基于Bi-LSTM和自注意力的恶意代码检测方法
2021-03-16唐永旺
唐永旺 刘 欣
1(中国人民解放军战略支援部队信息工程大学信息系统工程学院 河南 郑州 450002)
2(32088部队 北京 100000)
0 引 言
恶意代码是指故意编制或设置的、对网络或系统会产生威胁或潜在威胁的计算机代码。最常见的恶意代码有计算机病毒、特洛伊木马、计算机蠕虫、后门、逻辑炸弹等。恶意代码随着互联网的蓬勃发展而不断发展,现在呈现出变种数量多、传播速度快、影响范围广的特点。根据Symantec公司的报告,每天有将近百万的变种病毒在互联网中横行,已经成为威胁互联网安全的关键因素之一[1-2]。传统的主流恶意代码检测技术可分为两类:基于签名特征码和基于启发式规则的检测方法[3]。基于启发式规则的检测方法通过专业的研究人员分析恶意代码进行规则制定,并依照制定的规则对代码样本进行检测,但该方法的规则严重依赖人工选取,容易引起高误报率。另外,面对日益庞大的恶意代码数量,仅依赖人工进行恶意代码分析变得愈发困难。基于签名特征码的检测方法根据恶意代码二进制文件的特征码,在恶意代码库中通过模式匹配的方式检测恶意代码,该方法具有速度快、效率高、误报率低等优点,是当前网络安全公司广泛采用的方法。然而,该方法没有利用恶意代码样本的深层特征进行分类,恶意代码经过简单变形或者混淆即可躲避该方法的检测。
恶意代码检测的本质是一个分类问题[4],即把待检测样本区分成恶意或合法的程序。从早期的机器学习算法如K近邻算法(K-Nearest Neighbors,K-NN)、决策树(Decision Tree,DT)、支持向量机(Support Vector Machines,SVM)、随机森林(Random Forest,RF)等,到深度学习模型如卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN)、生成式对抗神经网络(Generative Adversarial Nets,GANs)等多数应用于分类问题。例如Vyas等[5]抽取恶意代码的元数据特征、编译的特征、DLL特征和引入函数特征,生成28维的特征向量,利用K近邻、决策树、支持向量机、随机森林等实现恶意代码分类。CNN多被应用于计算机视觉领域,对图像、视频等数据进行识别分类[6-8];RNN多被应用于自然语言处理领域,擅长处理序列数据分类问题[9-11]。
