基于神经网络的车间工件视觉识别研究
2021-03-15曹旭阳郭万达于效民
宋 鑫 曹旭阳 郭万达 于效民
大连理工大学 大连 116000
0 引言
现在主流的计算机视觉识别算法包含传统计算机算法和神经网络算法两种类型,传统的计算机算法已经逐步由深度神经网络算法取代[1]。在工业领域,图像识别问题受到了广泛关注,智能车间装卸设备可以代替人工,对库存的物料进行视觉识别,通过图像处理获取物料的物理信息,并对信息进行传递输出。人工神经网络识别算法被广泛应用于图像识别过程中,随着信息技术的进步,图像识别的精度和效率得到不断提升。
传统的机器学习领域非常依赖人工方法来提取图像的特征,如尺度不变、特征变换,方向梯度直方图[2],通过传统神经网络来完成识别目的。这些方法比较难以处理较深层次的内容丰富的图像信息,识别准确率普遍比较低[3]。卷积神经网络(Convolutional neural network)具备深层次的网络结构,跟传统的机器学习相比,具有特征信息的表达更丰富的特点,且不需要人工提取特征的信息,通过前向传播和反向传播可以自动从样本图像中学习图像特征,通过深层次的网络结构能获得更准确、更高维,更抽象的特征[4],从而达到良好的识别效果。在训练过程中,卷积神经网络主要包括学习卷积层的卷积核参数和神经网络层间的连接权重等参数,根据输入图像的特征和网络参数的计算做出对过程的预测。
卷积神经网络广泛应用在图像的分类、物体的检测及自然语言处理等领域。随着计算机视觉技术的快速发展,涌现出一大批优秀的卷积神经网络,例如AlexNet、ResNet、GoogLeNet等,推动了图像识别领域的高速发展,识别效果十分显著,训练模型轻易在各种智能设备上实现端到端的识别。卷积神经网络可以学习大量的关于输入和输出间的映射关系[5],而不需要两者之间的精确数学表达式,用卷积网络训练已知的模式,则网络就具备输入和输出间的映射能力。
本文研究对象是车间工件,选择了车间2种不同的工件作为研究对象。基于目标检测网络Yolov3的神经网络结构,对获得的数据集进行图像增强,从而实现了较小的数据集也能取得较好的车间工件的识别效果。图像增强是采用一定方法对原图像添加一些信息或更换数据,增强图像某些感兴趣的特征或抑制图像一些不太需要的特征,从而使得图像的信息与视觉的响应特性相匹配。图像增强广泛应用在工业的自动化产品设计和产品质量检验的领域,本文在图像增强后识别的准确率和损失值都有了明显的改善,取得了较为理想的识别效果。
