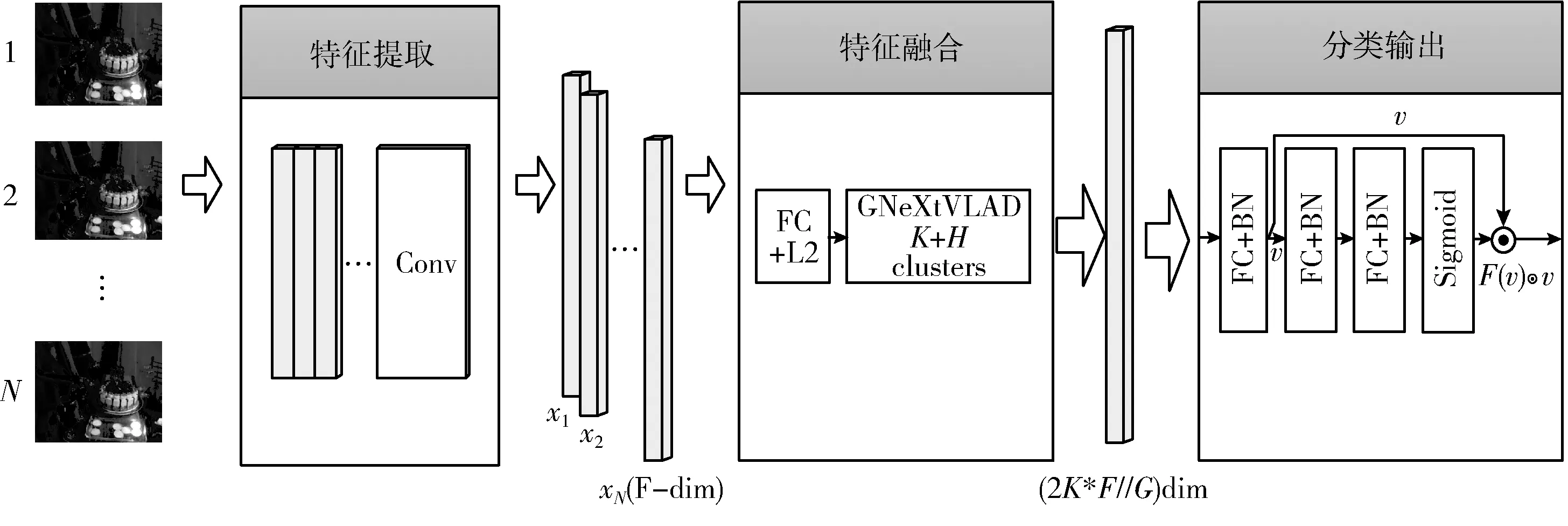
图2 网络整体设计
特征提取模块使用经典的图像分类模型ResNet-50[13],该算法通过学习残差,解决了传统卷积神经网络或全连接层在进行信息传递时存在的信息丢失问题,使得模型能更好学习图像的深度特征。本文为提取视频采样帧的深度特征,使用了ImageNet数据集在ResNet-50模型上进行预训练,预训练后去掉ResNet-50最后的全连接层使得特征提取模型输出为一个2048维度的深度特征,若视频采样帧数为Nsample,则特征提取模块输出为Nsample×2048维度的局部特征向量。
特征融合模块首先使用一个全连接层对特征进行降维,本文降维后维度为1024,然后使用对NeXtVLAD进行改进的GNeXtVLAD算法对Nsample×1024维的深度特征进行特征融合,从而得到视频级的深度特征。
分类输出模块将特征融合模块的视频级特征输出作为输入,通过对视频级特征的学习得到最终的分类输出。分类输出模块由两个全连接层和一个注意力机制模块组成,其中的注意力机制模块由两个全连接层和一个Sigmoid函数组成。
模型在训练过程中对特征提取模块的参数进行冻结,从而减少大量参数的反向传播,使得网络训练占用显存小、计算量小,从而保证在有限的资源条件下能训练大量视频采样帧。
2.2 视频采样策略
当处理未经裁剪的小视频数据时,这些视频镜头多变且场景信息复杂,对视频稀疏采样固定帧来描述视频信息效率不高,对时长较短的视频采样大量帧效率低下且影响性能,对时长较长的视频采样少量帧则会使得采样帧过少造成对视频信息的描述不足。本文提出多尺度的采样策略,假设视频总帧数为Ntotal,设置最小采样数和最大采样数分别记作Nmin,Nmax。 则采样帧数如式(5)所示
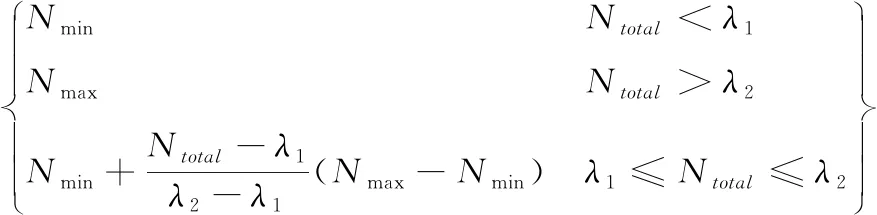
(5)
式中:λ1、λ2分别为最小帧数和最大帧数阈值。式(5)确定了对每个视频的采样帧数,在采样过程中,本文首先将所有视频帧等分为Nsample段,然后在每一段中随机采样一帧,从而对视频随机采样Nsample帧。
2.3 GNeXtVLAD
