基于Hadoop的高校校园大数据平台构建
2021-03-16黄少聪
黄少聪
(福建工业学校 信息教学部,福建 福州 350001)
当前,随着校园信息化的建设的快速发展,传统的管理方法逐渐不能满足日益增长的数据积累和管理需求。各个时期不同的信息系统形成的“数据孤岛”,数据资源无法共享;高校每年成千上万名新生入学,积累了大量的数据,这些数据不仅数量级大,数据结构也多样。各类校园数据规模日益庞大,数据利用不充分,缺少稳定高效的大数据环境,这些都对高校校园数据的研究提出了挑战。针对以上问题,基于大数据核心技术Hadoop构建校园大数据平台,对海量校园数据进行采集、存储,分析和应用,实现大数据汇聚整合,可以实现校园中信息的互联互通,体现了校园数据的实时性和价值性,能够对师生进行个性化服务,提高工作效率,为高校建设以及科学管理提供重要的依据。
一、Hadoop大数据处理的意义
随着互联网技术的快速发展,随之迎来大数据时代的来临,需要对日益增长的数据资源进行存储、处理与分析,并从中发现有价值的信息,需要先进的分析技术作支撑。Hadoop是Apache的一个用Java语言实现的开源软件框架,能够实现在集群中对海量数据的分布式处理和分析。Hadoop具有高可靠性、高扩展性、高效性和低成本的优点,用户可以轻松架构和开发分布式程序,应用研究主要涉及大数据存储、日志处理、ETL、机器学习、搜索引擎、数据分析与挖掘等领域[1]。
经过多年的发展,Hadoop核心功能在不断完善的同时,也衍生出多个功能组件,共同构成了Hadoop生态系统,成为大数据处理的业内事实标准。近年来,国内应用和研究Hadoop的企业越来越多,主要以互联网行业为主,包括百度、阿里巴巴、腾讯、360、中国移动等。
同样的,很多高校也投入到Hadoop的应用和研究中,目前各高校都在寻找符合自身特点的大数据应用开发模式,通过对遍布教、学、研多层面的数据进行整合,并结合对大数据技术的有效利用,可以从根本上给教学、科研、就业等带来全方位的提升,培养大数据人才,深化管理促进高校的改革发展。例如:清华大学的大数据研究平台,湖南大学的国云大数据云分析平台。
二、基于Hadoop的校园大数据平台架构
本文基于Hadoop生态集群,以构建基础工具层为底层支撑,将智慧校园相关的人、财、物、网络等结构化、半结构化和非结构化数据[2],采集到Hadoop集群中进行分布式文件存储,通过Hive和HBase构建共享数据中心,采用 Storm、Spark、MapReduce等分析方法,以各种可视化图形的方式,将结果展示给用户,满足业务需求,体现数据价值。平台架构如图1所示,主要包括五层:基础工具层、数据源层、数据采集层、数据分析层、数据应用展示层[3]。

