面向卷积神经网络的高并行度FPGA加速器设计
2021-03-18
(1.北京航天自动控制研究所,北京 100854;2.宇航智能控制技术国家级重点实验室,北京 100854)
0 引言
卷积神经网络(Convolutional Neural Network,CNN)是一种包含卷积计算的前馈神经网络,是深度学习的代表算法之一[1]。自从AlexNet[2]在2012 年ImageNet 大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)[3]上展示出CNN 在大规模图像处理中的巨大优势后,CNN 算法乃至循环神经网络(Recurrent Neural Network,RNN)等其他深度学习算法受到了广泛关注。现在,基于CNN的图像分类、目标检测、图像分割等算法已经广泛应用于道路行人检测、无人驾驶汽车、医学影像分析、国防安全等领域,并取得了显著成果。
虽然CNN 算法性能卓越,但是相较于传统的图像识别算法,它需要更多的计算量和存储资源,如19 层的VGG(VGG-19)[4]包含1.4 × 108个参数、3.9 × 1010次浮点运算,152 层的ResNet[5](ResNet-152)包含5.7× 107个参数、2.2 × 109次浮点运算,输入大小为300 × 300 的SSD[6]包含2.3× 107个参数、6.1× 1010次浮点运算。这对中央处理器(Central Processing Unit,CPU)来讲并不友好,因为CPU 更擅长流程控制,而用于计算的资源并不多;相比较而言,拥有大量计算核心的图形处理器(Graphics Processing Unit,GPU)更适合CNN 算法加速[7],但GPU 架构本身并非专为加速CNN 算法设计,存在功耗过大的问题,难以适应嵌入式领域的低功耗要求。
为了解决嵌入式领域CNN 计算设备算力不足的问题,研究者们从计算单元结构、访存方式、低功耗设计等多个方面提出各种CNN 的硬件加速器技术及方案[8-12]。然而这些设计要么只利用CNN 的输入输出通道并行[8],导致其架构的整体并行度较低,难以满足嵌入式领域很多应用的算力需求;要么直接将卷积计算转换为矩阵向量乘,导致其所需片上存储过大或者存储带宽需求过大,如Google 的张量处理器(Tensor Processing Unit,TPU)[9];虽然Eyeriss[11]通过其巧妙的脉动阵列同时利用了CNN 算法的多种并行,但是脉动阵列的逻辑控制复杂,导致其在现场可编程逻辑门阵列(Field Programmable Gate Array,FPGA)中的实现难以提高时钟频率[12];Xilinx 的深度学习处理单元(Deep learning Processing Unit,DPU)同时利用了CNN 的输入输出并行和特征图内并行,但其特征图内并行的方式会导致片上存储带宽需求增加、特征图尺寸变小时计算效率急剧下降等诸多难以克服的问题。Angel-Eye[13]利用可配置的2维卷积器[14]实现了卷积核内并行的方案,但是需要大规模的链式移动寄存器组,会消耗大量的FPGA 逻辑资源,而且控制逻辑复杂,难以利用高层次综合(High Level Synthesis,HLS)实现。总之,研究者们还未系统地比较研究CNN 算法中可用于硬件加速的各类并行度,也未针对CNN这种多通道2维卷积算法提出一种专门的硬件结构,以简洁有效地利用CNN 算法的卷积核内并行,进一步提高CNN加速器的算力。