鉴于深度学习自动提取数据深层特征的优点,深度学习算法下的恶意代码检测思想被提出,目前是业内研究的热点。Yuan等[12]将Android App所需权限,敏感API和某些动态行为相结合提取200维的特征向量,通过深度置信网络训练Android恶意App的分类器。Lindorfer等[13]结合Android App的动态特征(文件操作、网络行为等)和静态特征(App名字,App结构,权限需求等),提取特征向量后训练Android App分类器。Saxe等[14]从恶意代码上下文比特、PE端口号和PE元数据中提取1 024维特征向量,利用3层的神经网络模型和分数校准模型训练恶意代码分类器。
在实际环境中,一些恶意代码具有很强的反沙箱技术,一旦恶意代码发现自身正在被分析,就会切换运行流程,避免被查杀,动态特征难以提取。另外,这些方法在提取特征时还是建立在人工分析、制定规则的前提下,并没有实现真正的智能化。而且人工分析时并没有通过分析整个恶意代码获取恶意代码的深层特征,这样会丢失一些存在于代码本身的逻辑关联特征,如果恶意代码改变格式约定,隐藏恶意代码片段的区域,以上方法就无法正确区分恶意代码。
RNN可以挖掘恶意代码字节序列数据中的逻辑关系特征,以RNN最后一个时刻的隐状态或者各时刻隐状态的拼接作为提取的关联特征。但是,该特征无法突出表现恶意行为的端口、函数等之间的调用关系特征。自注意力机制[15]广泛应用在自然语言处理领域,用于挖掘与当前预测词关系紧密的上下文词语。由此推断可以通过自注意力机制关注字节序列中表现恶意行为的元素,从而在提取恶意代码字节序列特征时对这些位置的隐状态给予更高的权重。
综上所述,本文提出一种基于Bi-LSTM和自注意力机制的恶意代码检测方法。首先,将恶意代码文件转换为长度统一的字节流序列,每个字节元素(范围为[0x00,0xff])用256维的独热(One-hot)编码表示。采用Bi-LSTM根据字节序列的上下文隐状态充分学习序列的特征,输出各时间步的隐状态。然后,利用自注意力机制为表现恶意的时间步隐状态分配更高的权重,将各隐状态的线性加权和作为样本序列的深层特征表示。最后,将该特征表示输入到全连接神经网络层和Softmax层,输出样本的预测概率,完成恶意代码检测。
1 相关背景
1.1 RNN模型
RNN模型[16]通过隐含层的不断循环,可以对恶意代码字节序列数据进行学习,实现恶意代码样本的分类。RNN的模型结构如图1所示。
