基于情感增强的微博谣言检测
2021-03-14奚金霞
奚金霞
(四川大学网络空间安全学院,成都 610065)
0 引言
中国社会科学院2020年发布的《中国新媒体发展报告》指出[1]:我国网民在接收新闻信息时,倾向于通过移动端从微博、微信等社交媒体获取信息,电视、纸媒等传统媒体在信息传播方面占有率大大下降。社交媒体的公开性、快捷性使人们可以随时随地分享自己感兴趣的内容,极大地方便了信息交流,但由于消息发布的便利以及社交媒体自身审核环节的薄弱,用户的无节制传播促进了谣言的泛滥,在线社交网络成为谣言传播的重灾区。谣言在传播过程中通常会被放大和扭曲,引起受众恐慌,严重时甚至会威胁社会的和谐稳定。因此,不论是对于网络环境的净化,还是社会稳定的维护,都迫切需要技术手段自动化检测信息内容的真实性,从而促进在线社交媒体上谣言的快速有效识别。
为了及时鉴别谣言,遏制其传播,业界做了大量的努力与尝试。早期基于浅度机器学习的谣言检测采用特征手动提取结合机器学习算法的方法,主要围绕如何选择和提取有效的特征来区分谣言和非谣言而展开[3],所提取的特征通常分为四种类型:基于内容的特征,如句子长度、情感词数等[2];基于用户的特征,如是否认证、用户类型等[16];基于主题的特征(即前两个特征集的聚合),如集合中积极和消极情绪的比例等[5];基于传播的特征,如传播树的深度、广度等[8]。之后,一部分研究探索了上述特征随时间变化的动态特性[3,6],提出了基于时间序列的谣言检测方法。然而,基于浅度机器学习的谣言检测方法严重依赖于初期的人工特征工程,难以获取高维、复杂的数据特征[11],模型性能提升受限。为了解决这个问题,研究者们将深度学习引入谣言检测领域。循环神经网络RNN 最先被用来学习文本的时间序列特征[4],但RNN 在训练过程中存在梯度消失的问题,因而只能适应短文本中上下文依赖关系的学习。于是研究者们提出了用长短期记忆网络LSTM 和门限递归单元GRU[4,11]来解决梯度消失问题,实现了文本长距离依赖关系的捕捉。之后,在图像领域表现较好的卷积神经网络CNN 又被引入用于提取谣言全局特征[10,12-13],实验证明该方法能有效地识别谣言且有助于实现谣言早期检测。上述基于深度学习的谣言检测方法倾向于使用神经网络自动学习文本的上下文语义特征来判定待检测信息的可信度。然而,根据Vosoughi等人[14]的研究,人们对于谣言事件和真实事件的情感反应是不同的,谣言事件中群体反应多为恐惧、厌恶和惊讶等消极情绪,而真实事件多引发期待、喜悦和信任等积极情绪。相对于语义特征,文本中所携带的情感特征是区分谣言和非谣言更有效的特征[15]。因此,如何充分提取文本中的情感特征以提高谣言检测效率是本文研究的重点。除此之外,对于不同类型的信息,使用不同的特征进行模型训练将得到不同的结果。如Ro⁃sas 等人[9]发现对于教育、政治等严肃话题,需要重点关注信息中的语言特征,而对于明星类话题,则应该给予用户情感观点更多的关注。然而现有工作大多通过获取一套通用的特征集合来表征所有的网络数据,对数据集中的微博信息类型缺少必要的分析,忽略了不同类型数据的个性化特征,导致难以挖掘隐藏在异质数据中的高价值信息。因此,如何有效提取不同类型信息中的细粒度数据特征,也是本文研究的重点。
针对上述问题,本文选取新浪微博作为重点研究对象,将谣言检测任务拆分为微博类型检测、情感增强、谣言分类三个子任务,充分考虑情感特征对于谣言检测的重要性,区分待检测信息的类型。本文的主要贡献概括如下:
(1)将情感融入预训练模型来帮助识别不实信息。该方法在文本向量化过程中侧重于提取文本内容中的情感极性特征,能有效增强文本建模中情感特征的表现能力。
(2)针对不同类型的微博信息,基于情感文本编码结果,分类别构建分类器,挖掘更细粒度、更有效的特征来区分谣言和非谣言,进一步提高整个模型的检测准确率。
1 基于情感增强的谣言检测模型
本节主要介绍我们提出的基于情感增强的谣言检测模型。如图1所示,本文提出的基于情感增强的谣言检测模型由三部分构成:微博类型分类器、情感增强编码器、谣言分类器。在检测过程中,首先根据微博原帖文本对待检测微博进行类型分类,然后通过情感编码器获得微博文本(原帖、转发、评论)的情感增强向量,最后输入到对应类型的谣言分类器中得到谣言与否的分类结果。