针对上述问题,本文以CNN 算法中可用于硬件加速的各类并行度为切入点,在综合比较研究各类并行度的基础上,提出CNN 加速器设计的各类并行度组合方案,以面对嵌入式应用的不同算力需求场景。在较高算力需求场景下,为了简洁有效地利用CNN 算法的卷积核内并行,本文提出多通道卷积旋转寄存流水(Multi-channel Convolutional Rotating-register Pipeline,MCRP)结构,其逻辑简单,容易实现,且不会额外增加片上缓存带宽,计算过程中无须将输入特征图在卷积窗口内展开,就可以实现卷积窗口内数据的并行计算。利用此结构,可将CNN 加速器的并行度在只利用卷积输入输出并行的基础上增加9 倍,使得设计出更高并行度的CNN 加速器变得简单易行。本文的主要工作可归纳为如下几点:
1)针对3×3 的卷积运算,提出多通道卷积旋转寄存流水结构MCRP,简洁有效地利用了CNN算法的卷积核内并行。
2)基于多通道卷积旋转寄存流水结构,提出了一种CNN硬件加速器架构,并将其部署于Xilinx 的ZYNQ ultrascale+系列多处理器片上系统(Multi-Processor System on Chip,MPSoC)芯片上。
1 CNN及其计算并行度
CNN 通过局部连接模拟视觉神经的感知局部性,通过权值共享的方式避免了深度神经网络容易过拟合的问题,使其在图像分类、目标检测、图像分割等诸多领域表现优异。为了更好地理解本文的对CNN 及其各类并行计算方式的分析,本章将简要介绍CNN 的基础知识以及CNN 模型卷积层的各类计算并行度。
1.1 CNN
CNN 由一系列相互独立的层组成(Layer),以多个串联的卷积层和池化层作为特征提取器,以全连接层作为最后的特征分类器。CNN 的第一层输入是待处理的图片,输出是一组特征图(Fout);其余各层的输入(Fin)是前一层的输出特征图;最后一层输出CNN 的处理结果。在卷积层之后,为了缩小特征图的尺寸,一般会有一个池化层用于降采样。一般地,为了增加模型的表征能力,CNN 模型的每一层之后还会增加一个非线性激活函数,如ReLU、sigmoid等。
1)卷积层。卷积层的功能是对输入特征图进行特征提取。为了提取出多种不同特征,需要多个卷积核有规律地从输入特征图扫过。卷积核每次移动的距离称为步长S(Stride),每个卷积核都是一个3 维张量,卷积核的通道数与输入通道数相同,卷积核的个数和输出通道数对应。图1 展示了3×3卷积的一般过程,其中:M为输入通道数,N为输出通道数,Wi/Hi为输入特征图的尺寸(宽/高),Wo/Ho为输出特征图的尺寸。卷积层的计算过程可公式化表示为:

其中:conv2d为一般的平面内的2维卷积算子;W(i,j)为与第i个输入通道、第j个输出通道对应的卷积核;b(j)为与第j个输出通道对应的偏置。

图1 3×3卷积的一般过程Fig.1 General process of 3×3 convolution
2)全连接层。全连接层的功能是对输入特征进行线性变换:

其中:Fin、Fout分别是输入、输出特征向量,或者可以看成是尺寸为1 的特征图;W是大小为M×N的特征变换矩阵;b是输出的偏置向量。
3)池化层。池化层的功能是对输入特征图降采样,输出每个池化窗口内的最大值(最大池化)或平均值(平均池化)。池化层不但能降低特征图尺寸,而且还可以提高CNN 模型的特征鲁棒性。池化窗口为2 的最大池化的计算过程可公式化表示为:其中:w是输出特征图的列索引;h是输出特征图的行索引;j为输出特征图的通道索引。

除了卷积层和全连接层之外,CNN 模型还可能会包含池化层、跳连层(concat layer)[5]、元素可分离(element wise)卷积层[15]、深度可分离卷积层[16]以及其他层,但是这些层在规模较大的CNN 算法中的计算量占比都很小,图2 展示了经典CNN模型VGG-11[4]各类型层的计算量的分布情况。由图2可以看出,在VGG-11 模型中,3×3 的卷积层占了95%以上的计算量,全连接层占了约2%的计算量,这与大部分CNN 算法的计算量的分布情况一致[17],因此,大部分CNN 加速器只针对卷积层和全连接层设计[8-13]。为了进一步简化设计、提高性能,本文专门针对计算量占比最大的3×3 卷积进行硬件加速器设计,其他类型的层将通过3×3卷积算子间接支持。