NeXtVLAD算法虽然对NetVLAD算法进行改进后参数量减少且精度有一定提升,但NeXtVLAD对所有的聚类中心一视同仁,不能很好地避免采样帧中无关特征的干扰。对于长视频的分类,采样帧中会存在一些与分类标签无关的特征,而NeXtVLAD算法依然会将每一个特征聚类到一个聚类中心。
文献[14]在人脸识别领域提出GhostVLAD算法,该算法在NetVLAD的基础上加入ghost聚类中心来降低低质量人脸图像的权重,同时提高高质量人脸图像的聚合权重。GNeXtVLAD在NeXtVLAD的K个聚类中心上增加了H个ghost聚类中心,那么网络的聚类中心数为K+H,但是此时的H个ghost聚类中心是假设存在但实际并不使用的聚类中心点,在计算输入的局部特征与聚类中心残差时只取K个聚类中心,即忽略ghost聚类中心的计算,主要目的就是让低质量的无关的局部特征归类到这个类中心点上。经过端到端的训练,GNeXtVLAD特征聚合模块可把一些无关特征聚类到ghost聚类中心,从而使得网络更加关注于与任务相关的局部特征。
GNeXtVLAD的计算公式如式(6)所示
(6)
(7)
在式(6)的基础上并结合神经网络的特点,设计出GNeXtVLAD特征聚合模块结构如图3所示。首先对比图1的NeXtVLAD结构可得,GNeXtVLAD在计算VLAD时多加入了H个聚类中心,然而在向后进行计算时又将这H个聚类中心去掉从而去除不重要的采样图片帧。
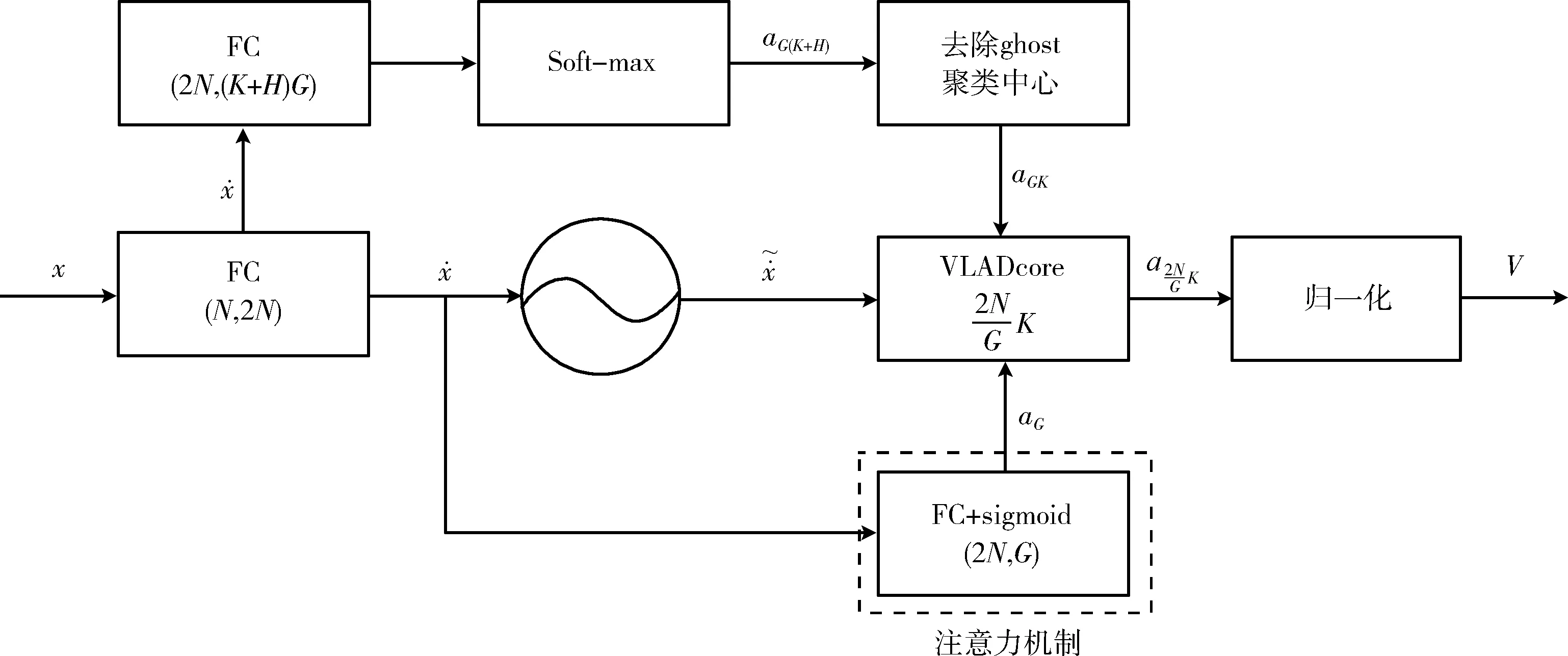
图3 GNeXtVLAD结构
3 实验与分析
为验证本文改进算法在视频分类任务上的有效性,本研究使用VideoNet-100数据集作为实验数据集,在搭载NVIDIA 2080Ti显卡的64位Ubuntu 16.04系统上搭建pytorch环境进行实验,通过一系列对比实验验证了本文改进算法在特定数据集上的有效性。
3.1 实验数据集