图1 高校大数据平台架构
基础工具层以现有的信息化硬件为底层基础,包括网络资源、云服务平台、机房物理设备等,通过基础支撑层为大数据平台提供统一认证、统一授权、日志管理、系统监控、运维管理等基础性服务。
数据源层包含有来自各个异构系统的数据,大致包括结构化数据、半结构化数据和非结构化数据三块[4],为大数据的分析提供支撑。一是来自传统的结构化数据,主要包括各信息系统中数据,一般以关系型数据库进行存储;二是来自海量半结构化数据,包括上网日志、微博、微信等;三是非结构化数据,主要包括校园监控、楼宇门禁等实时流数据[5]。
数据集成层包括数据的采集和存储。该层通过灵活的对接适配,与校内各信息系统对接,采集数据源层提供的异构数据,并为数据提供清洗、转换、整合、存储等基本管理功能。结构化数据采集可以采用Sqoop将关系型数据库(如Oracle、MySQL等)中的数据导入Hadoop的HDFS、Hive或者hbase表中[5]。对于非结构化数据,可以采用基于分布式处理Flume技术,快速有效采集服务器上的日志数据,最终发送到HDFS中进行存储。数据采集将数据整理后可靠的迁移到Hadoop系统中,确保数据的一致性和资源的有效利用。
大数据分析层使用数据操作系统Yarn来对平台中的资源进行统一管理和调度,从全新的视角辅助学校各项业务的开展与决策。平台可以根据不同的应用场景,选择合适的数据处理框架对数据进行处理。常用的有内存计算框架Spark和并行计算框架MapReduce。Spark适合应用在对实时性要求较高的大数据场景,例如:使用Spark SQL进行分布式数据快速查询和实时推荐;使用Spark Streaming可以实现高吞吐的,具备容错机制的海量流数据的处理;使用Spark GraphX进行高效的图计算[6]。而MapReduce适合进行批量海量数据的离线处理,例如:ETL,日志处理场景,数据挖掘与统计机器学习应用场景,数据采集与处理场景等。
数据应用展示层为不同的主体展示数据分析,根据需求制定针对性的数据报表,为用户推送信息,为师生用户的相关活动提供数据依据,用户可以查询分析结果,掌握对各项教学和管理工作的分析和判断,从而提高工作学习效率。针对数据分析和挖掘成果形成应用场景,建立个性化数据门户,通过建立校园大数据平台得到有价值的信息并以可视化方式展现给用户[5]。
三、系统实现
(一)Hadoop平台的搭建
Hadoop是运行在Linux,虽然借助工具也可以运行在Windows上,但是建议还是运行在Linux系统上。关于Hadoop平台的搭建,有多种模式可以进行安装架构,主要的安装模式有单机模式,伪分布式和完全分布式三种。本文采取虚拟机安装Hadoop完全分布式集群模式搭建。
1.配置实验环境
搭建形成完全分布式Hadoop集群,在服务器上做实验,通过VMwareWorkstation虚拟机架设四台服务器,均安装CentOS6.4X64bit,一台做NameNode,Job-Tracker,服务器名为 master。另外 3台做DataNode,Task-Tracker,服务器名分别为 slavel,slave2,slave3。配置静态 IP地址,修改文件vim/etc/hosts添加集群中所有机器的IP与主机名,使master和所有slave能够通信,并关闭防火墙和selinux,完成master和slave之间双向SSH无密码登录[7]。
2.实验中安装的软件版本
使用默认的root用户,将需要的软件全部安装在root用户下,并完成Hadoop文件的配置,将配置好的文件拷贝到其他3台slave机器上。这样基本搭建已经完成,形成节点之间的连接。
3.测试Hadoop集群
对于Hadoop集群的测试,在用start-all.sh启动集群后,可以用jps命令和实例进行验证集群是否安装配置成功。另外也可以通过用hadoop-examples-3.30.jar中自带的wordcount程序进行测试,该程序的作用是统计单词的个数。当HDFS启动完毕后,可以访问http://localhost:50070进入HDFS的可视化管理界面,在此页面中可以对整个HDFS集群进行监控以及文件的上传和下载。

表1 软件环境
(二)数据导入HDFS
由于校园大数据平台中很大一部分数据是结构化数据,来源于各个阶段开发的各类信息系统,比如 Oracle、MySQL、SQL Server、DB2 等关系型数据库,下面介绍一下Sqoop工具,用来在Hadoop(Hive)和关系型数据库之间传输数据。
1.MySQL数据导入到HDFS。
首先,在完成Sqoop的安装后,需要加载mysql驱动包到sqoop/lib目录下,然后可以这样测试sqoop是否可以连接到mysql:

如果能够显示数据库的库名说明连接mysql数据库ok。使用如下步骤和命令完成mysql数据的导入。
(1)列出 MySQL数据有哪些数据库:sqoop list-databases
(2)列出MySQL中的某个数据库有哪些数据表:sqoop list-tables
(3)创建一个具有相同名字和相同表结构的表:sqoop create-hive-table
(4)sqoop导入:sqoop import——hive-import
2.sqoop导出数据到Mysql数据库
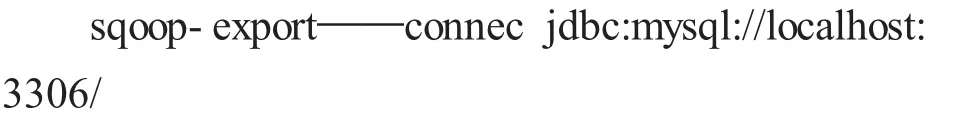
同样的,SQLserver、Oracle及其他使用jdbc连接的关系型数据库也可以在Hadoop中导入和导出。
四、结语
Hadoop分布式架构平台在大数据的处理和分析上有着巨大的优势,极大程度解决了与日俱增的海量数据处理问题,并且在其快速普及的同时,也有极强的发展前景。本文结合高校实际,设计基于Hadoop技术的大数据平台,研究了Hadoop技术在教育信息化领域的应用,对其功能、架构及搭建过程做了介绍,模拟搭建集群环境,经过数据交互测试,验证平台搭建成功,为后续工作打下坚实基础。下一步的工作是在大数据平台下进行有关算法研究,例如基于校园一卡通数据,对学生在校行为数据进行挖掘研究[7],构建学生行为分析系统,引导学生健康发展。