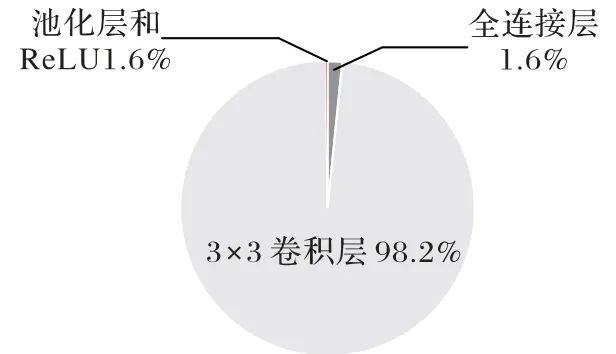
图2 VGG-11的计算量分布情况Fig.2 Calculation distribution of VGG-11
1.2 卷积层的各类并行度
从算法角度来讲,卷积层的前向计算过程为一个6 层嵌套循环,只在循环的最内层进行乘累加(Multiply ACcumulate,MAC)运算。具体过程见基本卷积的伪代码:

从上述伪代码中可以看出,这6 层循环之间没有依赖,它们的顺序可以任意调换。而硬件加速卷积层计算的基本原理就是,将某些循环部分展开后移至最内层,用多套乘累加电路并行计算,而剩余的循环依然在外层保持紧凑的嵌套结构,分时复用内层的计算电路。选择哪一层循环展开,展开为几套电路,即并行度类型和大小的选择,将很大程度决定CNN 加速器的算力峰值、硬件利用率、逻辑复杂度、数据流的安排、片上缓存设计以及最终性能。因此,计算并行度类型和大小的选择是CNN加速器设计的关键。本文将卷积计算的6层归纳为4 类计算并行度,如图3 所示,下面将分别介绍这4 类计算并行度。
1)输入通道并行。将基本卷积伪代码中的输入通道循环部分展开,同时计算PDi个输入通道的数据,即输入通道并行,并行度为PDi。由于大多数CNN 算法的特征图最小通道数不大于32[4-6,15-16],经剪枝处理[18]后,很多层的通道数将小于32。为了保证硬件加速器的实际利用率,PDi一般不大于32。
2)输出通道并行。将基本卷积伪代码中的输出通道循环部分展开,同时计算PDo个输出通道的数据,即输出通道并行,并行度为PDo。同样的,为了保证硬件加速器的实际利用率,PDo一般不大于32。
3)特征图内并行。将基本卷积伪代码中的特征图内的行/列循环部分展开,同时计算PDf个特征图内的数据,即特征图内并行,并行度为PDf。CNN 算法各层的特征图尺寸变化范围非常大,表1 统计了各经典CNN 模型的特征图尺寸变化范围。为了在特征图变小时依然保持较高硬件利用率,PDf一般不大于8。
4)卷积核内并行。将基本卷积伪代码中的卷积核内的行/列循环部分展开,即同时计算PDk个卷积核内的数据,即卷积核内并行,并行度为PDk。由于CNN 的大部分计算量集中在3×3卷积层,因此可将PDk设9。

表1 经典CNN模型的特征图尺寸变化范围Tab.1 Feature map size range of classic CNN algorithms

图3 卷积层的4种计算并行度Fig.3 Four kinds of computating parallelism for convolutional layer
2 FPGA高并行度加速计算方案
本章将首先分析利用各类并行度进行硬件加速的优缺点,提出应对不同算力需求场景的并行度选择方案。然后,提出MCRP 结构,此结构将输入通道并行和卷积核内并行巧妙结合在一起,以很小的代价有效地利用卷积核内并行。最后,基于MCRP 结构提出了CNN 加速器整体架构。如2.1 节所述,3×3的卷积层占据了CNN 算法的大部分计算量,为了简化计算、提高性能,本文专门针对3×3 卷积层优化设计CNN 加速器。
对于其他尺寸卷积层和全连接层,可将其通过简单的变换转换为3×3卷积后进行加速计算。比如,步长为1的1×1卷积层可转换为步长为3的3×3卷积层,转换后输入通道数变为原来的1/9,特征图尺寸变为原来的3 倍;步长为1 的5×5 卷积层,通过适当补零,将其转换为步长为1的3×3卷积,转换后输入通道数变为原来的4 倍,而特征图尺寸比本来的尺寸小3;而全连接层可以看作特征图尺寸为1 的1×1 卷积,与步长为1的1×1卷积类似,也可转换为3×3卷积层。
2.1 硬件加速器方案选择
