基于AdaBoost算法的人脸识别佩戴眼镜问题研究
2021-03-22杜骏霖
杜骏霖



摘 要:人脸识别技术在日常生活中的应用愈加广泛。本文着重研究如何在人脸识别过程中判断被识别者是否戴眼镜的问题。首先采用基于AdaBoost算法的Haar强特征级联分类器,把图像从起点到各个点之间形成的矩阵中所有像素点的和作为一个元素存进一个新的矩阵中,后将人脸眼部图像单独切割出来,并将眼部图像的像素点所占总像素点的比例作为一个判断是否戴眼镜的条件,运用回溯算法确定一个最佳阈值,最后得到人脸识别正确率为91.43%。
关键词:AdaBoost算法;Haar特征;回溯算法
中图分类号:TP391.41 文献标识码:A 文章编号:1003-5168(2021)26-0013-03
Research on Wearing Glasses in Face Recognition Based on
AdaBoost Algorithm
DU Junlin
(School of Remote Sensing and Geomatics Engineering, Nanjing University of Information Science and Technology, Nanjing Jiangsu 210044)
Abstract: Face recognition technology is more and more widely used in daily life. This paper focuses on how to judge whether the recognized person wears glasses or not in the process of face recognition. Firstly, the Haar strong feature cascade classifier based on AdaBoost algorithm is used to store the sum of all pixels in the matrix formed from the starting point to each point of the image into a new matrix as an element. Then the face eye image is cut out separately, and the proportion of the pixels in the eye image to the total pixels is taken as a condition to judge whether to wear glasses or not. The backtracking algorithm is used to determine an optimal threshold. Finally, the correct rate of face recognition is 91.43%.
Keywords: AdaBoost algorithm;Haar feature;backtracking algorithm
人臉识别技术作为一种新型的图像处理手段,正在逐步取代传统的身份验证模式。它通过摄像头采集含有人脸的图像或者视频流,自动检测人脸并进行定位,提取其中所蕴含的身份特征,然后将检测到的人脸与已有数据库中的人脸进行比对。人脸识别技术不仅具有非接触性、不易仿冒性等特点,还具有识别精度高、速度快等优点,能够大大提高重要关口的通行速度。目前,人脸识别技术还不够完善,尤其是面对人脸形状、颜色不同且有遮挡物(帽子、眼镜等)等情形时,检测较为困难。因此,加大对人脸识别技术研究方面的投入,进一步提高识别的效率与正确率,并将其应用于日常生活中显得尤为重要。
1 AdaBoost算法模型构建
1.1 模型介绍
AdaBoost是英文Adaptive Boosting(自适应增强)的缩写[1],其自适应性体现在前一个基本分类器被错误分类的样本权值会增大,而正确分类的样本权值会减小,并再次被用来训练下一个基本分类器。同时,在每一轮迭代中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数才确定最终的强分类器。Haar特征是计算机视觉领域常用的描述图像特征描述算子,通过像素分模块求差值来反映图像中的灰度变化。Haar特征是黑色矩形与白色矩形框内的像素和作差求得的值。本文将图片中的眼睛、鼻梁和嘴巴作为目标特征(黑色区域),将其余部位看作白色区域,需要提取出减去白色区域后的黑色区域[2]。
1.2 算法优化
