基于大数据挖掘技术的地震舆情感知研究
2021-03-23李姗姗孙晓玲袁国铭
李姗姗, 孙晓玲, 袁国铭
(1. 防灾科技学院信息工程学院, 河北 三河 065201; 2. 防灾科技学院智能信息处理研究所, 河北 三河 065201)
0 引言
随着移动互联网的广泛应用与“两微一端”的普及,涌现出许多新形式的社交媒体,包括微博、微信、博客、论坛和社交网站等[1-3]。社交媒体的出现彻底改变了人们获取信息和传播信息的方式。在不同形式的社交媒体中,微博以其新型的社交方式,广大的用户基础以及多媒体技术的融合,成为当今信息产生和传播的重要平台。
在这一新形势下,在破坏性地震发生后,大量网友涌入新浪微博,表达个人观点、态度和情感等。大量与地震相关的信息在新浪微博发布并广泛传播,汇集成海量数据。这些数据含有非常宝贵的第一时间信息,如包含震感、房屋破坏、人员伤亡情况和地震地质灾害等大量的图、视频和文字的地震舆情及灾情信息。这些信息对灾情信息的快速获取、定位、处理、分析和研判起到至关重要的作用。但舆情数据中也有消极负面的信息,它们能迅速扩散并造成震区恐慌情绪蔓延,严重影响社会秩序。如何从海量数据中挖掘出潜在有效信息,对于政府进行舆情的监测、引导和舆情处置等有着十分重要的意义。
然而,传统人工分析的方式,已经无法应对当下实时的不断暴涨的海量震后舆情。因此,对地震后海量舆情进行实时监测、情感倾向挖掘分析和准确预警迫在眉睫。
目前,有一些学者开始了此项研究。杨顺达等都对涉震舆情的演化机理进行了研究[4]; 邓月飞等对云南通海、巧家MS5.0 地震舆情的引导进行研究[5]。崔满丰等对地震网络舆情监测与应对机制进行研究[6]。李俊磊研究了将大数据技术应用到网络舆情信息监测和感知中[7]。这些研究都认识到了地震舆情研究的重要性,但是他们主要关注的是策略和机制,并未对实现技术进行探讨。技术层面的研究比较少。李亚芳等基于新浪微博大数据,运用网络爬虫技术,获取新疆伽师6.4级地震后48h新浪微博相关的博文和评论,进行了舆情信息的可视化研究[8]。但是仅做了数据可视化,尚未实现舆情的情感分析和预警等功能。
当前,新兴的大数据技术和深度学习成为处理和挖掘分析海量数据的一大利器。本文主要从技术层面进行研究,提出构建一个基于Word2vec和LSTM融合模型的集地震舆情数据抓取,监测、处理分析、挖掘建模和预测预警为一体的地震舆情感知平台。通过大数据技术搭建分布式计算和存储平台,实现对舆情数据的全天候抓取、监测和存储。通过Word2vec和LSTM融合模型对以往的历史数据进行训练建模,并用该模型来对舆论的情感倾向性进行预测,为舆情的预警提供支持,从而提供全方位的舆情服务。通过与传统深度学习模型进行对比实验,验证了本文提出的Word2vec和LSTM融合模型在地震舆情情感识别中具有更高的精确率。
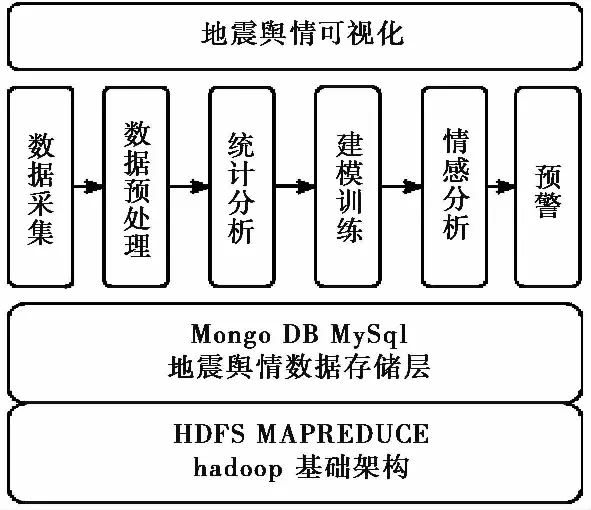
图 1 地震舆情感知平台模型Fig.1 The model of earthquake public opinion perception platform
1 地震舆情感知平台模型
