基于改进U⁃Net网络的铁路周边无人机影像建筑物提取方法研究
2021-03-14黄一昕方文珊刘传朋胡朝鹏
黄一昕 方文珊 刘传朋 胡朝鹏
1.中国铁路经济规划研究院有限公司,北京 100038;2.中国铁路设计集团有限公司,天津 300308
铁路遥感技术主要是通过航天、航空等传感器获取地物影像,并对其进行解译、分析和调查,获取铁路沿线的地形、地貌、地质构造等信息,从而对线路方案、重大构筑物等所处的地质条件做出评价,为后期选线提供技术支撑,辅助勘察设计工作[1]。无人机技术作为航空遥感的重要一环,凭借不受空域限制、影像获取便捷、覆盖地物全面的特点,在铁路勘察设计阶段的重要性日益凸显。目前对于铁路无人机影像的特征提取工作主要通过人工目视解译完成,人工成本高,生产效率低,亟待寻求新方法,在保证精度的前提下提升工作效率。
深度学习是机器学习和人工智能领域的重要研究方向之一,它通过对海量影像数据进行学习,能够快速、精准、自动地检测出影像上的地物特征[2]。卷积神经网络(Convolutional Neural Networks,CNN)是深度学习的代表性算法之一,能够以较小的计算量学习到影像的浅层特征与深层特征[3]。U⁃Net 网络是卷积神经网络的代表性模型之一,在小数据集的情况下依然有很好的表现[4]。学者们在对U⁃Net 网络进行深入研究的基础上做了大量的改进。刘浩等[5]提出了以U⁃Net 网络结构为基础的Se⁃Unet,并使用dice 函数和交叉熵函数复合的损失函数进行训练,以提升模型精度并减轻样本不平衡问题。冯凡等[5]通过在U⁃Net 网络结构中引入基于残差的金字塔池化模块(Pyramid Pooling Module,PPM)和基于残差密集连接的聚合特征精化模块,提升建筑物分类精度。宋延强等[7]通过在U⁃Net 网络的编码器部分加入通道注意力机制,突出目标特征,抑制背景噪声干扰,从而提高深浅层信息融合的准确率。王曦等[8]针对传统的遥感图像分割方法效率低下、分割精细度不够的问题,提出了一种U⁃Net 网络结构与特征金字塔网络(Feature Pyramid Networks,FPN)结构相结合的方法,缓解了对小尺度目标和大尺度目标边缘分割不佳的问题。
本文利用U⁃Net 网络对铁路无人机影像进行建筑物提取,针对U⁃Net 网络直接下采样造成信息损失且参数量大的问题,提出带有金字塔池化模块与深度可分离卷积相结合的U⁃PPM 系列网络。该网络通过对影像不同尺度的特征进行聚合获取包含不同尺度的信息,并利用深度可分离卷积代替标准卷积对影像特征进行提取。
1 U⁃Net网络
U⁃Net 网络于2015 年提出,该模型采用了基于编码-解码的架构模式,见图1。U⁃Net 网络的编码部分通过不断的卷积操作,逐层提取影像的特征信息。原图一共经历了4次卷积与池化操作。模型的解码部分通过对影像进行反卷积操作使影像尺寸变大但维度减半,然后将其与对应编码层的特征图进行融合拼接,最终将影像上采样至原图大小。

