在线学习环境下个性特征混合挖掘研究
2021-03-17倪政林
倪政林
在线学习环境下个性特征混合挖掘研究
倪政林
(马鞍山职业技术学院 电子信息系,安徽 马鞍山 243031)
:针对在线学习特征挖掘的全面性不足及智能化教育发展的需要,提出了一种混合式多智能技术挖掘方案。较全面分析与总结了个性特征的组成要素及各要素包含的主要因子。分别采取了关联数据挖掘、Top-N聚类算法、联合概率分布、K-均值聚类算法、协同过滤算法等技术对不同特点的要素进行挖掘。实验及调查结果表明这种结合多要素运用多技术进行混合式特征挖掘具有较高的准确性。
在线学习;个性特征;数据挖掘
伴随移动互联与5G技术的普及与应用,以及应对突发公共卫生安全事件,近半年来,线上教学受到了国内外教育界广泛的关注与大规模的运用。在线教育的发展为人工智能与教育深度融合的理论与应用研究提供了良好的契机和环境。智能化教育的研究课题有很多。其中,利用人工智能技术对在线学习个性特征进行数据挖掘与科学评估的研究[1-4]是一个重要方向,具有较强的现实意义。一方面为教师下一步的教学安排与个性化指导提供重要参考,另一方面减少了因人为因素导致的偏见,对教育的公平、公正具有重要意义,同时也减轻了教师的部分负担。
1 个性特征的组成
在线学习环境下,个性特征的组成要素主要有学习资源的偏好、能力倾向、学习风格、在线学习时间特点、学习效率等,各要素又包含了若干因子,具体如表1所示。各要素间具备一定的关联关系。个性化的资源偏好与能力倾向间存在两种联系,一是正相关联系,具备高度拟合的特点,另一是不相关联系,能力与偏好兴趣相背离。资源偏好与能力倾向影响了学习风格的形成。资源偏好影响了在线学习时间分布。学习效率受到资源偏好、能力倾向、学习风格及学习时间综合的影响。

表1 在线学习特征要素与主要组成因子
2 特征挖掘
2.1 资源偏好





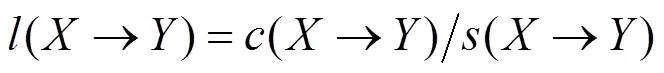
2.2 能力倾向
(1)考查因素。个体学习能力包含某一方面或多方面,同时能力的强弱也是相对而言。在线环境下,主要通过资源学习、所花费的时间、测试内容结果等对能力倾向特征进行间接地挖掘与评估。能力倾向与学习资源类型、所用时间、测试内容与结果间的联系如表2所示,其中,1,2等分别为表1中直播、动画等组成因子;1,2等分别为表1中填空、选择等组成因子。

表2 能力倾向与资源类型、学习时长、测试内容与结果间的联系


(2)Top-N聚类挖掘算法。为了提高挖掘的效率和降低运行成本,设定分组为注意力(1)、记忆力(2)等7个。能力倾向的Top-N算法描述如下:
第1步:建立原始数据集。通过公式(5)计算出第人在种资源的平均资源学习效率,形成原始数据集{(i, j, Ec)}。其中,取测试因子最大集元素个数,为集合中的元素下标,如:1对应的测试因子集为{1,2,3,4,7},5且1, 2, 3, 4, 7;其余见表2。

第2步:对第一步的结果集依据进行分组和降序排序,每组取Top-10值,将相应的值并入f对应的E分组中(=1~7)。删除{(,,Ec)}中所有包含值的三元组元素。
2.3 学习风格
通过浏览页面的顺序和内容对学生的学习风格进行挖掘。页面浏览顺序和资源内容通过文献[7]技术获取,页面浏览顺序信息用于挖掘顺序和全局型学习风格,资源内容用于挖掘直观感觉、视觉、言语、反思型学习风格。
(1)顺序与全局。萃取页面关键词或主题词[8],建立个体关键词频次集{(11), (2,2),…,(k,m},k为关键词、m为其出现的次数。设关键词集={1,2,…,k},子集⊆,联合关键词的概率()定义为式(6),其中,=(k1,k2,…)。若()的值随着集合中元素的增加而呈高度拟合的线性上升,则为全局型风格,否则为顺序型风格。

(2)直观感觉、视觉、言语、反思。挖掘技术类似本节第1点,依据表1中的资源偏好因子对浏览资源内容进行分类、汇总与统计,建立资源因子频次集{(1,1),(2,2),…,(12,12)},1,2等分别为表1中的直播、动画等资源因子。设资源因子集{1,2,…,12},子集⊆。不同于第1点的是联合资源因子取值方式不同,联合因子集及其概率()定义见表3所示,最高值对应的类型即为挖掘的学习风格类型。

表3 联合因子集及概率P(X)定义
2.4 时间特点
时间特点主要指挖掘学生在线自主学习时长及分布状况。
(1)在线学习时长。通过正态分布函数公式(7)预测在线学习时长特点。时长主要有15min内,15~30min,30~45min,45~60min,60~90min,90min以上6种类型。
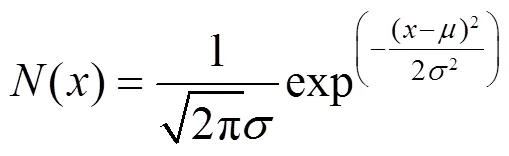

