基于排队时延主动探测的多路传输拥塞控制
2021-03-23赵静静衷璐洁
赵静静,衷璐洁
(首都师范大学 信息工程学院,北京 100048)
0 引 言
不同于传统TCP,MPTCP[1]是一种端到端的多路通信,它将一条数据流划分为多条子流,通过多条链路同时进行传输实现吞吐量提升。在无线移动网络不断进步的今天,智能手机终端普遍同时支持LTE和Wi-Fi[2]。针对MPTCP与TCP资源共享公平性问题,需要将子流往返时延不同的情况纳入考虑,根据各子流RTT的不同情况来控制拥塞窗口变化速度。同时,应充分考虑子流间拥塞程度差异,避免在子流间出现跳跃引起链路抖动问题,而通过对RTT进行主动探测,在数据流未拥塞至丢包状态时即实施拥塞控制,调整拥塞窗口大小,可有效减少分组丢失,对此,本文提出PPQD拥塞控制算法。通过在每条链路上使用一个窗口强度增长控制因子,实现各子流拥塞窗口的适时动态调整,避免拥塞窗口大波动的出现,提高链路带宽利用率。
1 相关工作
1.1 MPTCP设计要求
目前,MPTCP的多路径特性对拥塞控制算法提出了新的要求,对此IETF工作组在制定MPTCP规范时对吞吐量、公平性及拥塞控制等方面提出了几点要求请参见文献[3]。
1.2 MPTCP公平性
针对如何利用多条可用路径进行高效数据传输的问题,直接的方案是对已有单路径传输控制协议[4]进行功能上的扩展,即针对每条可用路径上的各条子流,都独立地执行单路径传输控制协议。但由于n条子路径的多路径流占用的瓶颈带宽一般为单路径流的n倍,当瓶颈带宽几乎完全被多路径流霸占时,就会产生单路径流带宽饥饿现象,这样的情形会引发公平性问题。
目前关于多路径公平性的相关研究中,Uncoupled的算法思想请参见文献[4],该算法在当这些子流共享同一瓶颈带宽时,会表现出较为严重的侵略性,令网络环境恶化。C.Raiciu等[5]提出的LIA算法,根据拥塞窗口大小wr、 总拥塞窗口大小wtotal和侵略因子α的值来动态分配各子流的拥塞窗口,实现了子流侵略性避免的动态控制。在该算法中,侵略因子考虑各子流RTT不相等的情况,用1/wr来控制拥塞窗口增长的上限,可有效制止各子流抢占更多的TCP链路流量,保障瓶颈链路上公平的带宽竞争。但LIA算法在子流拥塞程度差异不大时,会产生子流间的跳跃现象,引发“抖动性”问题。因此,提前探知网络状态减少拥塞窗口的抖动是提升吞吐量性能的重要前提。
1.3 基于时延的MPTCP拥塞反映机制