图1 U⁃Net网络结构
U⁃Net网络可以实现端到端的结果输出,通过4次下采样操作将图像缩小了16倍,深层次地提取了图像特征。再通过4 次上采样操作进行图像还原,将提取的高级特征图还原到原始图像大小,且保证了还原出来的分割影像边缘不会太粗糙。该网络还具备跃层连接的特点,在同一层级将高层的语义特征图和低层的视觉特征图相结合,使得模型高级特征图位置语义信息与低级特征图低层视觉信息都更为丰富,可以有效地实现多尺度预测,更好地还原图像。
U⁃Net 网络存在两个明显的缺点:①模型采用最大池化的方式在单一尺度上对影像进行下采样,在一定程度上会造成影像特征信息的损失,从而影响模型后续的分类精度;②模型采用了连续的标准卷积对影像进行特征提取,虽然在一定程度上可以增大影像的感受野,但是随着网络深度的不断增加,模型的运算参数变多,运算效率减慢。
2 网络的改进
针对上述问题,通过在模型的下采样部分引入金字塔池化模块对影像不同尺度的特征进行聚合,提高获取不同特征尺度的能力,进而提升模型的分类精度。使用深度可分离卷积代替标准卷积对影像特征进行提取,达到减少模型运算参数的目的。
2.1 金字塔池化模块
金字塔池化模块最早在金字塔场景解析网络(Pyramid Scene Parsing Network,PSPNet)中提出,它通过全局平均池化和特征融合的方式来聚合不同区域的上下文信息,减少不同子区域间的上下文信息丢失,从而提高获取包含不同尺度的全局信息的能力。通过PPM 获取的高层特征图有助于提高关键点检测的能力。PPM结构如图2所示。
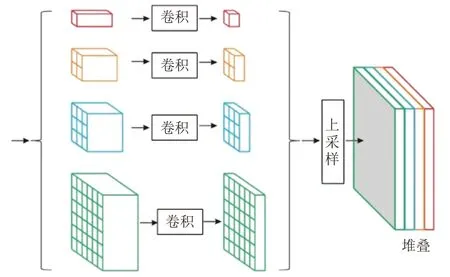
图2 金字塔池化结构
PPM 利用4 个不同的金字塔尺度融合特征,图中第一个红色方块部分是通过全局池化产生的整体输出,剩下的3 个金字塔层级将输入的特征图划分为不同的子区域。PPM 共包含4 个不同尺寸的特征图,为了保持全局特征的权重,首先对特征图进行卷积核为1×1的卷积操作来降低维度,然后使用双线性插值将4 幅特征图上采样至原图尺寸大小,最后将不同尺度的特征融合起来作为PPM的输出。
为了使U⁃Net 网络在下采样的过程中减少输入影像信息的丢失,促进不同尺度影像的特征融合,将对模型的下采样部分添加PPM 结构。在每次最大池化前分别引入输出特征图尺寸固定的PPM⁃1248 结构、PPM⁃14816 结构,以及输出特征图尺寸随影像尺寸改变而成比例变化的PPM⁃change结构,如图3所示。
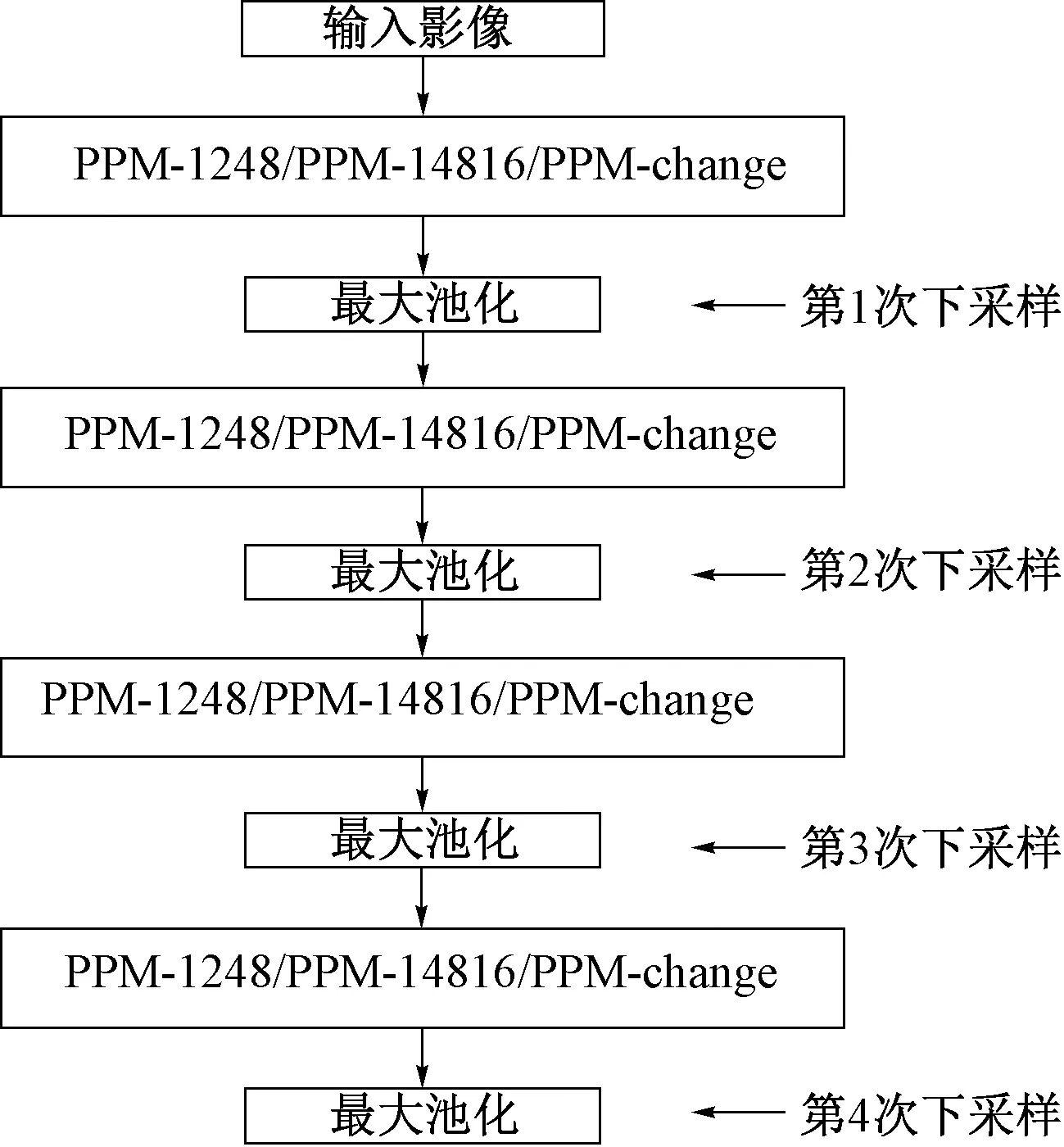
图3 引入不同PPM结构的U⁃Net下采样部分
在每次下采样操作前,PPM⁃1248结构根据输入影像的大小自动调整平均池化的步长,输出固定尺寸的特征图。例如,输入影像的尺寸为h(长度)×w(宽度)×c(维度),经平均池化后得到的4幅特征图尺寸分别为1× 1×c,2 × 2 ×c,4 × 4 ×c,8× 8×c。之后利用卷积核为1×1、滤波器个数为c∕4 的卷积操作逐一对特征图进行降维。最后采用反卷积操作将得到的特征图上采样至原始输入影像大小并同输入影像进行堆叠,见表1。

