广西大风短临预报预警方法的研究与应用
2021-03-16周冬静卓健毛家燊陈少斌苏彦郭彬奉意杰蒋亚平赵丽萍
周冬静,卓健,毛家燊,陈少斌,苏彦,郭彬,奉意杰,蒋亚平,赵丽萍
(崇左市气象局,广西崇左 532200)
大风致灾性高,容易造成较大的经济损失和人员伤亡[1]。目前有关大风的研究主要集中在个例分析和成因分析上[2-8],大风短临预报的准确率偏低[9]。造成大风短临预报预警存在较大困难的主要原因:第一,强对流天气系统的中小尺度结构和发展机理研究仍是当前强对流天气研究中的难点,大风形成的各种尺度系统和气象条件相互影响,错综复杂,瞬发性高、局地性强,留给预报员预判到发出预警的反应时间非常有限,预报难度大;第二,在日常业务工作中,预报员根据所掌握的理论知识和经验,依据天气雷达和其他探测资料对大风天气进行预报预警,预报员的主观经验差异对预报结果影响比较大;第三,此前多种研究表明,概率越低的天气越难预报,在强对流天气事件中,大风发生概率较低,这也是大风短临预报困难的客观原因。
崇左短临预报预警创新团队利用人工智能技术开发了一系列短临预报预警产品,其中广西大风短临预报预警系统是为解决实际业务中提高大风预报的准确率和大风预警的有效提前量问题而研发的子系统。该系统经过业务试运行和产品检验,经评估具有较好的预报准确率和提前量。
1 数据和产品