拥塞反映机制是拥塞控制研究中的重要环节。传统基于丢包作为网络拥塞的信号反映不够及时[6,7],而RTT更具可变性,反应也更为灵敏[8]。Brakmo等[9]提出一种单路径TCP拥塞控制算法TCP Vegas,通过测量链路RTT来进行拥塞区分。该算法在RTT变大时,认为网络拥塞发生,随后开始减小拥塞窗口,当探测到RTT减小时,认为网络拥塞逐步解除,当前链路传输性能转好,于是增大拥塞窗口提高发送速率。Cao等将Vegas的思想引入至MPTCP中,提出了基于时延的MPTCP拥塞控制算法w Vegas(weighted Vegas)。w Vegas算法思想请参见文献[10]。对于存在缓存、RTT增大的网络环境,w Vegas算法仍会在网络未拥塞的情况下降低相应子流的拥塞窗口,而由于网络未拥塞,单路径TCP不会降低自己的拥塞窗口,如此反复,w Vegas会引起带宽竞争力下降,传输效率也会随之受到影响。
2 基于主动探测排队时延的MPTCP拥塞控制方法(active detection of queuing delay,PPQD)
在无线移动网络场景中,一个移动用户可同时通过Wi-Fi和4G等多种方式访问互联网。发送端(sender)和接收端(receiver)之间传输数据的往返时延RTT计算方法请参见文献[11]。
图1给出了在无线移动网络场景中MPTCP的一条链路i从连接到接收ACK确认的过程。其中,Qd,i(t) 和Pd,i(t) 分别表示t时刻数据在路由器缓存的排队时延和系统处理时延;Td,i(t) 表示t时刻数据在链路i上的传播时延;d为往返时延。
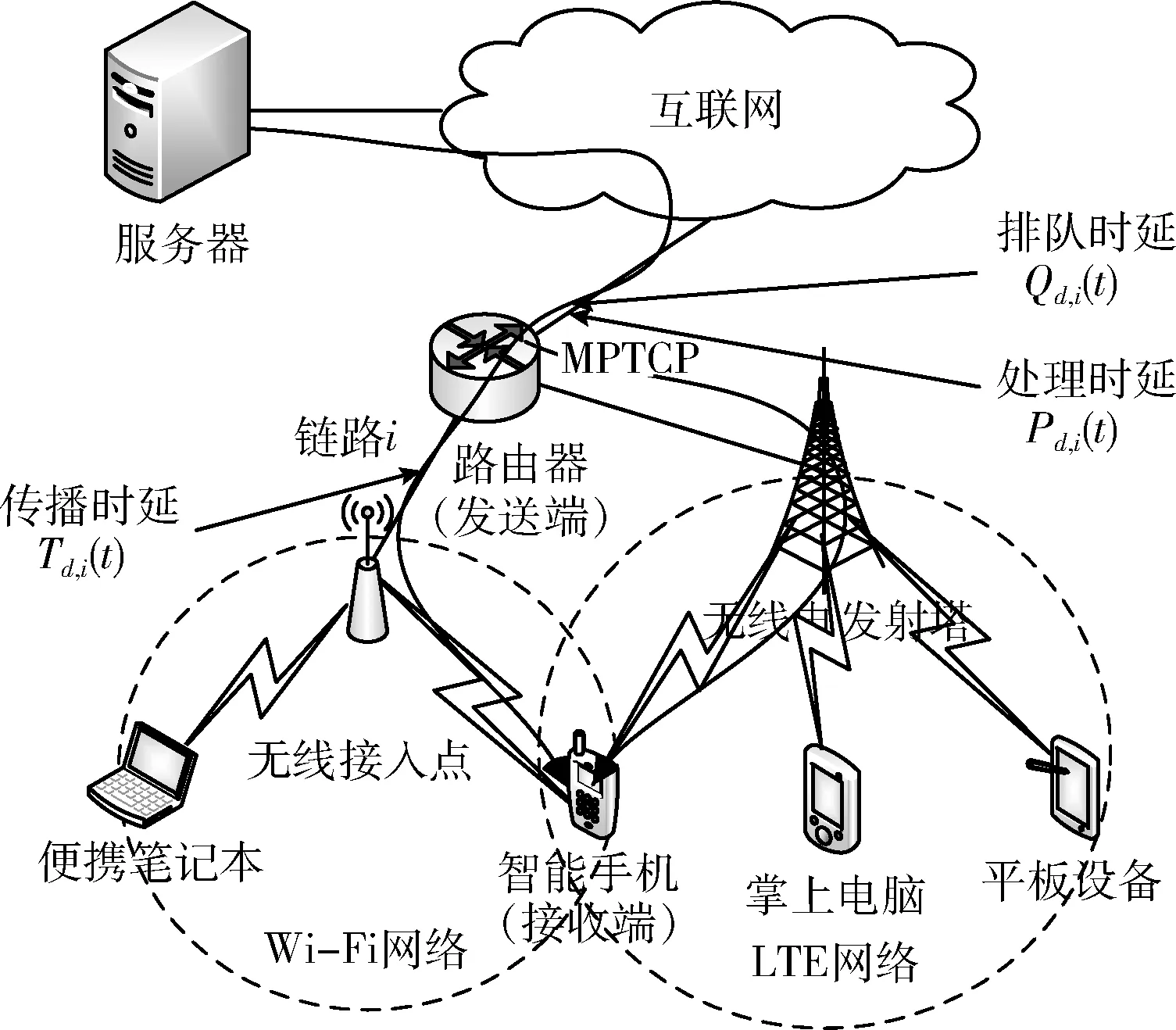
图1 链路i上的数据传输时延
定义1 前向时延(the forward delay,FD):假定子流s上数据从发送端S流经了n-1个路由达到接收端R,t时刻前向时延记作FD(t),如式(1)所示
(1)
定义2 后向时延(the backward delay,BD):假定子流s上数据从接收端S通过m-1个路由器将ACK反馈给发送端R,t时刻后向时延记作BD(t),如式(2)所示
(2)
往返时延RTT由前向时延及后向时延组成,如式(3)所示
RTT(t)=FD(t)+BD(t)
(3)
在不考虑路由改变的情况下,网络中排队时延可以用来感知网络拥塞的状态。为了计算链路的排队时延需先计算往返时延RTT。对此,本文提出将TCP Vegas基于时延的拥塞窗口动态调整方法与MPTCP融合,设计并实现了基于主动探测排队时延的MPTCP拥塞控制方法PPQD,方法框架如图2所示。PPQD方法采用二次指数平滑预测法对往返时延实施平滑预测,然后根据往返时延预测排队时延,以排队时延与其均值的比较结果反映网络拥塞情况,并据此指导拥塞窗口的动态调整。
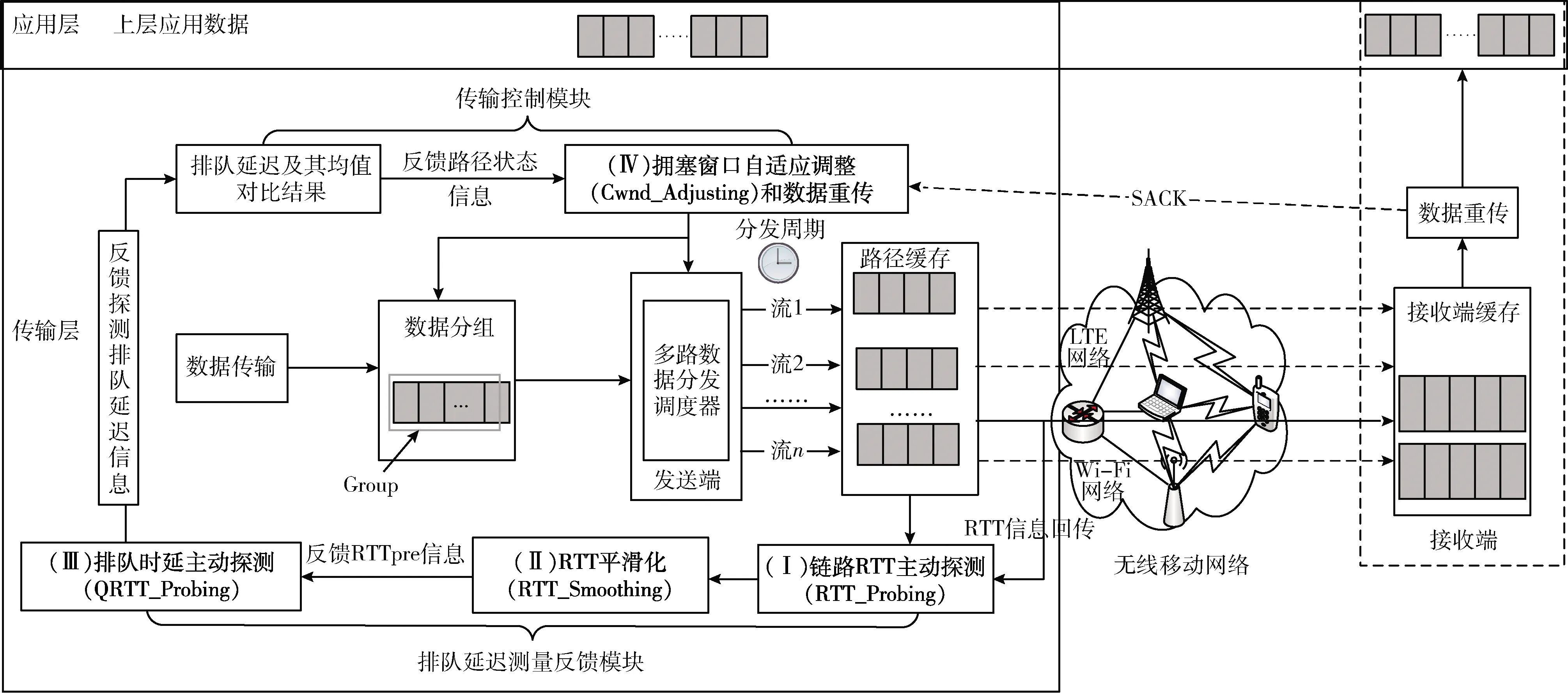
图2 PPQD整体框架设计
