基于GoogLeNet卷积神经网络的农业书籍文字识别*
2021-03-22陈飞昕陈振国张超伟李浩欣丁炜妮
陈飞昕,陈振国,张超伟,李浩欣,丁炜妮
(广东技术师范大学 机电学院,广东 广州 510635)
信息化是现代农业发展的一个重要方向,如何高效率地将传统纸质农业书籍转换为电子信息,成为农业信息化中的重要课题之一。当今世界计算机技术、人工智能技术[1]得到快速且蓬勃的发展,人们处理文字信息的频率也迅速提高,文字识别技术已经成为信息采集的重要方式之一。
汉字识别是一种使用相关算法及软件来提取汉字的特征,实现图像与汉字的关联[2],并与机器内预存特征进行匹配识别,将汉字图像自动转换成某种代码的一种技术。随着深度学习的崛起[3],数据成为推动深度学习技术发展的巨大助力,基于卷积神经网络的方法是现在主要研究的方法。柴伟佳,王连明[4]提出了以7层神经网络(其中3层为卷积层)对汉字字符进行识别。潘炜深等[5]则在卷积神经网络的基础上添加了基于多尺度滑动窗的方法提取文字的梯度直方图特征对汉字字符进行识别。王蕾等[6]提出一个用于特征提取的分块获胜序列模型,采用按行分块原则进行分块,多个获胜神经元有序组合的方式表征特征,模型的输出层为二维方形结构,增加了输出层神经元可以表示的类别数。代贺等[7]改进了卷积神经网络结构删减了部分全连接等并推导了前向和反向传插算法。与传统的神经网络相比,网络结构得到了有效简化,响应速度快,识别率也得到了提高,具有良好的鲁棒性和泛化性。但是由于书写风格的不同,会导致识别错误的情况。武子毅等[8]提出了基于集成注意力层的模型,将注意力放在图像的某个部位,对目标区域赋予更高的权重,注意力图与图像进行滤波处理,将AlexNet网络与注意力图进行了融合,增加了汉字图像重点区域的权重,有效弥补了神经网络丢失微小特征的不足,但是运算复杂度较高。