广西大风短临预报预警系统集实况监控、预报和预警于一体,使用来源于全国综合气象信息系统(CIMISS)的2017—2018年广西全区所有4要素以上自动站观测数据进行建模。系统于2019年6月建成并开始业务试运行,产品包括逐6 min更新发布广西各自动站0~1 h发生蓝色预警大风和黄色预警大风的概率预报产品。该系统根据广西大风预警信号发布的业务规定,模拟预报服务人员发布大风预警信号的行为方式,选择最优TS模型给出0~6 h各市县所辖区域发布大风蓝色和黄色预警建议。图1为2019年8月13日15:36(北京时,下同)系统自动读取和生成的广西风实况和0~1 h大风概率预报预警系统界面。
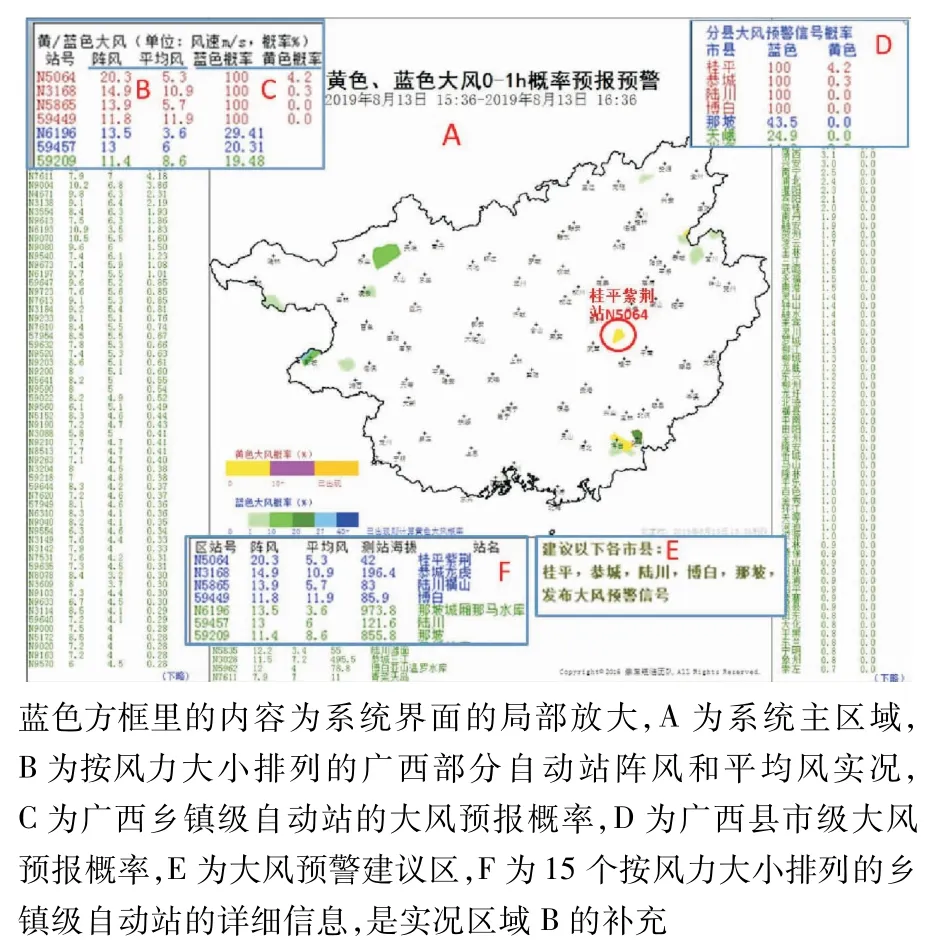
图1 2019年8月13日15:36的系统界面显示
2 方法
广西大风短临预报预警方法的研究基于机器学习和人工智能技术。本研究主要介绍用概率论、数理统计和信息论的知识对自动站大量历史数据进行数据挖掘的方法。
2.1 马尔科夫假设与马尔科夫链
概率论对随机变量的研究发展到对随机过程的研究之后,为解决随机过程由于多维度变量的不确定性造成的复杂度过高导致难于进行研究,马尔科夫提出了一种简化问题的假设,即随机过程中各个状态St的概率分布,只与它的前一个状态St-1有关,这一假设的提出使得以前许多不好解决的问题给出了近似解。这个假设被命名为马尔科夫假设,符合这个假设的随机过程则成为马尔科夫过程,也被称为马尔科夫链。两状态马尔科夫链可以用图2表示,其中S0、S1为不同状态,下一个时次状态不变化时称为状态自旋,状态发生变化称为状态转移,P10、P01为不同状态的转移概率,P00、P11为不同状态的自旋概率。