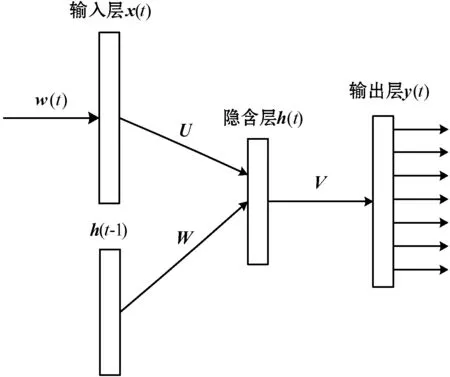
图1 RNN模型结构图
图中的模型由输入层、隐藏层、输出层及相应的权重组成。恶意代码序列中每个字节元素采用One-hot编码方式表示,作为输入向量w(t),维数为256。输出向量y(t)代表在给定当前整型数据向量w(t)和上下文整型数据向量h(t-1)的情况下,整个恶意代码序列的概率分布。输入层、隐藏层和输出层的计算公式如下:
x(t)=w(t)+h(t-1)
(1)
(2)
(3)

h(t)=f(Uw(t)+Wh(t-1))
(4)
y(t)=g(Vh(t))
(5)
式中:U为输入层和隐含层之间的权值矩阵;W为隐含层的自连接权值矩阵;V为隐含层与输出层之间的权值矩阵。神经元之间的影响程度取决于连接权重,且权重在网络神经元中共享。网络采用通过时间的反向传播算法训练参数,会造成梯度消失问题[17],限制了网络对无限长距离历史信息的学习能力。
1.2 LSTM模型
本文采用LSTM[18]单元替代RNN的隐含层单元,避免RNN训练时出现梯度消失的情况。LSTM的单元结构如图2所示。
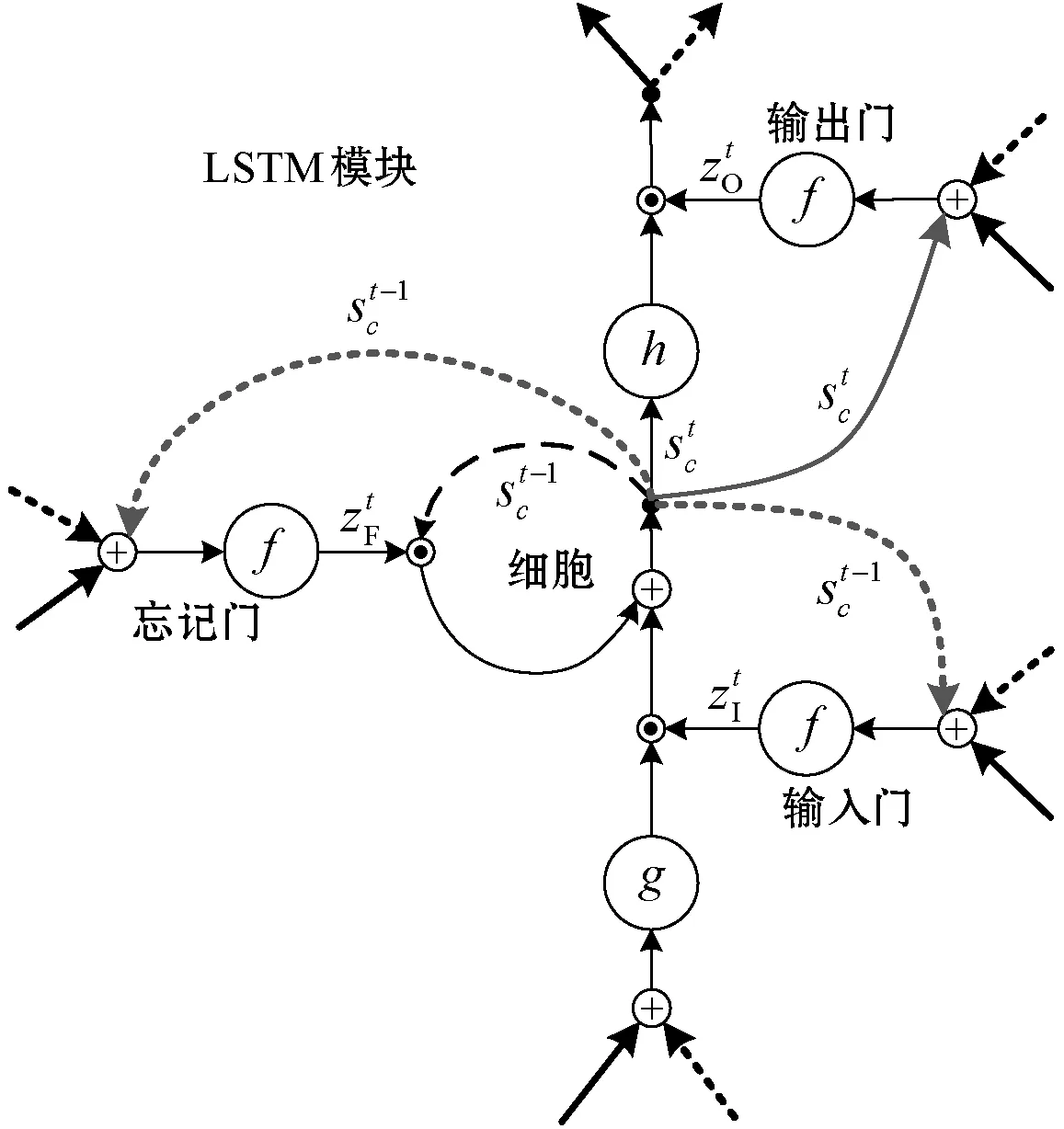
图2 LSTM单元结构
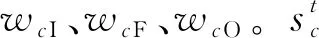
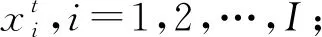
输入门:
(6)
经过激活函数后,输出为:
(7)

忘记门:
(8)
经过激活函数后,输出为:
(9)
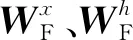
输出门:
(10)
输出门确定要输出的信息,并由细胞状态决定。经过激活函数后,输出为:
(11)

细胞输出:
(12)
式中:h(·)为tanh激活函数。LSTM的这种门控机制是一种让信息选择性通过的方法,使中心节点能够保存长期依赖信息,并且在训练时保持内部梯度不受外界干扰。每个中心节点有一个自循环连接线性单元,称为恒定误差传送带(Constant Error Carousel,CEC)。误差以恒定的值在内部进行传播,从而避免了梯度消失问题。
2 基于Bi-LSTM和自注意力的恶意代码检测
由于双向LSTM可以同时利用当前位置的上下文信息进行训练,较单向LSTM提取特征能力更强,本文采用双向LSTM网络结合自注意力机制提取恶意代码的特征,构建的恶意代码检测模型如图3所示。该模型主要分为Bi-LSTM层、自注意力层、全连接和Softmax层三大部分。

