大数据处理中MapReduce框架的Q-sample算法设计
2021-03-14王晓霞孙德才
王晓霞,孙德才
(渤海大学信息科学与技术学院,锦州 121013)
0 引言
随着互联网的飞速发展,各行各业数据量也急速增长,传统的数据处理方式已不能满足要求,大数据以其在存储、处理、管理和分析等方面的优势渐渐成为解决海量数据处理的有效工具[1-2]。而基于MapReduce 框架的相似连接技术在海量大数据分析中取得了重大进展,已成为主流的大数据分析技术[3]。近年来,大量的重复数据导致MapReduce 的混淆消耗过大[4],同时也导致网络传输的拥堵。为提高基于编辑距离的相似连接算法速度,本文提出了一种基于MapReduce 的双集合全局相似连接算法Q-sample,力图通过减少MapReduce 框架的混淆消耗和网络传输来提高连接效率。通过真实数据集的实验,结果显示本算法获得了较高的连接效率。
1 基于Q-sample和统计特征的相似连接算法
Q-sample 算法的定义是:给定二个字符串集R,S和一个编辑距离阈值τ,相似连接算法的主要目的是在集合R和集合S间找出所有满足相似要求的字符串对。为实现相似连接,设计了四个MapReduce 阶段,即统计阶段、过滤阶段、验证阶段1和验证阶段2。
1.1 统计阶段
统计阶段是统计集合中各个q-gram 的频率和对q-gram 进行m集合分类,输入是一个样例集合和q-gram 过滤器参数Q和统计向量长度限值m。统计阶段包含map、shuffle和reduce三个过程。
Map 过程的任务是输入一个key-value 对,key 是片段的编号sn,value 是片段的内容。首先将value 拆分出字符串的内容s,再把s从0到 |s|-Q拆分成固定长度为Q的连续且重叠Q-1 的q-gram,并输出一个key-value对。
在shuffle 过程中,把map 过程中产生的所有具有相同key 的key-value 对传输到同一个reduce结点上。
Reduce 过程中首先遍历链表并统计列表中1的数目c。最后输出一个key-value 对
当reduce 过程结束后,则统计出了样例集合中所有q-gram 的频率。为把所有q-gram 分散到m个集合中,即G[i],0 ≤i≤m- 1。本文采用文献[5]的贪婪算法实现q-gram 的分配,得出各个分组的频率总和接近。最后,输出这m个q-gram 分组到DFS中以备后用。
1.2 过滤阶段
过滤阶段的主要任务是生成子串和得出候选对集,同样包含map、shuffle 和reduce 三个过程。在一个map 任务内根据数据的来源不同进行不同的处理。对于输入的两个集合R,S,如果输入的key-value 对来源于集合R,将为集合生成索引子串。如果输入的key-value 对来源于集合S,将为集合生成匹配子串。首先字符串的编号sid和内容s先从key-value 对的value 中抽取出来。如果字符串s与字符串r相似,即ed(r,s) ≤τ,则字符串s中一定包含至少一个字符串的索引子串。如果字符串s有多个子串。则字符串r和字符串s满足 |r|<|s|-t或 |r|> |s|+t,则这二个字符串一定不是相似对。因此,为字符串s匹配子串时,只需考虑为那些满足 |s|-τ≤|r|≤|s|+τ的r生成匹配子串。为生成字符串s的匹配串,我们先让q从循 环到。在每次循环中,逻辑上把字符串s用q分割成连续但不重叠的qsample,而此时只需为第i个q-sample生成匹配子串的位置psj限制在范围[max(0,(i-1)q-t),min((i-1)q+t,s-q)]内,如图1所示。