本文基于Matlab开发环境针对农业书籍研究了适用于复杂版面的文字识别技术,实现了图像信息的获取,进行图像预处理,包括版面分析与提取预处理以及文字与处理,将处理后的文字图像进行卷积神经网络识别,卷积神经网络的训练需要大量的样本,因此本文在卷积训练之前进行了样本数据库扩增。卷积当中采用了能够避免Dead ReLU问题的Leaky ReLU激活函数进行卷积运算,大大减少了计算时间。本文搭建了GoogLeNet网络训练结构并进行了实验测试,结果表明:在该训练网络下,文字识别具有较高准确率。
1 复杂版面的分析与处理
1.1 图像预处理
输入图像第一步需要进行图像预处理,先对图像进行灰度化、二值化处理,经过灰度化、图像阈值二值化处理后,进行拉普拉斯算子边缘化处理,最后通过图像膨胀、腐蚀运算、图像顶帽运算完成图像的预处理。其中,运用拉普拉斯算子进行的边缘处理能更好地凸显字体的细节,为提高后续神经网络训练奠定了基础。拉普拉斯算子是一种较为简单的图像处理算子,旋转不变性是它最突出的特点。对于一个二维图像函数,拉普拉斯变换为各向同性的二阶导数,定义为:
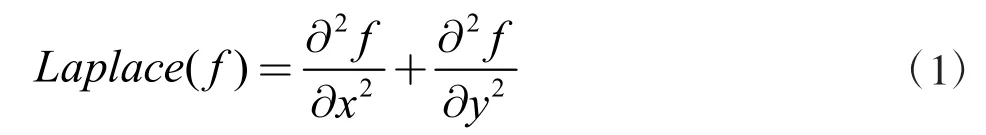
图1表示了灰度值存在的“跳跃”边缘,通过一阶微分求导,可以更加清晰地表示边缘“跳跃”的存在(峰值),如图2所示;而在边缘部分使用二阶求导会出现如图3所示情况,即在一阶导数的极值位置,二阶导数为0,但正因此本文利用该特点来作为检测图像边缘的方法。在研究过程中发现二阶导数的0值不仅仅出现在边缘,它们也可能出现在无意义的位置,但运用均值滤波可以过滤消除掉这些点。

图1 灰度值“跳跃”示意图
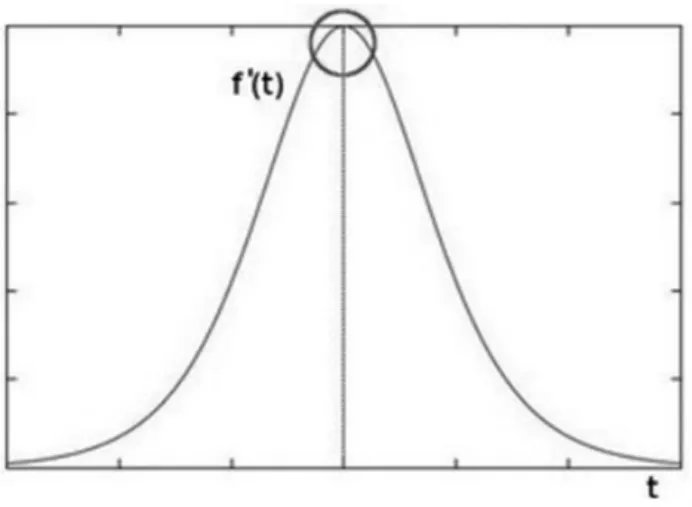
