自编码器在水质监测点位优化中的应用①
2021-03-19吕言成1魏景锋
张 镝,吕言成1,,张 楠,魏景锋
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
3(阜新市生态环境保护服务中心,阜新 123100)
4(辽宁省医疗器械检验检测院,沈阳 110000)
随着时代飞跃的发展和提高,人们的生活水平越来越好,城市的扩张,以及工业化的腾飞,对环境的影响是越来越大.人们慢慢将环境资源的可持续发展作为茶余饭后的话题[1],尤其是人类生存所必须的水资源,水资源中的污染物浓度值亦不可忽视,污染物个数多达数十种.因此,伴着社会的发展,水环境质量的分析,是完成环境与经济的可持续发展的重要工作.相关部门对水资源的管理和监测也越来越重视,对各个流域的水质有着周期性的监测,但随着环境质量的变化,水质也会跟随着变化,主要体现在:(1)比如扩建,那原地点的水质就会发生改变.(2)比如某一处土地集中进行绿化,那么土壤的质量必然会随着变化,这就必定导致水质量的变动.所以各个流域监测点位都是要随着时间,伴着周围环境质量和土壤的质量的变化而变化的.那么就必然涉及到点位优化的进行.这对实时监测水质最新的动向很有意义,也让把控着水质的动向,对水资源更好的治理和监测[2].
水质监测过程中,点位越多,收集的信息就越多,越能详细反映出水中污染物的真实状况.然而,碍于监测所需要的人力、资金、设备等成本的限制,无法对区域水质进行全面,无死角的布点监测.因此,为了能得到具有代表性又具有经济性的监测点位,就需要对大气监测点进行优化处理.本文就是采用auto-encoder结合聚类进行水质监测的点位优化.遵循了监测点位优化的宗旨:以尽量少的数据,尽可能的代表全部的监测点位的数据.
1 研究方法
根据要优化监测点位这一目的,选用了聚类方面的算法,由于是运用在水质监测方面,那么选取了适用于水质、地质、农业、天气方面的聚类算法.由于样本中高纬度的数据特征,存在各种噪声,如果不先剔除掉多余的特征和噪声,模型的效果会受到很大影响,但是如果只是单纯的剔除某些特征,那么就会把特征之间的联系给抹掉,聚类的结果不理想.为了解决此问题,本文采用了在聚类之前,先用神经网络降维的方法进行特征降维,将样本中原有的特征降维,重新生成一个更低维度的新样本[3-6].但同时特征降维涉及到有效数据的完整性,对于高纬度的水质监测点位数据,需要将有效的数据保存到降维后的数据中,剔除无效的数据.由于数据样本不需要进行标记,这里采用了无监督学习的auto-encoder 神经网络[7-9].对于水质点位监测的数据,传统的PCA 方法因为其线性降维,另外PCA 方法更依赖初始的数据,不能很好的保留有效信息的完整性,相对来讲,自编码器可以学习非线性关系,有效数据的保留更加充分,同时剔除无效的数据,泛化能力更强.图1为研究方法的整体流程图.

