基于模糊聚类算法的智能电子档案自动分类方法
2021-03-17田丰杨洋
田丰,杨洋
(衡水市人民医院, 河北 衡水 053000)
0 引言
作为文化事业单位,电子档案馆负责接收和管理各类档案,方便社会服务。伴随着社会水平的不断提高,人们对档案的要求也越来越高,档案分类的概念也不断深化,数字化档案服务需要智能化、个性化和知识化。相关学者为简化电子档案搜索步骤,进行了大量研究[1-2]。
文献[3]在多云服务器环境下,考虑到恶意TPA可能会窃取用户隐私的情况,提出一个支持批量审计的数据拥有性证明方案,远程校验用户数据是否完整存储于云服务器,有效抵抗恶意云服务器的攻击,保证针对恶意云服务器的安全性;文献[4]采用多进程和多线程的软件框架,对多源导航的验证周期进行预处理,实现大数据量、高实时性和高并发性的导航信息采集,并利用TCP/IP协议族搭建多导航传感器数据采集系统,其精确性、拓展性得到提高;文献[5]引入噪声过滤机制,提出增量式学习的数据流集成分类算法,以增量式C4.5决策树为基础,检测概念漂移,保持数据流抗噪性,提高分类器加权集成模型的动态更新效果,实现检测概念的准确性和抗噪性优化。
但传统方法进行电子档案智能分类的智能性较差,特征辨识能力不强,对此,本文提出基于模糊聚类算法的智能电子档案自动分类方法,展示了本文方法在提高电子档案智能分类能力方面的优越性能。
1 电子档案信息自动分类系统设计
设计智能电子档案系统需要考虑外界运行条件,以系统信息安全为目的。在设计硬件时需要考虑系统运行与维护的成本,在软件设计中需要考虑保障电子档案信息自动分类的准确性与效率。具体硬件与软件设计如下文所示。
1.1 电子档案自动分类硬件设计
电子档案信息自动分类系统基础硬件设计中采集数据模块选择8通道、内置16位和双极性输入的AD芯片,可以保证电子档案信息的同步采样;系统线性动态范围设置在10~20 dB;根据电子档案系统的安全特性需求,选择网络并行接口设计。网络基础配置为千兆自适应交换机下的局域网;服务器硬件CPU不低于3.2 GHz,内存16 GB,硬盘500 GB,千兆网卡;操作系统环境可选Microsoft Windows2007及以上的版本。
为了保证智能电子档案分类系统的数据存储模块与数据分类的动态连接,排除干扰信号,在电路端口处接入Sallen-Key低通滤波器,可以有效滤除干扰信号,维护系统的稳定性。Sallen-Key低通滤波器,如图1所示。

图1 Sallen-Key低通滤波器示意图
至此,完成了智能电子档案信息自动分类系统硬件部分的设计。
1.2 电子档案自动分类软件设计
在档案馆中,通常只有档案馆工作人员才有录入和修改档案的权限。档案管理员将档案属性和附件发送到业务逻辑层,进行处理,再将档案信息存储到本地数据库、磁盘和区块链数据保护子系统中。当点击新增档案界面和更新档案界面的“保存”按钮后,新增或更新表单的档案属性和附件信息会被发送到存储控制器中,执行添加或修改的操作,再将相关信息同步到区块链数据保护子系统中。普通用户可以通过该系统进行查询、验证和借阅操作,档案管理员可以对用户和档案进行管理操作,整个搜索过程具有繁杂性且技术要求高,为此进行电子档案智能信息采集和特征分析,优化电子档案自动分类方法。
1.2.1 电子档案智能信息采集
为了实现基于大数据平台的电子档案智能分类,基于多样本特征信息采样方法,构建电子档案信息采集模型,结合电子档案信息的特征分布,进行电子档案信息的综合数据采集,采用模糊信息特征分析方法,进行电子档案智能分类的大数据分析,结合模式识别方法[4-5],建立电子档案智能分类模型,提高电子档案智能分类管理能力。实现结构图,如图2所示。
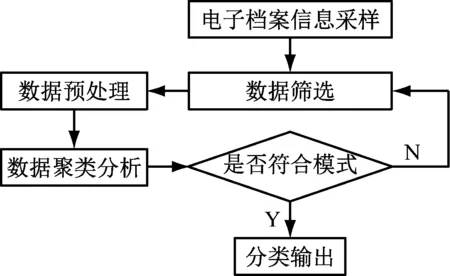
图2 电子档案智能分类实现结构图
根据图2所示的电子档案信息采样模型中,构建电子档案信息融合模型,采用模糊信息融合方法,进行电子档案信息分类[6-7],构建电子档案信息参数融合模型,得到特征分布集,如式(1)。

