基于长短时记忆神经网络的生猪价格预测模型
2021-03-16刘怡然王东杰邓雪峰刘振宇
刘怡然, 王东杰, 邓雪峰, 刘振宇
(1. 山西农业大学 信息与电气工程学院, 山西 晋中 030801; 2. 中国农业科学院 农业信息研究所, 北京 100081)
近年来,生猪价格市场的异常波动受到社会舆论的广泛关注,及时准确地掌握生猪价格的变化趋势对确保农产品市场平稳健康发展有重要意义.如果能够对生猪价格进行预测,决策者能够合理地调控生猪市场价格,养殖户也可据此调整圈舍中仔猪、种猪和育肥猪存栏量,因此,生猪价格预测成为研究者密切关注的领域.
早期的生猪价格预测模型结构相对单一,模型泛化能力较差,预测精度难以保证[1].随着计算机计算能力的提升,生猪价格预测模型的复杂程度越来越高,从单一的灰色系统模型、向量自回归模型、神经网络模型等趋于日渐复杂的组合模型[2-3].LI Z. M.等[4]以生猪历史价格为依据,将遗传算法优化的混沌神经网络用于生猪价格的短期预测,能够预测20 d的生猪价格.任青山等[5]将多元回归分析和反向传播神经网络(back propagation neural network, BPNN)结合,提高了生猪价格预测的准确性和可靠性.然而,生猪价格存在伪周期现象,即生猪价格周期是重复出现的,但又不是完全重复,采用固定序列长度对生猪价格进行预测并不十分合适[6-7].为了解决这一问题,姜百臣等[8]引入集成经验模态分解(ensemble empirical mode decomposition, EEMD)方法剖析“猪周期”价格波动原理,并结合遗传算法(GA)优化的支持向量机(SVM)建立了生猪价格预测模型.LIU Y. R.等[9]设计了一种相似子序列搜索算法并将其与支持向量回归模型组合,排除了生猪价格周期成分在时间轴上的弯曲和伸缩造成的干扰,解决生猪价格预测过程中序列周期长度不固定的问题.
随着生猪价格及其影响因素数据量的积累,可以采用深度学习的方法解决这一问题.LSTM神经网络使循环神经网络(recurrent neural network, RNN)自循环的权重视上下文而定,而不是固定的.由于LSTM积累的时间尺度可以动态改变,非常适合解决生猪价格序列预测问题[10-11].
因此,针对生猪价格的伪周期现象,文中提出萤火虫算法优化长短时记忆神经网络(firefly algorithm-long short term memory, FA-LSTM)的生猪价格预测方法.首先采用萤火虫算法搜索LSTM的参数,再根据得到的最优参数建立预测模型,将本算法与其他经典机器学习预测算法进行比较,具有更高的预测准确度.
1 预测模型
1.1 生猪价格预测方法总体流程
生猪价格序列属于典型的非线性时间序列,且由于其周期变化的特点,采用LSTM神经网络对其进行预测,考虑到其关键参数对预测结果影响非常大,因此采用萤火虫算法对LSTM模型进行参数优化.具体方法流程如图1所示.

图1 基于FA-LSTM的生猪价格预测方法总体流程
1.2 LSTM神经网络
长短时记忆神经网络适用于解决非线性时间可变时间序列预测问题[12].LSTM的单元结构如图2所示,其关键是类似于“传送带”的单元状态Ct(cell state),通过输入门、遗忘门和输出门的调节,决定哪些信息可以送上“传送带”.解决了循环神经网络多次展开中导致的梯度爆炸和梯度消失问题,令其能够处理长时间依赖[13-15].

图2 LSTM的单元结构
遗忘门决定上一时刻的单元状态信息有多少可以保留到当前时刻,则
ft=σ(Wf[ht-1,xt]+bf),
(1)
式中:ft表示遗忘门;ht-1为上一个单元状态的输出,它与当前时刻的输入xt共同拼接成一个输入矩阵;Wf和bf分别表示遗忘门的权重矩阵和偏置;σ为sigmoid激活函数.
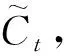
it=σ(Wi[ht-1,xt]+bi),
(2)
(3)
(4)
式中:W和b分别表示相应的权重矩阵和偏置.
根据当前单元状态,通过输出门ot决定当前输出信息.
ot=σ(Wo[ht-1,xt]+bo),
(5)
ht=ottanhCt.
(6)
进行LSTM训练时,采用均方误差(mean squared error,MSE)作为损失函数,其定义如下:
(7)