图3 基于Bi-LSTM和自注意力的恶意代码检测模型
2.1 Bi-LSTM层

(13)
(14)
2.2 自注意力层
自注意力层的作用就是在H上施加注意力,具体过程如图4所示。
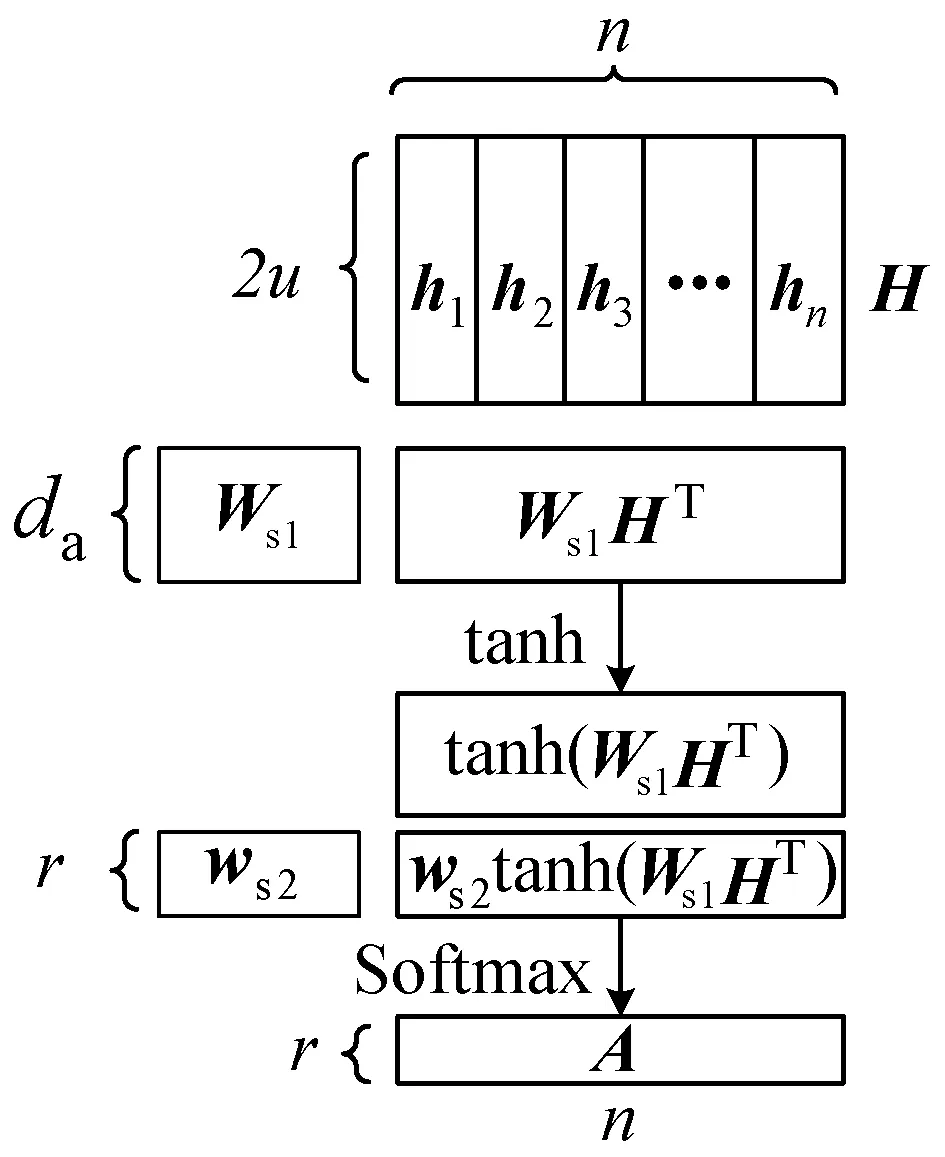
图4 自注意力机制计算示意图
自注意力层将Bi-LSTM的隐状态集合H作为输入,输出注意力向量a:
a=softmax(ws2tanh(Ws1HT))
(15)
式中:Ws1是维数为da×2u的权重矩阵;ws2是维数为da的参数向量,da为一个超参数;a的维数是n;Softmax函数保证输出的注意力向量的每个元素代表一个概率,且所有元素和为1。按照注意力权重分配向量a将H线性加权求和即可得到状态测量序列的嵌入表示m。
然而,一个m通常只关注了序列S某些维度的特征,恶意代码字节序列特征组合较多,因此一个m并不能代表序列S的所有特征,因此需要增强注意力,计算多个代表不同维度特征的m作为序列S的嵌入表示。假设需要计算序列r个方面的特征,则ws2的维度扩展为r×da并记作Ws2,向量a扩展为注意力权重分配矩阵A:
A=softmax(Ws2tanh(Ws1HT))
(16)
序列S的特征表示由m向量扩展为维数是r×2u的M矩阵:
M=AH
(17)
随后将M输入全连接层和Softmax层,输出识别概率:
Y=Softmax(WfM+b)
(18)
式中:Wf是全连接层的权重矩阵;b为偏置;Y是Softmax层计算的概率结果。
3 实 验
3.1 实验数据
本文实验所用数据均来自于VXHeaven,该数据集包括27万个恶意代码样本,按卡巴斯基命名规则命名。本文抽取worm、backdoor、virus和trojan这4个种类,共10 400个恶意代码样本。同时从Windows 7系统、Ninite.com和各种应用中选取1 100个正常文件,如表1所示。

表1 实验样本介绍
3.2 评测方法与标准
为了充分评估本文方法,按照不同的方法构造两种不同的训练数据集和测试集。第一种方法将各族恶意代码的名称(Virus,Backdoor,Worm和Trojan)分别作为各自的标签,正常样本标签为正常,该数据集记为5-class-data。第二种方法将恶意代码样本的标签统一标为恶意代码,正常样本标签为正常,该数据集记为2-class-data。采用10层的交叉检验方法,所有实验数据随机分为10个部分,依次选择1个部分作为测试集,剩余的9个部分作为训练集,重复做10次实验,将实验结果取平均值。
