基于时段客流特征聚类的地铁运营时段划分①
2021-03-19陈东洋陈德旺江世雄
陈东洋,陈德旺,江世雄,徐 宁
1(福州大学 数学与计算机科学学院,福州 350108)
2(福州大学 智慧地铁福建省高校重点实验室,福州 350108)
城市轨道交通的列车开行方案是运营公司日常组织运营调度的前提与基础[1],而合适的运营时段划分方案也是列车开行方案调整的基础.对于运营公司而言,分时段等间隔的发车方式同时具有灵活、易操作等特点,因此是运营公司广泛采用的一种发车模式[2].该模式通常根据客流规律将一天划分为高峰时期、正常时期、低谷时期等若干个运营时段,并在各运营时段内采用合适的发车间隔.但在实际的工作中,地铁运营时段的划分通常是技术人员根据经验等因素,主观地进行划分,难以符合实际的客流需求.因此国内外有许多学者针对此问题进行了研究.
对于时段划分问题的研究主要是针对公交、路口等问题,对于地铁的研究较少.在公交运营时段划分方面,Bulut 等[3]通过站间流量得到公交车使用率,并以此为特征变量采用聚类算法划分运营时段;文献[4-8]从车辆行程时间角度出发,以车辆单程时间、站间运行停留时间等作为特征变量,并采用有序样本聚类、K-means 等聚类算法划分运营时段;靳文舟等[9]以车队运营时间最小为优化目标构建模型,并借助遗传算法对模型进行求解,以寻找最优的运营时段划分方案.在交通路口时段划分方面,文献[10-13]以道路路口不同方向的流量等作为时段内道路的特征向量,并采用聚类等算法划分交通时段;杜长海等[14]建立了一种结合混合蛙跳算法优点与模糊C 均值算法优点的模型以解决交通运营时段的划分问题;杨立才等[15]借鉴生物免疫网络理论,建立了以人工免疫算法为基础的数据聚类分析算法模型,以解决城市交通运营时段的自动划分问题.在地铁时段划分方面,王文宪等[16]建立采用近邻传播聚类算法的地铁运营时段划分模型,模型中以目标线路各车站单位时间内的进站客流为描述变量;曾小旭等[17]根据实际客流数据建立了地铁单向OD 概率矩阵的时序模型,并以此为基础采用最优分割法求解模型,给出时段划分方案.
以上研究为地铁运营时段划分提供了参考.但是可以发现,上述研究主要是将研究对象一定时间内各组成部分的客流量或行程时间作为特征变量来描述该时段的特点,如站点间的客流量、行程时间等.但是该方法容易受到一些特殊站点等因素的影响,且其直接采用客流量等作为描述变量,因此难以体现线路总体客流的变化特性.而且在求解划分方案时忽略了不同时段之间的相似性,降低了时段划分方案的灵活性.基于以上分析,本文以地铁线路总体客流的变化特点为基础,首先构建运营日的时段客流样本数据集.再根据各时段客流片段的客流变化特点,构建每个时段客流片段的特征向量,并以此为基础采用K-means 算法进行聚类,最后借助聚类评价指标确定最佳聚类数.本研究能根据实际客流需求,实现地铁运营时段的准确、高效划分,为地铁列车时刻表的优化设计提供了良好的基础.
1 时段客流特征向量构建
城市轨道交通自动售检票系统(AFC)中存储着大量的乘客出行交易信息,其中包括乘客的进出站点编号、进出站日期时间、交易卡号等.对这些信息进行挖掘和分析,可以进一步提取出地铁线路的客流变化特征等信息.本文以福州地铁一号线2019年5月13日-5月17日以及5月20日-5月24日共10 个工作日的AFC 客流数据为基础,研究福州地铁一号线工作日的各运营时段的划分方案.
1.1 单日客流序列构建
将目标线路在运营日k中统计间隔i内到达目标线路站点候车的乘客人数记作则运营日k的客流序列可记作且满足其中Qk为目标线路在运营日k的客流总量,n为运营日k的统计间隔个数.本文中统计间隔选取1 min为单位,同时考虑福州地铁的实际运营情况,本文的运营日统计时段为06:00-23:59.因此本文中n的取值为1080.
为后续运营时段划分方便,同时考虑到目标线路多个工作日的客流序列的相似性,因此采用均值处理方式,构建工作日单日客流序列S={s1,s2,···,si,···,sn},其中:

式(1)中,K为运营日的天数.
1.2 时段客流样本构建
运营日的客流序列反映了目标线路一天中乘客乘坐地铁的客流变化规律.选取合适的时间间隔d,将运营日的客流序列划分为若干个长度相同的序列片段,则运营日的所有序列片段即构成了运营日的时段客流样本集D={D1,D2,···,Dm},其中m为样本集大小,且m=n/d.则有:

本文选取10 min为时间间隔单位,即d=10 min.因此样本集的大小m=108.
1.3 时段客流特征向量
样本集D的每一个样本都是工作日单日客流序列的某一个时段的客流变化序列,每一个样本的客流序列都有其变化特点.不同的时段客流样本可能具有相似的变化特点,也可能具有不同的变化特点.但是从客流数值上难以看出不同时段客流样本的异同,因此本文构建时段客流特征向量来描述一定时间段内的客流变化特征.
本文采用时段客流的最大值、最小值、平均值、标准差、客流上升时间比、客流下降时间比共6 个特征值来描述一定时间段内的客流变化特征.
对一段长度为N的时段客流序列c={c1,c2,···,cN},则上述特征值的计算公式如下:
时段客流序列c的最大值cmax计算公式如式(3):

时段客流序列c的最小值cmin计算公式如式(4):

时段客流序列c的平均值cavg计算公式如式(5):

时段客流序列c的标准差cstd计算公式如式(6):

时段客流序列c的客流上升时间比cup计算公式如式(7):

时段客流序列c的客流下降时间比cdown计算公式如式(8):

这6 个特征值中cmax反映时段内每分钟进站客流的上限;cmin反 映时段内每分钟进站客流的下限;cavg反映时段内每分钟进站客流的平均水平;cstd反映时段内按分钟统计的进站客流变化的波动幅度;cup体现时段内客流的上升趋势;cdown体现时段内客流的下降趋势.这6 个特征值共同组成该客流片段的特征向量,用以描述该客流片段的客流变化特征.
根据1.1 节和1.2 节生成的时段客流样本集,本文采用上述方法构建时段客流样本集D对应的时段客流特征向量样本集C.设样本Di对应的特征向量为Ci,且分 别对应样本Di的最大值、最小值、平均值、标准差、客流上升时间比、客流下降时间比,则样本Di的特征向量Ci表示如式(9):
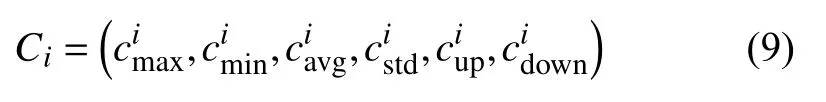
2 聚类算法模型
数据挖掘是一项通过分析大量历史数据进而挖掘提取隐藏的、存在潜在应用价值的信息的技术手段.而聚类分析作为数据挖掘的一种核心技术,具有巨大的潜在应用价值,是当下社会最具有应用前景的数据分析方式之一.而K-means 聚类算法是一种经典的解决数据聚类问题的算法,其快速、简单、高效,并且适合应用于大数据集上.本文基于K-means 算法进行地铁运营时段的划分.
2.1 K-means 聚类算法原理
K-means是一种常用的聚类算法,算法的核心思想是根据各样本之间的距离将最靠近的样本进行聚类,并在多次迭代中不断更新各聚类中心的值,直至达到算法设定的收敛条件,得到最好的聚类结果.
算法首先从样本集中随机选取k个对象作为聚类的初始中心点,然后计算样本集中所有剩余样本到各聚类中心点的距离,并以此将剩余的各个样本划分到与其相距最近的类别中,形成新的类别簇,再重新计算各类别的新的中心值,重复上述过程,直至达到算法提前设定的停止条件.K-means 算法终止迭代的条件有迭代次数、各类簇的中心变化率、最小平方误差等.本文采用最小平方误差作为K-means 算法的迭代终止条件.则算法的目标函数定义如下:

式(10)中,E表示样本集中所有样本到各自类别中心的距离平方之和,当某一次迭代之后E的值与上一次迭代后的值相比不发生显著变化时,算法即收敛.式中k为划分的类别数,Nj为类别j中包含的样本个数,xi为类别j中的样本i,µj为类别j的中心.
本文采用欧式距离作为样本间距离的计算公式,设两个样本向量分别为u=(u1,u2,···,un),v=(v1,v2,···,vn),则u,v的欧式距离定义如下:

同时采用计算均值替代的方式更新每个样本类别的中心点 µj的值,公式如式(12).