2.5 学习效率




3 实验与问卷调查
3.1 实验结果
为了验证和评估各算法或方法在个性特征方面挖掘的效率,基于本校MOOC平台数据,开展了仿真实验。收集了学生在线学习的后台访问记录135260条作为挖掘的原始数据集,其中包含了10个专业及300人,各专业人数与记录个数分布具体见表4。启动模型系统,线程数迅速增加,约20s左右达到峰值,之后逐渐回落,约10s后达到稳定状态,线程数保持在70左右上下摆动,持续了1分左右,所有线程运行结束,产生了个性特征数据300组,系统运行状态如图1所示。

表4 专业人数及记录数据分布

图1 系统运行状态
为了进一步验证数据记录的数量对系统挖掘效率及稳定性的影响,选取了1, 3, 7三个专业,进行了分组对比实验,运行状态如图2所示。图2中,3个专业的达到峰值时间、进入稳定状态时间基本一至,随着记录数据的增多峰值及稳定状态线程数量略有提升,三者的线型基本保持一至,系统挖掘性能较为稳定。

图2 专业1, 3, 7系统挖掘运行状态
3.2 问卷调查
为了评估挖掘的准确性,开展了问卷调查。针对实验的300人,发放了个性特征5个要素预测结果的评价问卷,在收回的问卷中抽取出5个要素都有效的问卷279份,经过统计汇总,各项评价人数分布如表5所示。汇总各要素的不同准确性并进行均值计算,得到总体评价:非常准确、比较准确、准确、一般、不准确分别占91.25%, 6.88%, 1.00%, 0.50%, 0.36%。针对评价为准确、一般、不准确的26人做了进一步的电话专访,总结其中的原因归纳为两点:一是线上学习的习惯不同于一般情况,从而导致了采集的数据中“噪音”较大;另一是数据挖掘前没有对“异常数据”作处理。

表5 准确性的评价结果
4 结束语
作为人工智能技术与教育深度融合的基础,对在线学习特征挖掘做了专项性研究。分别采取了关联数据挖掘、Top-N聚类算法、联合概率分布、K-均值聚类算法、协同过滤算法等技术对个性化资源偏好、能力倾向、学习风格、在线时间特点及学习效率五个方面进行挖掘。
从实验及问卷调查结果看出,采用多智能技术对在线学习特征进行多方面混合挖掘,具有较高的准确性和运行效率、较强的实际应用价值、个性评价的客观公正性及全面性。本课题为智能化教育的进一步研究提供基础,也为其它领域相关研究提供参考。
对实验结果与调查中发现的原始数据“噪音”问题的解决,将是下一步要研究的内容。
[1] 刘晓,飞朱斐,伏玉琛,等. 基于用户偏好特征挖掘的个性化推荐算法[J]. 计算机科学,2020, 47(04): 50-53
[2] 王改花,傅钢善. 数据挖掘视角下网络学习者行为特征聚类分析[J]. 现代远程教育研究,2018(04): 106-112
[3] 谢康. 基于读者个性化特征数据挖掘的图书馆书目推荐[J]. 现代电子技术,2018(41): 34-36
[4] 程艳,解建华,谭平飞,等. 面向虚拟学习社区的学习行为特征挖掘与分组方法的研究[J]. 江西师范大学学报:自然科学版,2016(06): 640-643, 647
[5] 刘儒德. 学习心理学[M]. 北京:高等教育出版社,2010
[6] Graf S, Viola S R, Leo T, et al. In-depth analysis of the felder-silverman learning style dimensions[J]. Journal of Research on Technology in Education, 2007, 40(1): 79-93
[7] 袁红,张海潮. 基于搜索时间序列聚类的网络用户搜索策略识别[J]. 图书情报工作,2016, 60(20): 94-103
[8] 李芳芳,葛斌,毛星亮,等. 基于语义关联的中文网页主题词提取方法研究[J]. 计算机应用研究,2011, 28(1): 105-107, 123
Research on hybrid mining of personality characteristics in online learning environment
NI Zheng-lin
(Department of Electronic Information, Ma'anshan Technical College, Anhui Ma'anshan 243031, China)
Aiming at the lack of comprehensiveness of online learning feature mining and the need for the development of intelligent education, a hybrid multi-intelligence technology mining scheme is proposed. A more comprehensive analysis and summary of the constituent elements of personality characteristics and the main factors contained in each element. Respectively adopt associated data mining, Top-N clustering algorithm, joint probability distribution, K-means clustering algorithm, collaborative filtering algorithm and other technologies to mine elements with different characteristics. Experiments and survey results show that this combination of multiple elements and multiple technologies for hybrid feature mining has high accuracy.
online learning;individual characteristics;data mining
2020-08-03
安徽省高校自然科学研究重点项目(KJ2018A0948);安徽省质量工程高水平教学团队项目(2018jxtd101)
倪政林(1969-),男,安徽和县人,副教授,硕士,主要从事数据挖掘、模式识别、教育信息化研究,945784143@qq.com。
TP311.13;G434
A
1007-984X(2021)01-0016-05
