基于Word2vec和句法规则的自动问答系统问句相似度研究
2021-03-16白尚旺陆望东党伟超潘理虎
刘 杰 白尚旺 陆望东 党伟超 潘理虎,3
1(太原科技大学计算机科学与技术学院 山西 太原 030024)
2(太原政通云科技有限公司 山西 太原 030000)
3(中国科学院地理科学与资源研究所 北京 100101)
0 引 言
自动问答系统的一般处理流程是对用户提出的问题查询FAQ (Frequently Asked Questions)问题库并返回最为相似问题的答案。早期的自动问答系统主要依靠专家系统,如文献[1]提到的LUNAR和文献[2]提到的STUDENT专家系统,但是专家系统往往有局限性,其数据结构通常是结构化数据,问句之间相似度匹配往往是句中词语的机械式匹配。张子宪等[3]从句子的关键词相似度、关键词距离以及相同关键词在问题库所占比例等方面进行了相似度计算分析,并提出一种基于句子规则的问句相似度计算方法。该方法虽然提高了句子相似度匹配精度,但是忽略了句子结构层面的分析。文献[4]提出了一种基于改进后的TF-IDF的句子相似度计算方法,通过同义词典统计关键词词频信息,然后计算向量之间余弦相似度。虽然该方法虑到了关键词的物理特征,但忽略了词语在问句环境中的依存关系以及语义关系。
近年来,随着大数据时代到来和云计算能力不断地提高,深度学习得到了非常快速的发展,其具有很好的特征学习能力,尤其是在图像和语音领域,这也激励着大批学者将其具有应用自然语言处理的研究中[5-7]。2013年,Google公开获取词向量工具Word2vec[8-9],立即引起了学术界和工业界的关注,其获取词向量方法与One-hot[10]方法相比能够更好地表达词与词之间的相似特征。2014年,Kim[11]提出了基于卷积神经网络的文本分类方法——Text-CNN,该方法相比RNN[12]能够取得更高的分类准确率,虽然对某些特殊复杂句式的分析比RNN差一些,但是Text-CNN的分类效率总体更高。