为验证本文算法对长视频的分类效果,实验采用VideoNet数据集[15]的前100个分类进行研究,简称数据集为VideoNet-100。VideoNet-100有3DPainting、3DPrinter、ACappella、accordionPerformance、acrobatics等100个类别。数据集中视频是未经裁剪的视频,其中每段视频时长不定,时长分布在几秒钟与几十分钟之间,大多数视频时长为几分钟。
VideoNet-100数据集中视频镜头数不固定,部分视频为单镜头拍摄,部分视频由多个镜头剪辑而成,图4为数据集中acrobatics类别的部分视频帧展示,可见随机采样帧中前后两帧场景可能完全发生变化,可能人物发生变化,也可能采样的某一帧的内容与主题无关。本文使用VideoNet原始切分的训练集和验证集,其中训练集视频个数17 798、验证集视频个数4580,训练集用于模型训练,验证集用于测试模型性能。

图4 VideoNet-100数据集中acrobatics类的部分视频帧展示
3.2 实验与分析
由于VideoNet-100数据集视频时长差异大,实验采用多尺度的采样策略与固定采样帧两种方法对视频帧采样,实验中设置多组不同的λ1、λ2、Nmin、Nmax参数和固定采样帧数进行对比实验以说明多尺度采样策略的有效性。由于网络输入的大小需要固定,其中采样帧数不足Nmax的用零进行填充。采样帧输入大小固定在224×224,每一采样帧经过特征提取模块即可得到一个2048维度的特征向量。在特征向量送入GNeXtVLAD进行特征融合之前先加入一个全连接层和Relu激活函数对特征向量进行降维,降维后的特征向量维度设置为1024。实验中GNeXtVLAD网络设置多组K聚类中心数、ghost聚类中心数进行对比实验,其中分组数G分别设置为8和16。实验采用Adam优化算法,初始学习率设置为0.001,每5个epoch将学习率降为原来的0.1倍,总共训练16个epoch。
表1对比了采用多尺度采样策略和不采用多尺度采样策略对视频分类准确率的影响。其中模型使用NeXtVLAD,设置默认参数G=8,K=128。 由表1数据可得,当设置最小采样帧数Nmin=32,最大采样帧数Nmax=128时正确率达到最高的0.908。当采用固定采样帧数时,最终测试正确率随着采帧数的增加而增加。通过对比固定采样帧数为128的识别正确率与采用多尺度采样且最大采样帧数为128的识别准确率可得:采用多尺度的采样策略能在减少采样帧数的情况下获得更高的正确率。