CNN 硬件加速器方案的选择,关键在于并行度类型和大小的选择。为了进一步说明各类并行度的优缺点,本文将首先建立一个简单而不失一般性的CNN 加速器的基本模型。如图4 所示,此模型由3 块独立的片上缓存和处理单元(Process Element,PE)组成,PE 每次计算时都从Fin_buf 获取输入特征、从W_buf 获取权重数据、从Fout_buf 获取卷积的中间结果,将本次的计算结果累加到中间结果上之后写回Fout_buf。

图4 CNN加速器的基本模型Fig.4 Basic model of CNN accelerator
由图3 可知,不同的并行度类型每次计算所需的数据量不同,即不同的并行度类型将会导致不同的片上缓存带宽需求。片上缓存带宽直接影响FPGA 中BRAM(Block Random Access Memory)和布线资源的消耗量,带宽越大,消耗的资源越多,当片上资源无法满足带宽需求时,将不得不调整数据流以及设计的其他部分。与本文其他部分的数据位宽设置相同,考虑到定点量化[20]的因素,将输入特征、权重数据的位宽设为8 bit,而为了保证计算精度,中间结果的位宽设为12 bit。表2为各类并行度大小为9时,它们对片上缓存带宽需求的比较。从表2 中可以看出,卷积核内并行所需带宽最小,仅为输出通道并行和特征图内并行的1/3。从这一方面讲,卷积核内并行是CNN硬件加速器最佳并行方式选择。
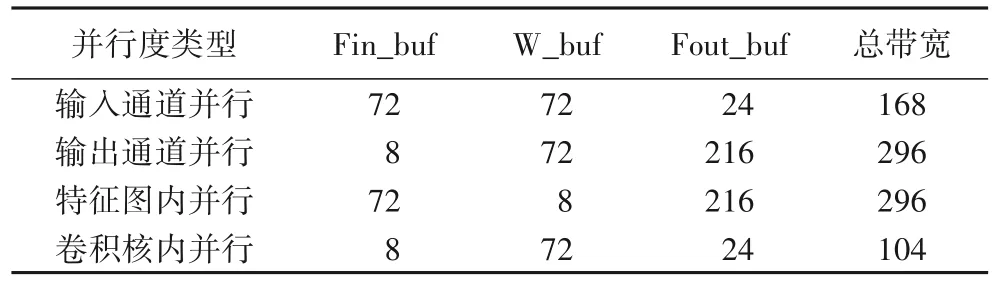
表2 各类并行度的带宽需求比较 单位:bit/clkTab.2 Comparison of bandwidth requirements for different kinds of parallelism unit:bit/clk
基于FPGA 的CNN 加速器一般工作在100~300 MHz[17],因此只能通过提高硬件总体并行度的方式提高算力。由2.2节可知,各类并行度都被限制在较小范围内,需将它们选择性地组合使用。一般地,在低算力需求的应用环境下,可选择最为简单的输入通道并行+输出通道并行(输入输出通道并行)的方式。在较高算力需求的应用环境下,Xilinx 的DPU 就是采用输入输出通道并行+特征图内并行的组合方案。而本文认为在这种应用环境下,DPU 的方案并不是最合适的。相比之下,输入输出通道并行+卷积核内并行的方案更加简洁高效,因为本文提出的MCRP 结构可将输入通道并行和卷积核内并行的数据流巧妙结合在一起,在只增加少量逻辑和不增加缓存带宽的情况下,就可以将设计的并行度在只利用输入输出并行的基础上增加9 倍,既避免了特征图内并行方案的复杂逻辑设计,又克服了其在特征图尺寸变小时,硬件利用率过低的缺陷。当然,在更高算力需求的应用环境下,当输入输出通道并行+卷积核内并行的方案不能满足应用的算力需求时,可以考虑将4种并行度全部组合起来使用。
2.2 多通道卷积旋转寄存流水结构
多通道卷积旋转寄存流水结构的主要功能是:在输入通道并行的基础上,在不增加Fin_buf 带宽需求的条件下,利用卷积核内的数据复用,每个时钟周期为PE 单元提供3×3×PDi个特征数据,以满足PE 单元每个时钟周期计算PDi个通道3×3 卷积的数据需求。MCRP 的结构如图5 所示,主要由Fin_buf、Line_buf和Fin_reg组成:
1)Fin_buf。用于缓存从片外双速率同步动态随机存储器(Dual Date Rate synchronous dynamic random memory,DDR)读取的输入特征数据,并向MCRP 结构提供数据。是由BRAM(Block RAM)实现的双端口RAM,读/写端口位宽均为PDi× 8 bit,可同时读写PDi个特征数据,其深度Fin_buf_LEN视片上存储资源和CNN 模型的规模而定,没有特殊要求。输入特征数据按照图6 所示的排序方式缓存到Fin_buf,第0 维对应Fin_buf 的宽度,而其余各维度在Fin_buf 的深度方向顺序缓存,即每PDi个通道的特征图为一组,按照通道、列、行、分组的顺序存储。