表1 PPM⁃1248特征图尺寸
由于原始输入的影像尺寸较大,直接将影像下采样至1× 1×c、2 × 2 ×c、4 × 4 ×c、8× 8×c,会造成影像细节信息的丢失。因此,PPM⁃14816 结构通过调整平均池化的步长将原始影像分别下采样至1× 1×c、4 × 4 ×c、8× 8×c、16 × 16 ×c,使得到的特征图尺寸变大,以保证在获取多尺度特征图的前提下包含尽可能多的影像特征信息,见表2。
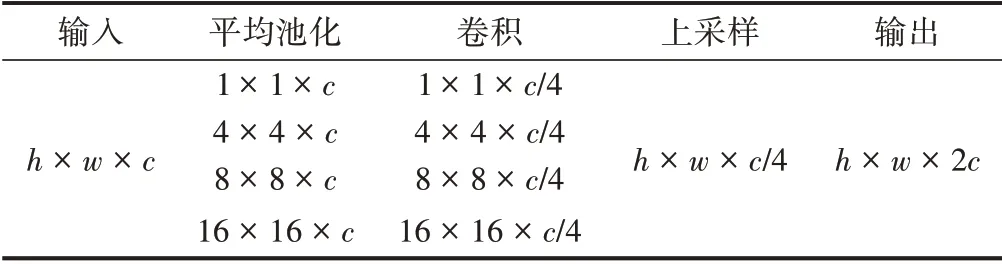
表2 PPM⁃14816特征图尺寸
U⁃Net 网络的4 次下采样操作会将原始影像分别缩小至原图大小的1∕2、1∕4、1∕8、1∕16,使用输出特征图尺寸固定的PPM⁃1248 结构与PPM⁃14816 结构无法更好地捕获不同尺寸的影像特征。PPM⁃change 结构根据输入影像的大小按照一定的比例构建影像特征图,见表3。