本文选用恶意代码检测领域的通用评测标准误报率(False Positive Rate,FPR)和准确率(Accuracy Rate,AR)评测本文方法效果。
(19)
(20)
3.3 实验设置与结果分析
本文选取文献[6]中四种基于机器学习的恶意代码检测方法作为对比方法,这些方法均从恶意代码样本的部分代码中提取28维特征作为机器学习的输入。四种机器学习算法分别为K近邻算法、决策树、支持向量机、随机森林,在测试集上的评测结果分别用K-NN、DT、SVM、RF表示。
本文将恶意代码文件转换为长度统一的字节流序列,每个字节元素(范围为[0x00,0xff])用256维的One-hot编码表示,使用TensorFlow深度学习框架编写基于Bi-LSTM和自注意力的恶意代码检测模型。根据训练模型的经验,本文采用一个输入层,3个Bi-LSTM和自注意力机制组合层,一个全连接层和一个Softmax层的结构,每个单向LSTM层有1 024个LSTM单元,LSTM单元的隐藏节点数为300,各单元之间共享训练参数,训练时间步长为1 024,优化算法选取Adam[19],epochs设置为100,每批数据batch_size大小为256,学习速率为0.01,全连接层的隐藏节点为3 000,使用dropout技术,避免过拟合问题,dropout设置为0.7[20],在测试集的评测结果记为Bi-LSTM-SA。
实验硬件配置为Intel Xeon E5-2650,128 GB内存的服务器,配备12 GB的双GTX 1080Ti独立显卡进行加速训练。
(1) 5-class-data数据集下的对比实验。上述五种方法在5-class-data数据集下,经过10次交叉实验,FPR和AR评测结果如表2和表3所示。
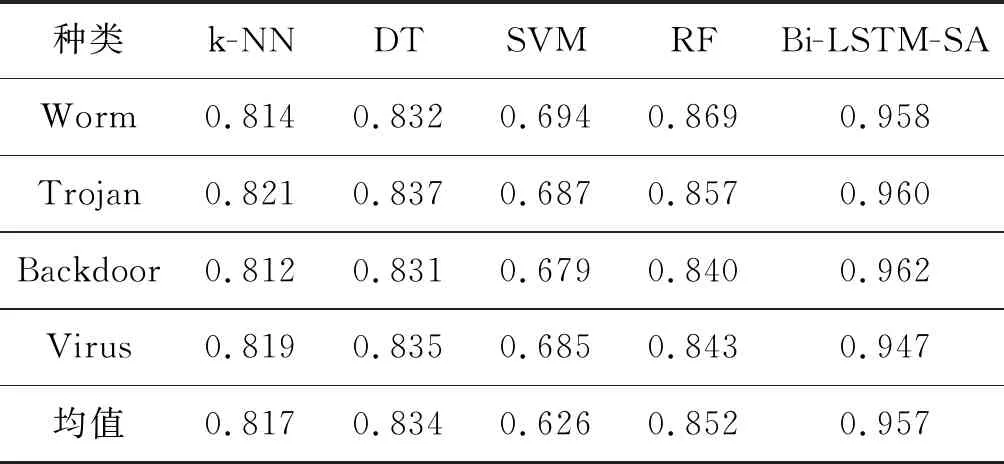
表2 AR评测结果
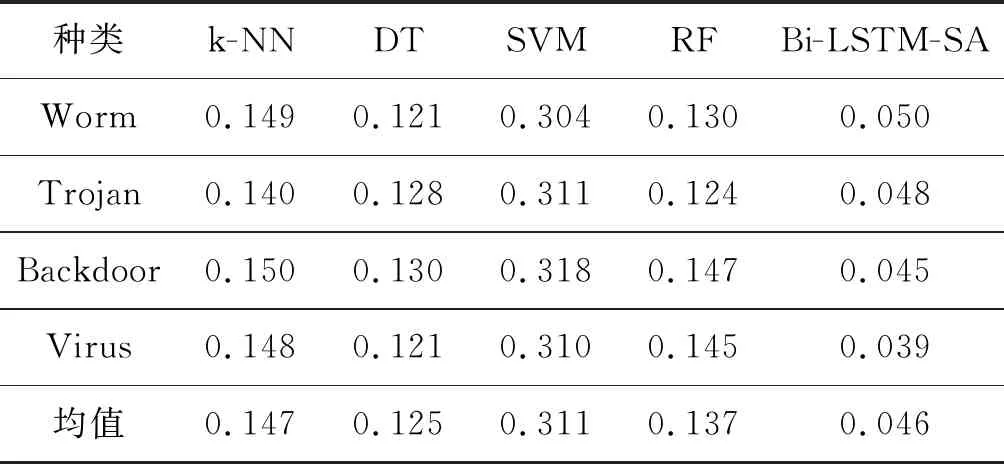
表3 FPR评测结果