基于主动探测排队时延的MPTCP拥塞控制(congestion control based on proactive probing of queuing delay,PPQD)方法由:(Ⅰ)RTT主动探测(RTT_Probing);(Ⅱ)RTT平滑处理(RTT_Smoothing);(Ⅲ)排队时延主动探测(QRTT_Probing)及(Ⅳ)拥塞窗口自适应调整(Cwnd_Adjusting)几个部分组成。其中,RTT_Probing主要负责主动探测链路RTT信息的提取,主要实现方式为:开启时间戳,记录数据包发送及到达时间对RTT信息进行主动探测;RTT_Smoothing主要负责平滑预测链路RTT,实现RTT平滑化,并在对RTT完成平滑处理后,将二次指数平滑后的值RTTpre反馈给QRTT_Probing;QRTT_Probing主要负责主动探测链路排队时延信息的提取,通过计算缓冲区中数据包数量和链路带宽,对排队时延信息进行求解预测,然后将排队时延与通过RTT均值计算出的排队时延均值进行对比来提前探测链路状态,并反馈链路状态信息给Cwnd_Adjusting;Cwnd_Adjusting则主要负责完成拥塞窗口的自适应调整,使用一个窗口强度增长控制因子,动态调整每一条链路的拥塞窗口。
3 方法描述
3.1 链路RTT主动探测(RTT_Probing)
提前探测排队时延信息,需要主动探测链路RTT,RTT_Probing模块使用基于时间戳的主动探测方法。首先向MPTCP网络注入一定长度的探测包并设置一个时间戳,然后等待来自于接收端的响应。通过计算探测包的到达时间与发出时间差值获取链路响应时间。在此过程中,为更准确地获取链路RTT,需要将发送端发送对应ACK前所消耗的响应时间纳入考虑。图3给出了考虑发送端响应时间的RTT主动探测过程。图中T1表示发送端发送探测包的时刻;T2表示接收端接收探测包的时刻;T3表示发送端接收到探测包及ACK到发送对应的ACK前所消耗的时间段,即发送端的响应时间;T4表示发送端发送该探测包的ACK的时刻。
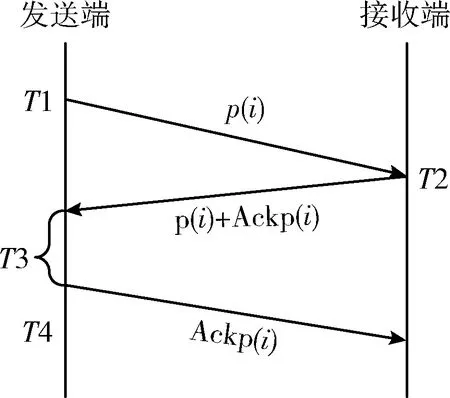
图3 考虑发送端响应时间的RTT主动探测
一个有效考虑发送端响应时间的RTT(i) 主动探测过程由一个4元组组成,RTT(i)={P,I,R,T3},其中:
(1)P是一个探测包的有限序列的集合,p(i) 是P中的第i个探测包。
(2)I是单调增函数,定义为:I∶P→S。S为发送端发送探测包的时间,I决定发送探测包到潜在的接收端的时间序列。
(3)R为所有响应包的时间戳函数,定义为:R∶P→T。T为发送端接收探测包和ACK后向接收端响应ACK的时间,R决定了发送端接收探测包和ACK后向接收端响应ACK时的带有时间戳的探测包时间序列[12]。
(4)T3(i)表示发送端接收到探测包i及ACK到发送对应的ACK前所消耗的时间段。
考虑发送端响应时间的RTT(i) 的计算方法如式(4)所示