图1 研究方法流程图
1.1 自编码器auto-encoder 神经网络
Auto-encoder是神经网络的一种,也是最常见的深度学习算法之一[10-13],其结构如图2所示.Autoencoder 主要被用来降维和特征提取,另外该神经网络属于无监督学习,不需要标记训练数据,这也是本文采用此种方法的原因[14].
自动编码器包括三层神经网络,第一部分是输入层,第二部分是隐藏层,隐藏层可以为多层,第三部分是输出层,输入层n个神经元对应样本中的特征,隐藏层k(k 图2 Auto-encoder 神经网络结构示意图 输入层和隐藏层之间计算: 在隐藏层和输出层之间计算: 其中,f是激活函数,本文选择Sigmoid 激活函数: 输出层a3各个节点值和输入层a1的各个节点值存在很大误差.为了让输入层和输出层尽量一致,利用反向传播算法,通过输入层和输出层产生的误差来更新各层之间的权重矩阵Wij、和隐藏层、输出层的偏置b2、b3.此神经网络用到的是BP算法,思想是采用的梯度下降的算法,即微积分的链式偏导的传递求值[15].本文所采用的梯度下降算法:每次只选n个样本中的一个样本进行梯度下降,每次更新需要的时间少,由于水质监测点位本身并不多,所以迭代至收敛的次数可以容忍,另外适当的学习速率可以平衡训练的速度和收敛到最优点的稳定性.对于水质点位监测的数据,单隐层的自编码器模型易理解,训练成本不高,无论是在计算成本还是精度方面,自编码器都是可行的.本文选用简单的单隐层自编码器,相对于堆叠式的自编码器,不容易发生梯度弥散和梯度爆炸. 取误差公式: 对权重进行链式求导并更新: 由于输入层到隐藏层的权重参数矩阵和隐藏层到输出层的权重参数矩阵互为转置关系,因此,只需要把后者的权重转置赋值到前者. 对偏置b3进行链式求导并更新: 对偏置b2进行链式求导并更新: 式中,η是学习速率. 整个auto-encoder 算法伪代码如算法1. 算法1.Auto-encoder 1.初始化auto-encoder 中各层之间的连接权重、偏置和学习速率.2.for all 数据集中每一个样本do 3.while (对于当前样本)do 4.根据式(1),式(2)计算隐藏层的输出值;5.根据式(3),式(4)计算输出层的输出值;6.根据式(5)计算输入层和输出层的误差;7.if (达到停止条件) 8.break;9.else if 10.根据式(6)~式(8)更新权值和偏置;11.end if 12.end while 13.end for 14.得到更新所有样本之后最新的权值和偏置;15.for all 数据集中每一个样本 do 16.根据式(1),式(2)计算隐藏层的输出值;(此步骤,特征提取并降维)17.将降维后的新样本存入文件中保存;18.end for 本文采用聚类中的系统聚类方法对上述神经网络降维的数据样本进行分类.对于没有预先处理的水质点位监测数据,模糊聚类算法是最适合的.但是由于数据及预先用神经网络进行了降维处理,特征数量减少,原本监测点位有限,因此本文选用了适用于少量特征、少量点位的系统聚类法,并且运行速度有一定的提升.首先,将类别分为n类,即每个监测点位分为一类,计算各类之间的距离,找出所有类间距中的最短距离的两个类,并合并他们为一个新类,重新计算n−1个类的类间距,找出最短距离并归类,直到所有类都归为一类[16]. 欧式距离公式为: 系统聚类算法伪代码如算法2. 算法2.系统聚类算法1.将降维后的数据样本分为类2.for all 类别do 3.计算类间距;4.找出类间距中的最短间隔距离;5.找到最短间隔的两个类,合并他们;n=n−1 n 6.合并之后新的类别数目为;n=1 7.if ()8.break;9.end for 本文数据集来源为某市实时监测的各个断面的水质污染物浓度值. 首先对数据进行预处理,将数据映射到(0,1)之间,即标准化处理,公式如下: 其中,xnorm表示标准、归一化处理后的数据,x表示原数据,xmin表示的是所有监测点位中每个污染物的最小浓度值,xmax表示的是所有监测点位中每个污染物的最大浓度值. 实验过程如图1所示,将标准化、归一化处理后的数据输入自编码器神经网络,初始化各层之间的权重参数,初始化隐藏层和输出层的偏置参数,开始训练.将自编码器神经网络降维后的新数据样本聚类分析,产生点位优化的结果. 本文首先检验原点位与优化后的点位之前的相关性,在给定 α=0.05显著性程度,f=n−2=3,查表r表=0.878,r计>r表,相关性结果如表1. 表1 相关性检验 为进一步验证,本文采用F检验法—方差齐性检验和t检验法验证原点位与优化后的点位之间所监测的数据是否具有一致性.结果如表2.所采用的公式为: 表2 一致性检验 为了进一步验证优化后的点位选择更加精准,本文通过姚式指数公式同时计算优化后与优化前的水质量指数和原点位的水质量指数进行比较.结果如表3,公式如下: 表3 质量指数对比 根据神经网络降维结合聚类所产生的点位选择结果如图3. 图3 实验结果图 如图3所示,神经网络降维结合聚类的算法选出了从9 个监测点位中选出了5 个监测点位.而原本单独使用的模糊聚类算法选出的是6 个监测点位.根据表1所示的相关性检验,表明原点位与优化后的各污染物浓度密切相关,无明显差异性.根据表2结果,进一步证实了原点位和优化后点位各污染物这两组数据评价结果一致,表明优化后的点位可以替代原点位.根据表3结果,表明本文所选的点位优化算法所产生的5 个点位的质量指数,比模糊聚类算法产生的6 个点位更接近原本的9 个点位的质量指数.综上所述,本文所选算法所产生的点位更能代表全部的9 个监测点位. 本文针对水质点位优化提出了一种神经网络结合聚类的点位优化算法,通过神经网络对数据进行降维处理,并通过系统聚类的方法选出合适的点位.本文所提出的方法相较于单一的聚类方法,减少了点位的选择,并且提高了点位选择的准确性,实现了以尽量少的点位,保证数据的代表性.

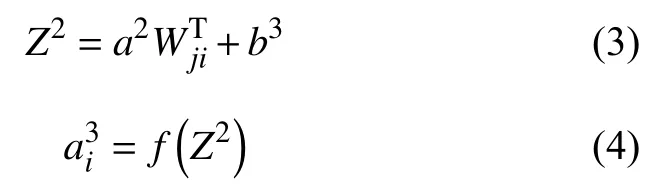








1.2 聚类分析


2 实验分析
2.1 数据预处理

2.2 实验过程
2.3 评价指标





2.4 结果分析

3 结论