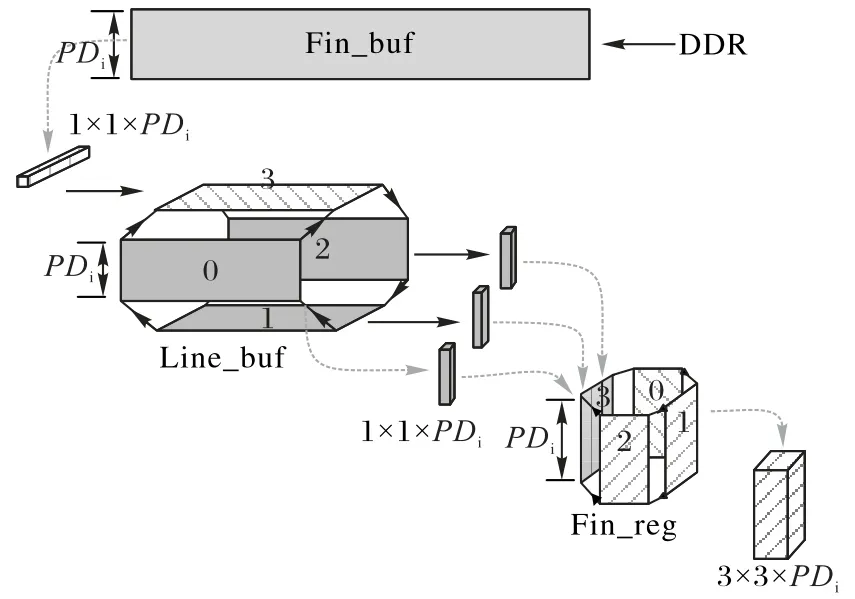
图5 多通道卷积旋转寄存流水结构Fig.5 Multi-channel convolutional rotating-register pipeline structure
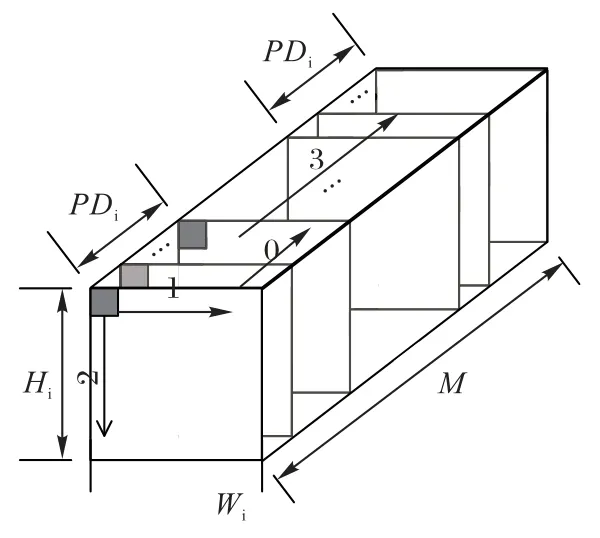
图6 DDR中输入特征的排序方式Fig.6 Sorting order of input features in DDR
2)Line_buf。由4 个独立的line buffer 组成,分别编号为0、1、2、3。每个line buffer 为BRAM 实现的单端口RAM,端口位宽为PDi× 8 bit,深度Line_buf_LEN 由CNN 模型的最大特征图尺寸决定,即每个line buffer 可存储PDi个通道的1 行特征数据。PE 每次开始计算前,需首先将输入特征图的1、2、3行从Fin_buf依次写入0、1、2 号line buffer;然后便可以每个时钟周期3×PDi个特征数据的速度向Fin_reg 供应数据;与此同时,开始向3 号line buffer 写入第4 行特征数据。当0、1、2号buffer中的数据完成一次计算后,3号line buffer中的数据也刚好写入完毕;此时,便可开始将1、2、3 号line buffer 中的数据供给Fin_reg,开启2、3、4 行特征图的计算;同时开始向0 号line buffer 写入第5 行特征数据。以此类推,计算开启后,总有3 个line buffer 在向Fin_reg 供应数据,而另一个line buffer从Fin_buf缓存数据,整个过程好似Line_buf在旋转。
3)Fin_reg。与Line_buf类似,由4组独立的Fin寄存器组成,分别编号为0、1、2、3。每组寄存器都由触发器(Flip-Flop,FF)实现,可缓存3×PDi个特征数据,等于每次可从Line_buf读取的数据量。当0、1、2组寄存器依次写满后(需要3个时钟周期),PE 单元便可开始工作,Fin_reg 每个时钟周期向PE 单元供应3× 3×PDi个数据;当下一个时钟周期到来时,第3 组寄存器已从Line_buf 取得数据,Fin_reg 便可将1、2、3 组寄存器中的数据供给PE 单元,同时向第0 组寄存器写入数据。以此类推,每行开始计算后,总有3 组Fin 寄存器向PE 单元供应数据,而另一组寄存器从Line_buf 读取数据,整个过程好似Fin_reg在旋转。
总体来看,MCRP 没有在输入通道并行的基础上增加对Fin_buf 的带宽需求;经过Line_buf 和Fin_reg 旋转寄存之后,便可在每个时钟周期向PE单元供应3× 3×PDi个特征数据。不难发现,MCRP结构中Line_buf负责卷积窗口内特征数据的行重用,Fin_reg 负责卷积窗口内特征数据的列重用,从而避免了将卷积层运算转换为矩阵向量乘[9]。对于其他尺寸卷积,MCRP 结构依然适用,只需调整Line_buf中line buffer 的个数和Fin_reg中寄存器组的个数。
2.3 CNN加速器架构
在MCRP 结构的基础上,本文提出了一种针对CNN 算法的FPGA 硬件加速单元(简称CNN 加速器)架构。此架构采用输入输出通道并行+卷积核内并行的方案,为了保证此加速器对于大部分CNN 算法都有较高的硬件利用率,输入通道并行度和输出通道并行度将会被限制在32 以内,当卷积核内并行度为9 时,在250 MHz 的时钟频率下,此加速器架构的理论峰值算力可以达到4 608 GOPS(Giga Operations Per Second),基本可以满足嵌入式领域大部分应用的算力需求。如图7 所示,CNN 加速器主要由控制单元(Control)、片上缓存、计算单元PE共3个功能模块组成。