RTT(i)=R(p(i))-I(p(i))-T3(p(i))
(4)
3.2 RTT平滑化(RTT_Smoothing)
为避免因丢包导致探测值产生大幅度的波动,保障RTT的平滑性,本文采用二次指数平滑预测模型对RTT_Probing模块获取的RTT探测值进行平滑处理。RTT平滑处理模块RTT_Smoothing主要由一次指数平滑处理和二次指数平滑处理两个阶段组成。
(1)一次指数平滑处理(RTT_Smoothing_FP)
为消除RTT探测值的短期上升或下降波动,首先对呈线性变化趋势的RTT时间序列进行一次指数平滑处理。定义RTT_Probing模块探测所得到的样本值为时间序列观测值,假设时间序列为x1,x2,…,xn(n为时间序列长度),区间[1,n]为时间序列的观测期,当时间序列的观测期n>n0时 (n0=15,经过大量实验验证,当观测期大于15时,误差较小且趋于稳定,探测精度更高),初始值对预测结果的影响很小,此时选取第一次观测值作为初始值,之后,根据链路RTT的进一步探测结果,选取BaseRTT作为平滑往返时延的初始值,BaseRTT的计算方法如式(5)所示
BaseRTT=min{RTT(i),T0}
(5)
式中:RTT(i) 由式(4)计算所得,T0为路由器缓存为空时的往返时延,也是所有观测往返时延的最小值。
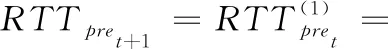
(6)
(2)二次指数平滑处理(RTT_Smoothing_SP)
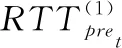
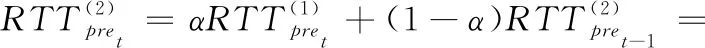
(7)
之后,计算第t+T时刻的RTT预测值
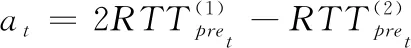
(8)
式中:α为平滑系数,T为t时刻到预测时刻的间隔时刻数。RTTpret+T预测结果由RTTpre表示。具体算法描述如算法1所示。
算法1: RTT_Smoothing
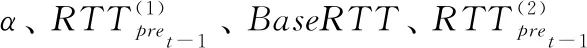
输出: 第t时刻的RTT二次平滑值
(1) for 任一MPTCP连接的子流ido
(2) if 子流i收到ACK then
(3) 获取RTT_Probing模块RTT探测值;
(4) RTT探测值进行一次指数平滑处理;
(5) RTT探测值进行二次指数平滑处理;
(6) 更新RTT序列;
(7) end if
(8) returnRTTpre;
(9) end for
其中,行(3)~行(5)完成对获取的RTT的探测值进行平滑化处理;行(6)、行(7)负责对处理后的RTT观测区间值进行更新存储;行(8)负责将计算完成后的最终平滑处理结果RTTpre传递给QRTT_Probing模块,用于排队时延的主动探测。