(1)
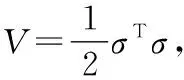
(2)
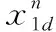
1.2.2 电子档案信息融合处理
提取电子档案信息的信息熵,采用关联规则特征分布式挖掘方法,进行电子档案信息融合和自适应调度[9],结合运行状态特征检测方法,构建电子档案信息的统计分析模型,如式(3)。
u(t)=Cn[f(X,t)+p(t)+K]
(3)
式中,K表示总特征统计值。通过对电子档案信息的特征提取结果,进行特征重构,采用空间分布式融合方法,建立电子档案信息融合模型,分析电子档案信息大数据的关联规则集[10-11],采用空间分布式融合技术进行电子档案信息的高分辨组合,得到组合后的主成分特征量,如式(4)—式(6)。
(4)
(5)
(6)
式中,A/B表示电子档案信息的模糊特征分量;θ表示电子档案信息大数据的谱分解系数;fg表示电子档案信息的采样率;fm表示电子档案信息状态点的频率。在电子档案信息的运行过程中,采用关联规则特征检测方法实现对电子档案信息的谱特征检测,得到电子档案信息的运行状态监测的频率分量,在采样分布区域中,得到电子档案信息状态监测模型,如式(7)。
x(t)=[1+Acos(2πfg+N)]
cos[2πfmt+Bsin[2πfg+φ]+N]
(7)
式中,N表示电子档案信息的谱峰值。考虑到电子档案信息的显著性特征[12],得到电子档案信息统计特征值表达式,如式(8)。
(8)
式中,φ表示显著特征值。根据上述分析,建立电子档案智能分类的特征检测模型,根据大数据分类结果,进行信息融合和分类识别。
1.2.3 电子档案的分类特征提取
提取电子档案信息的信息熵,采用关联规则特征分布式挖掘方法,进行电子档案信息融合和自适应调度,电子档案信息的运行状态属性分布集,如式(9)。
(9)
结合相似度特征分析方法,提取电子档案信息的关联规则特征集,拟合电子档案信息状态统计特征量,如式(10)。
(10)
式中,Vj表示电子档案信息的自相关特征量,其中电子档案信息特征分布集,如式(11)。
(11)
结合模糊度特征检测方法,进行电子档案信息分类识别,得到电子档案信息融合特征分布集,如式(12)。
fs=θj,kN
(12)
采用主成分识别方法,进行电子档案信息融合,得到特征判决式,如式(13)。
(13)
式中,L表示电子档案信息特征分量。计算电子档案信息的模糊度特征量,如式(14)。
(14)
式中,μ表示电子档案智能分类的阈值系数,结合统计特征分析方法,进行电子档案信息的特征提取[13]。
1.2.4 电子档案自动分类
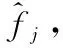
(15)
式中,
(16)
将电子档案信息的运行状态数据进行特征分解,结合统计特征聚类分析方法,得到电子档案智能分类矩阵X的奇异值分解结果,如式(17)。
X=UDVT
(17)
式中,U∈Rm×m表示电子档案信息综合数据的特征分布正交矩阵,V∈RM×M,初始化电子档案信息定位的聚类中心F(xi,Aj(L)),i=1,2,…,mj=1,2,…,k。
求出其个电子档案信息的特征值λ1,λ2,…,λl,采用空间特征点分布的偏离值,根据电子档案信息的属性特征,进行电子档案信息分类,得到分类结果,如式(18)。
(18)
式中,SURE(ωm,μ,L)表示电子档案信息的关联规则项。
结合神经网络学习方法,构建电子档案智能分类器,如图3所示。

图3 神经网络分类器
如图3所示,在用户层,为不同领域的信息资源、不同的数据集成和网络检索工具提供所支持的资源聚合描述规范,同时资源聚合描述可以将更大范围的异构数据联合起来,为用户提供良好的导航工具,扩大检索范围,提高信息检索能力;在资源层,可采用试点运行的方法建立数据整合标准,包括集合级的描述、对象级的描述、子资源聚合以及它们之间关系的描述,通过这些描述实现分布式信息检索、对象级资源的定位、异构信息系统之间的操作非常重要;在互操层,异构信息系统间的互操作不同于对资源对象的描述,具有分布式的特点,具有很多的层次,描述的对象位于不同信息系统,因此,这些描述对象的格式、数据结构、类型和检索接口等都是异构的。立体、动态资源聚合描述规范能够实现异构资源对象间的无缝组合,实现异构信息系统间的互操作。至此,实现基于模糊聚类算法的智能电子档案自动分类设计。
2 仿真测试分析
为了验证本文方法在实现电子档案智能分类的应用性能,进行仿真实验分析,在Kaggle(https://www.kaggle.com/datasets)平台中进行电子档案信息的采样,最终样本数为1 200,对初始电子档案信息采样率f0=1 kHz,模糊相关性特征分布系数为0.15,对电子档案信息采样的带宽为80 dB,相关性系数为σ0=0.2,β=5,m0=0.9,根据上述仿真环境和参数设定,进行电子档案智能分类,得到采集的电子档案数据,如图4所示。