本文采用大数据技术和深度学习技术设计提出了一个地震舆情感知平台模型,如图 1所示。模型的层次结构为:(1)Hadoop基础构架层。采用Hadoop[9]搭建大数据分布式计算平台,实现对海量舆情数据的处理和分析,为上层地震舆情存储层提供操作接口。(2)地震舆情数据存储层。采用MongoDB[10]实现对实时海量监测数据的分布式存储; 采用MySql对历史数据和处理分析结果进行存储。(3)数据采集处理分析层。本层完成从数据采集到数据预处理、统计分析、建模训练、情感分析和预警整个流程,并为上层地震舆情可视化层提供接口。数据采集模块采用Scrapy框架爬取微博中地震热点信息、地震博文的评论信息和评论用户信息等数据。数据预处理模块对爬取到的数据进行清洗、文本分词,以及预训练模型生成词向量,为后续模型的输入提供支持。统计分析模块实现地震舆情走势、用户行为、热词和传播等多维度统计分析。建模训练模块采用LSTM构建深度神经网络模型。情感分析模块基于已经训练好的情感分析模型对爬取到的舆情数据进行自动情感分类。预警模块将情感分析结果为负面的舆情与敏感词库进行比对,敏感度超过80%将触发报警,引发关注。(4)地震舆情可视化层。本层采用Boostrape4.0框架构建,使用Echarts加载和渲染数据,提供地震舆情概况分析、传播分析、舆论聚合和用户画像等可视化功能。
2 数据采集
以微博热搜为起点,从数据库获取经过筛选的热搜关键词,将其添加到分布式队列中等待爬取。以爬取结果为中心对评论及评论用户信息进行全天候,多维度循环深入爬取,将爬取结果保存到MongoDB数据库。针对微博结构复杂、数据量大的特点,本文使用Scrapy框架进行数据爬取,采用基于广度优先策略的聚焦网络爬虫,抓取与地震主题匹配更高的网页。
3 数据预处理3.1 数据清洗
使用分布式爬虫抓取到的地震舆情短文本数据中包含大量脏数据,比如无意义的html标签、特殊词、符号、表情和URL等。采用文本去重法和机械词压缩法清洗这些脏数据:(1)文本去重。采用python语言及pandas库的unique方法删除完全重复的数据。(2)机械压缩去词。某些文本自身存在大量机械重复的语料,如“加油加油加油!”。通过创建两个存放国际字符的列表来完成。读取国际字符,将其放入相应的国际字符列表,若触发压缩规则,则进行列表清空压缩去重。
3.2 文本分词
分词结果的准确性会影响到后续特征的选择,进而会对舆情文本数据的分析和建模挖掘产生巨大的影响。英文基于语法的特点,词语间有空格作为明显的分隔符。而中文中的词语长短不一,边界模糊,处理难度较大。本文采用jieba[11]进行分词。jieba分词基于统计词典,构造一个前缀词典。然后利用前缀词典对输入句子进行切分,得到所有的切分可能,根据切分位置,构造一个有向无环图。通过动态规划算法查找最大概率路径,找出基于词频的最大切分组合。对于未登录词,采用基于汉字成词能力的HMM模型训练模型自动发现新词,并对词典库进行更新。
3.3 预训练模型
分词后的数据仍然为文本数据,而模型的输入是数据元组。因此,需要将每条数据的词语组合转化为一个数值向量,即词向量。常见的转化算法有BOW、TF-IDF和Word2vec[12]。BOW根据词典中对应词在文档中出现的次数构建向量。这种方法会产生“词汇鸿沟”现象,忽略了词语间的语法和顺序,无法了解词语间的关联程度。TF-IDF以词语出现的频率为权重构建向量。如果某个词在一篇文章中出现的频率高,且在其他文章中出现的频率低,则认为其具有很好的类别区分能力,赋予其更高的权重。这种方法单纯以词频作为单词重要性度量,对位置没有敏感性。Word2vec采用神经网络语言模型,将每个词输入到神经网络模型中进行训练,生成一个实数向量。一般分为两种模型:CBOW和Skip-Gram。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。Skip-Gram正好相反,它的输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
4 神经网络训练模型
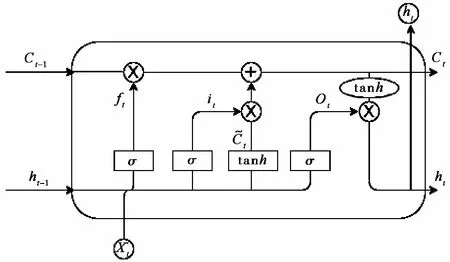