图2 求导后边缘的“峰值”示意图

图3 二阶导数位置为0示意图
为了更适用于数字图像表达,将该方程表示为离散形式:
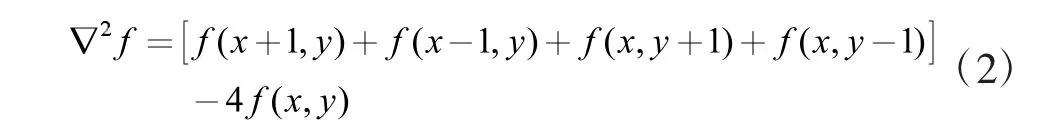
在经过一系列的文字图像预处理之后,得到理想效果(如图4所示),为后续进行神经网络训练奠定基础。

图4 文字图像预处理前后对比
1.2 版面分析与提取
版面分析的常用方法有自顶向下[2]、自底向上、非层次性或混合型等。自底向上的方法比较擅长获取文档图像的完整信息,对处理复杂版面的文档图像较为擅长,因此本文采用了自底向上的版面分析方法。自底向上版面分析方法首要的目的是获得最底层的版面信息,通过搜索文档图像的连通域来实现,获得底层信息后再通过某些约束条件将具有相同属性的连通域合并起来,可以获得整个文档图像的版面分析结果。整个版面分析方法最终能成功提取完整的版面信息,为后续的字符归类切分和字符识别奠定了基础。
基于Matlab复杂版面识别软件模块首先把预处理后的文档图像进行连通域搜索和初步的合并;提取较小和较大的特殊连通区域[9],其中,较小的连通区域作为噪声点去除,较大的连通区域看作表格或图像,再做进一步处理;剩余的连通区域为文本连通域,对其进行行、列合并使其逐步合并为文本区域,最后将识别结果再发送至版面呈现系统,便能实现文章的区分以及图像归类到相应文章(如图5所示)。
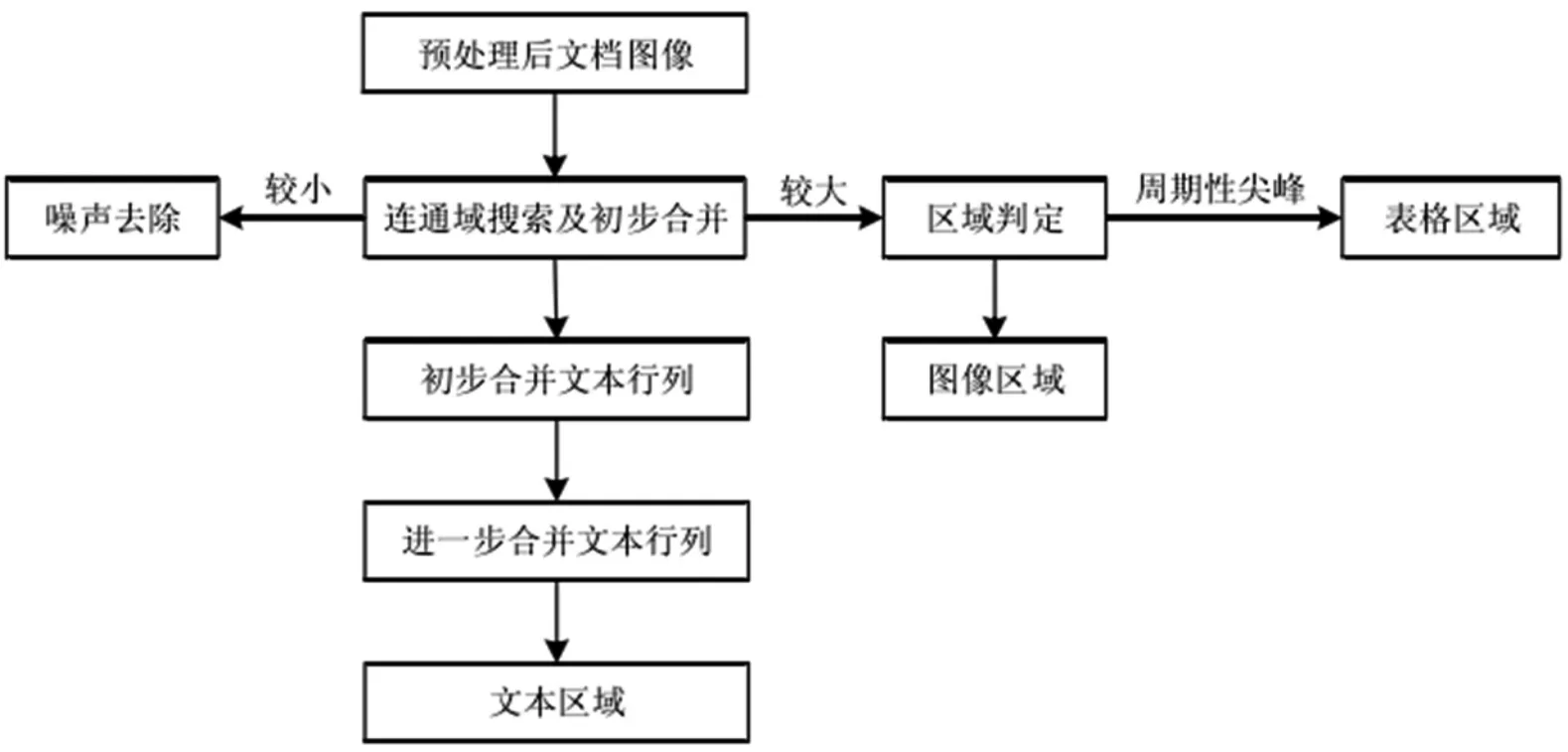
图5 版面分析原理图
2 基于卷积神经网络的文字图像识别
2.1 卷积神经网络的原理