训练LSTM时,由公式(1)-(6)得到单元状态输出后,由公式(7)可以得到存储单元的误差项,根据误差项更新权重梯度和权重,文中采用自适应动量估计算法(adaptive moment estimation, ADAM)更新权重[16].
1.3 萤火虫算法
LSTM神经网络需要调节的参数较多,主要包括隐含层数目、隐含层神经元数、学习率、批次大小等参数等.因此,需要结合参数搜索算法得到合适的参数进行网络设置优化.与粒子群优化(partical swarm optimization, PSO)等算法相比,萤火虫算法在解决嘈杂的非线性优化问题方面有优势,成为一种有利的优化工具[16-18].
萤火虫算法中,搜索过程与萤火虫的相对荧光亮度I和相互吸引度β有关,其定义如公式(8)和公式(9)所示.发光亮的萤火虫会吸引发光弱的萤火虫向它移动,发光越亮代表其位置越好,最亮萤火虫代表函数最优解[16].
I=I0e-γrij,
(8)
(9)
式中:I0表示最亮亮度;γ表示光吸收系数,通常取γ=1;r为两只萤火虫之间的距离;β0为其初始吸引度.每只萤火虫将会朝着所有亮度比自己高的萤火虫移动,其新的位置Xi+1如下:
Xi+1=Xi+β(r)(Xi-Xj)+αrand,
(10)
式中:Xi和Xj分别表示i,j2只萤火虫的空间位置;α为步长;rand为随机移动.
1.4 基于FA优化LSTM的预测模型
为了对生猪价格进行预测,设计了一个具有2层的LSTM网络结构,将萤火虫算法作为目标规划算法辅助寻找LSTM的第1、2隐含层神经元个数、学习率和批次大小.
构建FA优化LSTM的预测模型如图3所示.预测模型的主要步骤如下: ① 初始化萤火虫算法的参数和目标参数值域,主要包括迭代次数、种群大小、光吸收系数γ、初始吸引度β0和步长α,目标参数值域包括LSTM的第1、2隐含神经元个数、学习率和批次大小的取值范围.② 在目标参数的取值范围内,随机初始化一个萤火虫种群,即目标参数组合.③ 将训练集数据分割为训练集和验证集,使用初始的目标参数训练得到LSTM模型,并通过验证集数据计算初始适应度集合,选取其中最佳者作为最佳适应度.④ 判断是否到达最大迭代次数,若达到,则输出有最优适应度相对应的目标参数组合,使用最优目标参数训练得到LSTM模型,若未达到,则进行步骤⑤、⑥.⑤ 计算萤火虫种群亮度,并使每一只萤火虫向更亮的萤火虫移动.⑥ 使用新的种群训练新的LSTM模型并计算新种群的适应度,判断是否有萤火虫的适应度大于最佳适应度,无则直接返回步骤④,有则更新最佳适应度,并记录该适应度对应目标参数组合,返回步骤④.

图3 FA优化LSTM的生猪价格预测模型建立流程图
2 试 验
2.1 数据采集
为了满足LSTM模型训练的需要,采集中国种猪信息网、猪价格网和山东畜牧兽医网等农产品价格网站的生猪价格、猪肉价格、仔猪价格、玉米价格和豆粕价格作为试验数据,相关数据采集情况如表1所示.

表1 数据采集情况描述
2.2 数据预处理
爬虫程序采集的数据在量的单位、采样频率和精确度上存在差异,所以需要经过预处理操作得到正确完整价格序列,以便进行建模和预测.
1) 数据清洗.首先检测缺失值和异常值,对前后时间间隔不大的缺失数据采用线性插值进行了填补,如式(11)所示,对出现的异常数据采用均值平滑法进行处理,如式(12)所示.
(11)
(12)
式中:xa+i为a+i时刻的缺失值;xb为b时刻的异常值;xa、xa+j、xb+i、xb-i为分别为a、a+j、b+i、b-i时刻的有效数据.
2) 数据变换.猪价格网的数据采集范围是全国各县,以省为单位进行统计,得到每日全国各省的平均值.猪价格网的生猪、猪肉和仔猪的价格采样频率是每日1次,然而豆粕价格和玉米价格并非如此,且为了与其他2个数据来源的数据保持一致,采用周平均值将猪价格网的价格序列变换为每周1个样本.经过数据变换后,将3个数据来源的样本整合为一个数据集,得到样本2 131个,其基本情况描述如表2所示.