基于以上分析和自动问答系统存在的问题,本文提出一种基于Word2vec和句法规则的自动问答系统问句相似度计算方法。基于Word2vec模型训练的词向量能够更好地分析词与词之间语义关系,将向量空间相似度转换成语义相似度。基于句法规则的问句相似度计算方法能够更好地分析问句中特殊句型关系、词性关系以及依存关系。
1 自动问答系统问句相似度研究
图1所示为本文方法主要的处理流程。首先将用户提出的问题与FAQ库中的问题进行基于Word2vec和句法规则的问句相似度计算分析,判断其是否超过阈值。若超过阈值则将FAQ中超过阈值且相似度最高的问题的答案作为用户提出问题的答案返回给用户,否则系统记录该问题并通知管理员在FAQ库中添加该问题和相应的答案。

图1 自动问答系统流程
1.1 Word2vec词向量研究
在问句相似度计算过程中词是计算的基本单位,而词向量是词的特征在空间结构中的映射也是词的数字特征形式,所以词向量构建是问句相似度计算的重要环节。文献[8-9]提到训练Word2vec有两种非常重要的模型:跳字模型和连续词袋模型。
1.1.1跳字模型
跳字模型(skip-gram)是依据中心词来生成中心词周围的词。该模型以图2为例,假设存在文本序列“学校”“老师”“爱”“每一个”“学生”,设置其生成背景的窗口为2,在 skip-gram中,给定中心词“爱”,生成2个词的范围内的背景词“学校”“老师”“每一个”“同学”的条件概率为:
P(“学校”,“老师”,“每一个”,“学生”|“爱”)
(1)
如果生成概率是相互独立的,则式(1)可以改写为:
P(“学校”|“爱”)·P(“老师”|“爱”)·P(“每一个”|“爱”)·P(“同学”|“爱”)
(2)
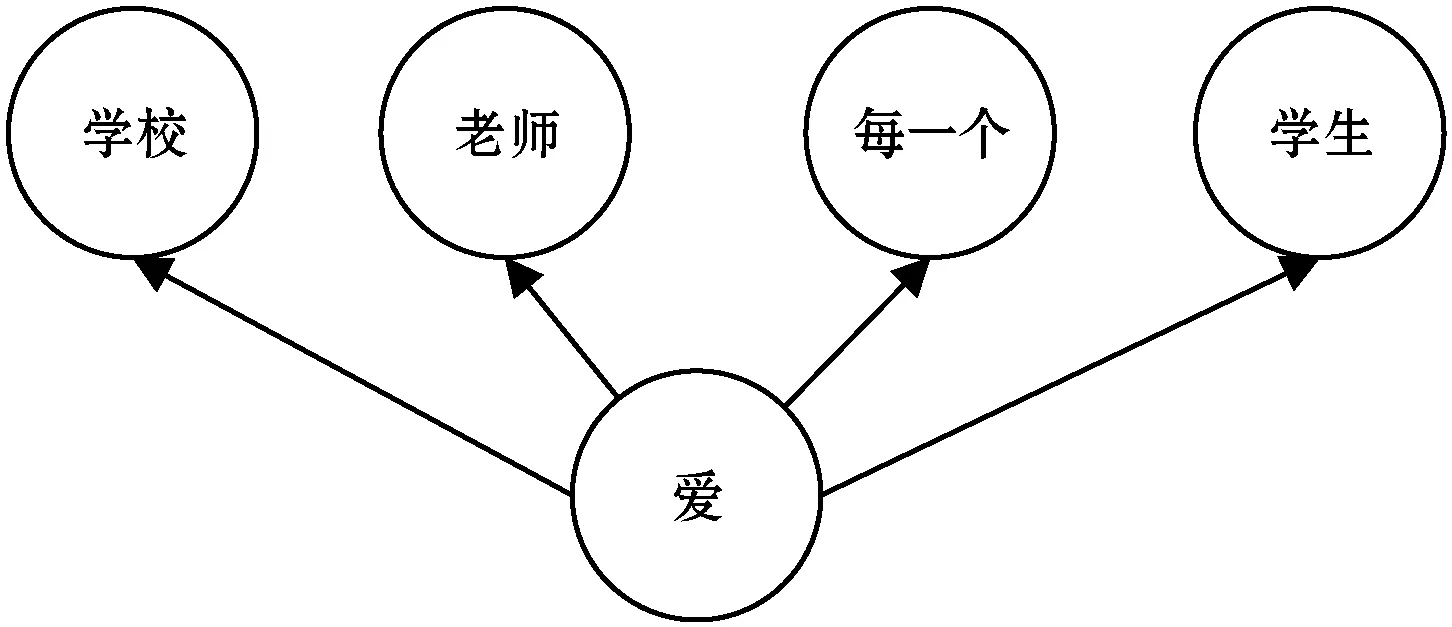
图2 跳字模型
假设存在一个索引集合为{0,1,…,n}的词典和一个中心词wc和背景词wo,且wc对应One-hot词向量为vc,wo对应One-hot词向量为uo,那么,在skip-gram中,给定中心词wc生成背景词wo的概率为:
(3)
式中:i、o、c表示为词典中索引的位置。
假设,存在一个长度为T的文本序列,那么,给定任一中心词w(t)生成w(t+j)背景词的概率为:
(4)
式中:t为时间步;m为生成背景词的窗口大小。
由式(4)可以得到最小化损失函数:
(5)
在训练过程中,采用随机梯度下降随机取一个子序列来训练更新模型参数,把式(3)代入式(5)通过微分可得到中心词向量vc的梯度:
(6)
训练结束后得到Word2vec词向量。
1.1.2连续词袋型(CBOW)
与跳字模型相比,连续词袋模型在生成结构上略有不同,该模型是给定周围背景词去生成中心词。以图3为例,假设存在文本序列“学校”“老师”“爱”“每一个”“学生”,在CBOW中,给定“学校”“老师”“每一个”“学生”作为背景词,生成中心词“爱”的条件概率为:
P(“爱”|“学校”,“老师”,“每一个”,“学生”)
(7)
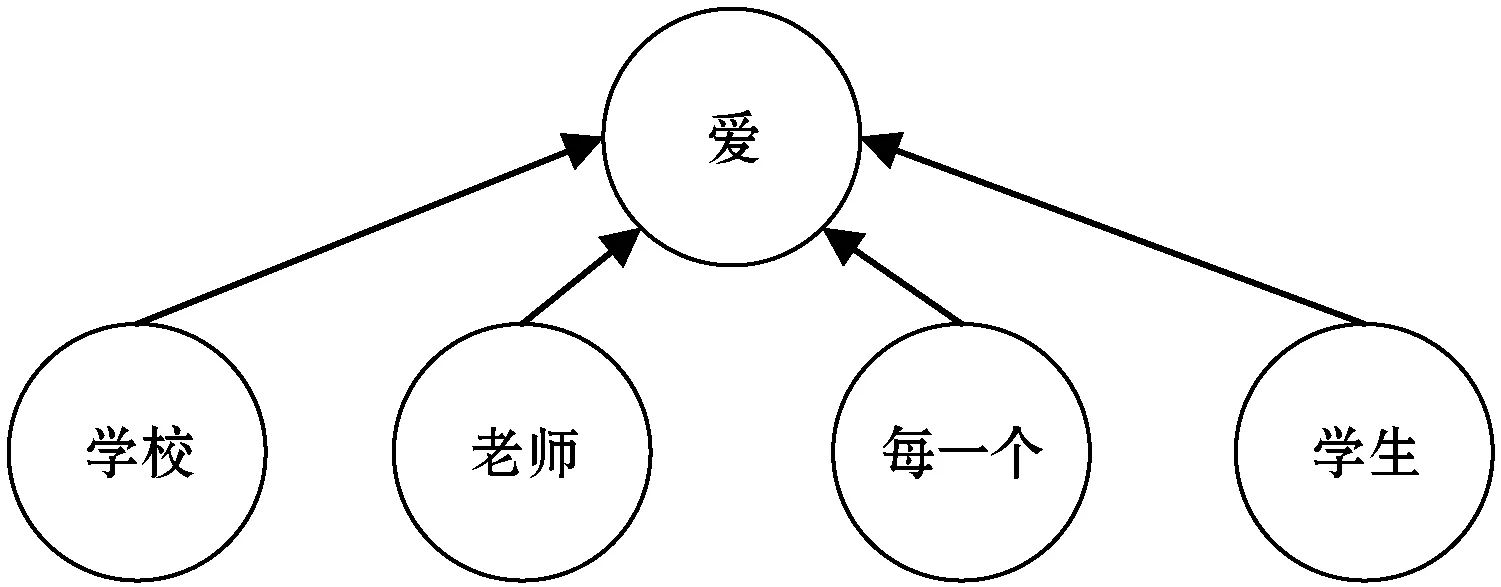
图3 连续词袋模型
假设存在一个索引集合为{0,1,…,n}的词典和一个中心词wc、一个背景词集合{wo1,wo2…,wo2m},且wc对应One-hot词向量为uc,{wo1,wo2…,wo2m}对应的背景One-hot词向量集合为{vo1,vo2…,vo2m},那么,在CBOW中,给定背景词集合{wo1,wo2…,wo2m}生成中心词wc的概率为:
(8)

那么式(8)改写为:
(9)
假设存在一个长度为T的文本序列,那么给定背景词w(t-m),…,w(t-1),w(t+1),…,w(t+m),生成中心词w(t)的概率为:
(10)
式中:t为时间步;m为生成背景词的窗口大小。
由式(10)可以得到最小化损失函数:
(11)
在训练过程中,同样采用随机梯度下降随机取一个子序列来训练更新模型参数,把式(9)代入式(11)通过微分可得到任一背景词向量vok(k=1,2,…,2m)的梯度:
(12)
训练结束后得到Word2vec词向量。