表3 PPM⁃change特征图尺寸
若输入影像的尺寸为h×w×c,得到的特征图尺寸分别为h∕32×h∕32×c,h∕16×h∕16×c,h∕8×h∕8×c,h∕4 ×h∕4 ×c。输出特征图的尺寸分别是输入影像尺寸的1∕32,1∕16,1∕8,1∕4。PPM⁃change结构使每幅特征图包含更多的影像信息。
2.2 深度可分离卷积
深度可分离卷积由Sifre 等[9]提出,应用在图像纹理分类方面效果很好。通常使用的标准卷积既包含了特征映射的空间信息,又包含了通道之间信息。而深度可分离卷积把标准卷积分解成两步,分别是逐通道卷积和逐点卷积[10]。逐通道卷积是对输入的每个通道单独做卷积,即每个通道有m个单独的卷积核,假设输入t个通道,输出有mt个通道,通常m取1。逐点卷积是标准的1×1卷积,它将逐通道卷积产生的mt个特征映射看成一个整体,组合起来做一次标准卷积操作。深度可分离卷积实现了通道和空间的分离,与标准卷积相比减少了参数,网络的训练速度更快,能够在网络中传播更多的特征信息,提高了网络的重建质量。
本研究将在模型中使用深度可分离卷积代替标准卷积,探索引入深度可分离卷积是否可以在降低网络参数量的同时保证分类的正确率。
3 试验数据及处理
3.1 数据集介绍
采用某铁路沿线的无人机航空影像作为试验数据,该数据前期已经过影像调色、POS 解算,空三加密等操作,并生成供本项目使用的数字正射影像(Digital Orthophoto Map,DOM)。其中,DOM 的空间分辨率为0.08 m。根据设计图要求,将影像裁剪至铁路沿线两侧500 m范围内,覆盖面积约4 km2。
3.2 地面标签制作
由于研究区域的DOM 数据缺少对应的地面真实标签,对其进行人工手动标注。影像涉及到的建筑物主要有居民住房、彩钢房、厂房、学校等,将这些建筑物的灰度值设为255。其余地物均为背景,灰度值设为0。采用了ArcGIS软件矢量标注功能。为了满足计算机GPU 的显存要求,将标注后的影像统一裁剪至512 × 512 大小,达不到512 大小的部分填充0 值。最终,共获得1 465 张影像。所有原始影像均为Tiff 格式,为提高模型的训练速度,将其转换为PNG 格式进行训练,如图4所示。

图4 DOM数据及其对应地面真实标签
3.3 影像数据增强
一般来说,数据量越大,模型越容易学习到具有代表性的特征。由于数据集有限,采用数据增强的方法扩充原始影像,将每张影像分别进行水平翻转180°、垂直翻转180°、随机裁切、对比度变换、饱和度变换、亮度变换,最终结果如图5所示。

图5 图像增强示意
3.4 评价指标
使用准确率、精确率、召回率和F1 分数作为最终评价指标。正样本(Positive)为建筑物,负样本(Negative)为背景,计算公式如下:

式中:α为模型的准确率;β为模型的精确率;γ表示模型的召回率;φ为F1 分数;TP为实际为真模型预测也为真的样本数量;TN为实际为假模型预测也为假的样本数量;FN为实际为真模型预测为假的样本数量;FP为实际为假模型预测为真的样本数量。
3.5 网络实现设置
神经网络在训练时需要人为设置一些超参数来指导模型学习,如学习率、优化函数、权重衰减参数等。经过多次试验,本文最终设置的初始学习率为0.01,使用自适应学习率方法中的Adam 优化算法[11],批尺寸(Batch Size)为8,每个卷积层后使用线性整流函数(Rectified Linear Unit,ReLU)[12]作为激活函数,并添加批标准化(Batch Normalization,BN)层,选用sigmoid 函数σ作为最终输出的激活函数[13],选用二值交叉熵(Binary Cross⁃entropy)B作为损失函数,
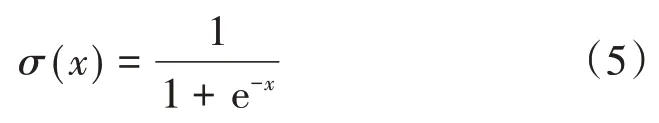