1 数据集
本文构建了一个含有多种车间工件的数据集。为保证工件种类正确,选择实验室环境下作为研究对象。为保证数据多样性,采取以下措施:1)使用不同品牌手机,包括市面上多数品牌;2)选择不同场景拍摄,实验背景有很强的对比性;3)不同的拍摄角度和距离,使得照片具备广泛性。这样的拍摄方式更加符合现实情况,并有利于训练出适应性更强的模型。
图1所示为车间工件的部分数据集图片,其中包括齿轮1 150件、轴承300件,虽然种类不同,但形状和颜色等方面具有相似性。

图1 车间工件的部分数据集图片
2 数据集与数据增强
数据增强是卷积神经网络模型训练时的常用方法,目的是提升网络训练的稳定性和模型的泛化能力以及防止过拟合。本文将会使用Imgaug工具包,进行图片增强[6]。采用的图像增强方法包括图像旋转、图像h和图像w随机偏移、水平翻转及改变图片亮度等方法扩充数据集[7]。
2.1 图像旋转
完成图像采集后,先将图像尺寸裁剪成416×416像素,然后进行数据增强操作。
图像旋转是指采集的图像照片以某一点作为中心旋转一定的角度,形成新的图像的过程[8]。这个点通常称为图像的中心。按照中心旋转具备旋转前和旋转后的点与中心的距离不变的属性。根据这个属性可以得到旋转后的点的坐标与原坐标的对应关系。
图像做旋转操作时,假设图像长、宽分别为W和H,需先将坐标原点从左上角移动到图像中心位置[9]。原图上任意一点(X0,Y0)旋转后的坐标为
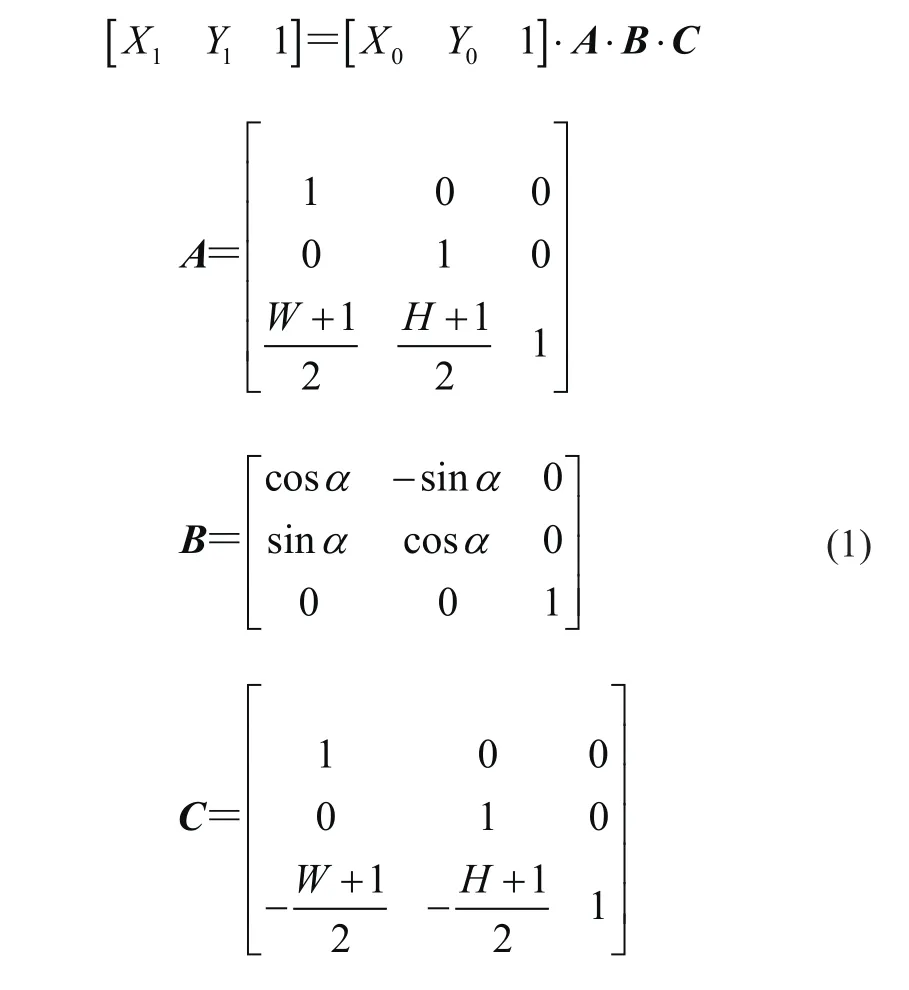
式中:A为移位矩阵,B为旋转角度α定义的旋转矩阵,C为将原点从图像中心复位到图像左上角的复位矩阵。
图像旋转的结果如图2所示。

图2 图像旋转示意图
2.2 图像偏移
图像偏移是指将图像的所有像素坐标进行水平或垂直方向移动,也就是图像的所有像素按照给定的偏移量在水平方向上沿着X轴或垂直方向沿着Y轴移动。
偏移图像时,需建立变换矩阵D。若原图上任意一点设为(X0,Y0),偏移后的坐标为(X1,Y1),则有