图 2 LSTM 基本结构Fig.2 The basic structure of LSTM
地震舆情数据是自然语言处理中的时序数据,需要考虑词与词的前后顺序。循环神经网络(RNN)[13]是一种常用于处理序列数据的神经网络。然而传统RNN仅有一种记忆叠加方式,网络会遇到梯度消失问题,使学习和调整网络之前层的参数变得非常困难,在实际中很难处理长期依赖。长短期记忆人工神经网络LSTM[14-15]能够很好地解决这个问题。它通过门控状态来控制传输状态,记住需要长时间记忆的信息,忘记不重要的信息。如图 2所示,它包含三个门:输入门、遗忘门和输出门。输入门决定有多少信息可以流入当前细胞,遗忘门决定细胞有多少信息会被遗忘,输出门决定细胞内多少信息被输出。
(1)遗忘门。它读取前一个输入ht-1和当前输入xt,通过sigmoid层为细胞上一个状态Ct-1中的每个数字输出0和1之间的数字。1代表完全保留,而0代表彻底删除。计算公式为:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
(2)输入门。Sigmoid层决定哪些信息需要更新,产生it,见式(2)。tanh层根据前一个的输出值ht-1和当前的输入值xt产生一个新的候选值向量,见式(3)。两部分联合实现对一个细胞状态的更新。
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(3)输出门。通过sigmoid层确定细胞状态的输出部分。通过tanh进行处理并将它和sigmoid门的输出相乘,最终确定输出部分。计算公式见(4)、(5)。
Ot=σ(Wo·[ht-1,xt]+bo)
(4)
ht=ot*tanh(Ct)
(5)
整个过程类似流水线,实现信息的加工处理。前一个状态Ct-1输入以后会经过遗忘和添加新的内容,最终输出新的状态到下一个细胞。

图 3 地震舆情感知平台实验床Fig.3 The experimental bed of earthquake public opinion perception platform
5 实验及分析
5.1 数据采集与统计分析
基于以上技术分析要点和设计方案,本文初步实现了一个基于大数据挖掘技术的地震舆情感知平台实验床“掘微舆情1.0”,其界面如图 3所示。该平台可实时监测分析地震相关舆情。在该实验床上,以2020年12月10日21时19分在台湾宜兰县海域(24.74°N, 121.99°E)发生的5.8级地震舆情数据为例进行测试。系统后台的分布式爬虫采集了地震发生后40h内476237条微博舆情数据,构建了此次地震事件的脉络及传播矩阵。数据量随时间波动如图 4所示,反映了地震发生后舆情的走势。在第二天早上10点左右达到高峰,数据量达到24800。随着时间推移,舆论热度逐渐消退。

图 4 2020年12月10日台湾地震后40h舆情走势图Fig.4 The trend of public opinion for 40 hours after the earthquake in Taiwan on Dec.10, 2020
5.2 数据预处理
基于前文提出的数据清洗方法进行数据清洗,去除了大量html标签、特殊词、符号、表情、URL以及重复数据后,数据规模为425674条。采用jieba进行分词,并生成词云图,如图 5所示。词云图可以对舆情形成第一印象,而不用一条条去翻阅微博,节省时间,同时也真实地展示了舆论。此外,平台还生成了此次舆情的意见领袖,倾听他们的声音有助于对舆论方向的判断。

图 5 地震舆情词云图Fig.5 WordCloud of earthquake public opinion