以上两组实验结果表明,本文提出的方法切实可行,而且准确率高,误报率低,均取得了最优结果。在对比方法中,支持向量机在28维的训练数据中得到的超平面分类效果最差。随机森林是一个用随机方式建立,包含多个决策树的分类器,输出类别由各树输出类别的众数而定。树上的每个节点随机选取所有特征的一个子集计算最佳分割方式,该特点使得随机森林擅长处理高维度特征,因此其评测效果相比于K近邻和单决策树方法的评测效果较好。
本文方法的评测结果同时实现了较高的准确率和较低的误报率,相较于RF的检测方法,AR值提高了12.32%,FPR值降低了66.42%。另外,通过分析Bi-LSTM-SA检测到而RF没有检测到的恶意代码样本发现,这些样本中关键函数和输入端口等特征有简单变形或者混淆的现象,这说明本文模型可以重点关注表现恶意行为的字节元素,获取更能代表恶意代码序列的深层特征表示。
(2) 2-class-data数据集下的对比实验。上述五种方法在2-class-data数据集下的评测结果如表4所示。
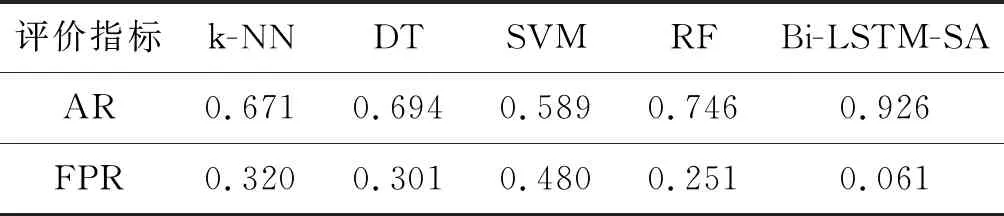
表4 2-class-data数据集下AR和FPR值
可以看出,本文方法在训练数据噪声比较大的情况下准确率依然最高,误报率最低。五种方法在2-class-data下的AR值相较于在5-class-data下AR的值分别降低了17.87%、16.79%、5.91%、12.44%、3.24%。FPR值依次分别增加了117.69%、140.80%、54.34%、83.21%、32.61%。四种对比方法的AR和FPR变化率明显大于本文方法的变化率,这是因为同样的数据集,2-class-data比5-class-data的类别少,特征相对变多,使得对比方法无法准确地提取恶意代码的特征,本文方法可以准确关注恶意特征位置,全面提取恶意代码的特征表示。
4 结 语
本文提出一种基于Bi-LSTM和自注意力机制的恶意代码检测方法。该方法自动重点关注恶意代码中表现恶意行为的字节,以这些字节隐状态的注意力加权和作为样本的特征表示,通过注意力提升准确地计算出样本的深层特征表示。实验结果表明本文方法切实可行,可以显著提高恶意代码检测效果。本文实验数据的类别和数量都有限,理论上训练数据规模越大,训练出的分类器性能越强,因此下一步准备从开源恶意代码分享网站搜集更大规模的数据,进一步测试和提升本文方法的分类性能。另外,LSTM的结构特性决定其只能顺序训练序列的元素,在大规模数据量下训练模型和利用模型检测均需要消耗大量的时间,如何构造一种可以并行训练序列元素的网络结构是下一步研究的另一重点。