1.2 基于句法规则的相似度分析
本文提出的句法规则主要分为问句分类规则、问句特殊句型规则、问句动名词规则、问句依存关系规则。
1.2.1基于问句分类规则的相似度分析
通过大量分析问句语料库发现,相似度较高的两个问题可以分为一类,因此在计算两个问句是否相似时候,可以把类的特征作为一个考量因素。如表1所示,第一组中的问句都属于“诗词”一类,第二组都属于“地理”分类。文献[4]方法没有把问句分类作为相似度计算的一个特征因素,其计算结果很低。
当问句分类结果作为一个相似度计算因素时,构造的问句分类模型必须要有较高的分类准确率。

表1 问句相似度分析一
卷积神经网络(Convolutional Neural Networks, CNN)最先被应用在图像识别方面,并且取得了长足的进步。其识别图像过程是通过模仿人类视觉层感知图像的过程。首先通过眼睛摄取图像的像素;然后大脑皮层细胞找到图像的形状边缘和形状方向并且抽象地确定该图像的形状;最后,进一步地抽象判定。
文献[11]提出文本数据也可以看作是一维图像,将文本映射成一维图像可以利用卷积神经网络提取词与词之间的特征 ,其网络结构为“单层卷积+池化”的简易 CNN 模型——Text-CNN,如图4所示。
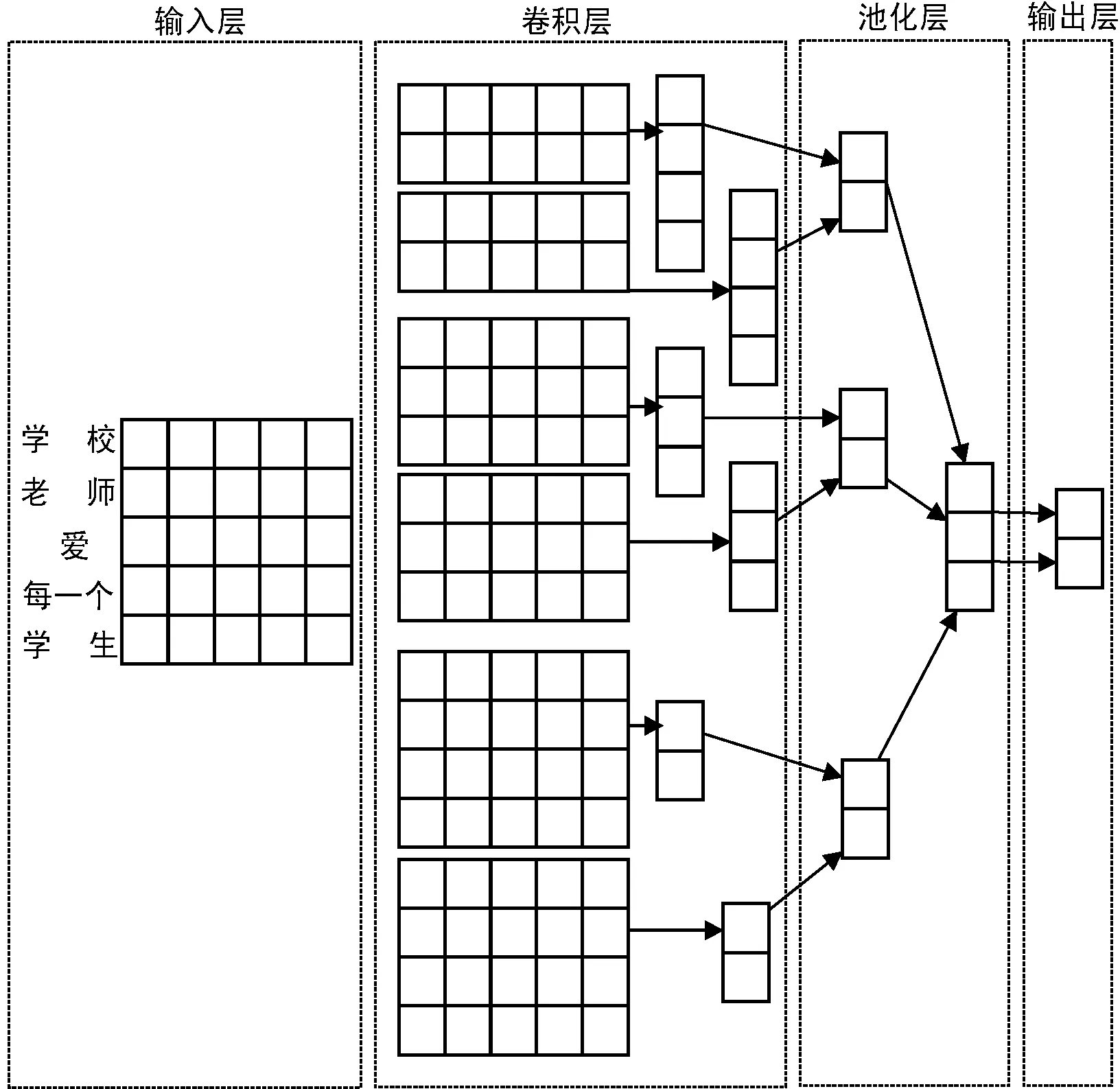
图4 Text-CNN网络结构
Text-CNN与CNN模型结构略有不同的是 Text-CNN网络模型结构首先定义了一维卷积核,其作用是对输入的特征进行卷积运算,卷积核的宽度不同则捕捉的词与词之间的相关性也可能不同,卷积运算之后再执行最大池化处理并将池化的输出值作为向量连接,最后通过全连接层将每个类别进行输出。图4中,输入层由5×5的词向量组成,词向量的维度是5,总共5个词向量,卷积层有3种尺寸不相同的卷积核,分别是2×5、3×5、4×5, 每种尺寸有两个卷积核。卷积核分别于上一层输入层进行卷积运算,其卷积后的结果再使用激活函数进行激活。每个卷积操作都会得到一个相应的特征图,池化层采用最大池化操作过滤出每个特征图最大值然后进行链接,输出层运用Softmax对卷积层连接好的向量进行分类。