图4 电子档案信息数据采集
以图4的电子档案信息综合数据采集为输入,提取电子档案信息的关联规则特征集,拟合电子档案信息状态统计特征量,实现电子档案数据分类,得到分类结果,如图5所示。

图5 分类结果输出
分析图5得知,在进行分类结果输出时,本文方法对输出点的拟合程度较高,说明本文方法进行电子档案分类的智能性较好,可应用于实际。
测试电子档案智能分类的精度,将本文方法与文献[3]批处理数据拥有性证明方案、文献[4]实时并行采集处理与传输系统、文献[5]新型含噪数据流集成分类的方法进行对比,得到对比结果,如表1所示。
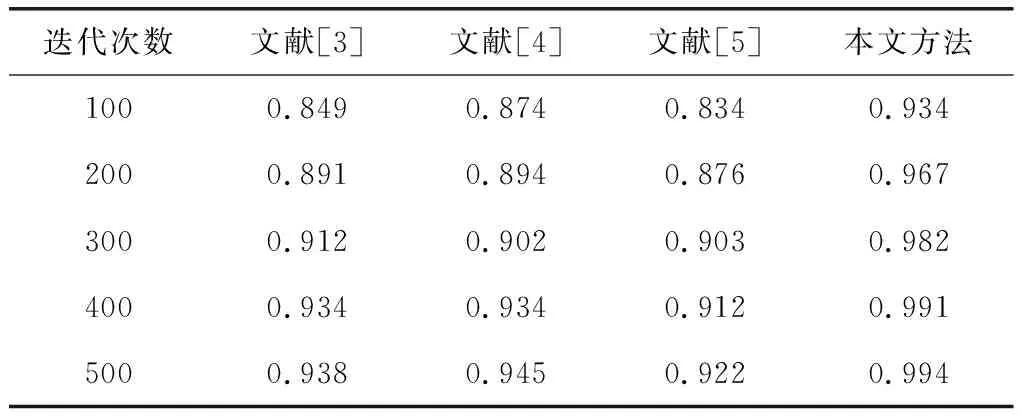
表1 电子档案智能分类的精度对比
分析表1得知,在不同的迭代次数下,本文方法进行电子档案智能分类时,精度值皆高于其他文献方法的精度值,说明其定位精度较高。
不同的电子档案信息采样模型,其空间特征的分布式融合程度不同,即信息融合程度不同,档案信息分类结果也受到限制。将本文方法与文献[3]、文献[4]和文献[5]方法进行对比,如图6所示。
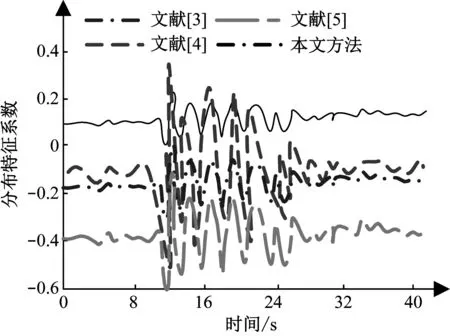
图6 不同方法信息融合程度对比结果
由图6可知,在40秒时间内,与其他文献方法相比,本文方法模糊相关性特征分布系数可保持在0.15左右,说明本文方法对特征分布情况掌握较好,可实现电子档案信息分布式检测,因为本文采用关联规则特征分布式挖掘方法,进行电子档案信息融合和自适应调度,提取电子档案信息的统计特征量,实现局部信息拟合。
考虑到电子档案信息的显著性特征,本文在对采集的电子档案信息大数据进行模糊聚类和特征分布式融合处理后,进行电子档案信息融合和自适应调度,其调度结果体现电子档案分类效率,也就是说,在相同的自相关特征量限制下,调度时间短,电子档案信息分类效率越高。不同方法信息分类效率对比结果,如图7所示。

图7 不同方法信息分类效率对比结果
由图7可知,与其他文献方法相比,本文方法的分类时间一直保持在6秒左右,因为本文基于多样本特征信息采样方法构建电子档案信息采集模型,其模型可实现信息融合和自适应调度,分类效率高,具有良好的实际应用效果。
3 总结
1.本文提出基于模糊聚类算法的智能电子档案自动分类方法。建立电子档案智能聚类分析模型,采用模糊信息聚类方法,进行电子档案智能分类,提高电子档案信息的分类能力。
2.经过仿真实验分析得知,本文方法进行电子档案分类的智能性较好,且分类效率和实际应用性得到验证,提高了电子档案的自动化管理能力,可为该领域的相关研究提供参考。