图7 CNN加速器的整体架构Fig.7 Overall architecture of CNN accelerator
1)控制单元。CNN 加速器是主控ARM(Advanced RISC Machine)的从设备,ARM 可以通过控制单元启动CNN 加速器,并通过AXILite 接口读取Status_reg 查询加速器的运行状态。除了与ARM 通信和协调外,控制单元的另一功能是控制CNN加速器其他功能模块的运行:控制各模块间的数据流,配置各模块的具体参数及功能、控制各模块的启动时序。具体工作过程为:当ARM 启动控制单元开始工作后,控制单元通过m_AXI 总线从DDR 读取指令序列;把指令解码后,根据指令中的信息以及Status_reg、Control_reg 的信息控制其他功能模块工作;当执行到最后一条指令时,即完成一次CNN 算法的前向计算后,控制单元产生中断信号,通知ARM计算完成。
2)片上缓存。片上缓存由Fin_buf、W_buf 和Fout_buf 共3 部分组成,都是由BRAM 实现,通过m_AXI 总线与片外存储DDR 进行数据交换。其中,Fin_buf 是MCRP 结构的一部分,用于缓存输入特征;W_buf用于缓存权重数据,写端口位宽为PDi× 8 bit,读端口位宽为PDi× 3× 3× 8 bit,深度W_buf_LEN 视情况而定;对于Fout_buf,需要3 个端口同时读写中间结果和写出最终结果到外部DDR,1 块双端口RAM 不能满足要求,因此设置了两片完全相同的输出特征缓存区,每片的读/写端口位宽均为PDo× 12 bit,深度Fout_buf_LEN 视情况而定。由此通过乒乓操作,可让中间结果的读写和最终结果的导出同时进行。
3)计算单元。计算单元是CNN 加速器的算力核心,由PDo个乘-加法树和3 个寄存器组成。乘-加法树的结构如图8 所示,由3× 3×PDi个乘法器和(3× 3×PDi-1)个加法器组成,为了避免因加法树过大而拖慢工作频率,还需在加法树中间插入寄存器,使得加法树变为多级流水线结构。每个乘-加法树负责PDi个输入通道的3× 3 卷积窗口内的乘累加运算,每个时钟周期从Fin_reg 和W_reg 分别获取输入特征和权重数据,并向Conv_reg 写入乘累加结果。一共PDo个加法树,各对应一个输出通道,因此计算单元可在一个时钟周期完成3× 3×PDi×PDo次乘累加运算(MAC),即计算单元的计算并行度可以达到3× 3×PDi×PDo。寄存器组包括Fin_reg、W_reg 和Conv_reg,都是由FF 实现。其中,Fin_reg 也是MCRP结构的一部分。W_reg 用于缓存从W_buf 获取的PDo个卷积核的PDi个通道的权重数据。由于W_reg 所需的数据量较大,难以在一个时钟周期内全部获取,因此设置2 个完全相同的W_reg,使得计算操作和权重数据的获取操作乒乓同时进行,同时也降低了对W_buf 的带宽需求。Conv_reg 用于获取Fout_buf 中的中间结果或偏置数据,与计算结果累加后写回Fout_buf。

图8 乘-加法树Fig.8 Multiplication-adder tree
3 实验及结果分析
3.1 实验环境
为了验证MCRP 结构以及CNN 加速器架构的设计合理性,采用XILINX的ZCU102开发板进行实验验证。ZCU102搭载的XCZU9EG 芯片为XILINX 的Zynq UltraScale+系列MPSoC,片上资源丰富,可基本满足实验要求。利用可编程逻辑(Programmable Logic,PL),即FPGA 部署CNN 加速器,通过输入输出通道并行度和卷积核内并行度的大小,最大限度地利用片上的DSP 资源,具体超参数设置如表3 所示。处理系统(Processing System,PS)端的ARM-Cortex-A53 作为系统主控,通过AXI Lite 总线与CNN 加速器交互,控制其运行。此外,ARM 还用于CNN 算法的预处理、后处理、监视CNN 加速器的运行状态和性能等。