1.2.2基于特殊句型的相似度分析
在带有否定词的问句句型中,否定词的影响可以忽略。如表2所示,在问句环境中两个问句描述的是一个意思,在计算问句相似度时可以去除问句中的否定词“不”,其相似度不变。

表2 问句相似度分析二
1.2.3基于问句中动词和名词的相似度分析
分析发现相似度较高的问句中,其相似度主要取决于句中名词与名词以及动词与动词之间的相似性。如表3所示,如果能提高第一组名词“计算机”与“电脑”,“屏幕”与“显示器”及动词“打”和“闪”之间的语义理解,那么其计算的相似度结果会更高。而基于Word2vec训练的词向量恰好解决了词语之间语义相似度计算的问题。

表3 问句相似度分析三
1.2.4基于问句依存关系相似度分析
一个词在问句的不同位置表达出来的意思可能完全不一样,如表4所示,问句1、2和问句3、4的包含和对比依存关系完全不一样,文献[4]并没有分析问句的依存关系,相似度计算的结果都较高。

表4 问句相似度分析四
2 基于Word2vec和句法规则的问句相似度计算方法
基于第1节的分析,本文提出一种基于Word2vec和句法规则的自动问答系统问句相似度计算方法,问句示例如下:
“杭州属于哪个省?”
J1
“杭州归于哪里?”
J2
其相似度计算式为:
SimJ(J1,J2)=a·SameCateSim(J1,J2)
β·cos(sim(J1n,J2n))+r·cos(sim(J1v,J2v))+
(13)
(1)SimJ(J1,J2)表示为问句J1和问句J2相似度值,值越接越近1表示问句J1和问句J2越相似,值越接近0表示问句J1和问句J2越不相似。
(2)sim(A,B)表示为词向量A和词向量B的余弦相似度,即:
(14)
为了方便比较,本文把余弦相似度都统一归一化到[0,1]区间内,归一化后的余弦相似度为:
cos(sim(A,B))=0.5+0.5×sim(A,B)