3.3 排队时延主动探测(QRTT_Probing)
在实时无线移动网络中,网络反馈时延的情况不可避免,传统MPTCP“加性增、乘性减”算法在执行一段时间后,各子流上的排队时延将存在巨大差异,导致周期性的振荡。为削弱反馈时延,弱化由此引起的振荡,本文提出采用排队时延的平滑预测值而不是实测值来驱动拥塞控制算法。考虑到数据传输过程中数据包的发送、询问、响应等一系列动作都与链路排队时延相关,而排队时延均值相较于最大排队时延及最小排队时延具有相对稳定,可更好反映网络性能优势,故在排队时延主动探测模块QRTT_Probing中将包含链路排队时延探测值计算、RTT均值计算以及排队时延均值计算等3个部分。
(1)排队时延探测值计算
链路i的排队时延主动探测值QueuingDelaypre计算方法如式(9)所示
(9)
式中:B表示当前占用缓冲区的大小为D的数据包数量,RTTpre为经RTT_Smoothing平滑处理后的反馈值。wr表示拥塞窗口大小。
(2)RTT均值计算
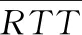
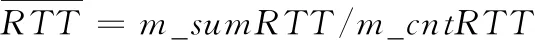
(10)
式中:m_sumRTT表示链路i从传输开始到传输结束的RTT总和,m_cntRTT表示在传输过程中RTT的增量。
(3)排队时延均值计算
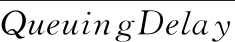
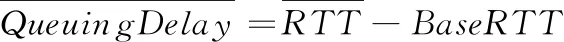
(11)
算法2: QRTT_Probing
输入: B,S,wr,RTTpre
(1) for 任一MPTCP连接的子流ido
(2) if 子流i收到ACK then
(3) 计算QueuingDelaypre;
(4) 计算RTT均值;
(5) 由RTT均值计算排队时延均值;
(6) end if
(7) returnQueuingDelaypre;
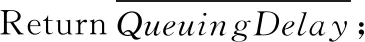
(9) end for
3.4 拥塞窗口自适应调整(Cwnd_Adjusting)
MPTCP拥塞控制通常采用“加性增、乘性减”的策略对拥塞窗口wr进行调整,采用各个子流独立进行拥塞控制的原则,依照各个子流传输情况,当收到接收端响应的新的ACK消息,其对应子流的wr将呈线性增加,当收到3个重复的ACK消息后,触发拥塞控制算法,调整子流wr按比例减少。这种策略聚合每条子流的可用带宽,当MPTCP多路径流与TCP单路径流同时使用某网络资源时,MPTCP流占用的容量应不多于TCP流所占用的容量,以保证MPTCP的公平性要求。但各子流的时延由于wr的调整会出现巨大差异,导致周期性的振荡发生,令有效吞吐量急剧下降。