式中:tx是宽偏移系数,ty是高偏移系数。图像随机偏移的结果如图3所示。

图3 图像偏移示意图
2.3 水平翻转
在OpenCV中,图像的翻转采用函数cv2. flip()来实现,该函数可以实现图像在水平、垂直方向的翻转、以及水平和垂直2个方向的同时翻转。
图像的宽度为W,进行水平翻转时,若图像上任意一点设为(X0,Y0),偏移后的坐标为(X1,Y1),则
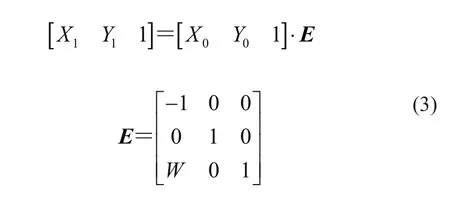
式中:E为建立的变换矩阵。图像进行水平翻转后的结果如图4所示。

图4 图像水平翻转示意图
当对训练集的部分图像进行旋转、偏移和水平翻转操作随机训练模型时,训练集的图像数量不增加,但可提升网络训练的稳定性和模型的泛化能力以及防止过拟合[10]。
3 试验算法
3.1 网络结构
本文识别车间工件采用的是卷积神经网络。卷积神经网络(Convolutional neural network)是一类需要进行卷积计算并且具有深层神经元结构的网络结构,是在目前图像识别和检测过程中一种主流的深度学习算法[11]。CNN算法的主要特点是采用局部链接并进行权值共享,而不是采用全链接的方式。该算法采用局部链接的原因是图像中的任意像素都与其周围的像素彼此关联,而不是关联着图像整体的所有像素点,采用局部链接对图像信息的特征提取具有良好的效果。采用权值共享方法的优点是对图像卷积操作时,不用对所有的卷积核都建立新参数,卷积核参数在滑动过程中都是可以共享的,与DNN算法相比,CNN算法能极大地减小图像识别过程中的计算量[12]。
卷积神经网络主要包括输入层、卷积层、池化层以及全连接层等结构。其中输入层的作用是输入图片的特征;卷积层的作用是负责提取卷积核的特征;池化层的作用是降低模型的参数量;全连接层作用是进行全链接处理。
本文采用的网络架构基于目标检测网络Yolov3,其基础特征提取网络的主干网络是DarkNet-53[13]。该网络的作用是提取图像的特征,网络架构如图5所示。DarkNet-53网络架构共有53层卷积,除去最后一个FC(全连接层,实际上是通过1×1卷积实现的)共有52个卷积用作主体网络。该网络模型结合了深度残差单元和Yolov2的基础特征提取网络DarkNet-19。输入416×416的图片后,进入到Darknet53网络架构中[14]。首先是1个32个过滤器的卷积核,然后是5组重复的残差单元。在每个重复执行的卷积层中,先执行1×1的卷积操作,再执行3×3的卷积操作,过滤器数量减半再恢复,共有52层。