图1 基于情感增强的谣言检测模型
1.1 微博类型分类器
考虑到多数微博原帖文本长度短、包含信息少等特点,本文选取Google 提出的预训练语言模型BERT对原帖文本进行建模。因为BERT利用多层的Transformer 作为基本的编码器,通过selfattention 机制在大量无监督数据上进行自监督训练,其内部已充分学习到常用语料的语法和句法知识,具有强大的语义表征能力。文本的编码过程如图2 所示,其中e1,…,en为输入向量,T1,…,Tn为输出向量。

图2 BERT模型结构
具体地,对于给定的微博原帖文本序列:

其中xi表示文本序列的第i个字符。考虑到微博类型分类器实现的是对单个微博原帖文本的分类,所以我们将句子分割向量EA置为0,并获取每个字位置嵌入符xi Pi和词嵌入Ei形成字符的表示,位置嵌入Pi的计算具体如下:

其中i表示字符在句子中的位置,2j和2j+ 1 分别表示词向量的偶数和奇数维度,d表示词向量的维度。我们分别对每个字符的三个向量求和,作为最终的输入向量。之后我们将输入到堆叠的Transformer 编码器和解码器中,取最后的输出成为最终的语义上下文编码,最后连接Softmax层产生微博类型概率分布:
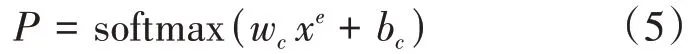
其中,wc和bc表示参数向量和偏置,xe为微博原帖的向量表示。得到类型概率分布后,取概率值最大的为预测结果,后续依此结果将数据输入到对应的谣言分类器中。
1.2 情感增强编码器
在情感编码器构建阶段,我们对数据集中的文本进行了情感标注,然后选出相近数量的积极情感文本和消极情感文本,基于BERT 进行情感分类,并固定模型参数形成情感编码增强编码器EBERT,它以情感学习为目标,所以对于文本情感特征的捕捉更加敏锐。情感分类模型的设计与微博类型分类器相同。在句向量表示阶段,具体地,对于待检测微博m中的所有文本:


再输入到多层带有多头注意力机制的Trans⁃former 中,将xei分别与矩阵WQ、WK、WV相乘,得到查询矩阵Q、键矩阵K、值矩阵V,以此计算自注意力:

其中dK为向量维度。接着计算多头注意力结果:

多头注意力输出结果经残差计算和标准化后,输入全连接层。经过n层编码器训练后,我们提取倒数第二层Transformer 的输出作为最终句向量的表示。整个句向量的表示过程可公式化为:

最后,将微博中所有句向量纵向拼接形成待检测微博m的整体表示:

1.3 谣言分类器
TextCNN[29]是Yoon Kim 提出的一种用于处理文本分类问题的卷积神经网络,与CNN 从上到下、从左到右滑动进行特征提取不同的是,TextCNN 仅存在竖直方向的滑动,其核心思想是捕捉文本局部特征。对于单条文本来说,局部特征是由若干词组成的滑动窗口,通过学习可以得到文本上下文联系,而对于本文所要检测的微博来说,局部特征是若干评论/转发组成的滑动窗口,通过学习可以得到微博中评论/转发文本之间的联系。综上所述,在构建本文的谣言分类器时,TextCNN 是一个合适的选择。该模块的模型结构如图3所示。