为了削弱因为时延差异所引起的链路震荡,提升MPTCP的有效吞吐量,本文提出一种基于排队时延主动探测的拥塞控制策略,在每条链路上使用一个拥塞窗口强度增长控制因子δ(δ取经验值0.9),并根据链路拥塞程度实施拥塞窗口的自适应调整。
若排队时延探测值大于排队时延均值,即使发送端没有收到3次重复的ACK,也会实施相应的拥塞窗口减小策略。若排队时延的探测值小于排队时延均值,实施拥塞窗口自适应调整策略,动态增加拥塞窗口。具体方法如下:

(12)
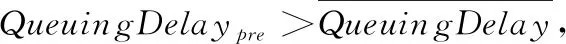
(13)
其中,wr表示拥塞窗口大小,wr+1表示下一时刻的拥塞窗口值,1/wr用来控制拥塞窗口增长的上限,确保与TCP流之间的公平性,wtotal表示所有子流实时拥塞窗口之和,α表示控制MPTCP流对TCP流侵略性的常量因子,定义如下
(14)
算法具体描述如算法3所示。
算法3: Cwnd_Adjusting
初始化:BaseRTT
输出: 完成拥塞窗口的自适应调整
(1) for 任一MPTCP连接的子流ido
(2) if 子流i收到ACK then
(3) //对比预测排队时延及其均值
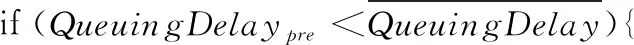
(5) //则判断链路无拥塞,增加拥塞窗口:
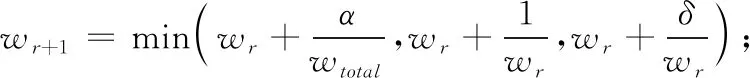
(7) }else
(8) {//则判断链路拥塞,减小拥塞窗口:
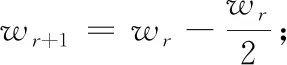
(10) }end if
(11) end if
(12) end for
其中,行(2)、行(3)负责子流i收到ACK后的预测排队时延及其均值的对比;行(4)~行(7)根据排队时延预测值及其均值的对比判断结果实施拥塞窗口的增加策略;行(8)~行(10)负责实施拥塞窗口的减小策略。
4 实验结果及分析
4.1 实验参数设定
本文实验环境为Intel(R) Core(TM) i7-4790 CPU @ 3.6 GHz,搭载8 GB内存,操作系统使用Ubuntu16.04,仿真实验平台采用NS-3,实验拓扑及参数设定如图4所示。
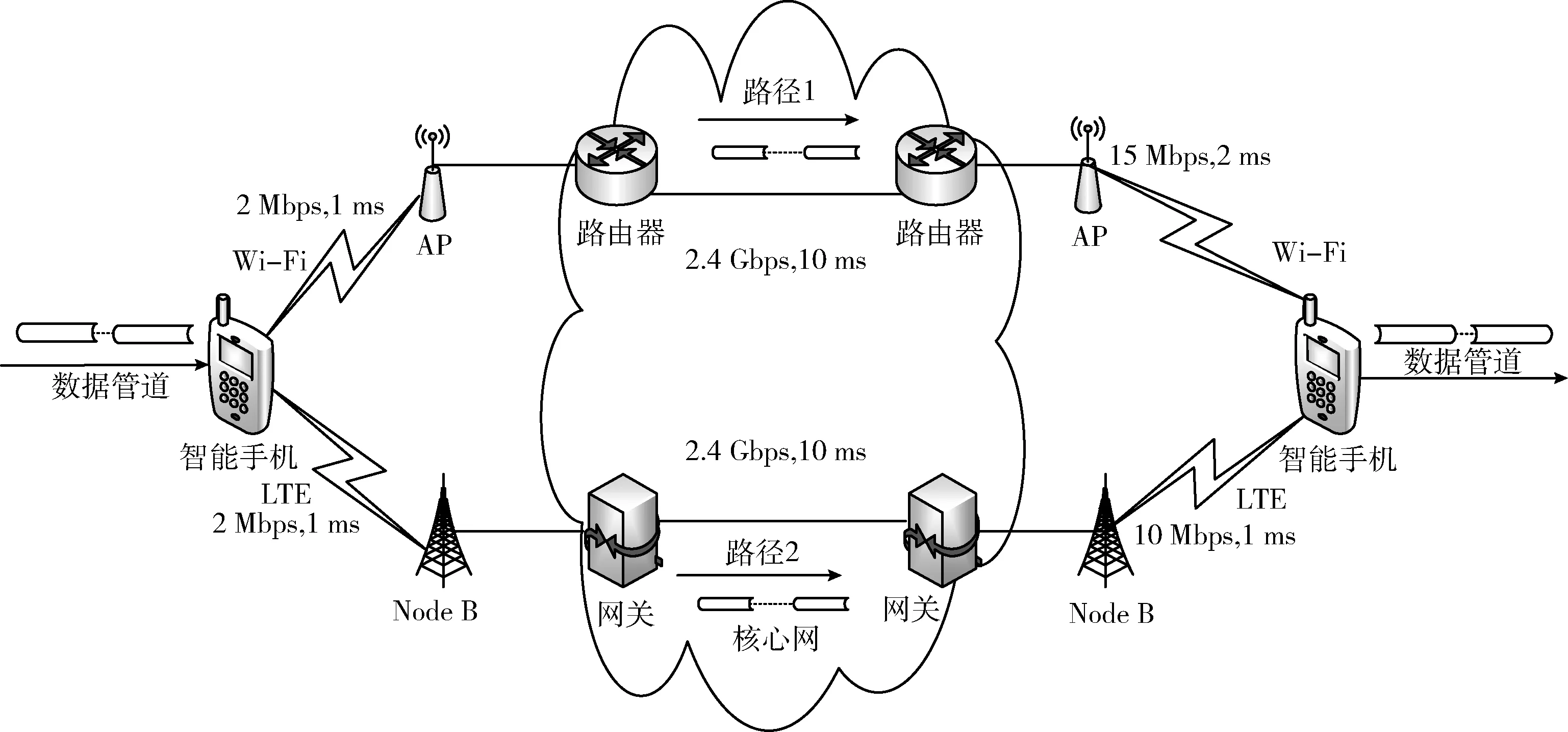
图4 实验拓扑及参数
实验拓扑包含双接口的手机终端,采用Wi-Fi和LTE双路径进行并行传输,其中:路径1上的平均带宽设置为15 mbps,2 ms的传播时延,路径2上的平均带宽设置为10 mbps,1 ms的传播时延。仿真中有线链路的带宽设置为2.4 Gbps,时延设置为10 ms,分组大小固定为1000 Byte。实验以FTP业务数据传输为例,仿真覆盖慢启动、拥塞避免及快重传阶段,以1 s为单位实施拥塞窗口及时延统计。