为验证视频长短对正确率的影响,本文按照视频时长对测试集分别切分短视频和长视频各500个,其中的500个短视频的时长不超过1 min,500个长视频时长均超过5 min,在不同采样策略上对比长视频和短视频的正确率,对比结果见表2。根据表2可以看出,当固定采样帧数较小时会影响时长较长的视频分类正确率,当固定采样帧数较大时对短视频分类正确率有一定的影响,而采用多尺度的采样策略效果最佳。

表1 不同采样策略识别正确率
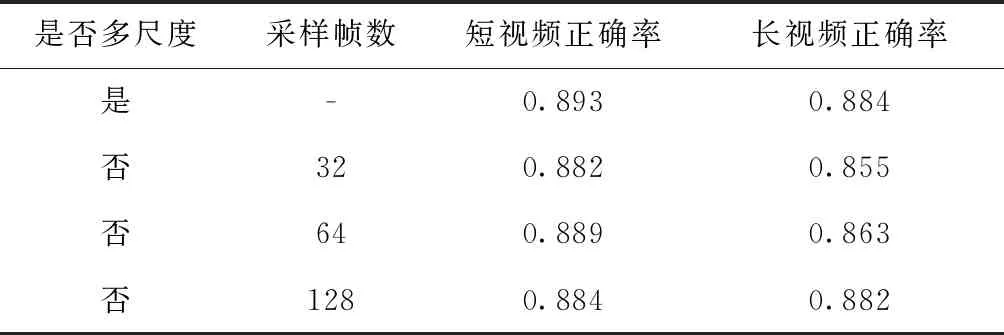
表2 不同采样策略对长视频和短视频精度影响
表3对比了多个不同的ghost聚类中心数值对GNeXtVLAD算法的影响,实验使用本文提出的多尺度采样策略对视频采样,设置默认参数λ1、λ2、Nmin、Nmax、K、G分别为750、7500、32、128、128、8。当ghost聚类中心数为0时,此时的特征聚合模块即为NeXtVLAD。由表3可以看出,加入ghost聚类中心的GNeXtVLAD相对于NeXtVLAD有着明显的提升。
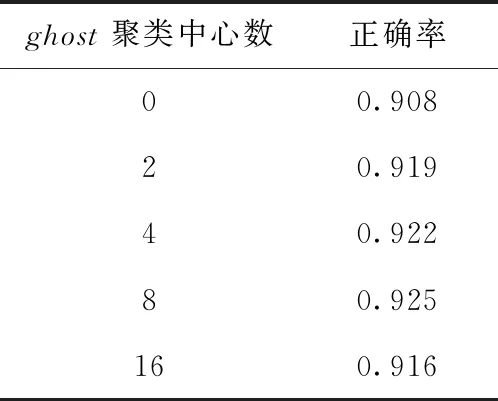
表3 不同ghost聚类中心的分类准确率
VideoNet-100数据集不同于UCF101和HMDB51等行为动作识别数据集,VideoNet时长远高于此类数据集。由于UCF101等行为识别数据集中视频镜头单一、时长较短,在一些经典的基于深度学习的行为识别算法中,一般对视频稀疏采样8帧或16帧即可达到不错的精度。对于VideoNet-100数据集中时长较长的视频来说,随机抽取8帧或者16帧可能对视频信息表达不完整,导致精度下降。本文对文献[1]提出的TSN模型进行复现,仅使用RGB图像在VideoNet-100数据集上进行实验对比。由于TSN模型对GPU显存的要求远高于GNeXtVLAD模型,故实验在TSN模型中对视频采样8帧和16帧,其余参数使用该文献的默认参数。表4为稀疏采样8帧和采样16帧的TSN模型和本文提出的网络在VideoNet-100上的实验结果。由表4可以看出,在稀疏采样8帧和16帧的情况下本文算法与TSN模型在VideoNet-100数据集上准确率相当,但是与表3中实验结果相比准确率较低,可见对于VideoNet-100数据集而言采样帧数会直接影响最终准确率。