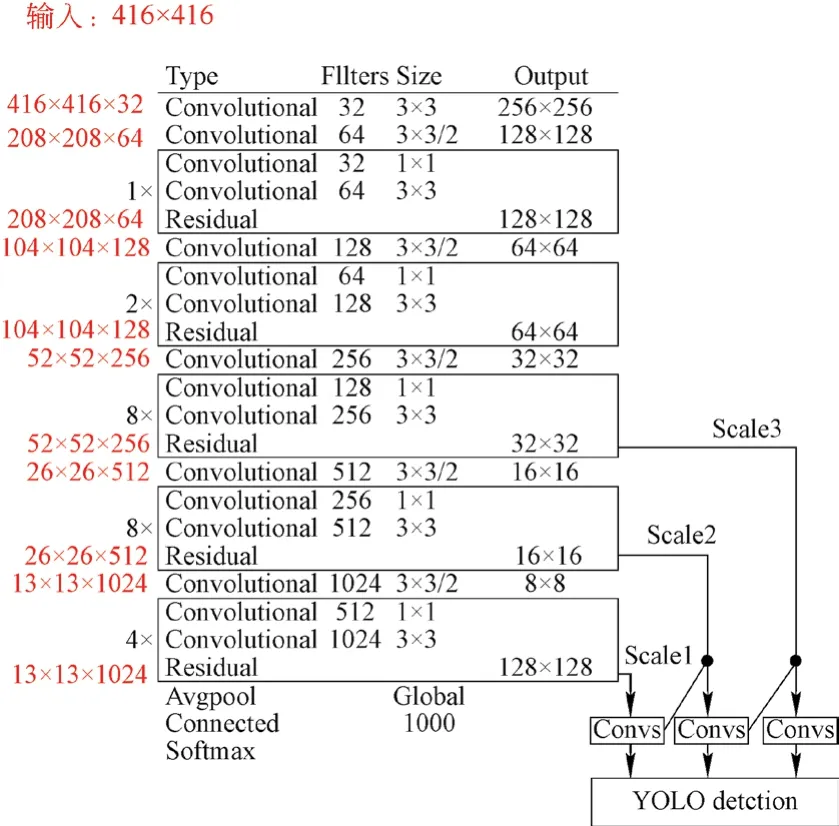
图5 DarkNet-53 网络架构
3.2 实验平台
本文训练和验证过程所使用的硬件平台配置为Intel(R) Xeon(R) CPU E5-2630 v4@ 2.20 GHz,操作系统为Windows 7(64 bit),编程语言为Python。本实验选取tensor flow为实验框架。
训练模型是采用Adam优化器,训练次数为100个epoch,训练批次为4,学习率初始值为0.001。本文对拍摄的图像增强操作后,实验准确率和损失值都比未增强的图像有所提高。图像增强前的识别准确率和损失值如图6和图8所示,图像增强后的识别准确率和损失值如图7和图9所示。
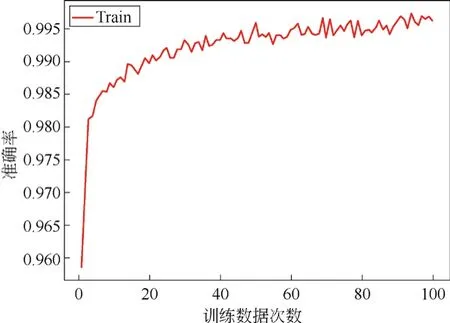
图7 图像增强后的识别准确率
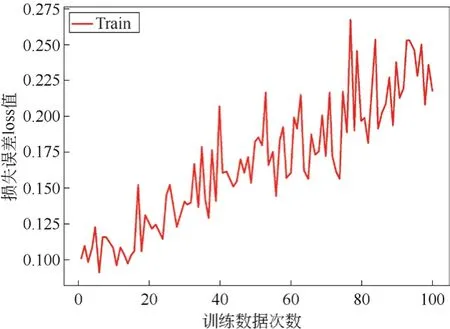
图8 图像增强前的损失误差
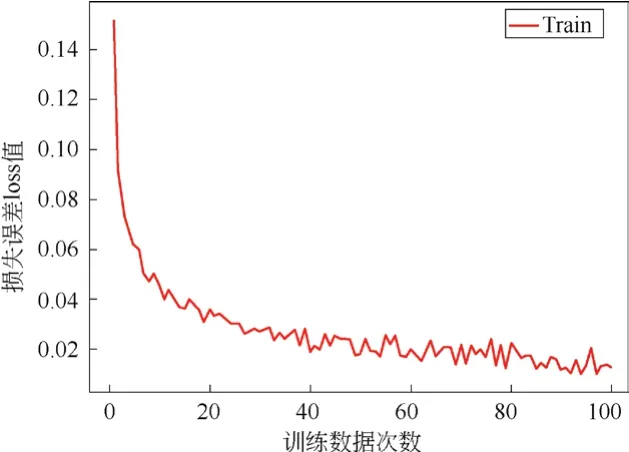
图9 图像增强后的损失误差
3.3 实验结果分析
图像增强后齿轮和轴承识别效果如图10所示,图像增强前后的识别准确率和损失误差对比如表1所示。
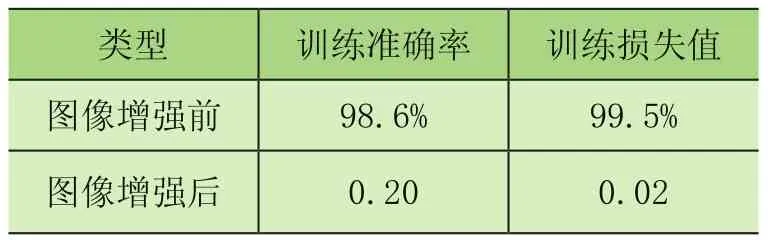
表1 图像增强前后的参数对比
通过表1中图像增强前后准确率和损失值的数值对比可知,图像增强后的识别准确率明显高于图像增强前的准确率;图像增强后损失值都明显低于图像增强前的损失值。由此可知,采取图像增强对于提升较小数据集的识别效果是比较明显的。

图10 轴承和齿轮识别效果
4 结论
本文建立了齿轮和轴承2种车间工件的数据集,在目标检测网络Yolov3的基础上,采用了图像增强的方法,增强了该模型在常规计算平台的实用性,实现了较小的数据集也能取得较好的车间工件的识别效果。通过实验验证,表明图像增强后识别的准确率和损失值都有了明显的改善,取得了较理想的识别效果。