图像识别就是对进行预处理后的图像运用算法进行识别的任务。基于结构模式识别和模板匹配识别是传统的文字识别算法中比较流行的两种算法。传统识别算法对于字符的识别存在一些缺陷,需要考虑字符的纹理特征等因素。因此本项目采用卷积神经网络的识别算法进行识别。本文构建了一个包括图像输入层、卷积层、激活函数层、最大池化层、全连接层、分类层等的卷积神经网络,用大量样本进行训练后,将该网络用来进行图像识别(如图6所示)。
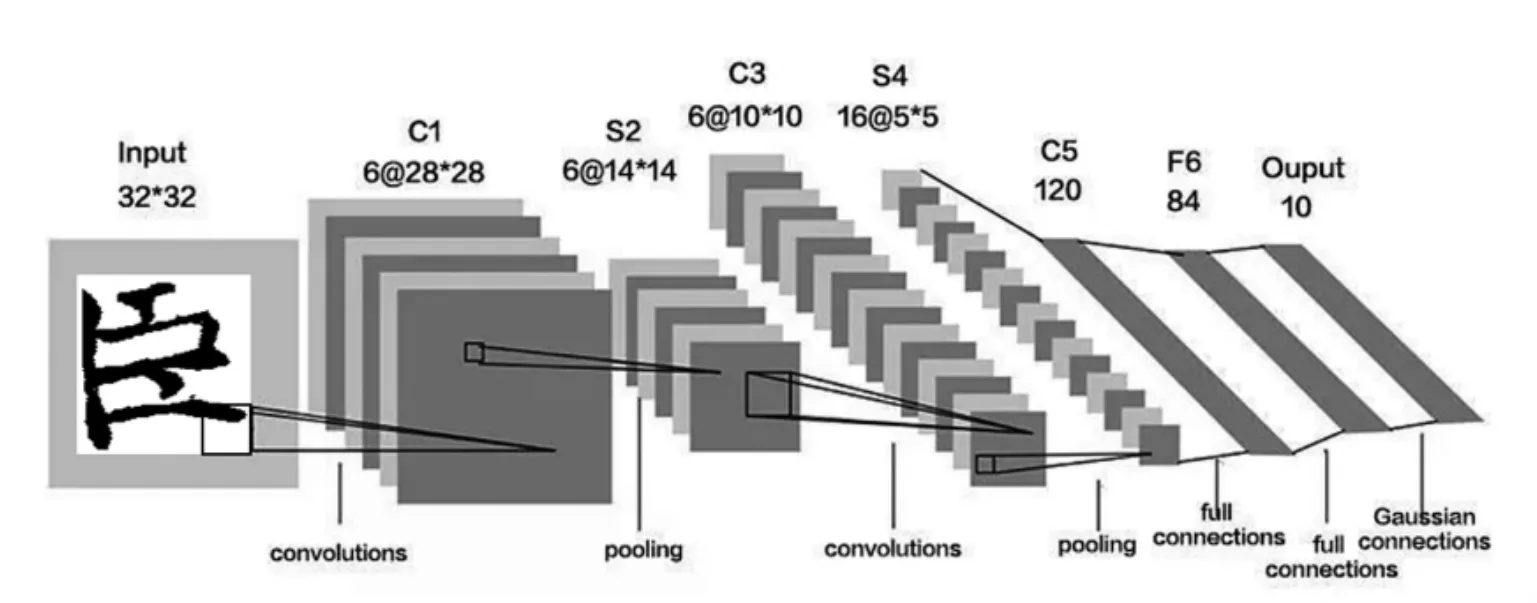
图6 卷积神经网络各个层次的连接
除此之外,为了使算法识别速率更快,有效提高对于特殊字符以及复杂文字的识别准确率,本文还针对该识别算法,进行了三种改进优化方式。
(1)样本扩增,本文采用了波纹扭曲结合平移[4]、旋转、尺度缩放的数据扩增方法(如图7所示)。

图7 样本扩增
(2)加入BN层,从而提升训练速度和精度。
(3)采用Adam和传统SGD方法相结合的训练方法[4],本文将采用Adam方法自适应调整学习率,避免手工调参,使网络快速收敛,使用SGD方法以极小的学习率在训练好的模型上进一步精调,最终达到最优的分类效果。
2.2 Leaky ReLU激活函数
激活函数在一个感知器中起着重要作用,为了增强网络的学习能力,使用的激活函数往往是一个连续且可导的非线性函数。同时为了使得训练的效率和稳定性不受到影响,激活函数的导函数的值域要合理地控制在一个合适的区间内,不能过大或过小。常见的激活函数有:sigmoid函数、logistic函数、tanh函数、reLU函数等。ReLU函数有“降低计算量”“解决梯度消失问题”“缓解过拟合问题”这三个重要的特点,但是,在实际使用过程中,会出现Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。为了解决ReLU函数的这些问题,本文采用Leaky ReLU激活函数。该函数输出对负值输入有很小的坡度。由于导数总是不为零,这能减少静默神经元的出现,允许基于梯度的学习,解决了ReLU函数进入负区间后,导致神经元不学习的问题。Leaky ReLU激活函数的数学表达式为:

从图8中可以看出,Leaky Relu激活函数很好解决了Relu函数的静默神经元过多问题,使得神经网络的训练更加高效以及准确。
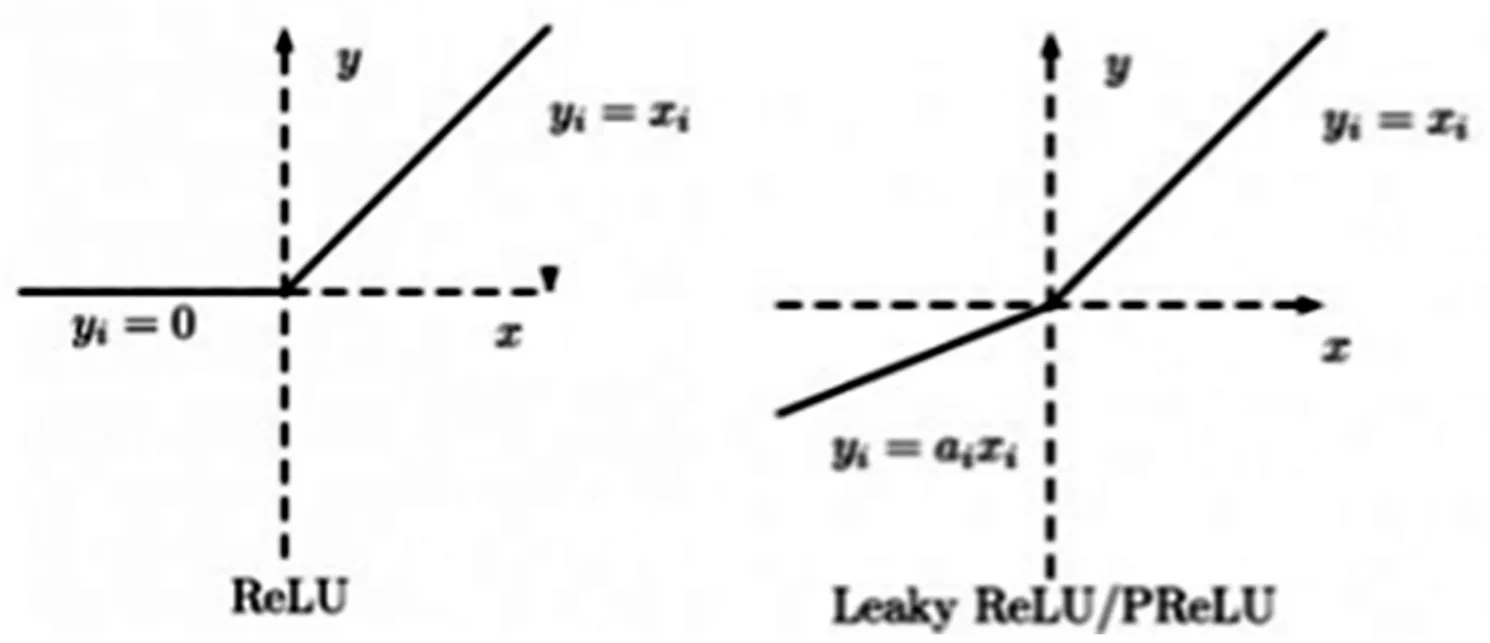
图8 Relu激活函数与Leaky Relu激活函数处理效果对比
2.3 随机梯度下降算法
为使神经网络的误差尽量小,损失函数要取到最小值,这个过程可以近似看作求取损失函数最优解的过程。对损失函数最小值的寻找方向一定是其下降幅度最大的方向,即损失函数初始点位处梯度向量的方向。在训练轮数进行不断迭代的过程中应用随机梯度下降法,得出最小化的损失函数以及训练模型的参数值,反向调整卷积核的输入权值[10]。随机梯度下降算法的相关计算公式如式(3)-(5)所示,公式的参数意义如表1所示。

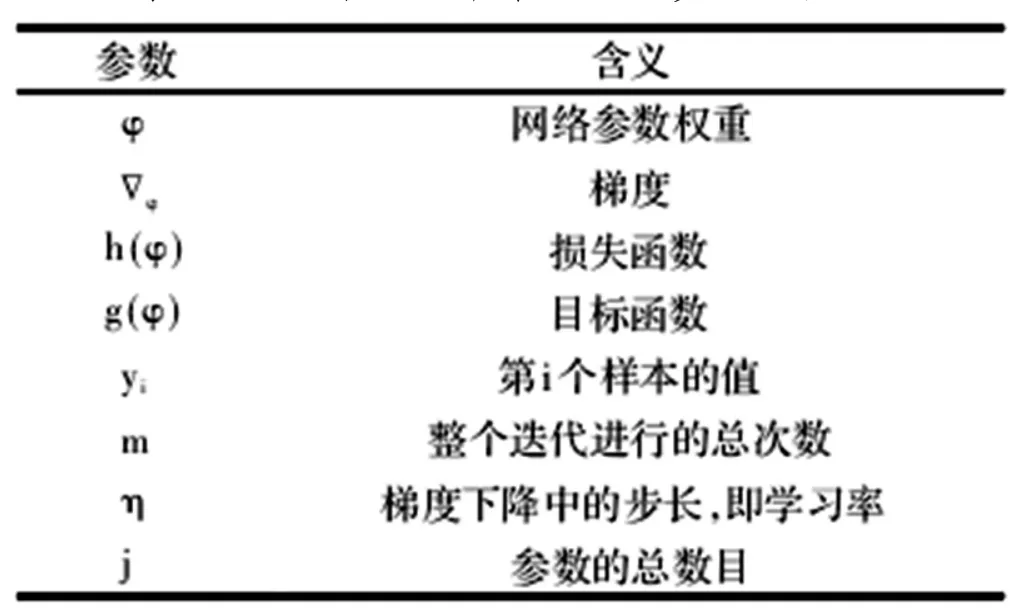
表1 随机梯度下降算法公式参数的含义
2.4 搭建GoogLeNet网络进行训练
该模型的创新在于使用Inception结构,这是一种网中网的结构,即原来的结点也是一个网络。Inception一直在不断发展,目前已经发展到V2、V3、V4。其中1×1卷积主要用来降维,用了InceptionV1之后整个网络结构的宽度和深度都可扩大,能够带来2~3倍的性能提升。但是,如果只是单纯的堆叠网络,虽然可以提高文字识别的准确率,但是会导致计算效率的下降,而InceptionV2使用Batch