基于机器学习的项目区分度分析方法的探索
2021-03-19
浙江师范大学 浙江 金华 321004
引言
区分度,是指测验项目对被试心理品质水平差异的区分能力,反映了测验题目对心理品质区分的有效性。提高区分度,可以很好地提高测验信度。
在心理与教育测量中,总是希望测验项目能够区分被试不同的心理特质或属性。比如,在选拔性考试里,试题必须具备区分度,以满足不同层次人才的需要;心理量表也要区分不同心理特质的被试。因此,在任何测验中,区分度都是非常重要的,是必须考虑的因素之一。
目前,区分度主要的计算指标:
(1)鉴别指数(D),该方法选取高分组、低分组两组进行计算。公式为:D=PH-PL
PH与PL分别为高分组与低分组在该项目上的通过率。一般在分数为正态分布时,高低分组各占27%。该方法需要区分多个层次时,只能采取两两比较的方法,因此反应较为片面,可提供的信息较少。此外由于仅分为两组,导致了结果受到分组依据的影响很大。面对主观题得分维度较高时,使用该方法会丢失大量信息。
(2)另一种常用方法是相关法,常常用项目分数与总分或校标分数的相关来计算区分度。这类方法结果受到计分方式的影响,且结果没有鉴别指数法好理解,提供的信息也比较少。
随着统计学的发展,统计方法不断革新,出现了机器学习。机器学习的目的是教机器如何有效的处理数据,特别是在我们无法解释或提取数据中的信息时。机器可以更好地找出变量与预测值间的映射关系,这种关系并不是简单的线性关系,这种更加复杂的关系可以用机器学习的模型来进行建构。
特征选择是机器学习重要的步骤之一,其目的是提高精确度、尽可能少影响精准度的情况下降低特征数。这和项目分析的目的不谋而合。此外,机器学习除了解决二分问题,也可以进行多分类问题。由此可见,机器学习可以弥补传统项目区分度算法的不足。机器学习算法提供的项目权重,作为特征选择的指标之一,可以在我们项目筛选时提供参考[1]。
因此,研究问题为机器学习算法是否能够为区分度提供更多的信息,以供项目分析时参考。
1 研究方法
1.1 被试
研究被试为温州市某小学的六年级学生。共发放测验160份,回收测验158份,根据学生的作答情况,排除无效测验11份,剩余有效测验147份。男生96份,女生51份,平均年龄11.95(SD=0.6)。
1.2 研究工具
数据来源:小学空间与图形诊断测验的数据。该测验共14道题、满分为39分。
机器学习模型:
(1)广义线性模型:传统的线性回归模型中不能很好地解决因变量是离散的或者是分类的情况。为了解决该问题,提出广义线性模型,其特点是不强行改变数据的自然度量,使数据可以解决非线性问题。
(2)随机森林:随机森林是包含多颗决策树的分类模型,该模型结果为多颗决策树预测的众数[2]。
(3)XGBoost:与随机森林一样也是多颗决策树的集合,但该模型预测结果与随机森林不同,该模型第二棵树会拟合第一棵树产生的误差,以此类推,用多个模型的和作为其结果。
(4)支持向量机是由Vapnik(1995)基于统计学习理论提出的一种机器学习算法。原理是通过找到一个超平面对样本进行划分。
1.3 研究过程
由于机器学习需要训练集进行训练,考虑到随机划分后各组样本量大小的问题。因此,分组策略定为,将学生分为三组,排名第49位学生(总人数的三分之一)的分数作为第一个切分点;排名98位的学生(总人数的三分之二)其分数作为第二个切分点。由此将学生分为A组(58人)、B组(46人)、C组(43人)三组。