图3 谣言分类模块架构
2 实验与分析
2.1 数据集
在目前的谣言检测研究中,很少有工作考虑到微博信息类型对谣言检测的影响,现存公开数据集不能满足本文实验的需求。因此,我们选择在新浪微博平台上构建自己的数据集。新浪微博平台将微博信息分为社会、科技、财经、历史等49 类,我们对新浪微博管理平台上的谣言进行了类别统计,发现谣言多产生于社会、国际、明星、健康类。因此,我们仅收集这四类微博数据验证本文方法的有效性,微博类型分类模块所使用的数据集如表1 所示。之后我们在Ma①https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect2017.zip?dl=0和Liu②https://github.com/thunlp/Chinese_Rumor_Dataset/的新浪微博公开数据集上进行了验证,数据集的具体情况如表2所示。

表1 微博类型分类所使用数据集概述

表2 数据集中谣言与非谣言分布情况
2.2 实验设置
本文使用准确率、精确率、召回率和F1值作为评估指标。在模型的实现上,微博类型分类器、情感增强编码器及其他对比实验所使用的预训练模型均基于BERT 中文预训练模型BERTBase-Chinese,模型结构为:12-layer, 768-hid⁃den, 12-heads, 110M parameter,超参数设置为:batch size 为24,学习率为3e-5、最大句子长度128。谣言分类器使用TextCNN,其中卷积核高度为[2,3,4],卷积核数量为128,Dropout 为0.5,batch size 为20,学习率为1e-3,使用ReLU 作为激活函数,使用交叉熵作为模型的损失函数。
2.2.1 对比方法
(1)无情感增强和分类。移除微博类型分类器,用BERT-Base-Chinese 代替EBERT 获得文本编码,再将所有类型数据不加区分地输入到TextCNN谣言分类器中。
(2)仅分类。在对文本进行建模时,用BERT-Base-Chinese 代替EBERT 获得文本编码,再输入到对应类型的TextCNN谣言分类器中。
(3)仅情感增强。移除微博类型分类器,使用EBERT 获得情感增强文本编码,再将所有类型数据不加区分地输入到TextCNN谣言分类器中。
(4)本文方法。使用微博类型分类器对微博进行分类,使用EBERT 获得情感增强文本编码,再输入到对应类型的TextCNN谣言分类器中。
2.2.2 实验结果及分析
表3、表4列出了实验结果,观察分析后可得出如下结论:
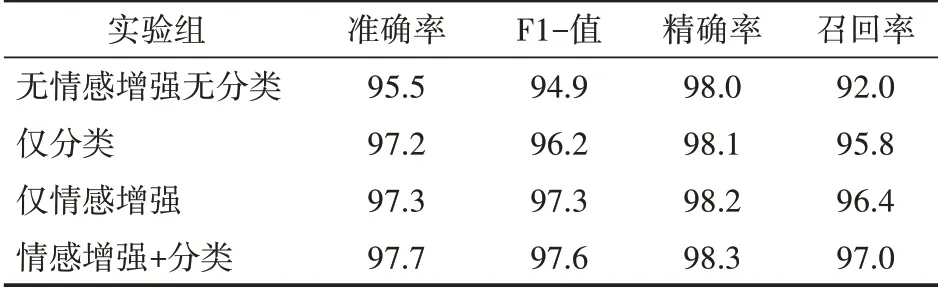
表3 rumdect数据集实验结果

表4 CED_Dataset数据集实验结果
(1)在我们的实验中,分类或情感增强任一模块的加入都使得模型四个指标有不同程度的提高,证明各类别信息特征的细粒度提取和情感特征充分提取能有效提升模型的性能。
(2)同时引入分类和情感增强模块的模型在两个数据集上均达到最高性能,召回率均提升5%以上,说明所提出模型能有效识别虚假信息,减少谣言漏报率。
3 结语
针对现有方法忽略谣言文本情感特征和特征提取粗粒度的问题,本文提出了基于情感增强的谣言检测方法。借助预训练模型强大的文本语义表征能力,以情感检测为导向构建情感增强编码器,充分提取文本中的语义和情感信息。并分类别构建谣言分类器,更深层次捕捉各类别信息的细粒度特征,实现全方位多层次的数据特征提取。在公开数据集上的实验结果表明,引入情感增强和微博类型分类后的谣言检测模型性能大幅提升,充分证明了本文方法的有效性。