图1 一个固定q值下q-gram有效开始位置的范围
而当q≤2τ+ 1时,此时所有q-gram都是有效的,所以不必为每个q-sample 计算生成q-gram。此时,map:< sn,split>→
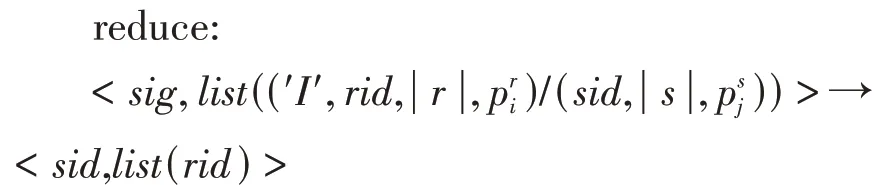
1.3 验证阶段1
在过滤阶段,产生了包含R和S间所有潜在匹配对的候选集。但候选集中只有串的ID 号而没有内容,所以不能进行验证。采用文献[6]中提出的二阶段读取方法实现R和S集合字符串内容的读取。验证阶段分为证阶段1 和验证阶段2 两个阶段。
验证阶段1 的主要任务是读取候选集中涉及到集S的串内容、消除冗余串对和生成集S中串的统计向量。验证阶段1 包含map、shuffle 和re⁃duce 三个过程。在setup(执行map 任务前)中,统计阶段的输出的m个q-gram集G[i],0 ≤i≤m- 1被读入并构建。
验证阶段1 的输入包括集合S和过滤阶段输出的候选集。在一个map 任务中,首先区分输入的来源。如果是候选集,则无需处理直接原样输出,即
map:
map:< sn,split> →
在shuffle 过程中,具有相同sid的key-value对被传送到同一个reduce 结点上。在reduce 过程中,输入也是一个key-value对
reduce:
1.4 验证阶段2
在验证阶段1结束后,候选集中属于集合S的串内容被保留,此时,因为缺少候选对中属于集合R串的内容,所以仍然无法进行验证。过滤阶段2的主要任务是读取候选集对属于集合R中串的内容、为集合R中串生成统计向量和验证候选对。在输出的m个q-gram 集G[i],0 ≤i≤m- 1 被读入并构建。验证阶段2 的map 过程的输入包括集合R和验证阶段1 的输出。在每个map 任务中,首先判断输入key-value 对的来源。如果来源是集R中的字符串r,则按验证阶段1 中方法为其生成统 计 向 量u, 并 输 出 key-value 对
map:<(sid,v#s),list(rid) > →
map:< sn,split> →
在reduce 中将通过验证每个候选对的方法找出真正相似对。在一个reduce 任务中,输入是一个key-value 对
2 实验
2.1 实验环境
实验中用Java 基于Hadoop 1.2.1 平台实现了算法Q-sample。本文实验数据来源于DBLP au⁃thor+title(http://dblp.uni-trier.de/xml/)、GenBank EST(ftp://ftp.ncbi.nlm.nih.gov/genbank/)和PubMed abstract(ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/)三个数据集。三个数据集的详情对比如表1。
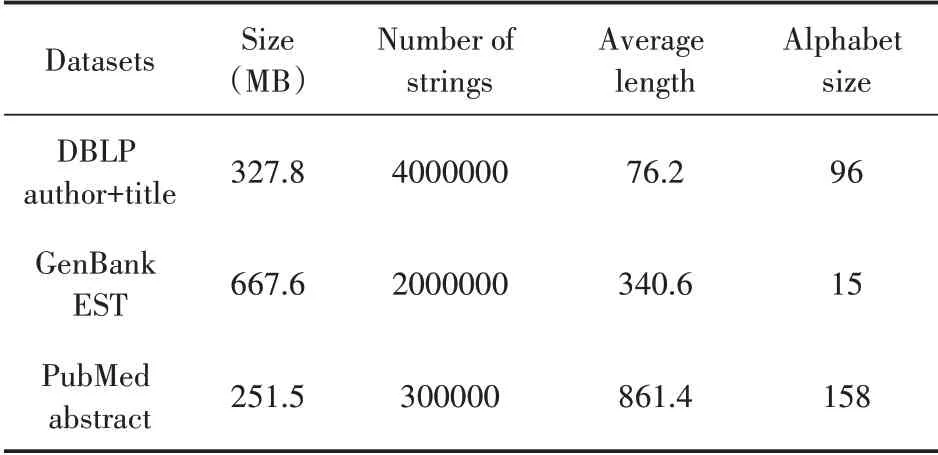
表1 数据集信息
实验集群中的总节点数为5个(1个主节点,4个从节点),每个节点的硬件配置为:CPU i5 4590 3.7 GHZ,内存16 G,硬盘1 TB。集群软件配置:操作系统Ubuntu 15.10 64 位,Java 1.7,Hadoop 平台版本1.2.1。为进行双集合相似连接实验,先把数据集分割成2 个字符串数目相等的集合(R和S),然后在上述集群环境中采用算法对2个集合进行相似连接。实验中以编辑距离作为默认的相似连接度量标准。
2.2 实验结果
实验中使用Q-sample 算法分别在DBLP(τ= 4)、GenBank EST(τ= 8)和PubMed abstract(τ= 20)数据集上进行相似连接运算。采用不同q-gram 过滤器及组合时算法的验证时间统计如图2到图4。

图2 不同q-gram过滤器及组合DBLP
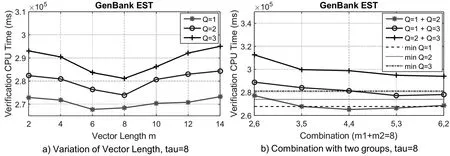
图3 不同q-gram过滤器及组合GenBank EST

图4 不同q-gram过滤器及组合PubMed
图2 到图4 展示了在三个不同数据集上Qsample 算法使用不同q-gram 过滤器和向量长度的验证时间。如图2—图4 所示,过滤器(Q= 1)的验证时间要一直少于其他q-gram 过滤器(Q= 2或Q= 3)。
从实验结果可以看出,在所采用的三种数据集中,Q-sample 算法的时间都是最低的,使得在MapReduce处理中提高处理速度。
3 结语
本文主要研究大数据处理框架下基于MapRe⁃duce 框架的相似连接并行算法Q-sample。因为Q-sample 的子串生成方案减少了子串数量,所以算法的map 过程输出量要降低,从而减少混淆时间和数据传输时间,因此过滤时间也减少了,而过滤时间的快慢大体上决定了从DFS 上读取数据的时间消耗。 reduce 过程的输出数据是候选集,采用了过滤验证二阶段模式。在验证过程中,采用了多维的统计向量进一步过滤掉了无效候选对,然后采用验证算法对候选对进行验证,这样则提高了过滤效率。实验结果显示算法可以解决大数据处理中的处理速度缓慢问题,在大数据应用中有实际意义。