图2 两状态的马尔科夫链
广西大风短临预报预警方法的研究正是基于马尔科夫简化问题的假设思路。本研究假设选定的预报因子对预报结果是独立影响,而且预报结果只与预报因子上一时次的状态有关。
2.2 用信息熵公式筛选预报因子
信息熵是对变量不确定性的量化,要消除变量不确定性所需要的信息量越多,信息熵的值就越大。信息熵(H)的公式可以写为

如某地有或无大风是等概率事件P=1/2,大风的熵为

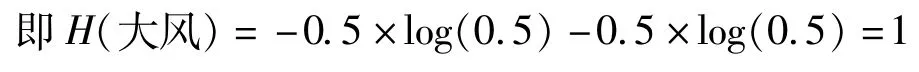
实际上,大风天气是一个小概率事件。从本研究用于建模的数据统计发现,广西某地出现蓝色大风以上级别的事件的概率为0.004,非大风概率为0.996,根据信息熵公式可知,大风的熵

假如通过引入其他额外信息能有效减少大风的信息熵,则可以说明引入的这个额外信息是有效的信息,有助于业务人员做大风预报。假设以X代表大风,增加的有效信息用Y表示,那么X和Y一起出现的概率为联合概率分布,在Y取不同值的前提下X的概率分布称为条件概率分布,此时定义条件熵(Conditional Entropy):
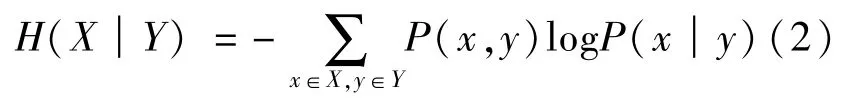
信息论创始人香农(Claude Shannon)对X和Y是两个随机事件相关性提出了一个用于量化度量的概念:互信息(mutual information),互信息定义见式(3),互信息就是熵 H(X)和条件熵H(X|Y)的差异(式(4)):
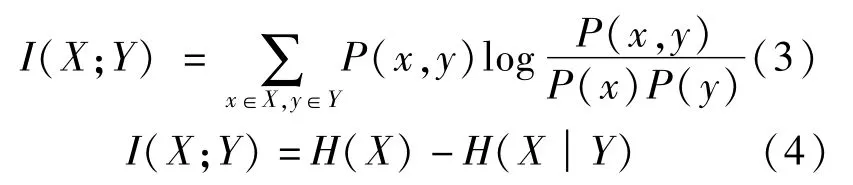
寻找一种使用自动站观测数据作为预报因子的大风预报方法,做出这种选择的理由主要是由于自动站观测数据量大,适合使用数据挖掘方法建模。作为一种简化处理手段,本研究假设预报因子是有效的信息,预报因子对预报结果是独立影响。建模首先将2017—2018所有广西四要素自动站的所有观测数据,逐一计算不同信息的引入对测站下一时次大风信息熵的缩减量,通过计算,认为阵风和平均风力数据适合用来作为进行大风概率预报的预报因子。
2.3 构建广西大风概率预报的统计模型
本研究把历史风力数据(共计30 529 816个样本)按阵风和平均风分开统计和计算。蓝色预警大风的标准为平均风力10.8~13.8 m/s,或者阵风13.9~17.1 m/s;黄色预警大风的标准为平均风力 17.2~20.7 m/s,或者阵风 20.8~24.4 m/s。在建模时,在0~24.5 m/s风力范围内,按0.1 m/s的等距分别统计历史上246个不同阵风和平均风风力对应下一时次(未来0~1 h)无大风、蓝色预警大风、黄色预警大风、橙色预警大风和红色预警大风的次数,并以此统计数据作为概率预报的基础。
2.4 用联合概率公式计算预报概率的方法
1)单站预报概率。
根据单站当前实况和广西大风概率预报统计模型的对应关系,利用联合概率公式计算单站的大风预报概率。以图1为例。图1中有4个站的实况已经达到大风蓝色预警级别,蓝色概率直接记作100%。以N6196站蓝色概率29.41%为例介绍单站预报概率的计算方法。假设P(A)表示以阵风统计的历史蓝色预警大风的概率,P(B)表示以平均风统计的历史蓝色预警大风的概率,不出大风的概率分别为1-P(A)和1-P(B)。根据蓝色预警大风的定义,利用式(5)计算单站蓝色预警大风的概率:

通过计算不出蓝色预警大风的联合概率,再反向计算至少有一种情况(阵风或平均风)出大风的概率作为单站蓝色预警大风的预报概率。用式(5)计算表 1的数据,P(A)=0.293 296,P(B)=0.001 151,P(N6196蓝色)=0.294 109。单站出蓝色预警大风后系统开始计算黄色概率,计算方法与蓝色概率同理。
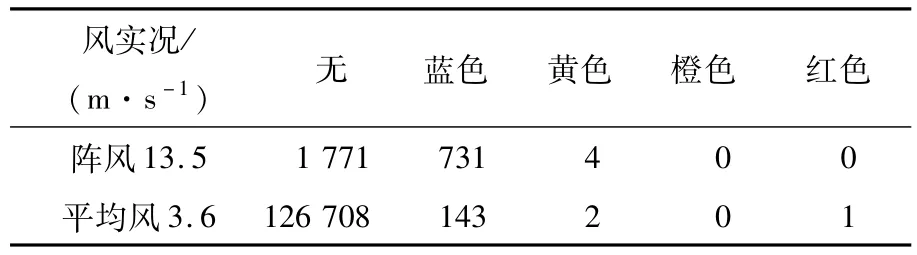
表1 单站风实况对应广西大风概率预报统计模型历史数据 次
2)分县预报概率。
分县预报概率的计算方法与单站预报概率相似,都用到了联合概率的公式。不同的地方在于,计算单站预报概率时只是阵风统计概率和平均风统计概率的二维联合概率,计算分县预报概率时要用某县所辖所有四要素区域站的单站预报概率来计算联合概率。同样,先逆向计算所有站都不出大风的概率,再计算至少有一个站出大风的预报概率作为分县预报概率。
2.5 大风预警产品
根据《广西壮族自治区气象灾害预警信号发布业务服务暂行规定》(桂气发[2008]264号),广西大风预警采用分县制作发布与传播机制,由各县预报服务人员发布所辖区域大风预警信息。本研究模拟人工发布大风预警信息的流程,对某一区域达到一定起报阈值后发布一个指定时段的大风预警信息,并且在有效预警时段内,根据大风概率预报产品的变化决定是否升级预警信号,有效预警结束后,根据最新的大风概率预报产品决定是否解除或继续发布预警信号。根据这个思路,本研究对大风概率预报产品的全概率模型进行数据分析,找出能获得最优TS评分的模型。通过计算,认为只要某县出现以下情况之一时,系统就自动给出发布大风蓝色预警信号的建议:单站蓝色概率达到27%;单站平均风达到8.8 m/s;单站阵风达到 12.7 m/s;分县蓝色概率达到30%。某县只要单站或者分县的黄色概率达到2%,系统就会给出发布大风黄色预警信号的建议。大风预警信号建议通过文字和地图上的色块体现。
3 产品检验
3.1 预报准确率检验
系统的预报准确率用TS指标来检验,如表2所示,并做以下2种情况的检验对比:
①全时段检验。2019年7月11日至2019年9月11日期间,系统对广西全区89个县级台站所做的所有大风蓝色预警和大风黄色预警,用同时段内全区所有4要素以上区域自动站的大风实况进行检验分析。
②去除高山站检验。由于高山站出现大风概率较高,现行业务规定允许各地气象局不将高山站纳入大风预警考核,为检验系统在不统计高山站数据的情况下的预报和预警能力,本研究对2019年7月11日至2019年9月11日期间出现大风概率最高的北流和武鸣两个站的预警信号做屏蔽处理,从表2可以看出在把高山站屏蔽之后系统预报准确率有所降低,这也可以看出系统预报性能符合此前专家得出的概率越小的事件预报难度越大,预报准确率越低的结论。

表2 系统大风短时临近预报的TS检验对比 %
3.2 时效性检验
用C表示预警信号时间提前量,用有效预警的时间提前量t来检验预警信号的时效性,即预警信号提前时间总和与应发预警信号次数及预警空报次数之和的比值。
在2019年7月11日至9月11日期间,去除部分高山站的数据后,系统模拟预报服务人员发布0~6 h广西各市县大风蓝色预警和大风黄色预警信号共计1 652条,如表3所示,其中NA为有提前量的正确预报站(次)数、NB为空报站(次)数、NC为漏报站(次)数。

表3 系统在2019年7月11至9月11日期间内去除部分高山站后的预警提前量检验 次
有效预警的时间提前量t=14.71 min。从表3中还可以看出,有提前量的预警NA占实际出大风预警总数(NA+NC)的 30.65%;提前量<60 min的预警(短时临近大风)占有提前量预警的约2/3。
4 结论
广西大风短临预报预警系统使用信息论作为理论基础,采用大数据挖掘技术进行研发,系统高频次监控实时数据,及时更新概率预报产品,所以对突发性较高的大风能做出有效的预报和预警,具有一定的准确率和提前量,适合业务运用。
系统模拟预报服务人员发布预警信号的方式发布一定时长的预警信号,在预警时效内根据数据的变化决定是否提升预警等级,在预警时效结束后,根据最新的数据决定是否继续发布预警信号。通过一年的业务试运行,产品稳定、更新及时、预警效果良好。
系统受概率统计方法取样的局限性和马尔科夫假设取近似值的影响不可避免。由于样本不足(该系统只取了2年的数据样本),只用全区所有4要素区域站的大风历史数据来笼统地计算和构建广西大风概率预报统计模型,没有足够的数据支持细化每个乡镇级观测站或者每个县级站的大风概率预报统计模型。如何在天气预报领域利用数据挖掘技术,挖掘海量气象历史数据的有用信息为实际的气象预报服务,是以后继续努力的方向之一。