表4 TSN模型与本文模型对比
表5对比了不同采样策略的GNeXtVLAD模型在训练时的占用显存大小以及TSN模型训练的占用显存大小。由于TSN模型在训练时需要对所有网络参数进行反向传播,故在batch_size大小为4,采样帧数为8时占用显存10 G。由表5可得,在占用显存相当的情况下,GNeXtVLAD模型相对于TSN在训练时单批次能处理更多的采样帧,当GNeXtVLAD模型采用多尺度采样策略并设置λ1=32、λ2=128时能在相同batch_size下减少一定的显存占用。GNeXtVLAD模型由于特征提取网络只需要前向传播而不需要计算梯度,在训练时大大减少GPU计算量和显存。
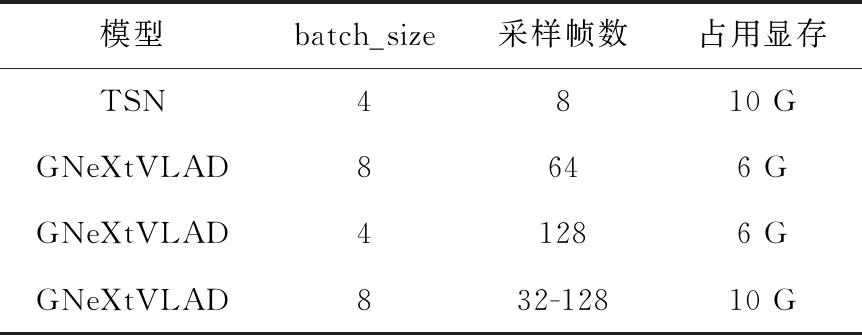
表5 TSN模型与本文模型训练占用显存大小对比
4 结束语
本文主要针对不同于行为动作识别数据集的VideoNet-100数据集进行研究,对NeXtVLAD算法进行改进并提出一个多尺度的采样策略,设计出一个端到端训练的视频分类模型。VideoNet-100数据集中视频时长较长,需要采样大量帧才能更好表达视频信息,而当前主流的基于深度学习的视频分类模型在采样帧数过大时需要庞大的计算资源才能进行训练。本文模型在训练时不需要对特征提取网络进行训练从而节约大量计算资源,解决了在计算资源有限的情况下采样帧数与计算资源之间的矛盾。本文在VideoNet-100数据集上进行对比实验,验证了本文所设计模型的有效性,在VideoNet-100数据集上达到了92.5%的准确率。本文方法在VideoNet-100数据集上采样帧最多达到了128帧,从而导致在训练和推理阶段需要花费大量时间在视频预处理上,下一步的研究工作就是探索新的特征融合网络,在少量采样帧的情况下得到良好的视频级特征进行分类输出,提高长视频分类准确率。