基于上述选择,本文的K-means 聚类算法的基本步骤如下:
步骤1.在样本集C中任意选取k个样本对象 µ1,µ2,…,µk作为每个类别的初始中心;
步骤2.采用式(11)计算样本集中剩余的所有对象Ci和µ1,µ2,…,µk的距离,并以此将其划分到与其距离最近的类别中心所属的类别中,即:

步骤3.根据式(12)更新每个类别的中心 µ1,µ2,…,µk;
步骤4.根据式(10)计算该次迭代后的目标函数E,如果该次迭代后的目标函数值与上次迭代后的目标函数值相差小于提前设定的阈值,则K-means 算法终止,否则,重复步骤2~步骤4.
由算法流程可知,K-means 算法有一个十分重要的参数,即聚类数目k值的选取.不同的k值所产生的聚类结果有很大差别,因此对于K-means 算法,确定一个合适的k值就十分重要.本文采用肘部法则以及轮廓系数两个评估指标确定最佳聚类数k.
2.2 肘部法则
肘部法则(elbow method)根据聚类的误差平方和(Sum of the Squared Errors,SSE)的变化程度来确定最佳的聚类数,SSE的计算公式如下:

式(14)中,Gi是第i个簇,p是Gi中的样本点,mi是簇Gi的中心,SSE是所有样本的聚类误差结果,代表了聚类结果的好坏程度.由SSE定义可知,SSE即为k值确定情况下该k值对应最终聚类结果的目标函数E.
采用肘部法则确定最佳聚类数的核心思想为:对于有一定的区分度的数据来说,伴随着K-means 算法的聚类数k值的增大,所有样本的划分会越来越精细,那么每一个类别的内部聚合程度会越来越高,则聚类的误差平方和SSE的值也就会变得越来越小.同时,当聚类数k的值还没达到样本集最优的聚类数时,伴随k值的增大,会极大增加样本中各类别的聚合程度,此阶段误差平方和SSE的值随k值的增大有较大下降幅度.而当聚类数k的值超过最优的聚类数时,伴随k值的增大,所能够得到的各类别聚合程度的回报会快速的降低,此阶段的误差平方和SSE的降幅会相应的变小,并随着聚类数k的值的增加而平缓增长.因此误差平方和SSE的值与聚类数k的关系图变化曲线会形如手肘,而图中的这个肘部位置也即是曲线拐点的位置对应的聚类数k就是所要找的最佳聚类数.
2.3 轮廓系数
对于一个聚类任务的结果,最希望的聚类情况是簇内样本尽量紧密,簇间的样本尽量远离.而轮廓系数(silhouette coefficient)同时考虑了类别内部的聚集度以及类别间的分离度,用以评价聚类结果的好坏.
轮廓系数的计算方法如下:
步骤1.计算样本i到同类别下其他样本的平均距离a(i).a(i)越小,表明样本i与该类簇的相似度越高,越应该被聚类到该类簇.
步骤2.计算样本i到与他相邻的最近的一个类别簇的所有样本的平均距离b(i).b(i)越大,表明样本i越不属于其他的类簇.
步骤3.根据以上计算,定义样本i的轮廓系数如下:

步骤4.对所有的样本计算轮廓系数,再采用所有样本的轮廓系数的均值作为该聚类结果的轮廓系数.
由轮廓系数的定义公式可知,其取值范围为[−1,1].其中取值越大,就说明聚类得到的结果越加合理.当s(i)越 接近1 时,表明对样本i的聚类越合理;s(i)的值越接近−1,则表明样本i更应该被分类到其他的类别簇中去.当s(i)接近0 时,表明样本i在两个类别簇的边界上.使用轮廓系数来确定最佳聚类数时,应尽量选择使轮廓系数较大的聚类数k值.
3 实验结果
基于本文第1 节提取的样本特征向量集,采用第2 节的K-means 聚类算法模型进行聚类分析,其中聚类数k的范围设定为[2,9].则各聚类数k聚类结果如图1以及图2所示,图1为聚类数k与误差平方和的关系图,也即肘部法则图,图2为聚类数k与轮廓系数的关系图.