式中:y*i为地面真实标签;yi为预测值。
标签中每个像素被设置为0 和1 来表示负类别和正类别,阈值取0.5,总共训练30 个epoch。训练集与测试集划分为8∶2,计算机硬件配置见表4。
表4 计算机硬件配置
4 试验结果及分析
共开展了7 个对比试验。首先利用原始U⁃Net 网络对影像进行训练,网络标记为U⁃Net。然后在U⁃net网络下采样部分分别引入PPM⁃1248、PPM⁃14816 及PPM⁃change,网络标记为U⁃PPM⁃1248、U⁃PPM⁃14816、U⁃PPM⁃change。最后将各PPM 结构与深度可分离卷积结合,网络标记为U⁃PPM⁃1248*,U⁃PPM⁃14816*、U⁃PPM⁃change*。7 种模型在影像测试集上的建筑物提取精度见表5。由于采用随机采样策略和充分的训练,原始U⁃Net网络精度较高。相对于原始网络,改进后的网络在精确率、召回率、总体精度、F1分数都有了明显提升。这说明本研究的改进方法有效。

表5 建筑物提取精度
U⁃Net下采样部分添加PPM结构后,U⁃PPM⁃1248、U⁃PPM⁃14816 的召回率分别为0.932 4、0.961 6,相比U⁃PPM⁃change 网络分别降低了0.033 3、0.004 1。这说明随着输入影像的大小按比例调整输出特征图的方式,可以使更多的建筑物被网络识别。对于总体精度而言,U⁃PPM⁃change 网络的总体精度与其他两种网络相比显著提升,对影像特征的识别更准确。F1分数进一步说明了模型的分类精度得以提升。
在PPM 结构中使用深度可分离卷积代替标准卷积时,U⁃PPM⁃1248*、U⁃PPM⁃14816*、U⁃PPM⁃change*的各项精度指标比原先稍有提升,参数量却大幅骤减。这表明深度可分离卷积可以在降低网络参数量的同时保证分类的正确率。
预测建筑物对比见图6,可以看出,各个网络都能取得较好的建筑物识别效果。与U⁃PPM⁃1248、U⁃PPM⁃14816 相比,U⁃PPM⁃change 网络结构更显著地保留了建筑物的细节信息和建筑物的连续性。在引入深度可分离卷积后,影像的边缘特征显著增强,建筑物内部的空洞呈不同程度的减少。然而,对于形状不规则的建筑物,改进后的网络虽然较原始U⁃Net 网络有了明显的提升,但是部分细节信息还没有体现,应进一步提高网络对特征的学习能力。

图6 预测建筑物对比
5 结论与建议
1)在U⁃Net网络的下采样部分引入PPM 结构进行多尺度的特征融合有助于保留原始影像丰富的信息,提升分类精度。
2)与固定特征图尺寸的U⁃PPM⁃1248、U⁃PPM⁃14816 网络相比,输出特征图尺寸随影像尺寸按比例变化的U⁃PPM⁃change 网络对于影像的信息保留更丰富,能够更精准地识别建筑物的边缘等细节,提升聚合特征的判别力。
3)针对使用标准卷积提取地物信息参数量大的问题,使用深度可分离卷积代替标准卷积,可以在降低网络参数量的同时保证分类的正确率。
4)本文的试验数据中,由于铁路沿线周边建筑物的相似性强,训练样本有限且获取到的影像均来自同一传感器,而实际应用时往往是多源数据的混合使用,且影像覆盖地物类型众多。以后的模型改进中应更注重模型的普适性,增加数据集的多样性和数量。
5)本文仅提取了研究区的建筑物,并没有对建筑物进行分类,若将影像中的建筑物预先分成不同类型再进行提取,则可对影像实现更精细的提取,有助于后续房屋应用相关研究的开展。