(15)
(3) (J1,J2)表示J1和J2是否同类,如果是同类,SameCateSim=1;否则SameCateSim=0。
(16)
(4) 用LTP[13]对问句中的动词(v)和名词(n)进行词性标注,J1n表示为问句J1中的所有名词Word2vec词向量累加和,J2n同理;J1v表示为问句J1中得所有动词Word2vec词向量累加和,J2v同理。
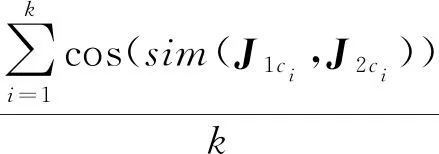
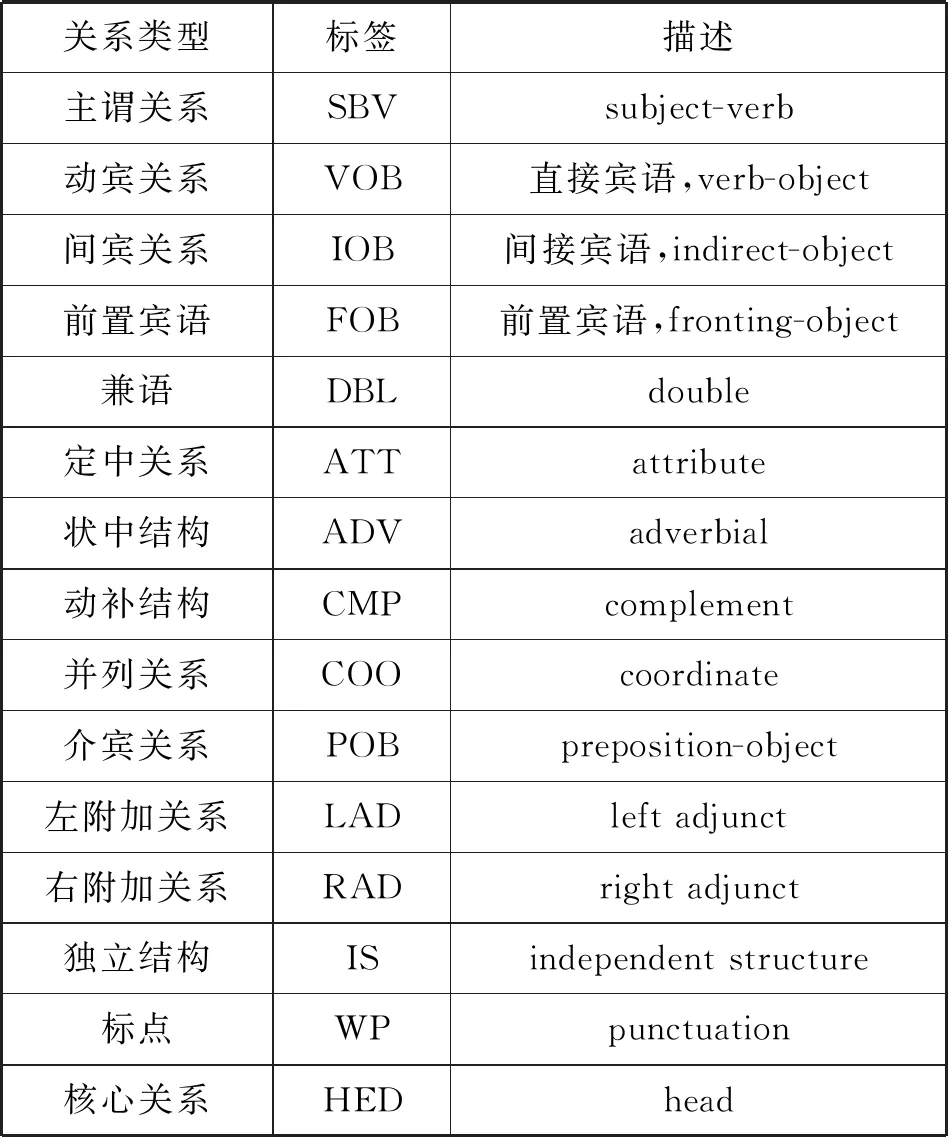
表5 句法依存关系表
例如,问句J1与问句J2的相同依存关系为“SBV”“HED”“VOB”“RAD”,那么集合C={“SBV”,“HED”,“VOB”,“RAD”},C的大小为4,k=4。假设,问句J1中的“SBV”的Word2vec词向量为y1,“HED”的Word2vec词向量为y2,…,“RAD” 的Word2vec词向量为y4。 问句J2中的“SBV”的Word2vec词向量为x1,“HED”的Word2vec词向量为x2,…,“RAD”的Word2vec词向量为x4,那么:
(16)
(5)a、β、r、z为相似度权重因子,a+β+r+z=1,经过200个问句相似度计算测试,将a、β、r、z分别设置为0.2、0.2、0.2、0.4。
为了更加详细说明本文方法计算问句相似度的过程,将问句J1和问句J2计算过程进行分析,如表6所示。由于词向量维数为400维,超出表格部分由省略号代替。
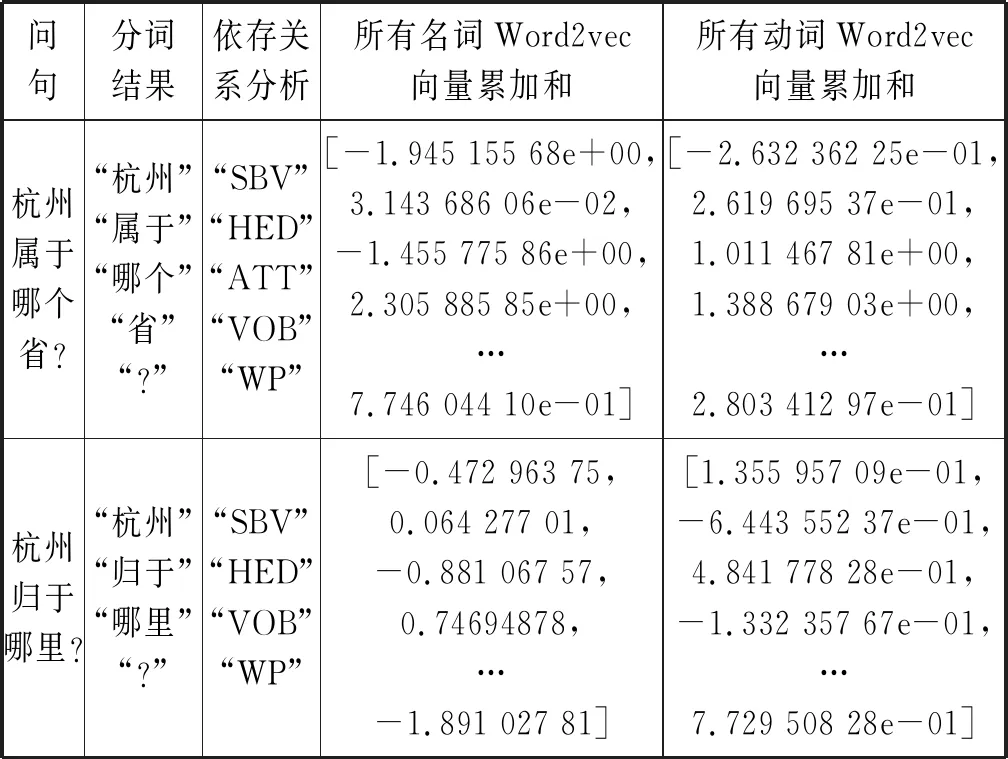
表6 计算过程分析
3 实 验
3.1 实验环境以及流程
本次实验运行环境为Ubuntu 16.04,CPU为Intel i7 9700,编译环境为Anconda 3,Python 3,选用jieba分词器分词,选用Tensorflow 1.0 训练Text-CNN问句分类模型,选用Gensim训练中文维基 Word2vec词向量。