图1 肘部法则关系图

图2 轮廓系数与聚类数k 关系图
由图1可知,聚类数k与误差平方和的关系图的拐点出现在k=3 处,根据肘部法则的思想,初步确定k=3为较好的聚类数.由图2可知,当k=2 时,聚类结果的轮廓系数最大,但结合图1可知,此时的聚类结果的误差平方和还较大,而k=3 时的轮廓系数仅略低于k=2 时的轮廓系数,同时,k=3 时的误差平方和也相较更低,而且k=3 也是肘部法则评判标准中的最佳聚类数.
因此,结合肘部法则以及轮廓系数两个评价标准,最终确定k=3为最佳聚类数,即将样本聚为3 类,此时聚类结果的误差平方和的取值为9.4758,对应的轮廓系数取值为0.4897.最终的聚类划分结果如表1所示.
由表1可知各样本所属类别.根据各样本所对应的时段,将各相邻的样本对应的时段进行合并,可以得到目标线路运营日中工作日一天的时段划分的初步结果如表2所示.初步的划分结果将一天划分为9 个时段.

表1 样本聚类结果

表2 初步的时段划分方案
由表2可以得到初步的运营时段划分方案.但是在初步的划分方案中,时段4 以及时段5 分别只有10 分钟的长度,这样的划分方式对于运营公司来说并不易于操作,因此需要对该划分结果进行修正.考虑到时段5 与时段3 在聚类时属于同一类别,因此将时段3、4、5 合并为同一个运营时段.同时由于福州地铁一号线的首末班车发车时间分别为6:30、23:00,因此经过修正后的运营时段的划分方案如表3所示.
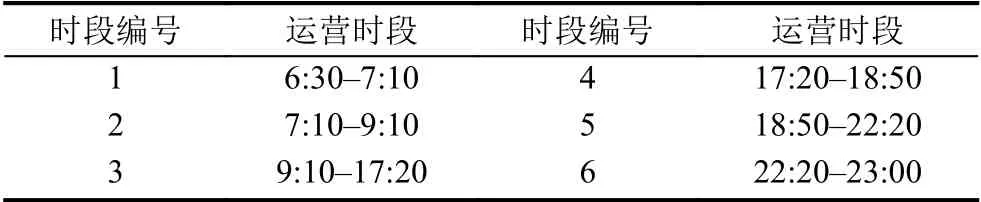
表3 修正后的时段划分方案
最终的运营时段划分方案将工作日一天划分为6 个时段,分别为6:30-7:10、7:10-9:10、9:10-17:20、17:20-18:50、18:50-22:20、22:20-23:00.其划分结果示意图如图3所示.图中虚线即为各时段的起止时间点分割线.
在该运营时段的划分方案中,每个时段内的客流都有着相似的变化特点,运营公司可以据此时段划分方案,根据各时段内的实际客流需求,采取合适的发车间隔,制定全天的列车运行方案.值得指出的是,时段6:30-7:10、9:10-17:20 以及18:50-22:20 由于属于相同类别,因此其客流变化特性具有相似性,在制定发车间隔时可以考虑采用相同或者相近的发车间隔.同理,时段7:10-9:10 与17:20-18:50 也是如此.这也为运营公司制定行车方案提供了更加丰富的思路.

图3 工作日全天时段划分
4 结论与展望
本文着眼于地铁运营时段划分问题进行了相应的研究.针对传统研究中采用客流量作为样本进行研究的局限等问题,提出一种构建时段客流特征向量的方法进行地铁运营时段的划分.首先构建线路目标运营日的单日客流序列,并采用合适的时间间隔将客流序列进行切片,再通过构建各时段客流样本特征向量的方式描述各时段的客流特征,最后借助于K-means 聚类算法模型确定最佳聚类结果,进而得到最优的运营时段划分方案.
地铁运营时段的合理划分,能够帮助运营部门制定更加符合实际需求的发车方案.本文提出的基于时段客流特征聚类的运营时段划分方法,以大量实际客流为基础,考虑了地铁客流的实际变化特性,能够更加客观的给出划分方案,避免了人工划分的主观性等缺点.当然,为了得到更加合理的地铁列车运行时刻表方案,需要在本研究的基础上进行进一步的各时段发车间隔研究,这同时也是作者下一步的研究重点.