5.3 模型训练
为了进行后续建模和训练,我们选取经过数据清洗后的12000条数据进行试验,对其进行人工情感标注。1为积极(正向), 0为消极(负向)。将其中70%作为训练数据, 30%作为测试数据。具体过程如下:(1)采用Word2vec的CBOW模型,将训练数据所有词输入模型,获取与目标词上下文相关的前后N个词语的词向量,通过计算目标词的条件概率和最大化条件概率值预测目标词,生成词向量。(2)采用五层网络结构构建LSTM神经网络,分别为词嵌入层、LSTM单元层、dropout层、二分类全连接层和激活层。将训练生成的词向量集合输入LSTM层。为了防止过拟合,设置dropout为0.5。经过实验验证,两层的全连接层的准确率并没有较一层提高,并且逼近速度较慢,因此实验选择一层全连接层。激活函数选用Softsign。定义损失函数为二元交叉熵binary_crossentopy。使用反向传播算法,不断调整模型的参数,反复迭代,使得损失函数最小化。(3)生成情感分析模型,将模型参数导出存储。
5.4 模型评估
使用Word2vec同样生成测试集的词向量。将词向量输入到上一步训练好的情感分析模型,预测生成测试样本的情感标签。将生成的测试集样本的情感标签与人工标注进行对比,评估模型的效果。为了进一步进行模型效果评价,本文同时选用了传统CNN进行实验,模型特征同样采用词嵌入方式,一维卷积层的卷积核长度为3,共265个。
评估衡量指标包括精确率Precision,召回率Recall和两者的调和指标F1-score。通过对数据集合中的正负情感数进行统计,得出表 1中的TP、FN、FP和TN。精确率、召回率以及F1-score计算公式如下:

表 1 评价指标参数Tab.1 Evaluation index parameters
(6)
(7)
(8)
由表 2可见,在地震舆情情感识别问题中,LSTM的精确率高达93.76%。LSTM在精确率,召回率和F1-score各指标中均高于传统经典的CNN。分别选取总体数据的0.2、0.4、0.6和0.8作为训练数据集进行测试,结果如图 6所示。LSTM在训练集数据仅为40%时就已经达到90%以上的精确率,逼近速度较快。实验表明LSTM在地震舆情情感分析中有较好的效果和性能,能够对抓取到的地震舆论进行情感识别。将被分为负向情感的舆论敏感度与敏感词库进行比对,若超过最小阈值80%,则被判定为具有危害的舆论,系统将启动预警响应,发送预警消息或邮件,通知相关部门进行网络干预。
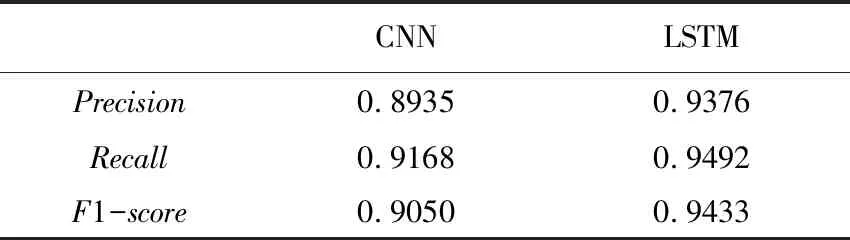
表 2 情感识别效果比较Tab.2 Comparison of emotional recognition effect

图 6 LSTM和CNN的性能对比Fig.6 Performance comparison between LSTM and CNN
6 结论
震后海量舆情数据的实时感知对于政府进行舆情的监测、引导和处置等有着十分重要的意义。本文提出的采用大数据技术和深度学习技术的地震舆情感知平台能够实现震后舆情动态分析,自动识别舆情情感,对危害性大的舆情进行预警。基于Word2vec和LSTM的融合模型在地震舆情情感识别中具有更高的精确率。地震谣言具有强烈的情感倾向,本文所构建的地震舆情情感识别模型为后续谣言的准确识别提供了强有力的支持。后续研究中,将基于本文的地震舆情情感识别模型,加入用户行为数据特征(用户画像),可进一步构建谣言模型,实现对谣言的识别。本文初步设计开发的地震舆情感知平台“掘微舆情1.0”功能在地震舆情应急处置方面有待进一步提升。