表2 数据集基本情况描述 元·kg-1
3) 数据规约.因各商品价格数量级有差异,采用式(13)对数据进行标准化处理.
(13)
式中:xi表示原始值,i表示其序号;xm表示序列平均值;xstd表示序列标准差.
4) 参数选择.研究[19-20]表明,生猪、猪肉、仔猪、玉米和豆粕等相关因素的变动都有可能影响生猪价格,然而并不是所有变量都能够对生猪价格预测产生积极影响.为了避免无关变量干扰预测精度,采用主成分分析法(principal component analysis, PCA)和相关系数分析对预测参数进行选取[21-22].由主成分分析得到各个主成分的方差贡献率如下:成分1为0.709 8;成分2为0.229 9;成分3为0.055 0;成分4为0.005 2,前2个主成分贡献了约94%方差,因此选取这2个主成分得到成分矩阵如表3所示.各因素相关系数如下:生猪价格,1.000 0;猪肉价格,0.986 4;仔猪价格,0.894 7;玉米价格,0.255 6;豆粕价格,0.113 2.

表3 成分矩阵
生猪价格、猪肉价格和仔猪价格都对成分1贡献较大,而成分1有70%的方差贡献率;生猪价格与猪肉价格、仔猪价格的相关性都较高,而与玉米、豆粕的相关性较低.因此,选取生猪价格、猪肉价格和仔猪价格作为预测生猪价格的参数.
2.3 试验设计
假设有训练样本集S={X,Y},X为样本特征向量(矩阵),Y为标签,样本集中任意一个样本点i表示为(X(i),Y(i)).若训练集与标签之间有一个长度为l的时间步长,每个样本有长度为m的时间窗口,则有如下表示的样本点(X(i),Y(i)).
1≤i≤n-m-l+1,i∈N,
(14)

为了验证本方法在进行生猪价格预测时的优越性,将本模型产生的结果与BPNN模型和SVR模型等两种经典的浅层预测模型进行了对比,同时也将本模型与另一种循环神经网络门控循环单元(gated recurrent unit, GRU)模型进了对比[23-26].
2.4 参数设置
试验平台硬件配置为Intel(R) Core(TM)i5-7360U CPU@2.3GHz处理器,8 GB运行内存;试验所采用的软件工具为python编程语言和keras框架.
参数优化试验中,萤火虫算法的迭代次数设置为200、种群大小为20、光吸收系数γ=1、初始吸引度β0=1,步长α=0.5[17];LSTM的第1、2隐含神经元个数的搜索范围设置在[1, 100],批次大小的取值范围是[16, 64];LSTM采用Adam算法进行自适应优化,取值范围[0.001,0.1].预测试验中,时间步长l分别取值1、4和8,每次试验的结果都与单隐含层的LSTM、SVR、BPNN和GRU进行对比,SVR、BPNN和GRU的参数也是由萤火虫算法搜索得出的,时间窗口m=16.由于对生猪价格的预测属于时序数据预测,训练集和测试集不宜随机选取,故取数据集的前90%样本作为训练集,后10%样本作为测试集.
3 结果与分析
3.1 评价方法
采用平均绝对误差(mean absolute error,MAE)、均方根误差(root mean squared error,RMSE)和确定系数(Rsquared,R2)评估模型的准确性,计算公式如下:
(15)
(16)
(17)
3.2 模型预测结果
3.2.1 萤火虫算法参数搜索结果
时间步长为1时,利用萤火虫算法对LSTM、SVR、BPNN和GRU模型进行参数搜索的适应度函数值变化如图4所示.FA-LSTM表示萤火虫算法优化的LSTM模型,其他同理.

图4 适应度函数值变化
由图4可知,萤火虫算法能在较少的迭代次数下迅速达到最佳适应度,非常适合进行参数搜索.文中采用的适应度函数是均方根误差的倒数,从适应度曲线的取值可以看出,LSTM模型有较小的训练误差.
为了证明LSTM模型适合对生猪价格的预测,排除参数搜索算法不同或者不进行参数搜索对模型预测准确性的干扰,也采用萤火虫算法对其他预测模型的参数进行了搜索,表4为不同时间步长下各个模型所取得的参数.