按照训练集60%、验证集40%随机划分数据。选取多个常用机器学习算法对学生进行分类。并对结果进行评估分析,以获得更多信息[3]。
2 研究结果
2.1 项目区分度分析
以不同机器学习模型对三组学生分类的准确度作为区分度指标,由于使用模型不同,所以结果有些许差别(区分度是相对的,不同的相关法计算区分度,结果也会不一致。),但项目3、项目1、项目5、项目6在各模型下分类准确度排名都较为靠后。特别是项目3和项目1的平均分类准确度低于随机水平。
续表
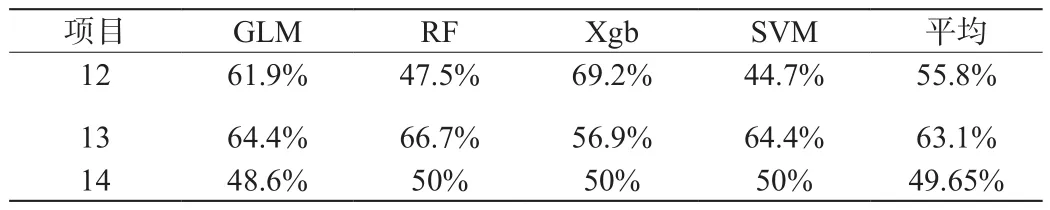
以其中一个XGBoost模型中项目14的分类评估为例子,如表2[4]。根据该表可以得到常用指标:
精确度(A):精确率为正确预测的除以总观测的数值,结果为0.5。
查准率(P):查准率为预测为某组的样本中,正确的比率。A的查准率为0.78、B组为0.32、C组为0.58。
查全率(R):查全率表示实际为某组的样本中,预测正确的比例。实际为A组的查全率为:0.3、实际为B组的查全率为0.47、实际为C组的查全率为0.77
(4)F1:查准率和查全率存在一定的矛盾,选择F1=2RP/(R+P)。作为两者平衡的指标。三组F1值分别为,A组:0.43、B组:0.38、C组:0.66。
根据F1指标可以看出,项目14对于C组学生的鉴别力最强,据此可以为题目筛选与组卷的过程中作为重要参考。比如,增加对B组鉴别力较好的题目使试卷对各组的鉴别力更为平衡[5]。

表2 XGBOOST模型项目14的分类表现评估
2.2 项目特征分析与选择
在实际测量中,有时会遇到题目之间的相互影响,产生交互作用。例如某项目区分度低,但与其他项目一起就能促进区分度的提高。对此类问题,机器学习模型能够很方便地对项目间关系进行研究。
区分度本身具有相对性,不同计算方法,所得区分度不同(戴海崎, 张峰, & 陈雪枫,2011)。因此,在实际使用当中,仅选用一种方法即可。本研究选用XGBoost模型进行该项分析,该模型为树型模型,采用多个树型模型结果的和来进行预测,可以更清楚的反应项目间的关系。训练集和验证集按照60%与40%随机划分[6]。为了更好地展示研究结果,研究将除了项目1与项目3外的12道题,随机分为两组,每组6道题,两组分别为项目组1和项目组3。将项目1与项目3纳入项目组1编为项目组2;纳入项目组3后,编为项目组4。分析结果如表3。

表3 项目关系分析

续表
根据F1值发现,所有项目组中A组和C组的F1值都明显高于B组的F1值,这是因为该试卷在编写时,采用的区分度算法是鉴别指数(D),以高低分组来进行区分度的分析。这也证明了,机器学习算法在面对区分度问题上的有效性,也反映了鉴别指数方法对于多层组别的区分度分析的不足[7]。
从各项指标来看,在加入项目1与项目3后,XGBoost模型的各项指标来看,都并未获得明显提高。当然,根据需要可以考虑更多的关系,比如项目1与其他某个项目共同测试了某一个属性的不同方面;或采用多次随机分组的方式,考察项目间是否存在隐含关系,具体可以根据实际情况进行更进一步的探究,来决定该项目是否保留。