4.2 实验数据分析
4.2.1 链路状态评估
在无线移动网络中,时延是一项重要的网络服务质量性能指标。对连续的实时应用而言,时延方差大小可以作为链路状态评估的指标,时延方差越小链路状态越好。本文选取LIA和Uncoupled作为比较对象,对多路径链接下的时延方差进行了对比,如图5所示。其中,PPQD算法的时延方差为7 896 490.816;LIA算法的时延方差为7 903 261.904;Uncoupled算法的时延方差为7 900 358.802。相较于LIA和Uncoupled算法,由于RTT的提前探测和平滑化处理,PPQD算法可更好地减弱RTT振荡,抑制RTT波动。
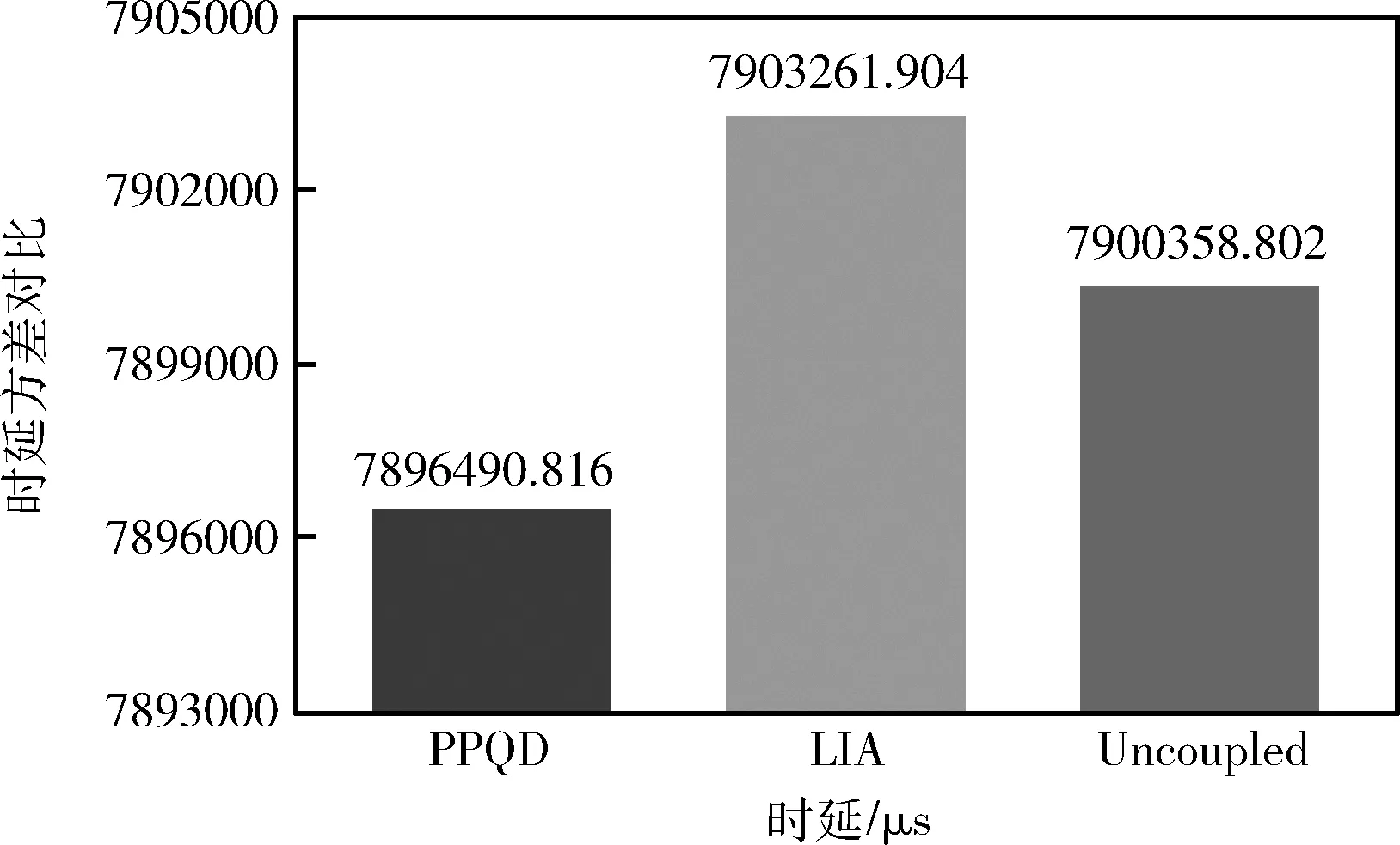
图5 RTT方差对比
4.2.2 公平性评估
图6给出了网络共享瓶颈场景的相关设置。其中,S1、S2代表数据发送端,F1、F2代表多路径两条子流;单路径流TCP和两条子流共享一条瓶颈路径;瓶颈路径带宽B设置为15 Mbps;时延D设置为2 ms;丢包率P设置为0.1%。3条路径同时进行数据传输。
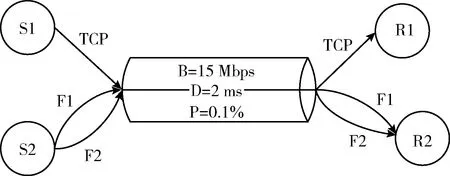
图6 共享瓶颈场景
图7给出了共享瓶颈处TCP流及两条PPQD子流PPQD-F1和PPQD-F2的吞吐量数据。其中,TCP单路径流平均吞吐量为7.52 Mbit/s,PPQD-F1和PPQD-F2多路径流的平均吞吐量为7.49 Mbit/s。MPTCP各子流的平均吞吐量与TCP单路径流的平均吞吐量接近,相差甚微。
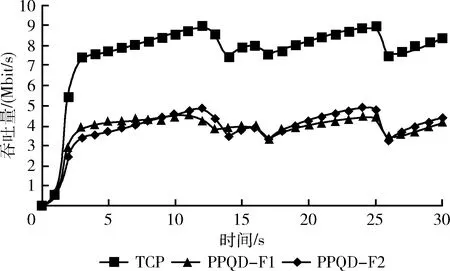
图7 共享瓶颈处TCP流和PPQD子流吞吐量
此外,本文还分别统计了PPQD、LIA和Uncoupled这3种算法的多路径连接吞吐量数据,如图8所示。其中,PPQD算法所获得的平均吞吐量为6.58 Mbps,LIA算法所获得的平均吞吐量为5.17 Mbps,PPQD算法的平均吞吐量性能优于LIA算法。与此同时,Uncoupled算法平均吞吐量为10.63 Mbps,占用了约70.8%的带宽容量,相较于LIA算法和PPQD算法,该算法在共享瓶颈处表现出了较强的侵略性。
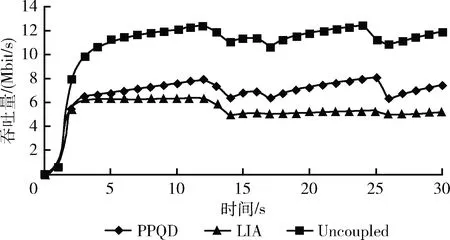
图8 实时吞吐量
4.2.3 网络性能评估
(1)丢包后吞吐量变化