Normalization,加快模型训练速度;使用两个3×3的卷积代替5×5的大卷积,降低了参数数量并减轻了过拟合;增大学习速率并加快学习衰减速度以适用BN规范化后的数据;去除Dropout并减轻L2正则化;更彻底地对训练样本进行打乱;减少数据增强过程中对数据的光学畸变,因为BN训练更快,每个样本被训练的次数更少,因此更真实的样本对训练更有帮助。因此本文采用Inception V2结构,Inception V2的结构如图9所示。

图9 Inception V2结构图
本文使用2个连续的3×3的卷积核组成小网络来代替单个size=5的卷积层(如图10),这样的方案不会导致表达缺失,因此,采用Inception V2结构是文字识别的比较好的一种方案。
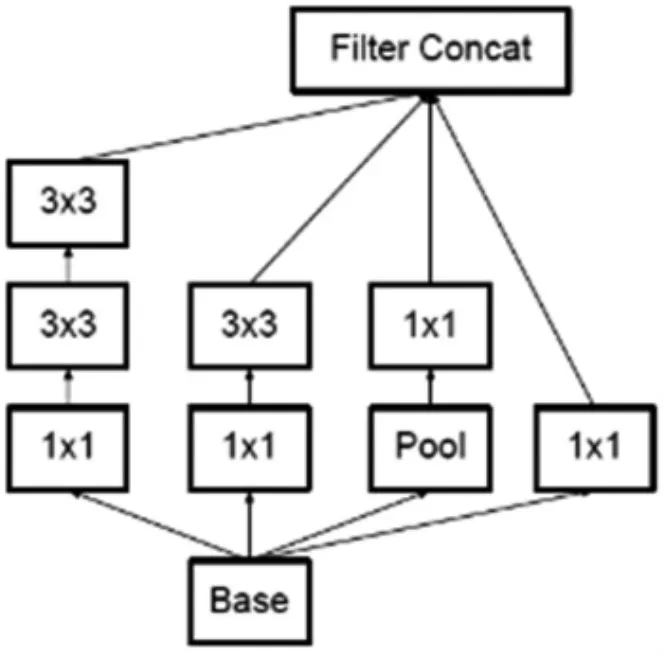
图10 用3×3卷积核代替5×5卷积核
2.5 实验结果分析
设置初始学习率为0.01,权重衰减为0.0001,迭代次数为51次。在训练过程中,使用交叉嫡作为损失函数,反向传播通过随机梯度下降算法调整下一轮迭代的卷积层权值,保存模型在此过程中性能最好的参数权重。
通过训练验证,本文构建的GoogLeNet模型识别准确率如图11所示。

图11 GoogLeNet模型识别准确率示意图
从图中可以看出训练刚开始时识别准确率提高得很快,且验证数据集与训练数据集同步上升,随着迭代次数加深,准确率逐渐趋近于98%,由此可以得出:模型训练结果较为理想。
3 结束语
本文针对农业书籍探索了基于卷积神经网络的文字识别的方法,通过对输入文档的图像预处理、版面分析与提取等处理方法,为计算机更好地识别采集到的文档图像提供了良好的条件,基于GoogLeNet构建了深度学习神经网络,利用该网络对处理后的文档图像进行了识别。实验表明,GoogLeNet网络具备高效率、高准确率识别的优势,为农业书籍的识别提供了技术参考。