本文以经典的SSD-300[6]作为测试算法,因为SSD 算法在目标检测与识别领域应用广泛,且计算量巨大。SSD 算法的部分计算并不适合硬件加速,对其进行软硬件划分:主干网络的CONV1~9 层、FC6~7 作为硬件加速部分,由CNN 加速器负责;剩余的所有计算和处理作为软件部分,由ARM 负责。硬件部分的参数量为183.48 Mb,每次前向推理的计算量为60.93 GOPS。因为访问一次外存DRAM 所消耗的能耗是访问一次片上SRAM 所消耗能量的128 倍以上[21],所以为了尽可能降低功耗,需将DDR 的读写次数降到最低,本文以SSD-300 所有层的输入输出特征、权重数据只从外部DDR 读写一次为目标,设置CNN 加速器的片上缓存(输入特征缓存、权重数据缓存、输出特征缓存)深度,具体如表3 所示。在这一条件下,CNN 加速器计算SSD 的硬件部分时的DDR 交互量达到最小,为460.60 Mb。换句话说,本文提出的CNN 加速器可根据CNN 算法的规模,灵活调整片上缓存大小,使得计算过程中DDR的交互量最小,整个加速器的功耗达到最低。

表3 CNN加速器的超参数Tab.3 Hyperparameters of CNN accelerator
实验流程为:首先,对训练好的SSD 算法进行定点量化,将其权重和偏置量化为8 bit 的定点数,并对量化后的参数根据CNN 加速器的要求进行重排序,生成.para 文件。然后,根据SSD 算法的网络结构(硬件部分)以及DDR 的内存空间,编译生成由自定义指令集组成的指令序列,得到.instruction 文件。在VIVADO 2019.1 中对CNN 加速器设计进行综合、布局、布线后生成bit 文件。然后在XILINX 的SDK 2019.1 中进行相应的软件开发,得到BOOT.bin 文件。最后,将.para 文件、.instruction 文件、BOOT.bin 文件一并下载到SD 卡中,ZCU102采用SD 卡启动的模式,开启实验。实验过程中,使用摄像头不断从外界采集图像,ZCU102 通过UART 串口实时向上位机回传检测结果以及性能、功耗等参数。
3.2 结果分析
在250 MHz 的时钟频率下,PL 端的资源利用率如表4 所示。可以看出,DSP 的利用率非常高,其中2 272 个用于PE 单元的乘-加法树搭建,2个用于控制单元中的参数计算。由表3中的各类并行度超参数的大小可知,本加速器PE单元一共有4 608个乘法器,其中4 544个乘法器由DSP实现,剩余的64个由查找表(Look Up Table,LUT)实现,这是Vivado 为了布线方便、自动优化的结果。DSP的利用量基本决定了CNN加速器的算力,DSP利用率越高,表明CNN加速器的架构设计越合理,越能充分利用硬件平台的片上计算资源。BRAM的利用率适中,表明本文以相对较小的片上缓存做到了DDR交互量最小。触发器(Flip Flop,FF)和LUT 的资源利用率都没有超过50%,表明此CNN 加速器架构设计合理,不需要过多的逻辑资源便可实现加速器的完整功能,为片上部署其他加速算法和实现用户自定义接口保留了充足的逻辑资源和片上存储资源。
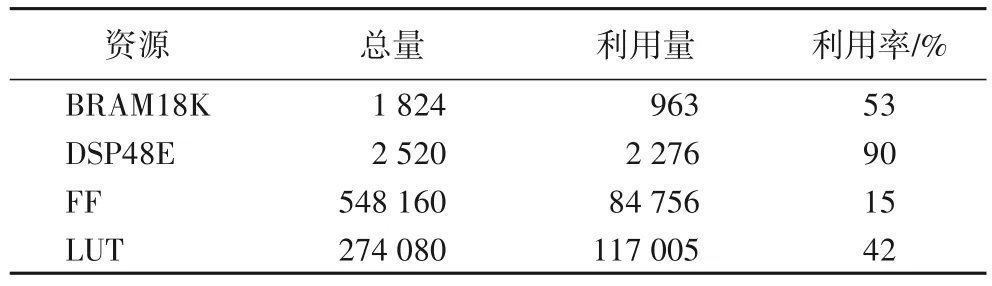
表4 PL端的资源利用率Tab.4 Resource utilization on the PL side
SSD-300 硬件部分各层的运行时间及硬件利用率等详细信息如表5所示。在表3的宏参数设置下,CNN加速器的峰值算力为2 304.00 GOPS,计算SSD-300 时,实际算力为1 830.33 GOPS,硬件的平均利用率达到79.44%。从表5可以发现,每层的工作负载越大,其硬件利用率越高,这是因为此加速器是专门针对较高算力需求场景而设计的。观察发现,fc-7、conv6-1、conv7-1、conv8-1、conv9-1 层的硬件利用率均低于9.5%,这是由于本CNN加速器是针对3× 3卷积设计的,对于1× 1 的卷积效率较低。但是在大部分较高算力应用场景中,1× 1 的卷积在CNN 算法中的计算量占比很低(低于10%),因此,整个CNN 算法在本加速器中依然可以达到较高的硬件利用率,如SSD-300,可达到79.44%的硬件利用率。