在表1中给出了PPQD、LIA和Uncoupled在发生链路丢包前后的实时吞吐量数据。其中,在[14 s,16 s]区间内,PPQD算法的实时吞吐量从6.4 Mbps增加至6.82 Mbps,增量为6.56%,LIA算法的实时吞吐量从4.9 Mbps变化为5.01 Mbps,增量为0.11%,Uncoupled算法的实时吞吐量从11 Mbps变化为11.32 Mbps,增量为2.9%;之后的两次丢包,PPQD算法的实时吞吐量增量分别为26.1%和17.4%,LIA算法的实时吞吐量增量分别为6.94%和4.07%,Uncoupled算法的实时吞吐量增量分别为6.18%和9.22%。相较于LIA算法和Uncoupled算法,PPQD算法表现出了更好的网络状态应对及性能恢复能力。
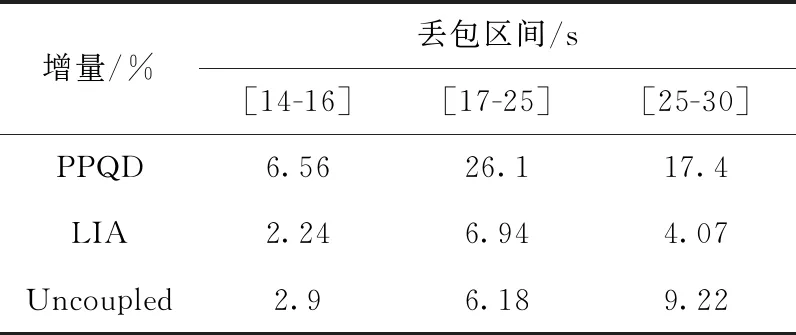
表1 链路丢包后实时吞吐量增量
(2)拥塞窗口变化
拥塞窗口在MPTCP建立新的连接和慢启动阶段的原理请参见文献[13],当网络发生拥塞进入拥塞避免阶段后,拥塞窗口会迅速减小,当数据包超时时,重新进入慢启动,拥塞窗口会慢慢恢复。
在数据传输过程中,PPQD算法的实时拥塞窗口整体大于LIA算法和Uncoupled算法。如图9所示,在12.6153 s,15.7773 s和24.9913 s时链路发生丢包现象,各算法的拥塞窗口及吞吐量均有所下降。在12.6153 s到15.7773 s的时间区间内,PPQD算法的拥塞窗口从72 285 bit上升至85 615 bit,增量为13 330 bit;Uncoupled算法的拥塞窗口从67 519 bit上升到74 659 bit,增量为7140 bit;LIA算法的拥塞窗口从62 753 bit上升至65 182 bit,增量仅为249 bit。第2次丢包发生后,PPQD算法的拥塞窗口增量为24 146 bit;Uncoupled算法拥塞窗口增量为14 121 bit;LIA算法拥塞窗口增量仅为5049 bit;第3次丢包发生后,PPQD算法的拥塞窗口增量为17 253 bit;Uncoupled算法的增量为10 306 bit;LIA算法的增量仅为3360 bit。总体而言,PPQD算法表现出了较Uncoupled算法和LIA算法更强的拥塞窗口调节能力。
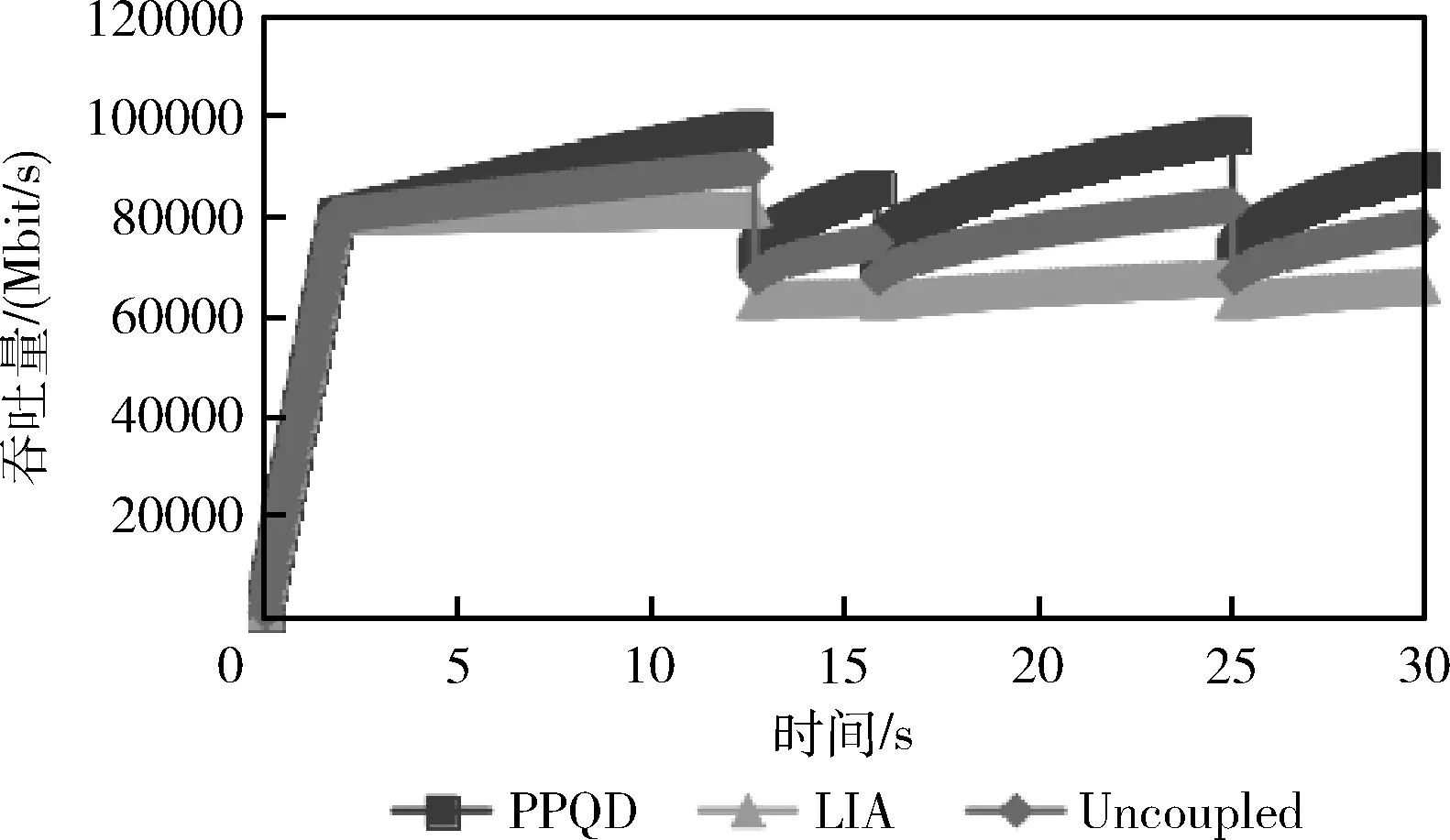
图9 拥塞窗口变化
5 结束语
本文针对多路传输中因网络拥塞所引发的排队延迟导致的分组延迟抖动及公平性问题,提出一种基于排队时延主动探测的拥塞区分链路质量优化协议PPQD,以满足多路径流公平性为基础,实施链路RTT主动探测,以排队时延预测结果及其均值比较为依据提前探知网络状态,并相应实施拥塞窗口动态调整,以解决链路抖动问题。仿真实验结果表明,PPQD相较于LIA和Uncoupled能够更好地实现TCP单路径流和多路径流在共享瓶颈处可用带宽的公平分配,减少时延抖动,提升吞吐量。