实验具体流程如下:(1) 数据预处理;(2) 训练构造Word2vec词向量模型;(3) 训练构造Text-CNN问句分类模型;(4) 用式(13)计算两个问句相似度;(5) 计算自动问答系统准率(P)和召回率(R)以及F值;(6) 对比实验结果进行分析。
3.2 实验设计
训练Text-CNN问句分类模型,设置词向量embedding_dim为128,过滤器filter_sizes大小分别为3、4、5,每层网络卷积核num_filters个数为128, DropOut概率为0.5,正则惩罚项为0.2,batch_size为64,epochs为100。训练数据采用搜狗公开问句数据集进行训练,人工把问句数据集分为“人物”“地理”“医疗”“历史”“动物”“诗词”“歌曲”“科学” 八种类型,共2 000个问句,其中1 500句作为训练集,500句作为验证集。
训练Word2vec词向量模型,设置词向量维数size为400,使用CBOW模型训练,训练Window大小为5,每批单词数量batch_words为1 000。训练数据采用中文维基百科数据,大约91万条,并将其xml格式的繁体数据转换成txt格式简体数据集,然后用jieba分词处理。
使用准确率(P)、召回率(R)和F-measure(F)对自动问答系统实验结果进行分析,计算如下:
(17)
(18)
(19)
3.3 实验结果分析
3.3.1Text-CNN问句分类结果
在模型训练迭代到12 000步时,验证集分类准确率达到91%,在12 000到16 000步时准确率趋于平稳,验证了Text-CNN问句分类的可行性,如图5所示。

图5 Text-CNN模型问句分类准确率
3.3.2问句相似度结果分析
选取5组不同类型的问句作为问句相似度分析,其结果如表7所示。
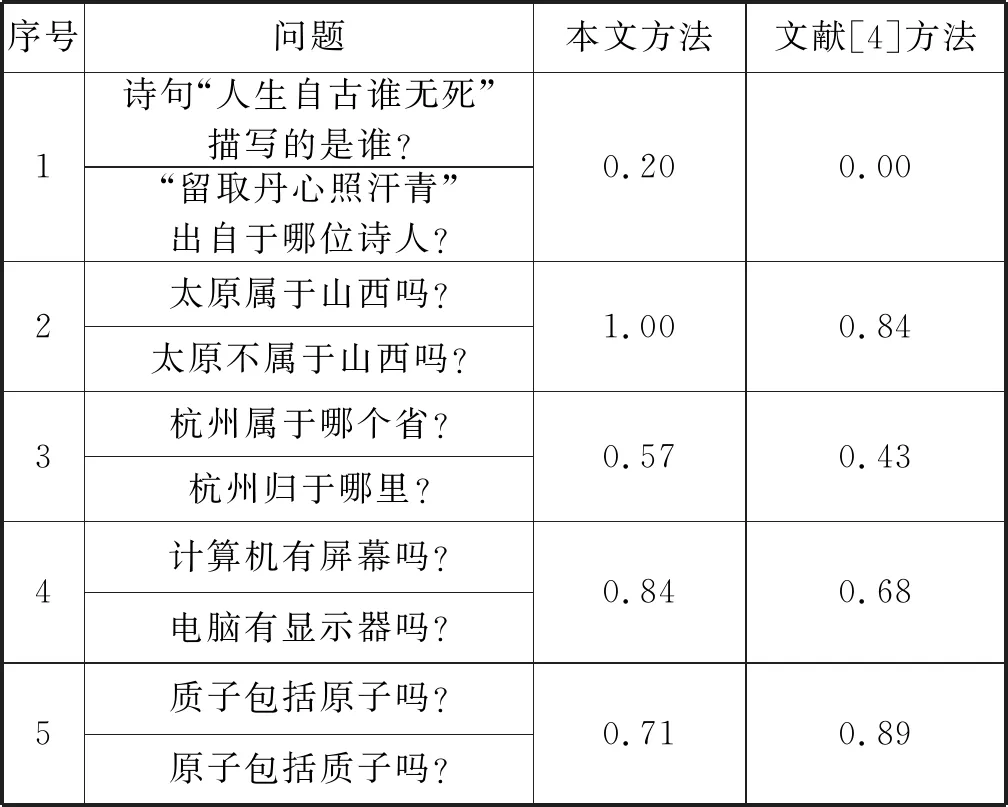
表7 问句相似度实验结果
可以看出,相比文献[4]方法,本文方法在计算问句之间相似度有着显著提高。