表4 不同时间步长下各个模型所取得的参数
3.2.2 对生猪价格的预测结果
时间步长分别取1、4和8时, 3次生猪价格预测结果如图5所示,可以看出FA优化的LSTM模型对真实价格的拟合度较好.
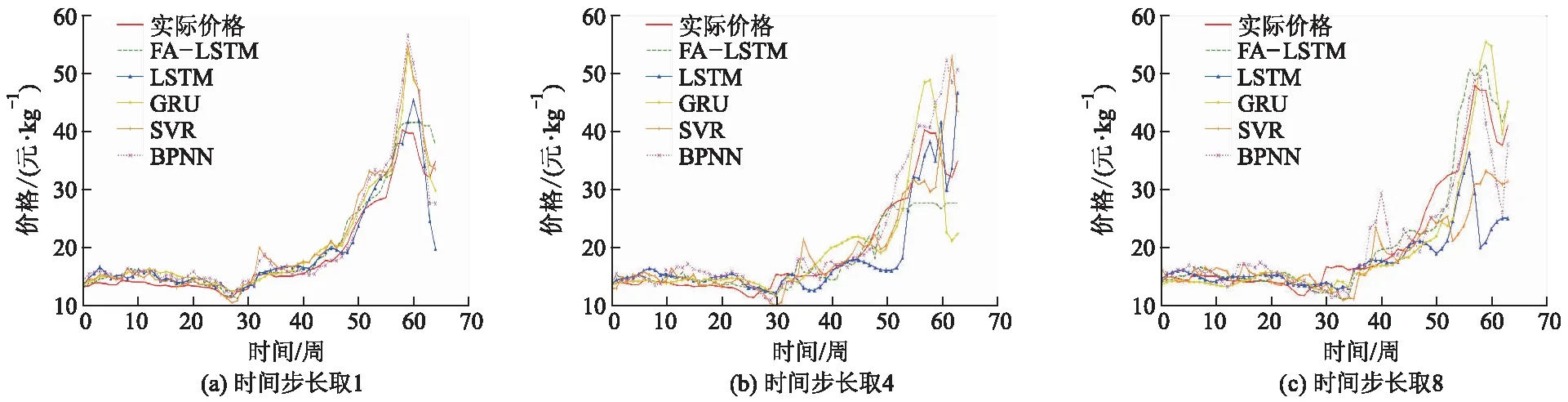
图5 3次生猪价格预测结果
时间步长为1、4和8时,FA-LSTM模型、LSTM模型、FA-SVR模型、FA-BPNN模型和FA-GRU模型对生猪价格预测结果与真实生猪价格的平均绝对误差、均方根误差和确定系数如表5所示.

表5 3次生猪价格预测模型评价参数
由表5可知,在时间步长为1、4和8时,FA优化LSTM都能取得比较好的预测结果,尤其是在时间步长为1时,FA优化LSTM模型的确定系数为92.57%,说明了其对真实价格走势的拟合度较高.当时间步长为1时,与不经过萤火虫算法优化的LSTM模型(其参数设置与GRU模型相同)相比,平均绝对误差和均方根误差分别降低了20.03%和36.71%,确定系数增加了4.88%,当时间步长取4、8时,与不经过萤火虫算法搜寻参数的LSTM模型相比,平均绝对误差和均方根误差也都下降了,而确定系数也都增加了,说明参数的选择对LSTM预测准确率影响非常大,但是人工进行参数搜索效率太低,萤火虫算法大大提升了该模型的参数搜索效率.
由表5也可看出,在时间步长为1、4和8时,各个模型的表现都较为不稳定.FA优化的SVR模型在时间步长取1时,对生猪价格的预测表现比较好,仅次于FA优化的LSTM模型,然而当时间步长取值为8时,它的表现又成为几个模型中最差的.与之相反的是,FA优化的GRU模型在时间步长取1时表现较差,仅优于FA优化的BPNN模型的表现,但当时间步长取8时,其表现能够和FA优化的LSTM旗鼓相当.但FA优化LSTM模型在3次试验中表现均优于其他模型,说明FA优化的LSTM的生猪价格预测模型具有较为理想的泛化性能,可以很好地拟合非线性变化的生猪价格.
虽然LSTM每个时间步长和权重的计算复杂度为O(1),且其每个时间步上权重是共享的,但萤火虫算法、粒子群算法、人工蜂群等一系列启发式算法都是NP-hard问题,导致现有试验条件下参数搜索阶段时间仍较长.其他相似的研究也存在这样的问题,在试验的后期使用阿里云服务器ECS,缩短了程序执行时间,所使用配置为Intel Xeon Platinum 8163处理器(8核,2.5 GHz),16 GB内存.由于训练数据是相同的,可以从目标参数搜索范围和步长设置上对萤火虫算法进行分级,采用分布式的参数搜索方式也可以对萤火虫算法进行自适应步长的改进.
4 结 论
1) 考虑到生猪价格序列在时间轴上的迟滞问题,提出了一种基于长短时记忆神经网络算法的生猪价格预测模型,首先对生猪价格数据进行预处理操作,并采用萤火虫算法对长短时记忆神经网络进行了参数优化,能够快速找到合适的长短时记忆神经网络参数,再利用经过优化的参数建立LSTM预测模型.
2) 所建立的基于长短时记忆神经网络的生猪价格预测模型,能够预测未来1周、1月和2月的生猪价格,与传统的浅层预测模型和未经优化的长短时记忆神经网络模型相比,提出的预测模型在不同时间间隔内的预测结果都具有更高的预测准确度.
3) 文中提出的生猪价格预测模型具有良好的预测性能和泛化能力,不仅能够为制定稳定生猪市场的决策提供量化分析工具,也能为其他农产品价格的预测提供参考.