本文采用积分图计算Haar的特征值提取,并利用基于AdaBoost算法的Haar强特征级联分类器进行人脸识别框取。如图1所示,将每张图像看作无数个点的集合,把最左上角的点记为起点0,把图像从起点到其余各个点1,2,3,……之间形成的矩阵中的所有像素点的和作为一个元素存进一个新的矩阵中。直接调用新矩阵的元素就可以在短时间内快速得到矩阵中的像素点的和。
记起点为0,目标矩形的4个端点分别为1、2、3、4,以a、b为对角线端点的矩形内的像素和为sum[a,b]。调用已有的像素和矩阵可知,A、B、C、D分别为4个小矩形内像素点的和,则有:
A=sum[0,1]
B=sum[0,2]-sum[0,1]
C=sum[0,3]-sum[0,1]
D=sum[0,4]-sum[0,3]-sum[0,2]+sum[0,1] (1)
2 基于AdaBoost算法的特征比较决策树模型
2.1 模型建立
级联分类器的训练主要采用的是迭代思想,通过将多个弱分类器按照一定的策略合理结合[3],得到一个强分类器。训练出多个强分类器后,按照级联的方式把它们组合在一块,可得到最终的Haar分类器。
首先,初始化各训练数据的权值分布。假设共有N个样本,将每一个训练样本在最初都赋予相同的权值1/N。其次,训练弱分类器。具体训练过程中,若某个样本点已经被准确分类,那么在构造下一个训练集时,它的权值就会降低。最后,将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起较大的决定性作用[4],同时降低分类误差率大的弱分类器的權重,使其在最终的分类函数中起较小的决定作用。
最基本的弱分类器只包含一个Haar-Like特征,也就是它的决策树只有一层,被称为树桩。以规格为20×20的图像为例,包含78 460个特征。如果直接利用AdaBoost训练,那么工作量极其巨大。所以,必须先筛选出T个优秀的特征值(最优弱分类器),然后把这T个最优弱分类器传给AdaBoost进行训练。算法流程如图2所示。
经过反复迭代训练,级联分类器通过机器学习基本掌握人脸五官的各项特征值,并据此判断出眼睛和嘴巴的位置[5]。
2.2 模型求解
采用基于AdaBoost算法的Haar强特征级联分类器对人脸进行分类,可以清晰找出眼睛、鼻子及嘴巴的位置,结果如图3所示。
3 眼镜佩戴检测模型
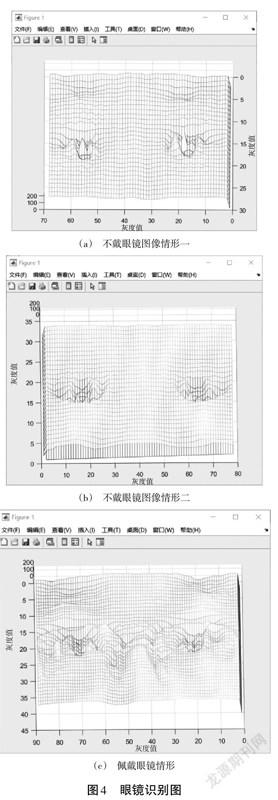
为了快速判断图像中的人脸是否戴眼镜,避免对整张人脸进行遍历而耗费时间,本文先用Python定位眼睛周围的图像并对其进行切割,然后用MATLAB对图像进一步处理。在MATLAB中将附件所给的灰度图绘制成网格图,如图4所示,其中图4(a)和图4(b)为不戴眼镜图像,图4(c)为戴眼镜图像。经观察分析得知,图像戴眼镜的部位亮度明显低于周围没有被眼镜覆盖的部位。
而后对采集到的100张戴眼镜的图像进行处理,求出每张图像中眼镜所覆盖的脸部像素点占脸部总像素点的比例,确定一个最佳阈值,作为判断是否戴眼镜的标准。达到这个阈值判别为戴眼镜,反之则没有戴眼镜。在确定阈值的过程中采用回溯算法。此外,本文考虑了头发、痣等可能影响图像亮度的因素,并对其进行处理,提高了阈值的精确度。
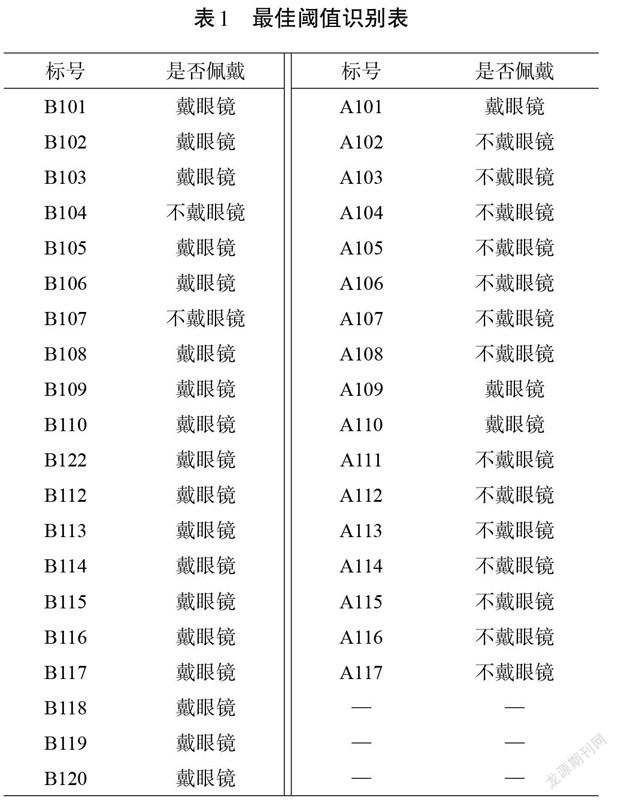
通过MATLAB找到最佳阈值后,再利用此阈值对附件中剩余图像进行自动识别,识别结果见表1(B开头编号为戴眼镜,A开头编号为不戴眼镜)。通过对这一识别过程进行概率统计和判断,发现识别正确率较高,说明本文使用的方法以及确定的筛选阈值正确可行。
4 结语
本文针对人脸识别过程中判断是否佩戴眼镜问题进行算法优化研究。采用基于AdaBoost算法的Haar强特征级联分类器,构建所有像素点集合的新矩阵。针对是否佩戴眼镜将人脸眼部图像单独切割出来,并将眼部图像的像素点所占总像素点的比例作为一个判断是否戴眼镜的条件。运用回溯算法,对图像进行处理,确定一个最佳阈值,达到这个阈值判断为戴眼镜,未达到阈值则判断为不戴眼镜。
参考文献:
[1]陈昱辰,曾令超,张秀妹,等.基于图像LBP特征与Adaboost分类器的垃圾分拣识别方法[J].南方农机,2021(21):136-138.
[2]刘仲民,李战明,王亚运,等.基于PCA/ICA和误差补偿算法的眼镜摘除研究[J]. 光学技术,2014(5):429-433.
[3]张建伟,霍进,李言章,等.基于人脸识别的防疫系统研究[J].现代计算机,2021(24):131-135.
[4]李金羽.多姿态人脸识别算法研究[D].北京:北京建筑大学,2020:35-37.
[5]李艳双,曾珍香,张闽,等.主成分分析法在多指标综合评价方法中的应用[J].河北工业大学学报,1999(1):96-99.
1139501186281