1) 本文方法将问句分类特征作为相似度计算的一个因素,将问句共性特征转换为问句相似的特征。表7中第一组问句都属于“诗词”一类,文献[4]并没有考虑问句分类的特征,所以相似度非常低。
2) 文献[4]并没有对问句中否定词的特殊性进行分析,而本文方法消除了问句中无用否定词。如表7 中 “太原不属于山西吗?”从问句角度的理解,去掉其中的否定词“不”并不改变其问句的意思。显然,文献[4]将其视为一个词处理,反而相似度不会很高,本文方法从问句的特殊句型角度出发提升了问句相似度计算结果。
3) 本文基于Word2vec模型训练的词向量更加精确地反映出了词语之间的语义关系,从语言含义角度提升了计算的精确度。如表7第4组问句中,在 “电脑”和“计算机”以及“屏幕”和“显示器”之间语义的理解,本文方法更为准确。
4) 本文方法加入了问句依存关系的分析,一个词在问句的不同位置可能表达出来的意思不一样,如表7第5组中,“质子包括原子吗?”与“原子包括质子吗?”包含的依存关系完全不一样,相似度也不会很高,而文献[4]没有分析问句的依存关系。
3.3.3自动问答系统实验结果分析
在自动问答系统测试过程中,随机从搜狗公开问答数据集中抽取200个数据进行测试,系统阈值设置为0.50,加入文献[4]方法对比分析,结果如表8所示。
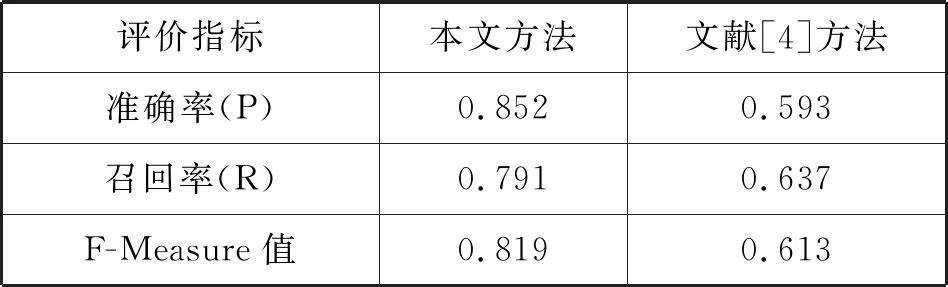
表8 不同方法的对比实验结果
可以看出,相比文献[4]方法,本文提出的方法在准确率、召回率以及F值三项对比中有明显的提升,召回率有显著提升的原因主要是本文方法在问句理解的广度上更为深刻。
4 结 语
本文提出的基于Word2vec和句法规则的自动问答系统问句相似度计算方法,更加准确地分析了问句的分类关系、特殊句型关系、依存关系以及语义关系,有效地提高了为自动问答系统返回答案的准确率。但是该方法对问句中一些专业词语的深层语义辨析上存在着一定的缺陷,下一步工作将对专业词汇的深层语义辨析做研究。