除此之外,权重分析也是机器学习特征选择指标之一,如图1(指标为weight:代表在所有树中,某特征被用来分裂节点的次数)。机器学习算法通常包含多种权重指标,比如XGBoost中常用的还有total_gain:代表了某特征在每次分裂节点时带来的总增益。除此之外,其他的一些指标也都可以选用。但需注意的是,不同特征权重反映的内容不同,不同机器学习算法的权重评估方法也不同。因此,不能简单地认为权重高代表着该特征一定好,还需考虑多重因素,可以根据实际情况进行选用并进行评估[8]。
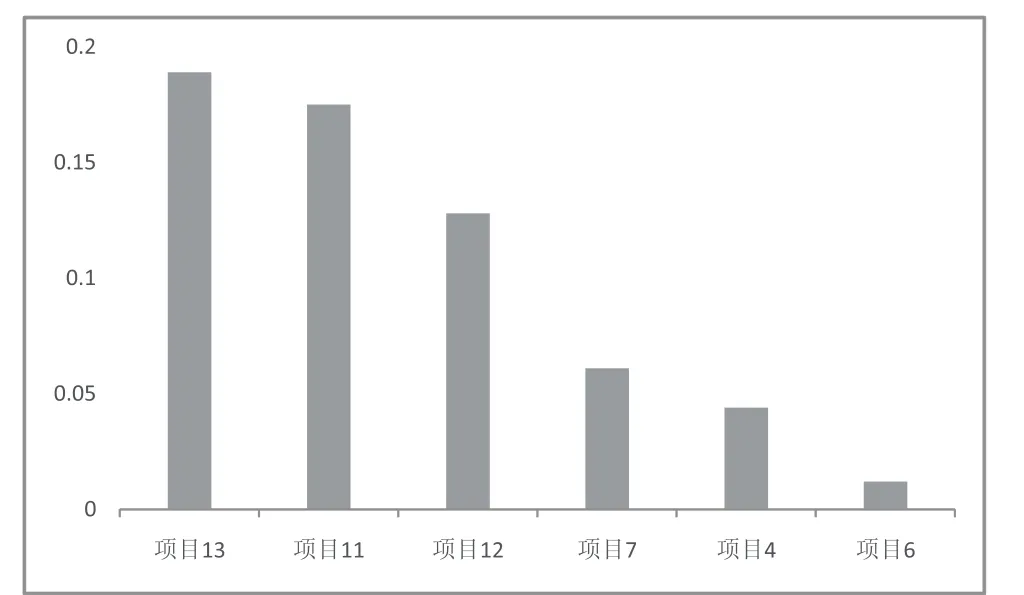
图1 XGBoost模型项目组1的特征权重
2.3 研究的意义与局限
利用机器学习模型,对项目区分度进行分析,为心理学与教育学的测评工作提供新的方法支持。在项目筛选的过程中,通过该方法,可以得到更多的信息,弥补原有方法的不足。
研究也有一些不足,首先,测验的项目数量不多、测验分值较低。机器学习更加适合处理高维数据,研究使用的测验的分值较低并不能完全发挥出机器学习的优势。此外,对于机器学习算法而言,样本数量需求较大,研究使用的样本数量少,限制了机器学习模型的拟合能力。最后,研究使用的试卷的分数,并没有明显的边界,在未来的研究中选用多层次异质性明显的样本来进行研究,来获得更有价值的信息[9]。
3 讨论
通过研究发现,不同机器学习方法由于模型不同,预测结果会有所不同,但对区分度最高与最低的项目存在较高一致性。机器学习模型的优点很明显,对于多级计分的题目,比如数学考试的应用题,学生可能获得的分数很多,面对这类问题上,机器学习模型往往能够发挥出它的优势。但必须承认的是,低维度项目上,利用机器学习进行项目区分度分析存在一定的弊端[10]。
总的来说,使用机器学习的方法对区分度进行分析时,相比于以往区分度指标,提供的信息更加详细。例如,机器学习模型提供的众多的项目权重指标,可以为项目的筛选过程提供更多的参考。在项目分析与选择的过程中,除了可以利用鉴别指数等传统指标,还可以配合机器学习的方法进行分析,根据实际情况,综合考虑项目的处理方式。但机器学习也存在着不同模型之间评价方式不一的情况,需要研究者根据自身研究特点选用恰当的评估方式[11]。
机器学习相比传统指标能够考虑项目之间到更加复杂的关系,这也是机器学习算法的最大优势。机器学习是学习输入与输出之间的映射关系,这种关系以代码的形式保存,无法明确的展示这一过程,这也是机器学习的缺点。但是在实际测量当中,不能完全否定其作用,测量最终目的就是通过项目来区分不同类别的被试,机器学习的任务也是在完成这一目标。针对模型可解释性差的这一缺点,相信会随着机器学习的发展,也会有更多的提高。
机器学习模型还具有更多的可拓展性,比如部分机器学习算法对于缺失数据具备容忍性,典型的是XGBoost算法,在心理量表中,很多题目并非像学业考试一样需要具备一定的知识结构才能够完成,因此在这类量表中的项目,出现的缺失值,不能单单用0分代替。XGBoost算法中,对于缺失值处理有自己的一套流程,它主要是通过学习默认方向来处理缺失值。该方法把缺失值当作稀疏矩阵来对待,本身不会考虑缺失的数值,会把缺失的特征分配到左子结点和右子结点,然后通过计算增益,选择增益大的方向进行分裂(Chen,2016)。免去了处理缺失数据的过程。另外,在大数据时代,机器学习的处理速度的优势也会更加明显[12]。
机器学习并不是来代替原有心理测量的方法,而是为心理与教育测量提供更多支持,与传统方法互补,相信测量和机器学习的结合,是未来发展的新趋势。