整个计算过程中,ARM 同步调用CNN 加速器,处理一张300×300 的RGB 图像平均需要67.02 ms,其中PS 端的软件部分平均耗时34.1 ms,PL 端的硬件部分平均耗时32.92 ms,软硬件部分耗时基本相当。在实际应用中,可以让ARM 异步调用CNN 加速器,使得软硬件消耗时间重叠,总消耗时间变为软/硬件部分耗时的最大值,以提高系统的整体性能。作为对照实验,关闭PL端的CNN 加速器,只用ARM-Contex-A53单核处理一张300×300 的RGB 图像平均需要172 792.2 ms。因此,与单核ARM 相比,CNN 加速器对SSD-300 算法的硬件部分的加速比为5 247.82。
表6 列出了3 类基于FPGA 的CNN 加速器,为了方便比较,本文将其分别命名为加速器A[22]、加速器B[23]和加速器C[24]。加速器A、B 的目标器件是XC7VX690T,其PL 端拥有3 600个DSP,比本文的目标器件XCZU9EG 多出1 080个DSP,但加速器A、B的算力远低于本文的加速器,主要有两个原因:首先是它们的加速器架构未充分利用PL 端的DSP 资源;其次是因为它们利用的数据类型位宽较宽,加速器A 的特征数据为16 bit 整型、权重数据为8 bit 整型(在表5 中表示为INT16/8),加速器B 的特征数据和权重数据均为16 bit 整型,均大于本文所采用的位宽。加速器C 所使用的器件为XCVU440,拥有2 880 个DSP,但其算力只有本文加速器的42.89%。比较发现,本文提出的CNN加速器架构可充分利用PL端的DSP资源,并能达到较高水平的算力。
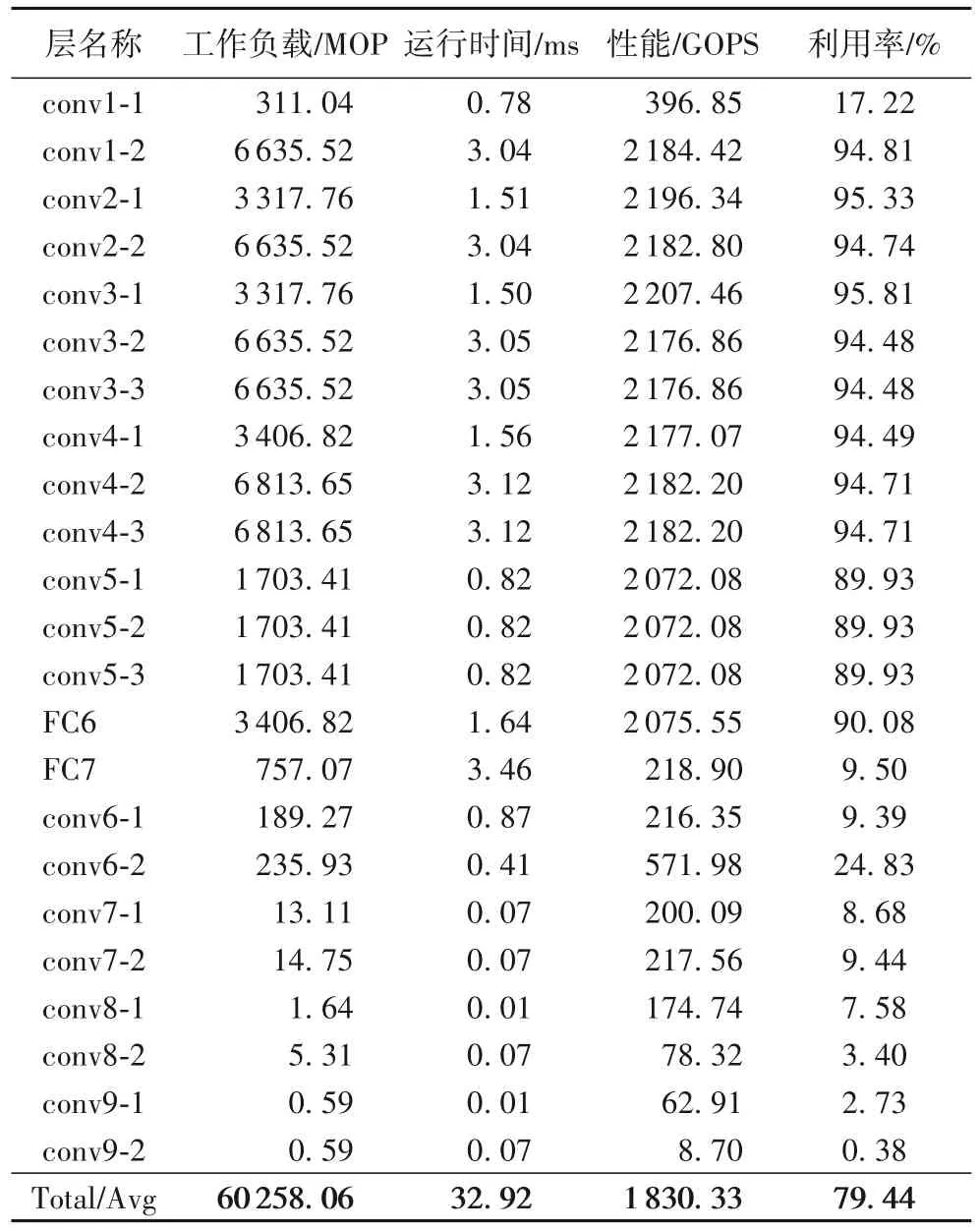
表5 SSD-300各层的计算性能对比Tab.5 Computing performance comparison of different layers of SSD-300

表6 不同基于FPGA的CNN加速器的比较Tab.6 Comparison of different FPGA-based CNN accelerators
4 结语
本文在比较分析CNN 算法各类并行度的基础上,提出了不同算力等级的CNN 加速器并行度选择方案。为了简洁有效地利用CNN 算法的卷积核内并行,提出了多通道卷积旋转寄存流水(MCRP)结构,此结构在只增加少量逻辑和不增加片上缓存带宽的条件下,可将CNN 加速器的并行度在只利用输入输出通道并行的基础上提高9 倍。在MCRP 结构的基础上,本文选择输入输出通道并行+卷积核内并行的方案,提出了一种CNN 加速器架构。此架构的理论峰值算力可在保证硬件利用率的条件下轻松达到4 608 GOPS,能够满足嵌入式领域大部分应用的算力需求。
为了验证本文CNN 加速器的设计合理性,将其部署到XILINX 的XCZU9EG 芯片上。在充分利用片上DSP 资源的条件下,CNN 加速器的峰值性能达到2 304.00 GOPS。以SSD-300为加速目标,硬件利用率达到80.96%,与单核ARM 相比,加速比达到5 283.1。与其他基于FPGA 的CNN 加速器相比,无论是峰值算力,还是实际的硬件利用率,都达到了较高水平,表明MCRP 结构可有效提高CNN 加速器的算力。此加速器目前存在的不足之处在于,它对1× 1的卷积硬件利用率过低,在未来的研究中,将设法突破数据带宽和数据流的限制,提高加速器对于1× 1卷积的硬件利用率。
